【SQL数据库基础】:从零构建数据王国,掌握数据存储的奥秘
发布时间: 2024-07-23 08:28:38 阅读量: 32 订阅数: 37 
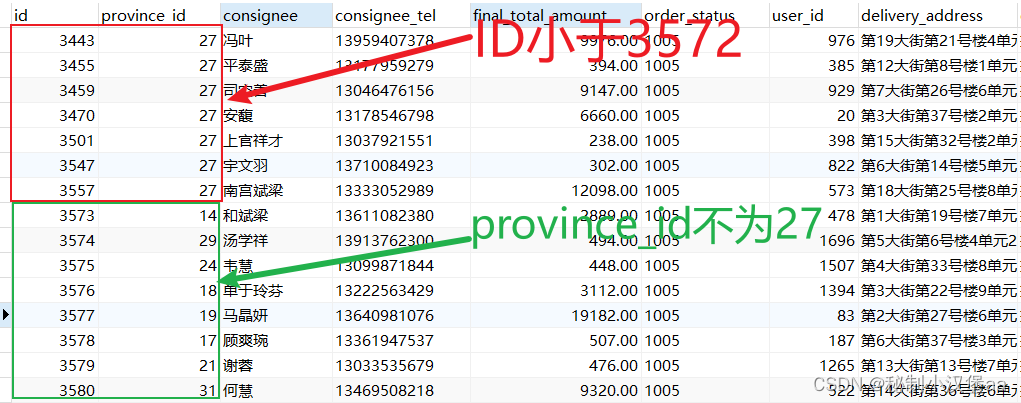
# 1. SQL数据库基础**
### 1.1 什么是SQL数据库?
SQL(结构化查询语言)数据库是一种关系型数据库管理系统,用于存储和管理结构化数据。它由一系列表组成,每个表由行和列组成,代表实体和属性。SQL数据库支持数据完整性、数据查询和数据操作。
### 1.2 SQL数据库的优势和应用场景
**优势:**
* **结构化数据:**数据以预定义的模式存储,便于组织和检索。
* **数据完整性:**约束和规则确保数据的准确性和一致性。
* **查询灵活性:**SQL提供强大的查询语言,可高效检索和处理数据。
**应用场景:**
* **事务处理:**在线交易、库存管理、订单处理。
* **数据分析:**商业智能、数据挖掘、客户细分。
* **数据存储:**文档管理、媒体库、用户数据。
# 2. SQL数据类型和表结构
### 2.1 数据类型概述
SQL数据库中,数据类型定义了数据的值的类型和格式。选择合适的数据类型对于优化数据库性能和数据完整性至关重要。
### 2.2 常用数据类型
**数值类型**
* **INTEGER:**整数,没有小数部分。
* **FLOAT:**浮点数,带小数部分。
* **DOUBLE:**双精度浮点数,精度更高。
* **DECIMAL:**定点小数,精度和范围由用户指定。
**字符串类型**
* **CHAR:**固定长度字符串,用空格填充至指定长度。
* **VARCHAR:**可变长度字符串,仅存储实际数据。
* **TEXT:**用于存储大文本数据。
**日期和时间类型**
* **DATE:**日期,不含时间。
* **TIME:**时间,不含日期。
* **DATETIME:**日期和时间。
* **TIMESTAMP:**日期和时间,带时区信息。
**布尔类型**
* **BOOLEAN:**布尔值,表示真或假。
### 2.3 表结构设计
表结构定义了表中数据的组织方式。它包括以下元素:
**字段:**表的列,每个字段都有一个名称和数据类型。
**主键:**唯一标识表中每行的字段或字段组合。
**外键:**引用另一个表的主键的字段。
**约束:**限制表中数据的规则,例如唯一性约束、非空约束和外键约束。
### 2.4 主键、外键和约束
**主键**
主键是唯一标识表中每行的字段或字段组合。它确保表中没有重复的数据。
**外键**
外键是引用另一个表的主键的字段。它建立两个表之间的关系,确保数据的一致性。
**约束**
约束是限制表中数据的规则。常见约束包括:
* **唯一性约束:**确保字段值在表中唯一。
* **非空约束:**确保字段不为空。
* **外键约束:**确保外键值在引用的表中存在。
**示例:**
```sql
CREATE TABLE customers (
customer_id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL,
PRIMARY KEY (customer_id)
);
CREATE TABLE orders (
order_id INT NOT NULL AUTO_INCREMENT,
customer_id INT NOT NULL,
product_id INT NOT NULL,
quantity INT NOT NULL,
PRIMARY KEY (order_id),
FOREIGN KEY (customer_id) REFERENCES customers (customer_id),
FOREIGN KEY (product_id) REFERENCES products (product_id)
);
```
在这个示例中,`customers` 表的主键是 `customer_id`,`orders` 表的外键是 `customer_id`,它引用 `customers` 表的主键。
# 3. 更新和删除
**数据插入**
`INSERT INTO` 语句用于向表中插入新数据。其语法如下:
```sql
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
```
其中:
* `table_name` 是要插入数据的表名。
* `column1`, `column2`, ... 是要插入数据的列名。
* `value1`, `value2`, ... 是要插入数据的具体值。
**示例:**
向 `users` 表中插入一条新数据:
```sql
INSERT INTO users (name, age, email)
VALUES ('John Doe', 30, 'john.doe@example.com');
```
**数据更新**
`UPDATE` 语句用于更新表中已有的数据。其语法如下:
```sql
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
```
其中:
* `table_name` 是要更新数据的表名。
* `column1`, `column2`, ... 是要更新的列名。
* `value1`, `value2`, ... 是要更新的具体值。
* `condition` 是更新数据的条件。
**示例:**
更新 `users` 表中 `name` 为 `John Doe` 的用户的年龄:
```sql
UPDATE users
SET age = 31
WHERE name = 'John Doe';
```
**数据删除**
`DELETE` 语句用于从表中删除数据。其语法如下:
```sql
DELETE FROM table_name
WHERE condition;
```
其中:
* `table_name` 是要删除数据的表名。
* `condition` 是删除数据的条件。
**示例:**
从 `users` 表中删除 `name` 为 `John Doe` 的用户:
```sql
DELETE FROM users
WHERE name = 'John Doe';
```
### 3.2 查询数据
**基本查询**
`SELECT` 语句用于从表中查询数据。其语法如下:
```sql
SELECT column1, column2, ...
FROM table_name
WHERE condition;
```
其中:
* `column1`, `column2`, ... 是要查询的列名。
* `table_name` 是要查询数据的表名。
* `condition` 是查询数据的条件。
**示例:**
查询 `users` 表中所有用户的姓名和年龄:
```sql
SELECT name, age
FROM users;
```
**过滤数据**
`WHERE` 子句用于过滤查询结果。它可以根据指定的条件筛选出符合要求的数据。
**示例:**
查询 `users` 表中年龄大于 30 岁的用户:
```sql
SELECT name, age
FROM users
WHERE age > 30;
```
**排序数据**
`ORDER BY` 子句用于对查询结果进行排序。它可以根据指定的列对数据进行升序或降序排序。
**示例:**
查询 `users` 表中所有用户,并按年龄升序排序:
```sql
SELECT name, age
FROM users
ORDER BY age ASC;
```
### 3.3 数据过滤和排序
**数据过滤**
`WHERE` 子句用于过滤查询结果,只返回满足指定条件的数据。其语法如下:
```sql
WHERE condition;
```
其中,`condition` 可以是以下几种类型:
* **比较运算符:** `=`, `!=`, `<`, `>`, `<=`, `>=`
* **逻辑运算符:** `AND`, `OR`, `NOT`
* **组合运算符:** `()`, `IN`, `BETWEEN`
**示例:**
查询 `users` 表中年龄大于 30 岁的用户:
```sql
SELECT name, age
FROM users
WHERE age > 30;
```
**数据排序**
`ORDER BY` 子句用于对查询结果进行排序,其语法如下:
```sql
ORDER BY column_name [ASC | DESC];
```
其中,`column_name` 是要排序的列名,`ASC` 表示升序,`DESC` 表示降序。
**示例:**
查询 `users` 表中所有用户,并按年龄升序排序:
```sql
SELECT name, age
FROM users
ORDER BY age ASC;
```
### 3.4 数据分组和聚合
**数据分组**
`GROUP BY` 子句用于将查询结果按指定的列分组,其语法如下:
```sql
GROUP BY column_name;
```
其中,`column_name` 是要分组的列名。
**示例:**
查询 `users` 表中每个年龄段的用户数量:
```sql
SELECT age, COUNT(*) AS count
FROM users
GROUP BY age;
```
**聚合函数**
聚合函数用于对分组后的数据进行聚合计算,其语法如下:
```sql
aggregate_function(column_name)
```
其中,`aggregate_function` 可以是以下几种类型:
* `COUNT()`: 统计行数
* `SUM()`: 求和
* `AVG()`: 求平均值
* `MIN()`: 求最小值
* `MAX()`: 求最大值
**示例:**
查询 `users` 表中每个年龄段的平均年龄:
```sql
SELECT age, AVG(age) AS avg_age
FROM users
GROUP BY age;
```
# 4. SQL数据定义语言(DDL)**
DDL(Data Definition Language)是SQL中用于创建、修改和删除数据库对象(如数据库、表、索引、视图和存储过程)的语言。它允许数据库管理员和开发人员定义和管理数据库结构。
### 4.1 创建和修改数据库
**创建数据库**
```sql
CREATE DATABASE database_name;
```
**修改数据库**
```sql
ALTER DATABASE database_name
[SET | RESET] option_name = option_value;
```
### 4.2 创建和修改表
**创建表**
```sql
CREATE TABLE table_name (
column_name data_type [NOT NULL] [DEFAULT default_value],
...
[PRIMARY KEY (column_name)],
[FOREIGN KEY (column_name) REFERENCES other_table(column_name)]
);
```
**修改表**
```sql
ALTER TABLE table_name
[ADD | DROP | MODIFY] column_name data_type [NOT NULL] [DEFAULT default_value];
```
### 4.3 创建和修改索引
**创建索引**
```sql
CREATE INDEX index_name ON table_name (column_name);
```
**修改索引**
```sql
ALTER INDEX index_name ON table_name
[REBUILD | RENAME TO new_index_name];
```
### 4.4 视图和存储过程
**创建视图**
```sql
CREATE VIEW view_name AS
SELECT column_list
FROM table_name
WHERE condition;
```
**创建存储过程**
```sql
CREATE PROCEDURE procedure_name (
[IN | OUT | INOUT] parameter_name data_type
)
AS
BEGIN
-- 存储过程代码
END;
```
**代码逻辑逐行解读:**
* `CREATE VIEW view_name AS`: 创建名为`view_name`的视图。
* `SELECT column_list`: 指定要从视图中选择的列。
* `FROM table_name`: 指定视图基于哪个表。
* `WHERE condition`: 可选,指定视图的过滤条件。
* `CREATE PROCEDURE procedure_name`: 创建名为`procedure_name`的存储过程。
* `[IN | OUT | INOUT] parameter_name data_type`: 指定存储过程的参数,包括参数名、数据类型和参数类型(输入、输出或输入输出)。
* `AS`: 存储过程代码的开始。
* `BEGIN`: 存储过程代码的主体。
* `END;`: 存储过程代码的结束。
**参数说明:**
* `database_name`: 要创建或修改的数据库的名称。
* `table_name`: 要创建或修改的表的名称。
* `column_name`: 要创建、修改或删除的列的名称。
* `data_type`: 列的数据类型。
* `NOT NULL`: 指定列不允许为NULL值。
* `DEFAULT default_value`: 指定列的默认值。
* `PRIMARY KEY`: 指定列为主键。
* `FOREIGN KEY`: 指定列为外键,并引用另一个表中的列。
* `index_name`: 要创建或修改的索引的名称。
* `view_name`: 要创建的视图的名称。
* `column_list`: 要从视图中选择的列的列表。
* `condition`: 视图的过滤条件。
* `procedure_name`: 要创建的存储过程的名称。
* `parameter_name`: 存储过程的参数名。
* `data_type`: 存储过程参数的数据类型。
* `parameter_type`: 存储过程参数的类型(输入、输出或输入输出)。
# 5.1 用户管理和权限控制
### 用户管理
在SQL数据库中,用户管理是至关重要的,它允许管理员创建、修改和删除用户,并授予或撤销他们的权限。
```sql
-- 创建用户
CREATE USER [用户名] WITH PASSWORD '[密码]';
-- 修改用户密码
ALTER USER [用户名] WITH PASSWORD '[新密码]';
-- 删除用户
DROP USER [用户名];
```
### 权限控制
权限控制决定了用户可以对数据库执行哪些操作。SQL数据库提供了细粒度的权限控制,允许管理员授予或撤销对特定对象(如表、视图、存储过程)的特定权限。
```sql
-- 授予权限
GRANT [权限] ON [对象] TO [用户名];
-- 撤销权限
REVOKE [权限] ON [对象] FROM [用户名];
```
权限类型包括:
* **SELECT**:允许用户查询数据
* **INSERT**:允许用户插入数据
* **UPDATE**:允许用户更新数据
* **DELETE**:允许用户删除数据
* **CREATE**:允许用户创建对象
* **ALTER**:允许用户修改对象
* **DROP**:允许用户删除对象
### 最佳实践
为了确保数据库安全,建议遵循以下最佳实践:
* 使用强密码并定期更改。
* 授予用户最低必要的权限。
* 定期审核用户权限。
* 使用角色管理权限,而不是直接授予用户权限。
* 启用审计功能以跟踪用户活动。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**SQL 数据库基础教程**
本教程从零开始,全面介绍 SQL 数据库的基础知识,帮助您构建数据王国,掌握数据存储的奥秘。涵盖 SQL 数据类型、表结构设计、查询、插入、更新、删除、聚合函数、索引原理、事务管理、备份与恢复、视图、存储过程、性能调优、索引优化、查询优化、死锁问题分析与解决、连接池详解、注入攻击防范等核心概念。深入浅出,理论与实践相结合,让您轻松掌握 SQL 数据库的精髓,为数据分析、数据管理和应用程序开发奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
TSPL2高级打印技巧揭秘:个性化格式与样式定制指南

# 摘要
TSPL2打印语言作为工业打印领域的重要技术标准,具备强大的编程能力和灵活的控制指令,广泛应用于各类打印设备。本文首先对TSPL2打印语言进行概述,详细介绍其基本语法结构、变量与数据类型、控制语句等基础知识。接着,探讨了TSPL2在高级打印技巧方面的应用,包括个性化打印格式设置、样
JFFS2文件系统设计思想:源代码背后的故事
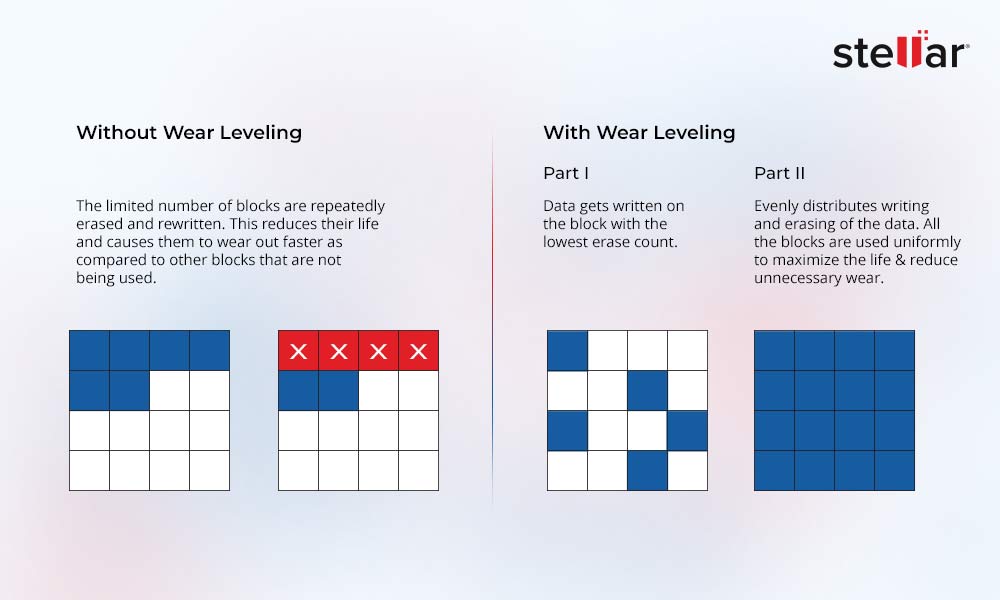
# 摘要
本文对JFFS2文件系统进行了全面的概述和深入的分析。首先介绍了JFFS2文件系统的基本理论,包括文件系统的基础概念和设计理念,以及其核心机制,如红黑树的应用和垃圾回收机制。接着,文章深入剖析了JFFS2的源代码,解释了其结构和挂载过程,以及读写操作的实现原理。此外,针对JFFS2的性能优化进行了探讨,分析了性能瓶颈并提出了优化策略。在此基础上,本文还研究了J
EVCC协议版本兼容性挑战:Gridwiz更新维护攻略

# 摘要
本文对EVCC协议进行了全面的概述,并探讨了其版本间的兼容性问题,这对于电动车充电器与电网之间的有效通信至关重要。文章分析了Gridwiz软件在解决EVCC兼容性问题中的关键作用,并从理论和实践两个角度深入探讨了Gridwiz的更新维护策略。本研究通过具体案例分析了不同EVCC版本下Gridwiz的应用,并提出了高级维护与升级技巧。本文旨在为相关领域的工程师和开发者提供有关EVCC协议及其兼容性维护
计算机组成原理课后答案解析:张功萱版本深入理解

# 摘要
计算机组成原理是理解计算机系统运作的基础。本文首先概述了计算机组成原理的基本概念,接着深入探讨了中央处理器(CPU)的工作原理,包括其基本结构和功能、指令执行过程以及性能指标。然后,本文转向存储系统的工作机制,涵盖了主存与缓存的结构、存储器的扩展与管理,以及高速缓存的优化策略。随后,文章讨论了输入输出系统与总线的技术,阐述了I/O系统的
CMOS传输门故障排查:专家教你识别与快速解决故障
# 摘要
CMOS传输门故障是集成电路设计中的关键问题,影响电子设备的可靠性和性能。本文首先概述了CMOS传输门故障的普遍现象和基本理论,然后详细介绍了故障诊断技术和解决方法,包括硬件更换和软件校正等策略。通过对故障表现、成因和诊断流程的分析,本文旨在提供一套完整的故障排除工具和预防措施。最后,文章展望了CMOS传输门技术的未来挑战和发展方向,特别是在新技术趋势下如何面对小型化、集成化挑战,以及智能故障诊断系统和自愈合技术的发展潜力。
# 关键字
CMOS传输门;故障诊断;故障解决;信号跟踪;预防措施;小型化集成化
参考资源链接:[cmos传输门工作原理及作用_真值表](https://w
KEPServerEX秘籍全集:掌握服务器配置与高级设置(最新版2018特性深度解析)
# 摘要
KEPServerEX作为一种广泛使用的工业通信服务器软件,为不同工业设备和应用程序之间的数据交换提供了强大的支持。本文从基础概述入手,详细介绍了KEPServerEX的安装流程和核心特性,包括实时数据采集与同步,以及对通讯协议和设备驱动的支持。接着,文章深入探讨了服务器的基本配置,安全性和性能优化的高级设
【域控制新手起步】:一步步掌握组策略的基本操作与应用
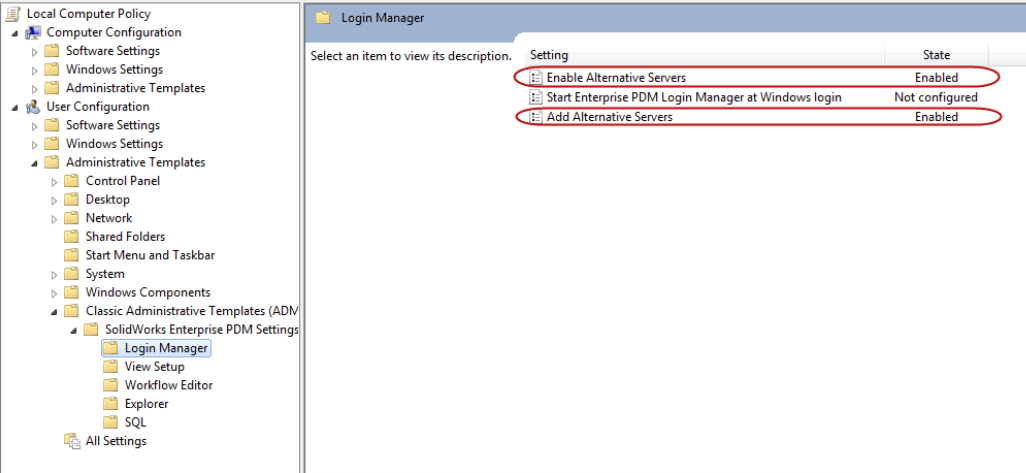
# 摘要
组策略是域控制器中用于配置和管理网络环境的重要工具。本文首先概述了组策略的基本概念和组成部分,并详细解释了其作用域与优先级规则,以及存储与刷新机制。接着,文章介绍了组策略的基本操作,包括通过管理控制台GPEDIT.MSC的使用、组策略对象(GPO)的管理,以及部署和管理技巧。在实践应用方面,本文探讨了用户环境管理、安全策略配置以及系统配置与优化。此
【SolidWorks自动化工具】:提升重复任务效率的最佳实践

# 摘要
本文全面探讨了SolidWorks自动化工具的开发和应用。首先介绍了自动化工具的基本概念和SolidWorks API的基础知识,然后深入讲解了编写基础自动化脚本的技巧,包括模型操作、文件处理和视图管理等。接着,本文阐述了自动化工具的高级应用
Android USB音频设备通信:实现音频流的无缝传输
# 摘要
随着移动设备的普及,Android平台上的USB音频设备通信已成为重要话题。本文从基础理论入手,探讨了USB音频设备工作原理及音频通信协议标准,深入分析了Android平台音频架构和数据传输流程。随后,实践操作章节指导读者了解如何设置开发环境,编写与测试USB音频通信程序。文章深入讨论了优化音频同步与延迟,加密传输音频数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )