Django迁移中的数据迁移脚本编写:自动化流程详解
发布时间: 2024-10-14 03:07:53 阅读量: 35 订阅数: 30 

# 1. Django迁移概述
Django迁移是数据库模式的版本控制工具,它允许开发者以一种可重复且可持续的方式更改数据库架构,而无需手动修改数据库。这一功能极大地简化了数据库管理,并保证了团队成员之间的协作效率。在本章中,我们将首先了解Django迁移的基本概念,以及它如何帮助我们在开发过程中保持数据模型的同步。
Django迁移涉及到两个主要步骤:首先是模型(model)的变更,然后是这些变更通过迁移(migration)应用到数据库中。Django通过一个内置的迁移框架来跟踪和记录模型的变化,确保数据库结构的变更可以被追溯和重复。这不仅使得数据库的版本控制变得容易,而且还提高了项目的可维护性。
Django迁移流程涉及几个关键点:
- **模型定义**:在Django中,模型是表示数据库表的Python类,定义了数据的结构和字段。
- **自动生成迁移文件**:当模型发生变化时,Django可以自动生成迁移文件,记录了数据库需要进行的变更。
- **应用迁移**:迁移文件可以通过命令行工具应用到数据库,执行实际的数据库修改。
在接下来的章节中,我们将深入探讨如何定义Django模型,如何生成和应用迁移文件,以及如何管理迁移历史和版本。我们还将学习数据迁移脚本的核心概念,包括其结构、高级操作以及测试与验证。此外,我们将探索自动化数据迁移脚本的编写和优化,以及通过实战案例分析来更好地理解迁移脚本的应用。最后,我们将讨论数据迁移脚本的常见问题及其解决方案。
# 2. Django模型与迁移基础
## 2.1 Django模型的定义
在本章节中,我们将深入探讨Django模型的定义,这是理解和使用Django迁移的关键基础。Django模型是定义数据库中表的结构的Python类,它们位于应用的`models.py`文件中。每个模型都对应数据库中的一个表,每个模型的实例都对应表中的一行记录。
### 2.1.1 模型字段类型
Django为不同的数据类型提供了多种字段类型,每种字段类型对应数据库中的特定列类型。以下是一些常见的模型字段类型及其用途:
- `CharField`:用于存储短字符串,例如名字和姓氏。
- `IntegerField`:用于存储整数。
- `DateField`:用于存储日期(年月日)。
- `DateTimeField`:用于存储日期和时间。
- `EmailField`:用于存储电子邮件地址,提供了一些额外的验证。
- `ForeignKey`:用于定义与另一个模型的多对一关系。
- `ManyToManyField`:用于定义与另一个模型的多对多关系。
### 2.1.2 模型元数据选项
模型的元数据是关于模型的“元”信息,即模型本身的属性,而不是模型字段。这些选项允许你为模型设置额外的信息,例如排序方式、数据库表名等。以下是一些常用的模型元数据选项:
- `verbose_name`:模型的友好名称,用于在Django管理界面显示。
- `db_table`:指定模型对应的数据库表名。
- `ordering`:设置默认的排序方式,例如`ordering = ['name']`会按照name字段的字母顺序进行排序。
代码示例:
```python
from django.db import models
class Person(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
birth_date = models.DateField()
email = models.EmailField()
friends = models.ManyToManyField('self')
class Meta:
verbose_name = "Person"
db_table = "persons_table"
ordering = ['last_name', 'first_name']
```
在这个示例中,我们定义了一个`Person`模型,它具有`first_name`、`last_name`、`birth_date`和`email`字段,并且通过`Meta`类设置了模型的元数据。
## 2.2 迁移文件的生成与应用
Django迁移是Django的内置功能,允许模型的改变能够同步到数据库结构中,而不需要手动修改数据库。它通过生成迁移文件来记录模型的变更,并应用这些迁移文件来更新数据库。
### 2.2.1 自动生成迁移文件
当你在`models.py`中定义或修改模型后,可以通过Django的`makemigrations`命令来自动生成迁移文件。这个命令会检查你的模型定义,并生成必要的迁移代码。
```bash
python manage.py makemigrations
```
这个命令会生成一个新的迁移文件,例如`0001_initial.py`,在`migrations`文件夹中。迁移文件中包含了一个名为`Migration`的类,它记录了模型变更的信息。
### 2.2.2 迁移文件的应用和回滚
生成的迁移文件需要通过`migrate`命令应用到数据库中。如果需要撤销最近的一次迁移,可以使用`migrate`命令的`undo`选项。
```bash
python manage.py migrate
python manage.py migrate app_name zero
```
第一个命令会应用所有待定的迁移,第二个命令会回滚到指定应用的最新迁移。`app_name`是你应用的名称。
## 2.3 迁移历史和版本控制
Django迁移不仅记录了模型的变更,还记录了迁移的历史。这意味着你可以查看模型的变更历史,并且可以回退到之前的版本。
### 2.3.1 迁移历史记录
迁移历史记录存储在数据库的`django_migrations`表中。你可以通过Django管理界面或者直接查询这个表来查看迁移历史。
```sql
SELECT * FROM django_migrations;
```
这个SQL查询会返回所有迁移的历史记录,包括应用的名称和迁移的名称。
### 2.3.2 迁移版本的管理
如果你需要管理迁移的版本,可以使用`migrate`命令的`--fake`选项。这个选项可以标记迁移已应用,但不会实际在数据库中执行迁移操作。
```bash
python manage.py migrate app_name migration_name --fake
```
这个命令会将指定的迁移标记为已应用,适用于那些由于某些原因无法实际执行迁移的情况。
在本章节中,我们介绍了Django模型的定义,包括模型字段类型和模型元数据选项。我们还讨论了如何自动生成迁移文件以及如何应用和回滚迁移。最后,我们了解了如何查看迁移历史和管理迁移版本。这些知识是理解和使用Django迁移的基础,也是接下来章节内容的铺垫。
# 3. 数据迁移脚本的核心概念
在本章节中,我们将深入探讨数据迁移脚本的核心概念,包括其结构、高级操作以及测试与验证的重要性。理解这些概念对于编写高效、可靠的迁移脚本至关重要。
## 3.1 数据迁移脚本的结构
数据迁移脚本是Django迁移系统的重要组成部分,它定义了如何在数据库中移动数据。一个典型的迁移脚本包含两个主要部分:数据迁移类的定义和数据迁移操作的执行。
### 3.1.1 数据迁移类的定义
数据迁移类通常继承自`migrations.Migration`,它定义了迁移的元数据和依赖关系。以下是一个数据迁移类的示例:
```python
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('app_name', 'previous_migration_file'),
]
operations = [
migrations.RunPython(copy_data_from_source_to_target),
]
```
在这个示例中,`dependencies`属性指定了当前迁移依赖的迁移文件,确保迁移按正确的顺序执行。`operations`列表包含了迁移操作,`migrations.RunPython`操作用于执行Python函数`copy_data_from_source_to_target`,该函数定义了数据迁移的具体逻辑。
### 3.1.2 数据迁移操作的执行
数据迁移操作可以是任何Python代码,但通常会使用Django提供的辅助函数来处理数据。以下是`copy_data_from_source_to_target`函数的示例:
```python
def copy_data_from_source_to_target(apps, schema_editor):
SourceModel = apps.get_model('app_name', 'SourceModel')
TargetModel = apps.get_model('app_name', 'TargetModel')
for source_obj in SourceModel.objects.all():
target_obj = TargetModel.objects.create(
field1=source_obj.field1,
field2=source_obj.field2,
)
target_obj.save()
```
在这个函数中,我们首先通过`apps.get_model`获取了源模型和目标模型的引用。然后,我们遍历源模型的所有实例,并为每个实例创建一个目标模型的新实例。
### *.*.*.* 代码逻辑解读分析
- `apps.get_model`:这个函数用于获取模型的引用,即使在迁移中也可以使用。
- `SourceModel.objects.all()`:获取源模型的所有实例。
- `TargetModel.objects.create()`:为每个源实例创建一个新的目标模型实例。
- `target_obj.save()`:保存新创建的目标模型实例。
## 3.2 数据迁移脚本中的高级操作
数据迁移脚本可以处理复杂的数据关系,并且能够进行错误处理,以确保数据迁移的准确性和鲁棒性。
### 3.2.1 复杂数据关系的处理
处理复杂数据关系时,可能需要编写更复杂的逻辑。例如,你可能需要处理多对多关系或处理外键约束。以下是一个处理多对多关系的示例:
```python
def handle_m2m(apps, schema_editor):
SourceModel = apps.get_model('app_name', 'SourceModel')
TargetModel = apps.get_model('app_name', 'TargetModel')
m2m_field = SourceModel._meta.get_field('m2m_field')
for source_obj in SourceModel.objects.all():
target_obj = TargetModel.objects.create(
field1=source_obj.field1,
)
target_obj.m2m_field.add(*source_obj.m2m_field.all())
target_obj.save(
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Django SQL 文件学习专栏!本专栏将深入探讨 django.core.management.sql 模块,为您提供全面且深入的指南。我们将揭秘 SQL 文件生成的策略,掌握自定义 SQL 输出的技巧,了解 Django 迁移命令背后的 SQL 逻辑,并分享专家级最佳实践。通过案例分析和实战应用,您将了解 Django 数据库迁移与 SQL 文件管理的精髓。此外,我们还将探讨 SQL 优化、日志记录、数据备份和性能影响等重要主题。本专栏旨在帮助您掌握 django.core.management.sql 模块,并提升您的 Django 数据库迁移技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
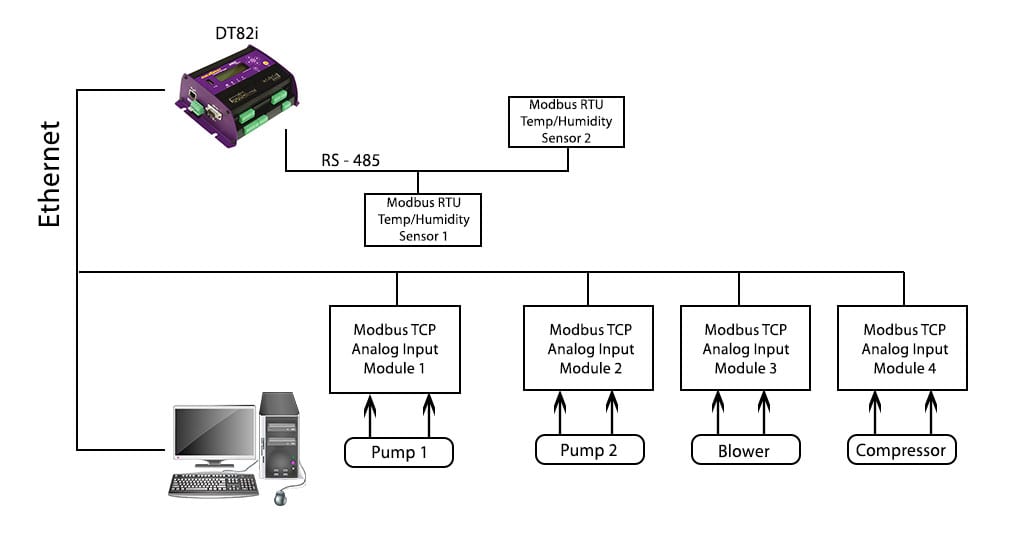
NModbus性能优化:提升Modbus通信效率的5大技巧
# 摘要
本文综述了NModbus性能优化的各个方面,包括理解Modbus通信协议的历史、发展和工作模式,以及NModbus基础应用与性能瓶颈的分析。文中探讨了性能瓶颈常见原因,如网络延迟、数据处理效率和并发连接管理,并提出了多种优化技巧,如缓存策略、批处理技术和代码层面的性能改进。文章还通过工业自动化系统的案例分析了优化实施过程和结果,包括性能对比和稳定性改进。最后,本文总结了优化经验,展望了NModbus性能优化技术的发展方向。
【Java开发者效率利器】:Eclipse插件安装与配置秘籍

# 摘要
Eclipse插件开发是扩展IDE功能的重要途径,本文对Eclipse插件开发进行了全面概述。首先介绍了插件的基本类型、架构及安装过程,随后详述了提升Java开发效率的实用插件,并探讨了高级配置技巧,如界面自定义、性能优化和安全配置。第五章讲述了开发环境搭建、最佳实践和市场推广策略。最后,文章通过案例研究,分析了成功插件的关键因素,并展望了未来发展趋势和面临的技
【性能测试:基础到实战】:上机练习题,全面提升测试技能

# 摘要
随着软件系统复杂度的增加,性能测试已成为确保软件质量不可或缺的一环。本文从理论基础出发,深入探讨了性能测试工具的使用、定制和调优,强调了实践中的测试环境构建、脚本编写、执行监控以及结果分析的重要性。文章还重点介绍了性能瓶颈分析、性能优化策略以及自动化测试集成的方法,并展望了
SECS-II调试实战:高效问题定位与日志分析技巧

# 摘要
SECS-II协议作为半导体设备通信的关键技术,其基础与应用环境对提升制造自动化与数据交换效率至关重要。本文详细解析了SECS-II消息的类型、格式及交换过程,包括标准与非标准消息的处理、通信流程、流控制和异常消息的识别。接着,文章探讨了SECS-II调试技巧与工具,从调试准备、实时监控、问题定位到日志分析
Redmine数据库升级深度解析:如何安全、高效完成数据迁移

# 摘要
随着信息技术的发展,项目管理工具如Redmine的需求日益增长,其数据库升级成为确保系统性能和安全的关键环节。本文系统地概述了Redmine数据库升级的全过程,包括升级前的准备工作,如数据库评估、选择、数据备份以及风险评估。详细介绍了安全迁移步骤,包括
YOLO8在实时视频监控中的革命性应用:案例研究与实战分析

# 摘要
YOLO8作为一种先进的实时目标检测模型,在视频监控应用中表现出色。本文概述了YOLO8的发展历程和理论基础,重点分析了其算法原理、性能评估,以及如何在实战中部署和优化。通过探讨YOLO8在实时视频监控中的应用案例,本文揭示了它在不同场景下的性能表现和实际应用,同时提出了系统集成方法和优化策略。文章最后展望了YOLO8的未来发展方向,并讨论了其面临的挑战,包括数据隐私和模型泛化能力等问题。本文旨在为研究人员和工程技术人员提供YOLO8
UL1310中文版深入解析:掌握电源设计的黄金法则

# 摘要
电源设计在确保电气设备稳定性和安全性方面发挥着关键作用,而UL1310标准作为重要的行业准则,对于电源设计的质量和安全性提出了具体要求。本文首先介绍了电源设计的基本概念和重要性,然后深入探讨了UL1310标准的理论基础、主要内容以及在电源设计中的应用。通过案例分析,本文展示了UL1310标准在实际电源设计中的实践应用,以及在设计、生产、测试和认证各阶段所面
Lego异常处理与问题解决:自动化测试中的常见问题攻略

# 摘要
本文围绕Lego异常处理与自动化测试进行深入探讨。首先概述了Lego异常处理与问题解决的基本理论和实践,随后详细介绍了自动化测试的基本概念、工具选择、环境搭建、生命周期管理。第三章深入探讨了异常处理的理论基础、捕获与记录方法以及恢复与预防策略。第四章则聚焦于Lego自动化测试中的问题诊断与解决方案,包括测试脚本错误、数据与配置管理,以及性
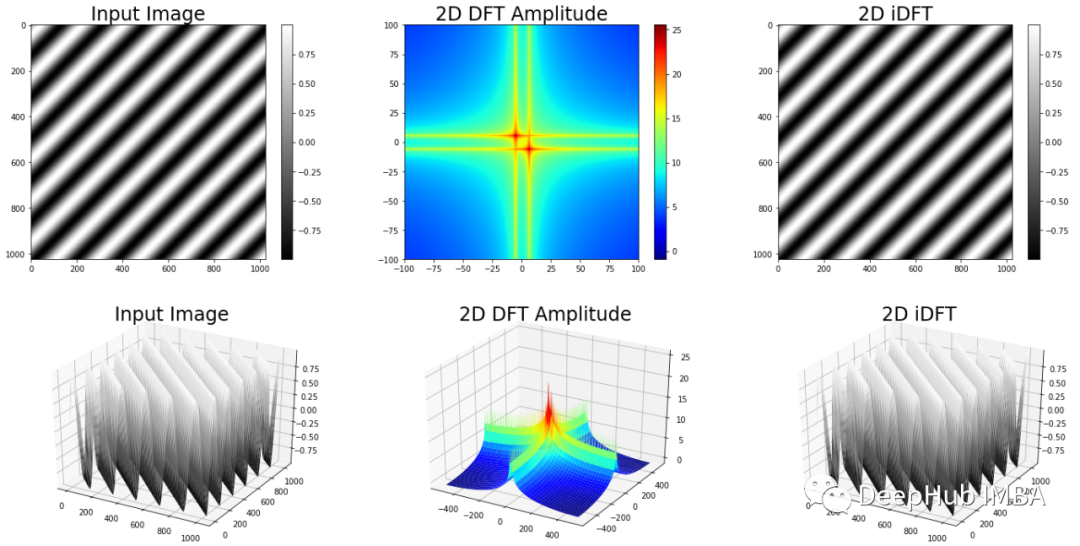
【Simulink频谱分析:立即入门】
# 摘要
本文系统地介绍了Simulink在频谱分析中的应用,涵盖了从基础原理到高级技术的全面知识体系。首先,介绍了Simulink的基本组件、建模环境以及频谱分析器模块的使用。随后,通过多个实践案例,如声音信号、通信信号和RF信号的频谱分析,展示了Simulink在不同领域的实际应用。此外,文章还深入探讨了频谱分析参数的优化,信号处理工具箱的使用,以及实时频谱分析与数据采
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )