ZooKeeper:Hadoop分布式应用程序的协调服务
发布时间: 2023-12-16 22:45:03 阅读量: 72 订阅数: 21 
## 第一章:ZooKeeper简介
### 1.1 ZooKeeper的定义与概述
ZooKeeper是一个分布式开源协调服务,最初由雅虎研究院开发并于2010年加入Apache基金会。它通过提供高性能的数据管理和协调服务,帮助构建可靠的分布式系统。
### 1.2 ZooKeeper在分布式系统中的作用
在分布式系统中,各个节点需要进行协调和通信,以实现一致性、可靠性和可扩展性。这些任务包括但不限于领导者选举、分布式锁、配置管理和命名服务。ZooKeeper提供了易于使用的接口和强大的一致性保障,使得开发人员能够轻松地构建分布式应用程序。
### 1.3 ZooKeeper与Hadoop的关系
ZooKeeper是Hadoop生态系统中的重要组件之一,用于提供Hadoop分布式应用程序所需的协调服务。Hadoop利用ZooKeeper来管理各个节点的信息、配置和状态,以确保系统的稳定性和高可用性。具体来说,ZooKeeper在Hadoop中的应用包括HDFS(Hadoop分布式文件系统)的命名空间管理和YARN(Yet Another Resource Negotiator)的资源调度等方面。
## 第二章:ZooKeeper的基本原理
ZooKeeper作为Hadoop分布式应用程序的协调服务,其基本原理是理解其在分布式系统中的数据模型、工作原理和一致性保障。在本章中,我们将深入探讨ZooKeeper的基本原理,包括数据模型、集群的工作原理以及一致性保障。
### 第三章:ZooKeeper的基本功能
在本章中,我们将深入探讨ZooKeeper的基本功能,包括分布式协调、配置管理以及命名服务的实现原理和应用场景。
#### 3.1 分布式协调
在分布式系统中,各个节点之间需要进行协调以实现统一的行为,这就需要一种可靠的分布式协调服务。ZooKeeper提供了一套高效的协调机制,可以帮助分布式系统节点之间进行同步和通信。
**示例场景:**
假设我们有一个分布式系统,需要实现任务的分配和同步执行。使用ZooKeeper可以轻松实现任务分配的协调,每个节点可以在ZooKeeper中创建临时节点来表示自己的可用状态,其他节点可以监听这些节点的变化,一旦有节点异常或可用状态改变,就可以及时通知其他节点作出相应处理。
**代码示例(Java):**
```java
public class DistributedTaskCoordinator {
private ZooKeeper zooKeeper;
private static final String ZOOKEEPER_ADDRESS = "localhost:2181";
private static final String TASK_ASSIGNMENT_PATH = "/task/assignment";
public void connectZooKeeper() throws IOException {
CountDownLatch connectedSignal = new CountDownLatch(1);
zooKeeper = new ZooKeeper(ZOOKEEPER_ADDRESS, 5000, event -> {
if (event.getState() == Watcher.Event.KeeperState.SyncConnected) {
connectedSignal.countDown();
}
});
try {
connectedSignal.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void assignTask(String task) throws KeeperException, InterruptedException {
zooKeeper.create(TASK_ASSIGNMENT_PATH, task.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
public void watchTaskAssignment() throws KeeperException, InterruptedException {
List<String> assignmentNodes = zooKeeper.getChildren(TASK_ASSIGNMENT_PATH, event -> {
if (event.getType() == Watcher.Event.EventType.NodeChildrenChanged) {
// handle task assignment changes
// ...
}
});
// process initial task assignment
// ...
}
}
```
**代码总结:**
上述代码演示了如何使用ZooKeeper进行分布式任务分配和协调。通过ZooKeeper的节点创建和监听机制,实现了对任务分配状态的实时监控和处理。
**结果说明:**
通过ZooKeeper的协调机制,可以确保任务在分布式系统中的统一分配和同步执行,提高了系统的可靠性和稳定性。
#### 3.2 配置管理
分布式系统中的节点通常需要共享配置信息,以便实现统一的配置管理。ZooKeeper提供了一种轻量级的配置管理方式,可以方便地实现配置的发布和订阅。
**示例场景:**
假设我们有一个分布式应用,需要共享数据库连接配置信息。通过ZooKeeper的配置管理,可以实现数据库连接配置的统一管理和动态更新,各个节点可以实时获取最新的配置信息。
**代码示例(Python):**
```python
from kazoo.client import KazooClient
ZOOKEEPER_ADDRESS = 'localhost:2181'
DB_CONFIG_PATH = '/configs/db'
# Connect to ZooKeeper
zk = KazooClient(hosts=ZOOKEEPER_ADDRESS)
zk.start()
# Set up watch for config changes
@zk.DataWatch(DB_CONFIG_PATH)
def watch_db_config(data, stat, event):
if event and event.type == 'CHANGED':
update_db_connection(data)
# Get initial DB config
db_config = zk.get(DB_CONFIG_PATH)[0]
update_db_connection(db_config)
def update_db_connection(config):
# Update DB connection with new config
print(f"Updating DB connection with new config: {config}")
# Main application logic
# ...
```
**代码总结:**
以上Python代码演示了如何使用Kazoo库连接ZooKeeper进行配置管理,通过监听配置节点的变化,实现了动态更新数据库连接配置的功能。
**结果说明:**
通过ZooKeeper的配置管理,可以实现统一的配置发布和订阅,保证各个节点始终使用最新的配置信息,提高了系统的灵活性和可维护性。
#### 3.3 命名服务
在分布式系统中,需要对服务和资源进行统一的命名管理,以便实现统一的服务发现和路由。ZooKeeper提供了一种高效的命名服务机制,可以帮助分布式系统实现统一的命名管理和服务路由。
**示例场景:**
假设我们有一个微服务架构的系统,需要实现服务发现和路由。通过ZooKeeper的命名服务,可以将各个微服务的地址和状态注册到ZooKeeper中,其他服务可以通过ZooKeeper实时获取最新的服务地址和状态信息。
**代码示例(Go):**
```go
package main
import (
"fmt"
"github.com/samuel/go-zookeeper/zk"
"time"
)
var (
zkHosts = []string{"localhost:2181"}
conn *zk.Conn
)
func main() {
var err error
conn, _, err = zk.Connect(zkHosts, time.Second)
if err != nil {
panic(err)
}
servicePath := "/services/my-service"
serviceData := []byte("127.0.0.1:8080")
// Register service in ZooKeeper
createOrUpdateNode(servicePath, serviceData)
// Watch for changes in services
for {
watchServiceChanges(servicePath)
time.Sleep(10 * time.Second)
}
}
func createOrUpdateNode(path string, data []byte) {
exists, _, err := conn.Exists(path)
if err != nil {
panic(err)
}
if exists {
_, err := conn.Set(path, data, -1)
if err != nil {
panic(err)
}
} else {
_, err := conn.Create(path, data, 0, zk.WorldACL(zk.PermAll))
if err != nil {
panic(err)
}
}
}
func watchServiceChanges(path string) {
data, _, ch, err := conn.GetW(path)
if err != nil {
panic(err)
}
fmt.Printf("Current service data: %s\n", data)
<-ch
fmt.Println("Service data changed.")
}
```
**代码总结:**
以上Go语言代码演示了如何使用go-zookeeper库连接ZooKeeper实现命名服务,包括将服务地址注册到ZooKeeper和监听服务变化的过程。
**结果说明:**
### 第四章:ZooKeeper在Hadoop中的应用
在大规模分布式系统中,如Hadoop,ZooKeeper作为一个分布式协调服务,扮演着至关重要的角色。它为Hadoop提供了可靠的配置管理、命名服务和分布式锁等功能,有效地解决了Hadoop中的一些问题。
#### 4.1 Hadoop中的问题与ZooKeeper的解决方案
在Hadoop集群中,有一些共享的资源需要被多个任务或节点同时访问和操作。例如,HDFS中的元数据信息需要被多个数据节点访问和更新,YARN中的应用程序信息需要被多个节点协调。这些共享资源的管理和协调会导致一些问题,包括竞态条件、数据不一致和单点故障等。
ZooKeeper提供了一套解决方案来解决这些问题。它通过提供分布式锁、有序节点和观察者等机制来确保资源的互斥访问、一致性更新和实时通知。这些机制使得Hadoop集群更加可靠和稳定。
#### 4.2 ZooKeeper在HDFS中的应用
在HDFS中,ZooKeeper作为一个命名服务,负责管理和维护HDFS的元数据信息。它提供了分布式的命名空间,将文件和目录组织起来,并提供了访问控制和权限管理等功能。
具体来说,ZooKeeper使用ZNode来表示文件和目录,并使用节点的路径来表示命名空间中的位置。当HDFS需要访问或更新元数据信息时,它将通过ZooKeeper来获取锁、获取最新的元数据副本,并保持与其他节点的一致性。
#### 4.3 ZooKeeper在YARN中的应用
在YARN中,ZooKeeper用于协调和管理应用程序的启动、状态转换和资源分配等过程。它为YARN提供了一个可靠的中心化调度和资源管理的机制,确保集群中的资源被高效地使用和分配。
具体来说,YARN使用ZooKeeper来维护应用程序的状态信息、节点的健康状态和资源的使用情况。它还通过ZooKeeper来实现容错和容灾能力,以应对节点故障和网络分区等情况。
### 第五章:ZooKeeper的性能优化与调优
在使用ZooKeeper时,不可避免地会遇到性能瓶颈的问题。本章将介绍如何进行ZooKeeper的性能优化与调优,以提高其在分布式应用中的效率和可靠性。
#### 5.1 ZooKeeper性能瓶颈分析
在开始性能优化前,我们首先需要了解ZooKeeper的性能瓶颈所在。一般来说,以下几个方面可能成为ZooKeeper性能瓶颈的原因:
- 网络延迟:ZooKeeper使用基于TCP的通信协议,因此网络延迟对其性能有较大影响。
- 存储设备性能:ZooKeeper的数据存储在磁盘上,磁盘性能较差时会导致读写延迟。
- 集群规模:较大规模的ZooKeeper集群可能带来更多的通信开销和负载。
- 客户端请求频率:高频率的客户端请求可能会导致ZooKeeper的负载过大。
了解了可能的性能瓶颈后,接下来我们将介绍一些性能调优的策略。
#### 5.2 ZooKeeper集群的部署与配置
正确地部署和配置ZooKeeper集群是提高性能的重要一步。以下是一些可以考虑的配置和部署策略:
- 使用SSD:考虑使用SSD作为ZooKeeper的数据存储设备,以提高读写性能。
- 适当增加硬件资源:根据集群规模和负载情况,适当增加服务器的硬件资源,如CPU、内存等。
- 配置合理的网络参数:根据网络情况,调整ZooKeeper的最大连接数、最大请求数等参数,以提高网络性能。
- 分散负载:将ZooKeeper集群中的节点部署在不同的物理机上,以分散负载和减少单点故障。
#### 5.3 ZooKeeper的性能调优策略
除了适当的配置和部署外,还可以采取一些性能调优的策略来提高ZooKeeper的性能:
- 批量请求:合并多个客户端请求为一个批量请求发送,减少通信开销。
- 数据压缩:对ZooKeeper的数据进行压缩,减少网络传输的大小和延迟。
- 读写优化:根据应用场景的需求,合理选择读写操作的优先级和ZooKeeper节点的数据模型。
- 监控和诊断:监控ZooKeeper的性能指标,及时诊断和调整集群配置。
通过以上策略的综合应用,可以显著提高ZooKeeper的性能和可靠性,从而更好地支持Hadoop等分布式应用的正常运行。
### 第六章:ZooKeeper未来发展趋势
在这一章中,我们将探讨ZooKeeper未来的发展趋势,包括最新版本的更新与特性、在云原生时代的发展方向,以及与新兴技术的整合与创新应用。
#### 6.1 ZooKeeper 3.6版本更新与特性
最新的ZooKeeper 3.6版本带来了许多令人振奋的更新与特性,其中最引人注目的包括:
- 增强的TLS支持:为了提高安全性,ZooKeeper 3.6引入了更加灵活和可配置的TLS选项,使得用户可以更好地保护其ZooKeeper集群。
- 新的Watch事件类型:引入了新的Watch事件类型,帮助开发人员更精细地监控ZooKeeper中节点的变化,提高系统的实时性和敏捷性。
- 增强的节点类型:引入了Sequential和Ephemeral的组合节点类型,进一步扩展了ZooKeeper的数据模型,使得开发者可以更灵活地应对各种场景需求。
#### 6.2 ZooKeeper在云原生时代的发展方向
随着云原生技术的快速发展,ZooKeeper也在不断演进以适应云原生应用的需求,主要的发展方向包括:
- 容器化支持:ZooKeeper 3.6版本已经对容器化有了更好的支持,未来将更加深入地与容器技术(如Kubernetes)进行集成,提供更便捷的部署和管理方式。
- 弹性伸缩:针对云原生应用动态伸缩的特点,未来ZooKeeper将进一步优化其集群的动态扩展和缩减能力,以应对不断变化的工作负载。
#### 6.3 ZooKeeper与新兴技术的整合与创新应用
除了云原生技术,ZooKeeper将会与更多新兴技术进行整合,并在各个领域实现创新应用,例如:
- 与边缘计算结合:随着边缘计算的兴起,ZooKeeper将与边缘计算平台深度整合,为边缘设备间的协调和通信提供可靠支持。
- 与区块链技术融合:ZooKeeper与区块链技术结合,可以为分布式账本系统提供高效的协调服务,为数据共识与一致性提供支持。
通过不断地与新技术融合和创新应用,ZooKeeper将继续在分布式协调领域发挥重要作用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Hadoop生态系统中的各种组件及其在大数据处理中的重要作用。从Hadoop的基本概念与架构解析开始,到HDFS分布式文件系统的详细解读,再到MapReduce并行计算框架的理论与实践,以及YARN资源管理与作业调度平台的深入剖析,本专栏覆盖了Hadoop生态系统的方方面面。此外,我们还逐一介绍了Hive数据仓库、Pig数据流脚本语言、HBase列式数据库、ZooKeeper协调服务等重要组件,以及Sqoop、Flume、Oozie等相关工具的详细解读。而对于Hadoop集群的管理监控以及安全性、高可用性、性能优化、规模扩展与负载均衡等关键问题,本专栏也提供了一系列有效的解决方案。最后,本专栏还涵盖了Hadoop生态系统中的机器学习、数据挖掘、图计算、实时数据处理等新兴技术应用,为读者提供全面的信息和深入的理解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电子组件可靠性快速入门:IEC 61709标准的10个关键点解析
# 摘要
电子组件可靠性是电子系统稳定运行的基石。本文系统地介绍了电子组件可靠性的基础概念,并详细探讨了IEC 61709标准的重要性和关键内容。文章从多个关键点深入分析了电子组件的可靠性定义、使用环境、寿命预测等方面,以及它们对于电子组件可靠性的具体影响。此外,本文还研究了IEC 61709标准在实际应用中的执行情况,包括可靠性测试、电子组件选型指导和故障诊断管理策略。最后,文章展望了IEC 61709标准面临的挑战及未来趋势,特别是新技术对可靠性研究的推动作用以及标准的适应性更新。
# 关键字
电子组件可靠性;IEC 61709标准;寿命预测;故障诊断;可靠性测试;新技术应用
参考资源
KEPServerEX扩展插件应用:增强功能与定制解决方案的终极指南
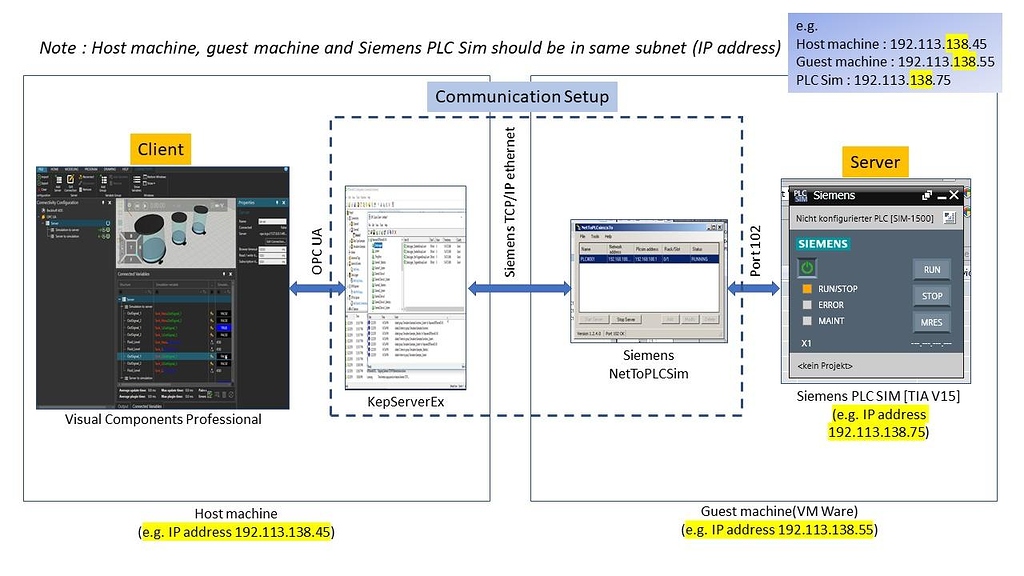
# 摘要
本文全面介绍了KEPServerEX扩展插件的概况、核心功能、实践案例、定制解决方案以及未来的展望和社区资源。首先概述了KEPServerEX扩展插件的基础知识,随后详细解析了其核心功能,包括对多种通信协议的支持、数据采集处理流程以及实时监控与报警机制。第三章通过
【Simulink与HDL协同仿真】:打造电路设计无缝流程

# 摘要
本文全面介绍了Simulink与HDL协同仿真技术的概念、优势、搭建与应用过程,并详细探讨了各自仿真环境的配置、模型创建与仿真、以及与外部代码和FPGA的集成方法。文章进一步阐述了协同仿真中的策略、案例分析、面临的挑战及解决方案,提出了参数化模型与自定义模块的高级应用方法,并对实时仿真和硬件实现进行了深入探讨。最
高级数值方法:如何将哈工大考题应用于实际工程问题
# 摘要
数值方法作为工程计算中不可或缺的工具,在理论研究和实际应用中均显示出其重要价值。本文首先概述了数值方法的基本理论,包括数值分析的概念、误差分类、稳定性和收敛性原则,以及插值和拟合技术。随后,文章通过分析哈工大的考题案例,探讨了数值方法在理论应用和实际问
深度解析XD01:掌握客户主数据界面,优化企业数据管理

# 摘要
客户主数据界面作为企业信息系统的核心组件,对于确保数据的准确性和一致性至关重要。本文旨在探讨客户主数据界面的概念、理论基础以及优化实践,并分析技术实现的不同方法。通过分析客户数据的定义、分类、以及标准化与一致性的重要性,本文为设计出高效的主数据界面提供了理论支撑。进一步地,文章通过讨论数据清洗、整合技巧及用户体验优化,指出了实践中的优化路径。本文还详细阐述了技术栈选择、开发实践和安
Java中的并发编程:优化天气预报应用资源利用的高级技巧
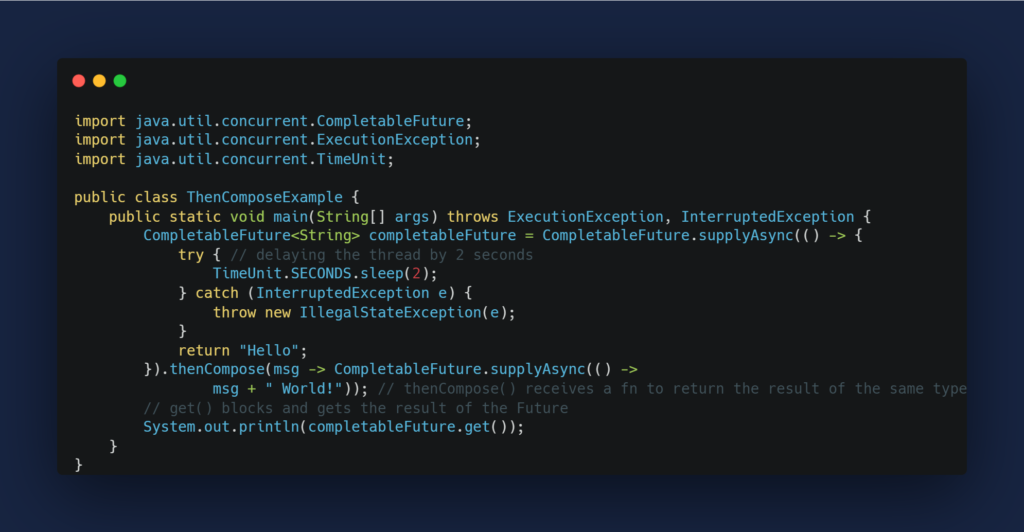
# 摘要
本论文针对Java并发编程技术进行了深入探讨,涵盖了并发基础、线程管理、内存模型、锁优化、并发集合及设计模式等关键内容。首先介绍了并发编程的基本概念和Java并发工具,然后详细讨论了线程的创建与管理、线程间的协作与通信以及线程安全与性能优化的策略。接着,研究了Java内存模型的基础知识和锁的分类与优化技术。此外,探讨了并发集合框架的设计原理和
计算机组成原理:并行计算模型的原理与实践
# 摘要
随着计算需求的增长,尤其是在大数据、科学计算和机器学习领域,对并行计算模型和相关技术的研究变得日益重要。本文首先概述了并行计算模型,并对其基础理论进行了探讨,包括并行算法设计原则、时间与空间复杂度分析,以及并行计算机体系结构。随后,文章深入分析了不同的并行编程技术,包括编程模型、语言和框架,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )