ZooKeeper:Hadoop集群的协调服务
发布时间: 2024-01-14 10:09:33 阅读量: 39 订阅数: 41 

ZooKeeper 是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等
# 1. ZooKeeper 简介
## 1.1 ZooKeeper 的背景介绍
ZooKeeper是一个开源的分布式协调服务,由Apache基金会管理和维护。它最初是由雅虎公司开发的,后来成为Apache软件基金会的一个顶级项目。ZooKeeper的设计目标是提供一个高性能、高可靠性、高可扩展性的协调服务,用于分布式系统中的进程协作和数据管理。
在分布式系统中,各个节点之间的通信和协作是非常复杂且关键的。ZooKeeper通过提供一组简单的原语(如数据节点、锁和通知机制),为分布式系统提供了一种可靠的协调和同步机制。它可以帮助开发人员构建高性能、可靠性和高可扩展性的分布式应用。
## 1.2 ZooKeeper 的作用和特点
ZooKeeper的主要作用是在分布式系统中提供可靠的协调、通知和管理服务。它具有以下几个特点:
- 简单易用:ZooKeeper提供了一套简单的API供开发人员使用,使得分布式应用的开发变得简单和直观。
- 高性能:ZooKeeper采用高性能的内存数据模型和异步通信机制,能够处理高并发的请求,并且具有较低的延迟。
- 高可靠性:ZooKeeper采用了多副本同步机制和数据持久化机制,能够保证数据的安全性和可靠性。
- 高可扩展性:ZooKeeper使用了分布式架构和节点动态扩展机制,能够支持大规模的分布式系统。
## 1.3 ZooKeeper 在Hadoop集群中的重要性
在Hadoop集群中,ZooKeeper扮演着重要的角色。它主要用于管理和协调Hadoop集群中的各个组件,包括NameNode、DataNode、ResourceManager、NodeManager等。通过使用ZooKeeper,Hadoop集群能够实现高可靠性和高可扩展性,并提供一致性的文件系统、作业调度和监控等功能。
ZooKeeper为Hadoop集群提供了以下功能:
- 高可用性:ZooKeeper通过选举机制和心跳检测,确保Hadoop集群中的主节点(如NameNode和ResourceManager)的高可用性和故障恢复能力。
- 数据一致性:ZooKeeper提供了分布式锁和同步原语,用于保证Hadoop集群中各个节点之间的数据一致性和顺序性。
- 配置管理:ZooKeeper能够动态管理Hadoop集群的配置信息,使得配置修改能够及时生效并在整个集群中同步。
- 监控与通知:ZooKeeper提供了监控和通知机制,使得Hadoop集群能够实时监控状态变化,并及时通知相关组件进行响应。
ZooKeeper在Hadoop集群中的重要性不可忽视,它为Hadoop集群的可靠运行和高效协作提供了坚实的基础。在接下来的章节中,我们将深入探讨ZooKeeper的基本概念、安装配置、应用场景、管理与监控以及未来发展方向。
# 2. ZooKeeper 的基本概念
ZooKeeper 是一个开源的分布式协调服务,提供了一个简单的接口来处理分布式应用程序中常见的协调任务。在Hadoop集群中,ZooKeeper起着至关重要的作用,它用于协调Hadoop集群中不同节点之间的状态同步和通知。
### 2.1 ZooKeeper 的数据模型
ZooKeeper 的数据模型是基于树形结构的层次命名空间,类似于文件系统。每个节点称为"Znode",每个Znode都可以存储数据,并且可以有多个子节点。Znode的层级结构和路径具有唯一性,这样就可以方便地使用路径来定位和访问Znode。
### 2.2 ZooKeeper 的Znode
Znode 是ZooKeeper数据模型中的基本单元,它存储着数据和状态信息。Znode可以分为持久节点和临时节点两种类型。持久节点在创建后会一直存在,直到有删除操作来移除它;而临时节点的生命周期和客户端会话相关联,当客户端会话失效时,临时节点也会被自动删除。
ZooKeeper 还提供了顺序节点的功能,在创建节点的同时,可以添加顺序号,以保证节点的顺序性。
```java
// Java示例代码,创建一个持久节点
ZooKeeper zk = new ZooKeeper("localhost:2181", 3000, null);
zk.create("/path", data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// Java示例代码,创建一个临时顺序节点
String path = zk.create("/parent", data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
```
### 2.3 ZooKeeper 的Watcher
Watcher 是ZooKeeper中的一种机制,用于通知客户端关于Znode状态变化的信息。当客户端注册Watcher时,如果Znode发生变化(如被删除、数据更新等),ZooKeeper会通知客户端。Watcher是一次性的,即一旦触发一次通知,Watcher就会被移除,因此需要在收到通知后重新设置Watcher。
```python
# Python示例代码,注册Watcher并处理Znode变化通知
def watch_event(event):
if event.type == EventType.NodeDeleted:
print("Node deleted: " + event.path)
elif event.type == EventType.NodeDataChanged:
print("Node data changed: " + event.path)
zk = KazooClient(hosts='127.0.0.1:2181')
zk.start()
zk.exists("/my-node", watch=watch_event)
```
ZooKeeper 的基本概念如Znode、数据模型和Watcher为理解和使用ZooKeeper提供了基础。在下一章节,我们将学习如何安装和配置ZooKeeper,并探讨它在Hadoop集群中的应用。
# 3. ZooKeeper 的安装与配置
ZooKeeper 的安装与配置对于其在Hadoop集群中的正常运行至关重要。本章将介绍ZooKeeper的安装步骤、集群配置以及常见配置参数,帮助读者更好地理解和使用ZooKeeper。
#### 3.1 ZooKeeper 的安装步骤
在安装ZooKeeper之前,首先需要确保系统环境满足以下要求:
- Java环境:ZooKeeper是基于Java开发的,因此需要安装Java环境。
- 网络连接:确保服务器能够访问互联网,以便下载ZooKeeper安装包。
接下来,按照以下步骤进行ZooKeeper的安装:
1. 下载ZooKeeper安装包:
可以从ZooKeeper官方网站(https://zookeeper.apache.org)下载最新的稳定版本安装包,也可以使用wget命令从命令行下载。
```bash
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
```
2. 解压安装包:
```bash
tar -zxf apache-zookeeper-3.7.0-bin.tar.gz
```
3. 配置ZooKeeper:
进入解压后的ZooKeeper目录,复制一份模板配置文件,并进行相应的配置。
```bash
cd apache-zookeeper-3.7.0-bin
cp conf/zoo_sample.cfg conf/zoo.cfg
vi conf/zoo.cfg
```
在配置文件中可以设置ZooKeeper的数据目录、客户端端口、选举端口等参数。
4. 启动ZooKeeper:
执行ZooKeeper的启动命令。
```bash
bin/zkServer.sh start
```
#### 3.2 ZooKeeper 集群的配置
在生产环境中,通常会部署多个ZooKeeper节点构成ZooKeeper集群,以提高系统的可用性和容错能力。下面是搭建ZooKeeper集群的基本步骤:
1. 复制ZooKeeper配置文件:
将单节点ZooKeeper的配置文件复制到其他节点,并根据实际情况修改配置文件中的节点ID、数据目录、客户端端口等参数。
2. 配置集群中的节点互联信息:
在每个节点的配置文件中配置集群中其他节点的地址信息。
3. 启动集群:
逐个启动各个ZooKeeper节点,确保集群中的节点正常启动并互相识别。
#### 3.3 ZooKeeper 的常见配置参数
ZooKeeper的配置文件(zoo.cfg)中包含了许多重要的配置参数,以下是几个常见的配置参数及其作用:
- `dataDir`:ZooKeeper存储数据的目录。
- `clientPort`:ZooKeeper客户端连接的端口。
- `initLimit`:集群中的Follower节点与Leader节点建立初始连接的时间上限。
- `syncLimit`:Leader和Follower之间的心跳同步上限。
- `server.x`:集群中各个节点的配置信息。
通过合理配置这些参数,可以更好地适应不同规模和需求的ZooKeeper集群。
以上是ZooKeeper的安装与配置内容的基本概要,后续章节将会对ZooKeeper在Hadoop集群中的应用进行更详细的介绍。
# 4. ZooKeeper 在Hadoop集群中的应用
#### 4.1 Hadoop中的ZooKeeper使用场景
在Hadoop集群中,ZooKeeper作为一个协调服务可以被广泛应用于以下场景:
- **主从选举(Master Election)**:在Hadoop集群中,某些组件需要选择一个主节点来负责协调和管理其他节点的工作。ZooKeeper提供了一个可靠的选举算法来实现主节点的选举,确保只有一个节点成为主节点。
- **命名服务(Name Service)**:Hadoop集群中的各个组件都需要访问特定的资源,如HDFS的文件,YARN中的应用、任务等。ZooKeeper可以作为一个分布式命名服务,提供统一的命名和地址注册,使得各个组件能够方便地找到需要的资源。
- **配置管理(Configuration Management)**:Hadoop集群中的各个组件有着大量的配置参数,这些参数需要统一管理和动态更新。ZooKeeper可以作为一个配置中心,提供配置参数的存储和分发,使得配置的修改能够快速生效并保持一致。
#### 4.2 ZooKeeper与Hadoop的集成
在Hadoop集群中,为了能够使用ZooKeeper来实现协调服务,需要进行以下步骤:
1. **安装和配置ZooKeeper**:按照第三章的内容,安装ZooKeeper并进行必要的配置。
2. **Hadoop配置文件的修改**:修改Hadoop的相关配置文件,将ZooKeeper的地址和端口等信息配置正确。
3. **在Hadoop组件中使用ZooKeeper**:根据需要,在Hadoop的相关组件中使用ZooKeeper提供的API来实现主从选举、命名服务和配置管理等功能。
#### 4.3 ZooKeeper在Hadoop中的协调服务
ZooKeeper在Hadoop中的协调服务主要包括以下方面:
- **主从选举**:在Hadoop的Master组件中使用ZooKeeper实现主节点的选举。通过创建临时有序节点并监听其变化,当节点创建或删除时,根据一定的规则选择主节点。
- **命名服务**:在Hadoop的各个组件中使用ZooKeeper作为分布式命名服务,将各个资源的名字和地址注册到ZooKeeper中,以供其他组件查询和访问。
- **配置管理**:通过在ZooKeeper中存储和分发Hadoop的配置参数,实现配置的统一管理和动态更新。各个组件可以从ZooKeeper中获取最新的配置信息,并及时响应配置的修改。
通过上述方式,ZooKeeper在Hadoop集群中发挥着重要的协调服务作用,保证了集群的可靠性和高效性。
```java
// 示例代码:使用ZooKeeper实现主从选举
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
public class LeaderElection implements Watcher {
private static final String ZOOKEEPER_ADDRESS = "localhost:2181";
private static final int SESSION_TIMEOUT = 3000;
private static final String ELECTION_NAMESPACE = "/election";
private String currentZnodeName;
private ZooKeeper zooKeeper;
public static void main(String[] args) throws InterruptedException {
LeaderElection leaderElection = new LeaderElection();
leaderElection.connectToZooKeeper();
leaderElection.volunteerForLeadership();
leaderElection.electLeader();
leaderElection.run();
leaderElection.close();
System.out.println("Finished the leader election process.");
}
public void connectToZooKeeper() throws InterruptedException {
this.zooKeeper = new ZooKeeper(ZOOKEEPER_ADDRESS, SESSION_TIMEOUT, this);
System.out.println(zooKeeper.getState());
Thread.sleep(2000);
}
public void volunteerForLeadership() throws InterruptedException {
String znodePrefix = ELECTION_NAMESPACE + "/c_";
String znodePath = zooKeeper.create(znodePrefix,
new byte[]{}, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
this.currentZnodeName = znodePath.replace(ELECTION_NAMESPACE + "/", "");
System.out.println("Registered znode: " + currentZnodeName);
}
public void electLeader() throws InterruptedException {
Stat predecessorStat = null;
String predecessorZnodeName = "";
while (predecessorStat == null) {
Stat stat = zooKeeper.exists(ELECTION_NAMESPACE + "/" + predecessorZnodeName, this);
if (stat == null) {
break;
}
predecessorStat = zooKeeper.exists(ELECTION_NAMESPACE + "/" + predecessorZnodeName, this);
}
if (predecessorStat == null) {
takeLeadership();
} else {
System.out.println("Watching znode " + predecessorZnodeName);
}
}
public void run() throws InterruptedException {
synchronized (zooKeeper) {
zooKeeper.wait();
}
}
public void close() throws InterruptedException {
zooKeeper.close();
System.out.println("Disconnected from ZooKeeper server.");
}
public void process(WatchedEvent watchedEvent) {
switch (watchedEvent.getType()) {
case None:
if (watchedEvent.getState() == Event.KeeperState.SyncConnected) {
System.out.println("Successfully connected to ZooKeeper server.");
} else {
synchronized (zooKeeper) {
System.out.println("Disconnected from ZooKeeper server.");
zooKeeper.notifyAll();
}
}
break;
case NodeDeleted:
try {
electLeader();
} catch (InterruptedException e) {
e.printStackTrace();
}
break;
}
}
private void takeLeadership() {
System.out.println("I am the leader now.");
}
}
```
上述示例代码演示了如何使用ZooKeeper实现一个简单的主从选举过程。通过创建临时有序节点并监听其变化,当节点创建或删除时,根据一定规则选择主节点。通过ZooKeeper的API,可以实现更加复杂的选举算法和策略。
通过使用ZooKeeper,Hadoop集群中的各个组件可以实现高可用性和强一致性,提供稳定的协调服务。同时,ZooKeeper也为集群的管理和监控提供了便利,方便进行故障处理和性能调优等工作。
# 5. ZooKeeper 的管理与监控
ZooKeeper 的管理与监控是确保Hadoop集群稳定运行的重要环节。在本章中,我们将介绍ZooKeeper的管理工具、监控与故障处理以及性能优化和调优。
#### 5.1 ZooKeeper 管理工具介绍
在实际的运维过程中,我们常常需要使用一些管理工具来进行ZooKeeper集群的管理与维护。这些工具可以帮助管理员更方便地进行状态查看、配置管理、性能监控等操作。
常用的ZooKeeper管理工具包括:
- **ZooKeeper Shell**: 它是ZooKeeper自带的命令行工具,可以通过命令行方式连接ZooKeeper集群,执行各种操作指令。
- **ZooKeeper Web 操作界面**: 一些第三方工具提供了基于Web的ZooKeeper集群管理界面,可以通过Web页面进行集群的监控和管理操作。
- **ZooKeeper Manager**: 提供了一套图形化界面,可以对ZooKeeper的节点、状态进行监控和管理。
#### 5.2 ZooKeeper 的监控与故障处理
ZooKeeper 的监控与故障处理是保障集群稳定性的重要手段。管理员需要对ZooKeeper集群进行实时的监控,及时发现并解决潜在的故障问题。
常见的监控与故障处理手段包括:
- **ZooKeeper 状态监控**: 可以通过ZooKeeper自带的四字命令(`mntr`)来查看ZooKeeper服务器的状态信息,如延迟、连接数、节点情况等。
- **日志分析与故障排查**: 定期分析ZooKeeper的日志,及时发现和解决潜在的问题。
- **故障转移与恢复**: 当ZooKeeper集群中的某个节点出现故障时,及时进行故障转移并进行数据恢复,保证集群的正常运行。
#### 5.3 ZooKeeper 的性能优化和调优
为了提高ZooKeeper集群的性能和稳定性,管理员需要进行性能优化和调优工作。主要包括以下方面:
- **网络优化**: 合理规划ZooKeeper集群的网络拓扑结构,保障节点间的网络通信畅通。
- **硬件调优**: 针对ZooKeeper服务器的硬件资源进行合理配置和调优,包括CPU、内存、磁盘等。
- **参数调优**: 针对ZooKeeper的配置参数进行调优,根据集群规模和负载情况进行合理的参数调整,如会话超时、最大连接数等。
以上是在ZooKeeper集群管理中常见的一些工作,通过这些管理与监控手段,可以有效地保障ZooKeeper集群的稳定运行。
# 6. ZooKeeper 的发展与未来展望
#### 6.1 ZooKeeper 的发展历程
ZooKeeper 最早是由雅虎公司开发并作为开源项目发布的,后来成为了Apache基金会的顶级项目。自2008年进入Apache基金会以来,ZooKeeper经历了多个版本迭代,不断完善和改进其功能,提高其在分布式系统中的稳定性和可靠性。
#### 6.2 ZooKeeper 在大数据领域的应用前景
随着大数据技术的快速发展,ZooKeeper在大数据领域的应用也变得越来越重要。除了作为Hadoop集群的协调服务外,ZooKeeper在Spark、Kafka、HBase等大数据系统中也扮演着重要角色。随着大数据应用场景的不断扩展,ZooKeeper作为分布式协调服务的需求将会持续增加。
#### 6.3 ZooKeeper 的未来发展方向与趋势
未来,随着容器化、微服务和云原生技术的兴起,ZooKeeper作为分布式协调服务的地位将更加巩固。同时,随着硬件技术的发展,ZooKeeper在性能、可靠性和安全性等方面也会不断进行优化和改进。另外,由于ZooKeeper本身的复杂性,未来可能会出现更加简化和易用的替代方案,但作为分布式协调服务的基本概念和需求将会持续存在。
以上是关于ZooKeeper的发展历程、在大数据领域的应用前景以及未来发展方向和趋势的简要介绍。随着大数据和分布式系统技术的不断发展,ZooKeeper作为重要的分布式协调服务,将继续发挥着重要作用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【概率论与数理统计:工程师的实战解题宝典】:揭示习题背后的工程应用秘诀

# 摘要
本文从概率论与数理统计的角度出发,系统地介绍了其基本概念、方法与在工程实践中的应用。首先概述了概率论与数理统计的基础知识,包括随机事件、概率计算以及随机变量的数字特征。随后,重点探讨了概率分布、统计推断、假设检验
【QSPr参数深度解析】:如何精确解读和应用高通校准综测工具

# 摘要
QSPr参数是用于性能评估和优化的关键工具,其概述、理论基础、深度解读、校准实践以及在系统优化中的应用是本文的主题。本文首先介绍了QSPr工具及其参数的重要性,然后详细阐述了参数的类型、分类和校准理论。在深入解析核心参数的同时,也提供了参数应用的实例分析。此外,文章还涵盖了校准实践的全过程,包括工具和设备准备、操作流程以及结果分析与优化。最终探讨了QSPr参数在系统优化中的
探索自动控制原理的创新教学方法

# 摘要
本文深入探讨了自动控制理论在教育领域中的应用,重点关注理论与教学内容的融合、实践教学案例的应用、教学资源与工具的开发、评估与反馈机制的建立以
Ubuntu 18.04图形界面优化:Qt 5.12.8性能调整终极指南

# 摘要
本文全面探讨了Ubuntu 18.04系统中Qt 5.12.8图形框架的应用及其性能调优。首先,概述了Ubuntu 18.04图形界面和Qt 5.12.8核心组件。接着,深入分析了Qt的模块、事件处理机制、渲染技术以及性能优化基
STM32F334节能秘技:提升电源管理的实用策略
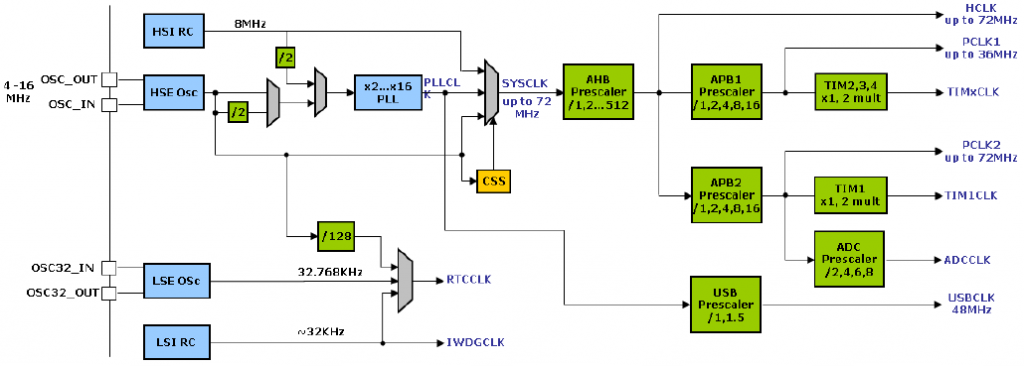
# 摘要
本文全面介绍了STM32F334微控制器的电源管理技术,包括基础节能技术、编程实践、硬件优化与节能策略,以及软件与系统级节能方案。文章首先概述了STM32F334及其电源管理模式,随后深入探讨了低功耗设计原则和节能技术的理论基础。第三章详细阐述了RTOS在节能中的应用和中断管理技巧,以及时钟系统的优化。第四章聚焦于硬件层面的节能优化,包括外围设备选型、电源管
【ESP32库文件管理】:Proteus中添加与维护技术的高效策略
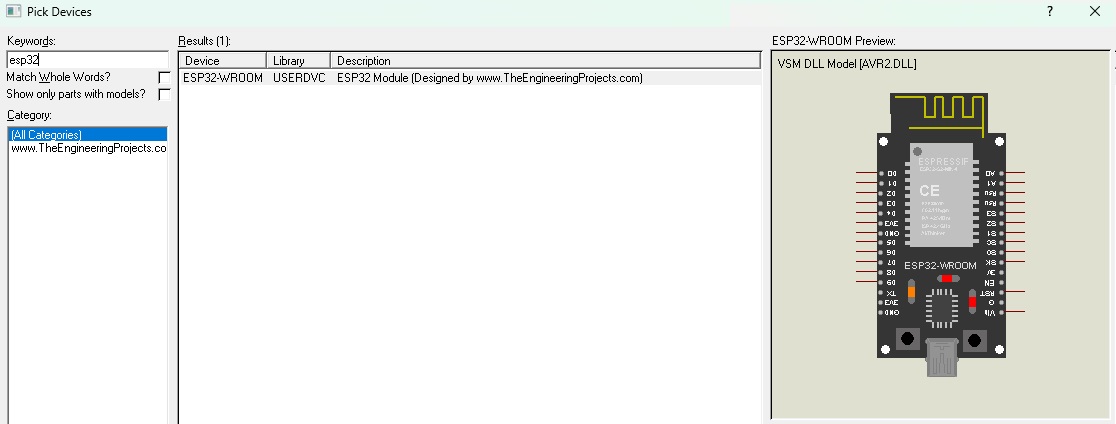
# 摘要
本文旨在全面介绍ESP32微控制器的库文件管理,涵盖了从库文件基础到实践应用的各个方面。首先,文章介绍了ESP32库文件的基础知识,包括库文件的来源、分类及其在Proteus平台的添加和配置方法。接着,文章详细探讨了库文件的维护和更新流程,强调了定期检查库文件的重要性和更新过程中的注意事项。文章的第四章和第五章深入探讨了ESP3
【实战案例揭秘】:遥感影像去云的经验分享与技巧总结

# 摘要
遥感影像去云技术是提高影像质量与应用价值的重要手段,本文首先介绍了遥感影像去云的基本概念及其必要性,随后深入探讨了其理论基础,包括影像分类、特性、去云算法原理及评估指标。在实践技巧部分,本文提供了一系列去云操作的实际步骤和常见问题的解决策略。文章通过应用案例分析,展示了遥感影像去云技术在不同领域中的应用效果,并对未来遥感影像去云技术的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )