紧急曝光!Django SQL文件生成全攻略:一文看懂django.core.management.sql
发布时间: 2024-10-14 02:26:02 阅读量: 2 订阅数: 3 
# 1. Django SQL文件生成概述
## Django SQL文件生成的重要性
在Django开发中,SQL文件生成是一个重要的步骤,它能够帮助开发者在数据库迁移过程中保持数据的一致性和完整性。通过生成SQL文件,我们能够将Django模型定义转换为数据库特定的SQL语句,这对于数据库迁移、备份、恢复以及数据迁移等场景至关重要。
## 生成SQL文件的基本流程
生成SQL文件的基本流程涉及使用Django的管理命令`manage.py sqlall`或`manage.py sqlmigrate`。这些命令能够根据当前的数据库模型状态生成相应的SQL语句,使得开发者能够在不同的数据库之间迁移数据或进行版本控制。
## 应用场景示例
例如,在进行数据库迁移时,开发者可以生成SQL文件来检查Django将要执行的数据库操作,确保这些操作符合预期。此外,在备份数据库时,生成的SQL文件可以作为数据的完整备份,便于未来的数据恢复或迁移。
```bash
# 使用Django命令生成SQL文件
python manage.py sqlall [app_name]
```
通过上述命令,开发者可以获得应用`app_name`对应模型的SQL语句,用于数据库迁移或备份的准备工作。
# 2. Django SQL文件生成理论基础
## 2.1 Django模型与数据库关系
### 2.1.1 Django ORM简介
Django ORM(Object-Relational Mapping)是Django框架的核心特性之一,它提供了一个强大的数据库抽象层,使得开发者可以使用Python代码来操作数据库,而无需直接编写SQL语句。通过定义模型(Model)类,ORM自动为数据库中的表提供了CRUD(创建、读取、更新、删除)操作的支持。
在Django中,每个模型类对应数据库中的一个表。模型的属性被映射为表的列,而模型实例则代表表中的一行数据。通过继承`models.Model`类,开发者可以定义模型,并通过Django提供的API进行数据库操作。
### 2.1.2 模型与数据库映射原理
Django的模型与数据库之间的映射原理基于元数据(metadata)。每个模型类中的字段(field)定义了表列的类型和属性,而Django的元数据系统则负责将这些字段转换成数据库中的列定义。
例如,一个简单的模型类可能定义如下:
```python
from django.db import models
class Person(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
```
在这个例子中,`first_name`和`last_name`字段都是`CharField`类型,这意味着它们将映射为数据库中的`VARCHAR`类型的列。`max_length`参数定义了列的最大长度。
Django通过元数据系统来处理模型与数据库表的映射,包括列的数据类型、索引、外键关系等。当模型发生变化时,Django的迁移系统会生成相应的SQL语句来更新数据库结构,而无需手动编写SQL代码。
## 2.2 Django迁移系统详解
### 2.2.1 迁移的基本概念
Django的迁移系统是其ORM的核心部分,它负责跟踪模型定义的变化,并将这些变化同步到数据库结构中。迁移是Django中一种记录模型变化的方法,它允许开发者在不同的环境中保持数据库结构的一致性。
每次对模型类进行修改后,开发者都需要创建一个新的迁移文件,该文件记录了需要在数据库上执行的变更操作。Django提供了一个简单的命令行工具来自动化这一过程:
```bash
python manage.py makemigrations
```
这个命令会检查模型定义的变化,并生成一个新的迁移文件,该文件包含了对应的变化操作。
### 2.2.2 迁移文件的作用与生成过程
迁移文件是一系列描述性的Python脚本,它们包含了用于修改数据库结构的SQL语句。Django通过执行这些SQL语句来应用模型的变化。
当运行`makemigrations`命令时,Django会根据模型定义的变化来生成一个新的迁移文件。例如,如果在模型中添加了一个新字段,Django会生成一个迁移文件,其中包含了向现有表中添加新列的SQL语句。
```python
# Generated by Django <当前版本号> on <生成迁移文件的时间戳>
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('myapp', '上一个迁移文件的名称'),
]
operations = [
migrations.AddField(
model_name='person',
name='age',
field=models.IntegerField(default=20),
),
]
```
在这个迁移文件中,`dependencies`列表定义了迁移操作依赖的迁移文件,而`operations`列表则定义了具体的数据库操作,例如添加字段。
## 2.3 SQL语言在Django中的应用
### 2.3.1 SQL语言概述
SQL(Structured Query Language)是用于数据库管理和操作的标准语言。它允许开发者执行查询、更新、插入和删除操作,并对数据库结构进行修改。
虽然Django的ORM提供了强大的数据库操作抽象,但在某些情况下,直接使用SQL语句可能更为直接和高效。例如,复杂的查询可能无法通过ORM简单实现,或者需要优化性能时,直接编写SQL语句可能更为合适。
### 2.3.2 Django中执行原始SQL的方法
Django提供了几种方式来执行原始SQL语句,这包括:
1. `raw()`方法:允许开发者直接在模型查询集(QuerySet)上调用`raw()`方法,并传入SQL语句来执行。
```python
people = Person.objects.raw('SELECT * FROM myapp_person')
```
2. `execute()`方法:使用`django.db.connection`对象的`execute()`方法可以直接执行SQL语句。
```python
from django.db import connection
def my_custom_sql(self):
with connection.cursor() as cursor:
cursor.execute("UPDATE bar SET foo = 1 WHERE baz = %s", [self.baz])
cursor.execute("SELECT foo FROM bar WHERE baz = %s", [self.baz])
row = cursor.fetchone()
return row
```
3. `cursor()`方法:通过`cursor()`方法可以创建一个游标对象,用于执行SQL语句并处理结果集。
```python
from django.db import connection
def my_custom_sql(self):
with connection.cursor() as cursor:
cursor.execute("UPDATE app_model SET name = %s WHERE id = %s", ['new_name', self.id])
***mit() # 提交事务
```
通过这些方法,开发者可以在Django中灵活地使用SQL语言来执行复杂的数据库操作。然而,过度依赖SQL可能会降低代码的可移植性和可维护性,因此建议在必要时才使用这些方法。
以上内容介绍了Django SQL文件生成的基础理论,包括模型与数据库的关系、迁移系统的概念以及如何在Django中应用SQL语言。这些知识为理解Django如何生成SQL文件提供了必要的背景和理解。在接下来的章节中,我们将深入探讨`django.core.management.sql`模块,以及如何在实践中生成和管理SQL文件。
# 3. django.core.management.sql模块深度解析
在本章节中,我们将深入探讨Django框架中的`django.core.management.sql`模块,这个模块对于生成和管理Django项目的SQL文件至关重要。通过对这个模块的深度解析,我们可以更好地理解如何利用Django的管理命令来生成SQL文件,并对这些文件进行详细的分析。
## 3.1 模块功能与用途
### 3.1.1 sql模块概述
`django.core.management.sql`模块是Django框架中用于生成和管理SQL文件的核心组件之一。它提供了一系列工具和API,使得开发者能够轻松地生成数据库迁移所需的SQL语句。这些SQL语句可以用于创建数据库架构、应用迁移或导出数据库模式。
### 3.1.2 sql模块的主要功能
该模块的主要功能包括:
- **生成SQL文件**:通过`sql`模块提供的工具,可以生成包含数据库表创建、索引创建等SQL语句的文件。
- **自定义SQL生成**:开发者可以通过自定义迁移操作来影响SQL文件的生成过程。
- **管理SQL文件**:生成的SQL文件可以被查看、维护和应用,以支持数据库迁移和模式管理。
## 3.2 SQL文件生成API详解
### 3.2.1 generate_sql()函数
`generate_sql()`函数是`sql`模块的核心,它负责生成SQL文件。这个函数接受两个主要参数:`database`和`state`。
- **database**:指定目标数据库的别名。
- **state**:描述模型状态的对象,包含要生成SQL的迁移状态。
函数返回一个生成器对象,其中包含生成的SQL语句。这些语句可以通过进一步处理来写入文件。
#### 示例代码:
```python
from django.core.management.sql import sql
def generate_sql_for_database(database, state):
sql_generator = sql(database, state)
with open(f"{database}_schema.sql", "w") as sql_***
***
***"{sql_statement};")
```
在这个示例中,我们首先导入了`sql`函数,然后定义了一个`generate_sql_for_database`函数,它接受数据库别名和模型状态作为参数。函数内部创建了一个SQL生成器,然后打开一个文件并将生成的SQL语句写入该文件。
### 3.2.2 使用示例与场景分析
在实际应用中,`generate_sql()`函数通常在自定义迁移操作中使用。例如,当需要对特定数据库进行特定的SQL操作时,可以通过编写自定义迁移类来实现。
#### 示例场景:
假设我们需要为一个名为`custom_database`的数据库生成特定的SQL文件,我们可以这样做:
```python
from django.db import migrations
def generate_custom_sql(apps, schema_editor):
state = apps.get_model('your_app', 'State').objects.get_current_state()
sql_generator = sql('custom_database', state)
with open('custom_database_schema.sql', 'w') as sql_***
***
***"{sql_statement};")
class Migration(migrations.Migration):
dependencies = [
('your_app', 'previous_migration'),
]
operations = [
migrations.RunPython(generate_custom_sql),
]
```
在这个场景中,我们定义了一个`generate_custom_sql`函数,它通过调用`sql`函数生成自定义数据库的SQL文件。然后在迁移操作中使用`RunPython`来执行这个函数。
## 3.3 SQL文件内容分析
### 3.3.1 自动生成SQL语句的类型
自动生成的SQL语句主要分为两类:
- **数据定义语言(DDL)**:用于定义数据库架构的SQL语句,例如`CREATE TABLE`、`ALTER TABLE`、`DROP TABLE`等。
- **数据操作语言(DML)**:用于操作数据库中的数据的SQL语句,例如`INSERT`、`UPDATE`、`DELETE`等。
### 3.3.2 SQL语句的结构和逻辑
生成的SQL文件中的语句通常遵循一定的结构和逻辑。例如,首先创建表,然后创建索引,最后是数据插入等。这些语句的顺序对于数据库的完整性和性能都是至关重要的。
#### 示例SQL文件结构:
```sql
CREATE TABLE my_table (
id serial PRIMARY KEY,
name VARCHAR(100)
);
CREATE INDEX idx_name ON my_table(name);
INSERT INTO my_table (name) VALUES ('John Doe');
```
在这个示例中,我们首先创建了一个名为`my_table`的表,然后创建了一个索引`idx_name`,最后插入了一条数据。
通过本章节的介绍,我们对`django.core.management.sql`模块的功能、用途和API有了深入的了解。我们探讨了如何使用`generate_sql()`函数来生成SQL文件,并通过实际的示例展示了如何在自定义迁移操作中应用这些知识。此外,我们还分析了SQL文件的内容,包括自动生成SQL语句的类型以及这些语句的结构和逻辑。在下一章节中,我们将进一步探讨如何在Django项目中实践SQL文件的生成和管理。
# 4. Django SQL文件生成实践指南
在本章节中,我们将深入探讨如何在实际项目中应用Django SQL文件生成技术。我们将从环境配置与准备开始,逐步介绍生成与管理SQL文件的过程,并通过应用案例来展示数据库迁移前后的对比,以及数据库回滚与恢复操作的具体步骤。
## 4.1 环境配置与准备
### 4.1.1 Django项目的创建与配置
要开始生成SQL文件,首先需要一个配置好的Django项目。以下是创建和配置Django项目的基本步骤:
1. 安装Django:使用`pip install django`命令安装最新版本的Django。
2. 创建项目:通过`django-admin startproject myproject`创建一个新的项目。
3. 配置数据库:编辑项目的`settings.py`文件,设置数据库连接信息,例如:
```python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
}
}
```
这里我们使用了SQLite数据库作为示例,您可以根据实际需要更换为MySQL、PostgreSQL等其他数据库。
### 4.1.2 数据库的安装与连接
接下来,您需要安装所选的数据库并确保它可以正常工作。以下是使用MySQL作为示例的步骤:
1. 安装MySQL服务器和客户端库。
2. 创建数据库:登录MySQL客户端,执行`CREATE DATABASE mydatabase;`创建数据库。
3. 创建用户并授权:`CREATE USER 'myuser'@'localhost' IDENTIFIED BY 'mypassword'; GRANT ALL PRIVILEGES ON mydatabase.* TO 'myuser'@'localhost';`。
4. 安装MySQL数据库驱动:`pip install mysqlclient`。
最后,确保Django项目的`settings.py`中的数据库配置正确,例如:
```python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'mydatabase',
'USER': 'myuser',
'PASSWORD': 'mypassword',
'HOST': 'localhost',
'PORT': '3306',
}
}
```
完成以上步骤后,您就可以开始生成SQL文件了。
## 4.2 生成与管理SQL文件
### 4.2.1 生成SQL文件的命令与参数
Django提供了内置命令来生成SQL文件。基本命令是`python manage.py sqlall app_label`,它可以生成指定应用的所有SQL语句。
#### 生成所有应用的SQL文件
如果您想生成整个项目的所有SQL文件,可以使用以下命令:
```bash
python manage.py sqlall [app_label]
```
其中`[app_label]`是可选的,用于指定特定应用。
#### 生成特定应用的SQL文件
如果只想生成特定应用的SQL文件,可以省略`app_label`参数:
```bash
python manage.py sqlall
```
#### 参数解释
- `--database`:指定生成SQL文件的数据库,默认是`default`。
- `--schema`:只生成schema SQL,不包括数据。
- `--data`:只生成数据SQL,不包括schema。
### 4.2.2 SQL文件的查看与维护
生成的SQL文件默认保存在项目的根目录下。您可以使用文本编辑器打开并查看文件内容。
#### SQL文件的查看
要查看生成的SQL文件,可以直接使用文本编辑器打开文件,例如使用`vim`或`cat`命令:
```bash
cat myproject/sqlall.sql
```
#### SQL文件的维护
您可以手动编辑SQL文件来调整生成的SQL语句,比如添加索引、优化查询等。但请注意,修改后的文件可能需要在迁移时排除以避免与Django自动迁移冲突。
### 4.3 SQL文件的应用案例
#### 4.3.1 数据库迁移前后的对比
生成SQL文件后,您可以在执行数据库迁移之前查看生成的SQL语句,以确保迁移操作符合预期。以下是一个简单的迁移前后对比案例:
1. 生成迁移前的SQL文件:
```bash
python manage.py sqlall > before_migration.sql
```
2. 执行数据库迁移:
```bash
python manage.py migrate
```
3. 生成迁移后的SQL文件:
```bash
python manage.py sqlall > after_migration.sql
```
4. 对比两个文件的差异:
```bash
diff before_migration.sql after_migration.sql
```
#### 4.3.2 数据库回滚与恢复操作
在某些情况下,您可能需要回滚数据库到某个特定的状态。Django提供了回滚命令,可以使用以下步骤来恢复到迁移前的状态:
1. 查看所有迁移记录:
```bash
python manage.py showmigrations
```
2. 回滚到最后一个迁移:
```bash
python manage.py migrate [app_label] zero
```
其中`[app_label]`是可选的,用于指定特定应用。
3. 使用SQL文件恢复数据:
您可以将生成的SQL文件中的数据部分导入到数据库中,以恢复到特定的数据状态。
通过以上步骤,您可以有效地生成、管理和应用SQL文件来维护您的数据库结构和数据。这些实践指南将帮助您在实际项目中更加自信地使用Django SQL文件生成技术。
# 5. Django SQL文件生成高级应用
## 5.1 自定义SQL文件生成规则
在Django项目中,有时候我们需要对自动生成的SQL文件进行定制,以满足特定的需求。自定义SQL文件生成规则涉及到自定义迁移操作以及自定义SQL文件的生成逻辑。
### 5.1.1 自定义迁移操作
自定义迁移操作通常需要在迁移文件中使用`RunSQL`或者`RunPython`操作。这些操作可以让我们执行自定义的SQL语句或者Python函数,从而实现更复杂的数据库操作。
```python
from django.db import migrations
def forwards_func(apps, schema_editor):
# 使用自定义的SQL语句进行操作
db_alias = schema_editor.connection.alias
with schema_editor.connection.cursor() as cursor:
cursor.execute("UPDATE myapp_mytable SET mycolumn = 'new value' WHERE mycolumn = 'old value';")
class Migration(migrations.Migration):
dependencies = [
('myapp', '0002_auto_***_1200'),
]
operations = [
migrations.RunPython(forwards_func),
]
```
在上面的例子中,我们定义了一个`forwards_func`函数,该函数使用`schema_editor`执行一个自定义的SQL更新语句。然后在迁移操作中调用这个函数。
### 5.1.2 自定义SQL文件的生成逻辑
自定义SQL文件的生成逻辑则更加灵活,可以在`generate_sql()`函数中实现。通过扩展`django.core.management.sql`模块,我们可以重写`generate_sql()`函数,使其在生成SQL时加入我们的自定义逻辑。
```python
from django.core.management.sql import sql"})
from django.db import migrations
def generate_custom_sql(apps, schema_editor):
# 自定义SQL生成逻辑
custom_sql = []
for table_name in ['myapp_mytable', 'otherapp_othertable']:
custom_sql.append(f"CREATE INDEX custom_index_{table_name} ON {table_name} (mycolumn);")
return custom_sql
class Migration(migrations.Migration):
# ...
def sql(self, schema_editor, *args, **kwargs):
return generate_custom_sql(schema_editor, *args, **kwargs)
```
在这个例子中,我们重写了`sql()`方法,并在其中定义了`generate_custom_sql`函数,该函数生成了额外的索引创建SQL语句。这样在执行迁移时,这些自定义的SQL语句也会被执行。
## 5.2 集成外部工具与扩展
为了进一步提升SQL文件生成的灵活性和功能性,我们可以集成外部工具或者扩展`django.core.management.sql`模块。
### 5.2.1 第三方库的使用
Django社区提供了许多第三方库,可以帮助我们更好地管理数据库迁移和SQL文件生成。例如,`django-extensions`库中的`sqlcustom`命令允许我们运行自定义SQL文件,而无需修改迁移操作。
首先,你需要安装`django-extensions`库:
```bash
pip install django-extensions
```
然后在你的Django项目中添加`django_extensions`到`INSTALLED_APPS`设置中,并运行`manage.py sqlcustom`命令:
```bash
./manage.py sqlcustom yourapp
```
这将生成一个名为`yourapp.sql`的文件,其中包含了自定义SQL语句。
### 5.2.2 扩展django.core.management.sql模块
我们可以通过创建自定义的`BaseCommand`来扩展`django.core.management.sql`模块。这允许我们添加新的命令,用于生成特定的SQL文件。
```python
from django.core.management.base import BaseCommand
from django.core.management.sql import sql"]
class Command(BaseCommand):
help = 'Generates a custom SQL file'
def add_arguments(self, parser):
parser.add_argument('app_label', type=str, help='Name of the app to generate SQL for')
def handle(self, *args, **options):
app_label = options['app_label']
sql_output = []
for migration_name, sql_statements in sql(app_label, None):
sql_output.append("-- %s" % migration_name)
sql_output.extend(sql_statements)
with open(f"{app_label}_custom.sql", 'w') as f:
f.write('\n'.join(sql_output))
```
在这个例子中,我们定义了一个新的命令`sqlcustom`,它接受一个应用标签作为参数,并生成一个包含该应用所有迁移SQL语句的文件。
## 5.3 SQL文件生成的最佳实践
为了确保SQL文件生成的效率和安全,我们需要遵循一些最佳实践。
### 5.3.1 性能优化技巧
性能优化是SQL文件生成中的一个重要方面。我们可以采取以下措施来优化性能:
1. **批量处理**:在执行自定义SQL时,使用批量处理可以减少数据库的I/O操作。
2. **事务控制**:使用事务可以确保SQL操作的原子性,减少锁竞争。
3. **索引优化**:在生成SQL之前,确保数据库表已经建立了合适的索引,以加快查询速度。
### 5.3.2 安全性考虑与最佳实践
在处理SQL文件生成时,安全性也是一个不容忽视的问题。以下是一些确保生成SQL文件安全性的最佳实践:
1. **使用参数化查询**:避免使用字符串拼接来构建SQL语句,以防止SQL注入攻击。
2. **限制权限**:为执行SQL的用户分配最低权限,防止不必要的数据库访问。
3. **代码审查**:对生成SQL文件的代码进行定期的代码审查,确保没有安全漏洞。
通过遵循这些最佳实践,我们不仅能够提高SQL文件生成的效率,还能够确保生成的SQL文件的安全性。
本章节介绍了自定义SQL文件生成规则、集成外部工具与扩展以及SQL文件生成的最佳实践。通过这些高级应用,我们可以更好地控制和优化Django项目中的数据库迁移过程。
# 6. Django SQL文件生成的疑难杂症排查
## 6.1 常见问题与解决方案
在使用Django生成SQL文件的过程中,可能会遇到各种各样的问题。以下是一些常见问题及其解决方案。
### 6.1.1 SQL文件生成失败的常见原因
SQL文件生成失败可能是由于多种原因导致的,例如:
- **数据库连接问题**:确保数据库服务运行正常,并且数据库连接信息正确无误。
- **模型定义错误**:模型中可能存在字段定义错误,如字段类型不支持或者缺失必要的参数。
- **迁移文件冲突**:迁移文件可能存在依赖问题或者文件损坏。
- **权限不足**:执行生成SQL文件的操作时,没有足够的权限访问数据库。
### 6.1.2 解决SQL文件内容不一致的问题
如果SQL文件生成后,发现文件内容与预期不一致,可以尝试以下步骤:
- **检查迁移记录**:确认所有的迁移记录都已经应用,并且迁移文件没有遗漏。
- **使用`--empty`选项**:如果需要重新生成SQL文件,可以使用`manage.py sqlsequencereset --empty <app_name>`命令来重置迁移序列。
- **手动编辑SQL文件**:对于一些特殊情况,可能需要手动编辑SQL文件来调整内容。
## 6.2 调试技巧与性能分析
在Django项目中,调试和性能分析是不可或缺的技能。以下是相关的技巧和方法。
### 6.2.1 Django调试工具的使用
Django提供了一些内置的调试工具,可以帮助开发者快速定位问题:
- **django-debug-toolbar**:这是一个非常有用的调试工具,可以提供请求的各种信息,如SQL查询、时间线等。
- **print()函数**:虽然简单,但是在紧急情况下,`print()`函数可以输出变量的信息,帮助开发者理解程序的运行状态。
- **Python pdb调试器**:使用Python自带的pdb调试器,可以逐步执行代码,查看变量值和执行流程。
### 6.2.2 SQL生成性能分析与调优
性能分析和调优是提高SQL文件生成效率的关键:
- **使用`--noinput`选项**:在生成SQL文件时,使用`--noinput`选项可以避免等待用户输入,从而提高效率。
- **分析SQL查询**:使用Django自带的`connection.queries`属性可以查看执行的SQL查询,找到可能的性能瓶颈。
- **优化模型查询**:在模型层面优化查询,使用`select_related`和`prefetch_related`来减少数据库查询次数。
## 6.3 社区资源与扩展阅读
对于遇到的难题,除了自行摸索,还可以利用社区资源和扩展阅读材料来寻找解决方案。
### 6.3.1 Django社区资源概览
Django社区提供了丰富的资源,包括:
- **官方文档**:Django官方文档是学习和解决问题的第一手资料。
- **Stack Overflow**:在Stack Overflow上搜索相关问题,通常可以找到现成的解决方案。
- **Django论坛**:Django官方论坛是交流问题和经验的好地方。
### 6.3.2 推荐的扩展阅读材料
以下是一些扩展阅读材料推荐:
- **《Django by Example》**:这本书通过实际案例讲解Django的使用,适合进阶学习。
- **《Two Scoops of Django》**:这本书包含了很多Django开发的最佳实践和技巧。
- **Django官方博客**:Django官方博客不定期发布新功能和技术文章,值得订阅。
通过以上的内容,我们可以看到在Django SQL文件生成的过程中可能会遇到的问题以及解决这些问题的方法,同时也提供了一些调试和性能分析的技巧,以及社区资源和扩展阅读的推荐。这些信息对于开发者来说是非常宝贵的,可以帮助他们更高效地完成任务。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Python邮件库学习之路】:email.mime.text的基本使用与案例分析

# 1. Python邮件库概述
Python作为一种编程语言,因其简洁易学、功能强大,在邮件处理方面也有着广泛的应用。其中,`email`库是Python标准库中的一个重要组件,它提供了丰富的工具来构建和解析邮件消息,包括文本邮件、HTML邮件以及附件等。`email.mime.text`作为`email`库中的一个子库,专门用于处理邮件文本内
【Tornado.options合并策略】:多环境配置管理的高级技巧

# 1. Tornado.options概览
在本章节中,我们将对Tornado.options进行一个初步的介绍,让读者了解这个模块的基本功能和应用场景。Tornado.options是一个用于处理配置的Python库,它提供了一种简单而强大的方式来定义和
【Lxml.html在网络安全中的应用】:网页内容监控与分析,专家教你保障网络安全
# 1. Lxml.html概述与安装
## 简介
Lxml.html是一个强大的库,用于解析和处理HTML和XML文档。它建立在libxml2和libxslt库之上,提供了一个简洁的API,使得HTML和XML的解析变得简单且高效。
## 安装
要开始使用Lxml.html,您需要先确保安装了Python和pip工具。接下来,使用pip安装lxml库:
【Django Signals与数据备份】:post_delete事件触发数据备份的策略和实现
# 1. Django Signals概述
在Web开发中,Django框架以其强大的功能和高效率而广受欢迎。Django Sig
【Mercurial代码审查实战】:Python库文件管理的变更集审查

# 1. Mercurial代码审查概述
## 1.1 代码审查的重要性
代码审查是一种质量保证手段,它涉及对源代码的系统性检查,旨在发现并修复错误、提高代码质量以及促进知识共享。通过审查,团队成员可以相互学习最佳实践,保持代码库的整洁和一致性。
## 1.
【Django GIS最佳实践】:提升GIS应用响应速度的5大技巧

# 1. Django GIS概述
## 1.1 Django GIS简介
Django GIS是一个集成地理信息系统(GIS)功能的Python框架,它允许开发者在Django项目中处理和展示地理数据。GIS技术的加入使得Web应用能够处理地图、空间查询和各种地理计算,从而扩展了其应用场景,比如
Genshi.Template性能测试:如何评估模板引擎的性能

# 1. 模板引擎性能测试概述
## 1.1 为什么进行性能测试?
在现代的Web开发中,模板引擎作为将数据与界面分离的重要工具,其性能直接影响到Web应用的响应速度和用户体验。随着业务的扩展和用户量的增加,模板引擎的性能问题会变得更加突出。因此,对模板引擎进行性能测
【win32process的内存管理】:Python中的内存优化与进程内存分析的秘籍
# 1. Win32Process内存管理概述
## 内存管理的重要性
在现代操作系统中,内存管理是确保系统稳定运行的关键因素之一。Win32Process,作为Windows操作系统的核心组成部分,提供了丰富的API来管理内存资源。对于开发者而言,理解内存管理的基本原理和方法,不仅能够帮助提高程序的性能,还能有效地预防内存泄漏等问题。
## 内存管理的基本概念
内
【Twisted并发编程技巧】:线程与进程协同工作的高级技巧
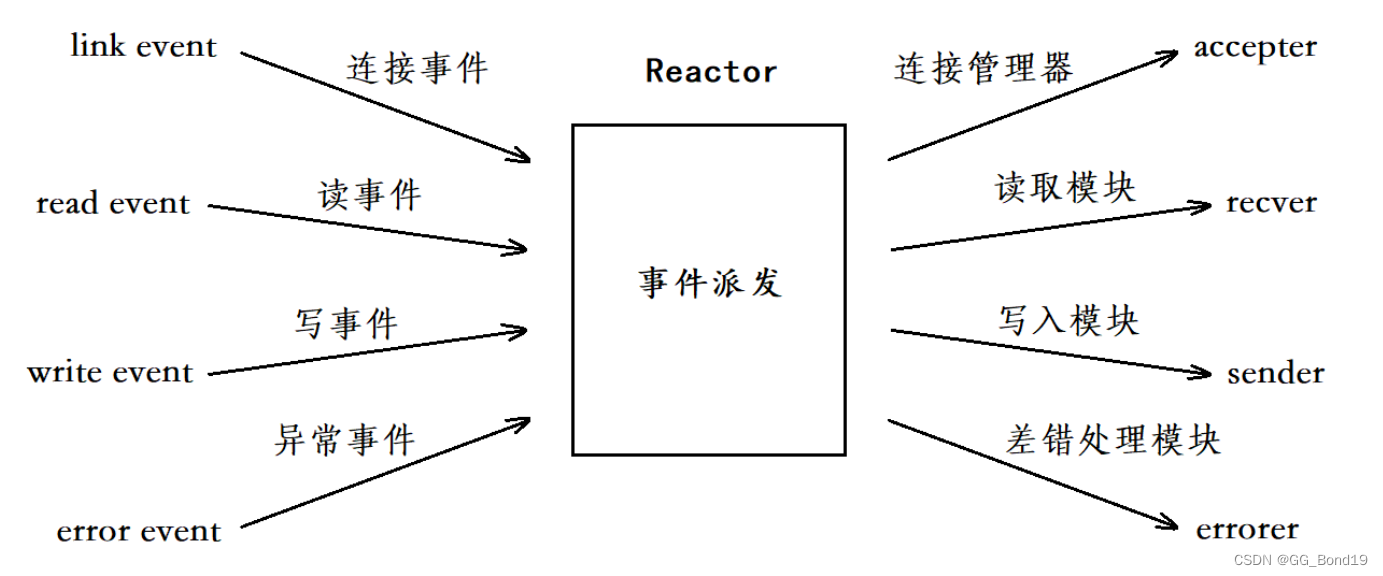
# 1. Twisted框架概述
## 1.1 Twisted框架简介
Twisted是一个开源的Python网络框架,专门用于构建网络应用程序。它采用了异步事件驱动模型,可以有效地处理大量并发连接,是构建高性能网络服务器的理想选择。
## 1.2 Twisted框架的历史和发展
Twisted起源于1999年,经过多年的迭代和发展,已经成为一个成熟稳定的网络框架。它支持多种网络协议,如TCP
Python Serial库与加密通信:保证数据传输安全性的最佳实践
# 1. Python Serial库基础
## 1.1 Serial库简介
Python Serial库是一个用于处理串口通信的库,它允许用户轻松地与串行端口设备进行交互。Serial库提供了简单易用的接口,可以实现串口数据的发送和接收,以及对串口设备进行配置等功能。
## 1.2 安装Serial库
在开始使用Serial库之前,需要先安装这个库。可以通过Python的包
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )