MapReduce原理与编程模型详解
发布时间: 2024-03-06 12:05:31 阅读量: 28 订阅数: 24 
# 1. MapReduce概述
### 1.1 MapReduce概念与发展历程
MapReduce是一种分布式计算框架,最初由Google提出并用于分布式计算和处理大规模数据。随着大数据技术的快速发展,MapReduce框架逐渐成为处理海量数据的重要工具之一。其发展历程可以追溯到2004年Google发表的一篇论文《MapReduce: Simplified Data Processing on Large Clusters》。
### 1.2 MapReduce的核心思想与原理
MapReduce的核心思想是将大规模数据集进行分布式处理和计算。它采用了分而治之的思想,将数据集分成若干个小块,并通过Map和Reduce两个阶段进行处理和汇总,从而实现并行化的计算。
### 1.3 MapReduce的典型应用场景
MapReduce广泛应用于各种大数据处理场景,包括数据挖掘、日志分析、搜索引擎等领域。通过MapReduce框架,可以高效处理海量数据并进行并行计算,极大地提高了数据处理和分析的效率和速度。
# 2. MapReduce编程模型
MapReduce编程模型是一种用于分布式计算的编程框架,它将大规模数据集分成小的数据块,并在集群中的多台计算机上并行处理这些数据块。本章将深入探讨MapReduce编程模型的基本概念、数据流程、执行过程、任务调度以及数据分片等内容。
### 2.1 MapReduce编程模型的基本概念
在MapReduce编程模型中,主要包括两个关键阶段:Map阶段和Reduce阶段。Map阶段负责将输入数据集转换成键值对的形式,并生成中间结果;Reduce阶段则负责对Map阶段输出的中间结果进行合并和计算,最终生成最终的输出结果。这种分而治之的思想使得MapReduce能够有效地处理大规模数据集。
### 2.2 MapReduce编程模型的数据流程
MapReduce编程模型中的数据流程通常遵循以下步骤:
1. 输入数据的切分:将大规模数据集划分成小的数据块。
2. Map阶段的并行处理:对每个数据块进行Map函数的并行处理,生成中间键值对。
3. Shuffle阶段:将Map阶段输出的中间结果按照键进行排序,并将具有相同键的值聚合在一起。
4. Reduce阶段的并行处理:对Shuffle阶段输出的键值对进行Reduce函数的并行处理,生成最终输出结果。
### 2.3 MapReduce编程模型的执行过程
MapReduce编程模型的执行过程主要包括以下几个步骤:
1. Job的提交:将MapReduce作业提交到集群中的Master节点。
2. Job的划分:Master节点将作业划分成多个Task,包括Map Task和Reduce Task。
3. Task的分配:Master节点将各个Task分配给集群中的Worker节点进行处理。
4. 任务的执行:Worker节点执行具体的Map和Reduce任务,并将中间结果写入临时文件。
5. 任务的汇总:Master节点负责将各个Worker节点的中间结果汇总,并生成最终输出结果。
### 2.4 MapReduce编程模型的任务调度与数据分片
MapReduce框架通过任务调度器负责将作业分成多个独立的任务,并将这些任务分配给集群中的不同节点执行。同时,MapReduce框架还会将输入数据集进行切分,并将切分后的数据块分配给不同的Map Task进行处理,以实现数据的并行处理和分布式计算。
通过以上内容的讲解,读者可以对MapReduce编程模型有一个更深入的了解,包括其基本概念、数据流程、执行过程以及任务调度与数据分片等方面。在接下来的章节中,我们将进一步探讨MapReduce中的Map阶段和Reduce阶段的具体实现细节。
# 3. MapReduce中的Map阶段
在MapReduce编程模型中,Map阶段是数据处理的第一步,主要负责将输入数据处理成键值对的形式,以便后续的Reduce阶段进行处理。本章将深入探讨Map阶段的数据处理流程、Map函数的设计与实现以及Map阶段的数据局部性与并行处理。
#### 3.1 Map阶段的数据处理流程
Map阶段的数据处理流程如下所示:
1. 输入数据被切分为若干个数据块。
2. 每个数据块通过Map函数处理,生成中间键值对。
3. 中间键值对根据键被分配到不同的Partition中。
4. 同一Partition中的键值对被送往相应的Reducer进行进一步处理。
#### 3.2 Map函数的设计与实现
Map函数是Map阶段的核心,在MapReduce编程模型中负责将输入数据转换为中间键值对。以下是Python语言中Map函数的简单实现:
```python
def map_function(input_key, input_value):
# 对输入数据进行处理,生成中间键值对
for word in input_value.split():
yield (word, 1)
```
在上述代码中,map_function函数接受输入的键值对input_key和input_value,将inpu

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PDF文档版本控制】:使用Java库进行PDF版本管理,版本控制轻松掌握

# 1. PDF文档版本控制概述
在数字信息时代,文档管理成为企业与个人不可或缺的一部分。特别是在法律、财务和出版等领域,维护文档的历史版本、保障文档的一致性和完整性,显得尤为重要。PDF文档由于其跨平台、不可篡改的特性,成为这些领域首选的文档格式
【大数据处理】:结合Hadoop_Spark轻松处理海量Excel数据
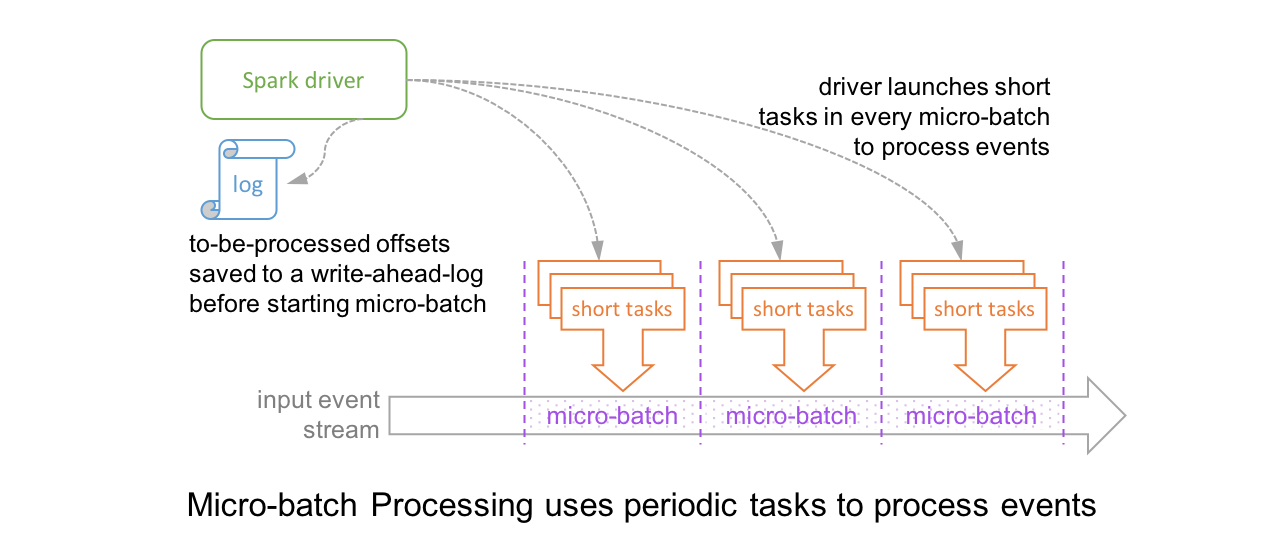
# 1. 大数据与分布式计算基础
## 1.1 大数据时代的来临
随着信息技术的快速发展,数据量呈爆炸式增长。大数据不再只是一个时髦的概念,而是变成了每个企业与组织无法忽视的现实。它在商业决策、服务个性化、产品优化等多个方面发挥着巨大作用。
## 1.2 分布式计算的必要性
面对如此庞大且复杂的数据,传统单机计算已无法有效处理。分布式计算作为一种能够将任务分散到多台计算机上并行处
Web应用中的Apache FOP:前后端分离架构下的转换实践

# 1. Apache FOP简介和架构基础
## 1.1 Apache FOP概述
Apache FOP(Form
Linux Mint 22用户账户管理
# 1. Linux Mint 22用户账户管理概述
Linux Mint 22,作为Linux社区中一个流行的发行版,以其用户友好的特性获得了广泛的认可。本章将简要介绍Linux Mint 22用户账户管理的基础知识,为读者在后续章节深入学习用户账户的创建、管理、安全策略和故障排除等高级主题打下坚实的基础。用户账户管理不仅仅是系统管理员的日常工作之一,也是确保Linux Mint 22系统安全和资源访问控制的关键组成
Linux Mint Debian版内核升级策略:确保系统安全与最新特性

# 1. Linux Mint Debian版概述
Linux Mint Debian版(LMDE)是基于Debian稳定分支的一个发行版,它继承了Linux Mint的许多优秀特性,同时提供了一个与Ubuntu不同的基础平台。本章将简要介绍LMDE的特性和优势,为接下来深入了解内核升级提供背景知识。
## 1.1 Linux Min
Rufus Linux基础教程:全方位指南助你轻松安装与配置
# 1. Linux基础知识介绍
Linux操作系统是开源的,拥有高度的灵活性和强大的自定义能力。它源自UNIX,由芬兰学生Linus Torvalds于1991年首次发布。如今,Linux发展成为各种企业服务器和个人计算机上使用的主流操作系统之一。
在Linux世界中,发行版(Distribution)是预装软件包的Linux内核版本。不同的发行版针对不同的用户群、应
前端技术与iText融合:在Web应用中动态生成PDF的终极指南
# 1. 前端技术与iText的融合基础
## 1.1 前端技术概述
在现代的Web开发领域,前端技术主要由HTML、CSS和JavaScript组成,这三者共同构建了网页的基本结构、样式和行为。HTML(超文本标记语言)负责页面的内容结构,CSS(层叠样式表)定义页面的视觉表现,而J
数据库连接池实战演练:Spring Boot中的HikariCP配置优化秘籍

# 1. 数据库连接池概念与HikariCP简介
在本章中,我们将深入了解数据库连接池的概念,并介绍HikariCP这一流行的Java连接池实现。数据库连接池是一种常用的连接管理技术,旨在提高应用程序与数据库交互的性能。它通过重用和管理数据
【Linux Mint XFCE自定义主题与图标打造】:桌面风格个性化完全手册
# 1. Linux Mint XFCE桌面环境概述
Linux Mint XFCE是Linux Mint操作系统的一个轻量级版本,它以轻快稳定著称,非常适合硬件资源有限的老旧计算机使用。XFCE桌面环境是一套简单易用的桌面解决方案,它不仅提供了丰富的定制选项,同时也保持了对系统资源的高效利用。作为Linux Mint系列中的一个分支,XFCE版本继承了Min
【Linux Mint Cinnamon性能监控实战】:实时监控系统性能的秘诀

# 1. Linux Mint Cinnamon系统概述
## 1.1 Linux Mint Cinnamon的起源
Linux Mint Cinnamon是一个流行的桌面发行版,它是基于Ubuntu或Debian的Linux系统,专为提供现代、优雅而又轻量级的用户体验而设计。Cinnamon界面注重简洁性和用户体验,通过直观的菜单和窗口管理器,为用户提供高效的工作环境。
#
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )