Hive:基于Hadoop的数据仓库与SQL查询
发布时间: 2024-01-14 10:02:18 阅读量: 80 订阅数: 41 

Hive是一个构建在Hadoop上的数据仓库平台,其设计目标是.pptx
# 1. Hive简介
## 1.1 什么是Hive
Hive是一个建立在Hadoop之上的数据仓库工具,可以通过类似SQL的语言HiveQL来进行数据查询和分析。它将结构化的数据文件映射为一张数据库表,提供了对存储在Hadoop集群中的数据的操作能力。
## 1.2 Hive的历史和发展
Hive最初由Facebook开发,并于2008年作为开源项目发布。随后,Hive被Apache基金会接管,并迅速成为Hadoop生态系统中广泛使用的工具之一。
## 1.3 Hive与Hadoop的关系
Hive是建立在Hadoop之上的应用,通过Hadoop的MapReduce等计算框架来实现数据处理和分析。它为Hadoop提供了SQL查询的能力,使得开发人员可以利用熟悉的SQL语法来操作Hadoop中的数据。
## 1.4 Hive的优势和局限性
Hive的优势在于对大数据的高效处理和查询能力,同时能够与现有的商业智能工具集成。然而,由于其建立在Hadoop之上,Hive在处理实时数据和低延迟查询方面存在一定的局限性。
# 2. Hive的架构与组件
### 2.1 Hive的架构概述
Hive的架构是基于Hadoop的分布式存储和计算框架,它提供了一个用于查询和分析大规模结构化数据的SQL接口。Hive的核心组件包括元数据存储、查询处理、执行引擎和存储格式。
### 2.2 元数据存储
Hive的元数据存储是通过Hive Metastore实现的,它将Hive表和数据的元数据存储在持久化的存储介质中(如MySQL、Derby等)。元数据包括表的结构、分区信息、数据的存储位置等。Hive Metastore还提供了对元数据的管理和查询的接口。
### 2.3 查询处理
Hive的查询处理是基于HiveQL(Hive Query Language)来实现的。查询处理包括查询解析、查询优化和查询执行三个步骤。首先,Hive将用户提交的查询语句解析成抽象语法树(AST),然后对AST进行优化,如表达式下推、谓词下推等,最后将优化后的查询计划转换成一系列MapReduce或Tez任务来执行。
### 2.4 执行引擎
Hive的执行引擎负责将查询计划转换成可执行的任务,并进行任务的调度和执行。Hive支持多种执行引擎,包括MapReduce、Tez和Spark等。不同的执行引擎可以根据不同的场景和需求选择合适的执行方式,以提高查询的性能和效率。
### 2.5 存储格式
Hive的存储格式决定了数据在Hadoop中的物理存储方式。Hive支持多种存储格式,如文本格式、序列文件格式、ORC文件格式和Parquet文件格式等。每种存储格式都有各自的特点和适用场景,可以根据数据的特点和使用需求选择合适的存储格式来提高查询的性能和压缩比。
以上是Hive的架构与组件的介绍,这些组件共同作用于Hive的数据仓库和SQL查询功能。在后续的章节中,我们将深入探讨Hive的语法、性能优化、与Hadoop生态系统的集成以及实际应用案例等内容。
# 3. HiveQL基础
HiveQL是Hive的查询语言,它是基于SQL的扩展,可以将SQL语句翻译成MapReduce任务。在本章中,我们将介绍HiveQL的特点、语法以及数据定义、操作和查询等方面的内容。
### 3.1 HiveQL的特点和语法
HiveQL具有类似于SQL的语法,同时也支持用户自定义函数(UDF)、用户自定义聚合函数(UDAF)以及用户自定义表生成函数(UDTF)。此外,HiveQL还支持将查询结果输出到HDFS,以及从HDFS加载数据到表中等操作。
### 3.2 数据定义
在Hive中,我们可以使用HiveQL进行数据定义,包括创建表、加载数据、导出数据等操作。具体的语法包括如下内容:
#### 创建表
```sql
CREATE TABLE IF NOT EXISTS employee (
id INT,
name STRING,
age INT,
salary FLOAT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
```
#### 加载数据
```sql
LOAD DATA LOCAL INPATH '/path/to/employee.csv' OVERWRITE INTO TABLE employee;
```
### 3.3 数据操作
HiveQL支持常见的数据操作,包括插入、更新、删除等操作。下面是一个插入数据的示例:
#### 插入数据
```sql
INSERT INTO TABLE employee VALUES (1, 'Alice', 25, 5000.00), (2, 'Bob', 30, 6000.00);
```
### 3.4 数据查询
HiveQL可以用于执行数据查询,包括简单查询、聚合查询、连接查询等。下面是一个简单查询的示例:
#### 简单查询
```sql
SELECT * FROM employee WHERE age > 25;
```
### 3.5 HiveQL中的内置函数
HiveQL内置了丰富的函数库,包括数学函数、字符串函数、日期函数等。这些内置函数可以在HiveQL查询中直接调用,以方便用户进行数据处理和分析。
以上是关于HiveQL基础的内容,通过学习这些内容,你可以开始编写HiveQL查询,操作Hive中的数据。
# 4. Hive与Hadoop生态系统的集成
4.1 Hive与HDFS的集成
在Hadoop生态系统中,HDFS(Hadoop Distributed File System)被用作数据存储和分布式文件系统。Hive与HDFS的集成能够充分利用HDFS的高可靠性和可扩展性。
Hive将数据存储在HDFS上,并通过HiveQL语句进行操作和查询。通过Hive与HDFS的集成,我们可以使用Hive来处理和分析存储在HDFS上的大规模数据。
以下是一个示例代码,展示了Hive与HDFS的集成:
```sql
-- 创建一个外部表
CREATE EXTERNAL TABLE employees (
id INT,
name STRING,
department STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/hive/warehouse/employees';
-- 从HDFS导入数据到表中
LOAD DATA INPATH '/user/hive/input/employees.txt' OVERWRITE INTO TABLE employees;
-- 查询数据
SELECT * FROM employees WHERE department = 'IT';
```
在上述示例中,我们创建了一个名为employees的外部表,将数据存储在HDFS的指定目录下。然后,我们使用LOAD DATA命令将数据从HDFS的特定路径导入到表中。最后,我们可以使用HiveQL语句查询表中的数据。
4.2 Hive与MapReduce的集成
MapReduce是Hadoop中用于大数据处理的计算模型和框架。Hive与MapReduce的集成可以通过将HiveQL语句转化为MapReduce任务来实现数据处理和分析。
Hive通过将HiveQL查询转化为MapReduce任务来执行数据操作和查询。这种集成允许用户使用简单、类SQL的语法来分析和操作大规模数据。
以下是一个Hive与MapReduce的集成示例代码:
```sql
-- 创建一个表
CREATE TABLE page_views (
id INT,
url STRING,
visit_date STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
-- 插入数据到表中
INSERT INTO TABLE page_views VALUES (1, 'http://example.com', '2021-01-01');
INSERT INTO TABLE page_views VALUES (2, 'http://example.com', '2021-01-02');
INSERT INTO TABLE page_views VALUES (3, 'http://example.com', '2021-01-03');
-- 使用MapReduce计算每个URL的访问次数
SELECT url, COUNT(*) AS visit_count FROM page_views GROUP BY url;
```
在上面的示例中,我们首先创建了一个名为page_views的表,然后插入了一些数据。最后,我们使用HiveQL语句查询表,并通过MapReduce计算每个URL的访问次数。
4.3 Hive与YARN的集成
YARN(Yet Another Resource Negotiator)是Hadoop的集群资源管理器,用于对集群资源进行统一管理和调度。Hive与YARN的集成能够更高效地利用集群资源。
通过与YARN的集成,Hive可以自动向YARN提交MapReduce任务,并根据集群资源情况进行任务调度和管理。这样可以确保Hive作业能够在集群中高效执行,提高整体的数据处理性能和资源利用率。
以下是一个Hive与YARN的集成示例代码:
```sql
-- 设置Hive在YARN上运行
SET hive.execution.engine = yarn;
-- 创建一个表
CREATE TABLE customers (
id INT,
name STRING,
email STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
-- 插入数据到表中
INSERT INTO TABLE customers VALUES (1, 'John Doe', 'john@example.com');
INSERT INTO TABLE customers VALUES (2, 'Jane Smith', 'jane@example.com');
INSERT INTO TABLE customers VALUES (3, 'Bob Johnson', 'bob@example.com');
-- 查询数据
SELECT * FROM customers;
```
在上述示例中,我们通过设置hive.execution.engine参数为yarn来启用Hive与YARN的集成。然后,我们创建了一个名为customers的表,并插入了一些数据。最后,我们使用HiveQL语句查询表中的数据。
4.4 Hive与HBase的集成
HBase是Hadoop生态系统中的分布式NoSQL数据库,具有高可扩展性和高性能。Hive与HBase的集成能够将HiveQL查询转化为HBase的查询操作,并实现Hive与HBase之间的数据交互。
通过与HBase的集成,Hive可以使用HBase作为数据存储,同时通过HiveQL语句执行高级查询和分析操作。这种集成提供了对大规模数据的快速访问和分析能力。
以下是一个Hive与HBase的集成示例代码:
```sql
-- 创建一个外部表
CREATE EXTERNAL TABLE users (
id INT,
name STRING,
email STRING
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
'hbase.columns.mapping' = ':key,info:name,info:email'
)
TBLPROPERTIES (
'hbase.table.name' = 'users'
);
-- 查询数据
SELECT * FROM users WHERE id = 1;
```
在上述示例中,我们创建了一个名为users的外部表,并将其与HBase进行了集成。我们使用HBaseStorageHandler作为存储处理程序,并指定HBase中列到Hive表列的映射关系。最后,我们可以使用HiveQL语句查询表中的数据。
希望以上内容对你有所帮助。这些示例展示了Hive与Hadoop生态系统的集成,以及如何使用Hive进行数据处理和分析。
# 5. 性能优化与调优
在本章中,我们将深入探讨如何对Hive进行性能优化与调优。我们将从查询优化、数据存储优化、执行计划优化以及性能调优实例等方面进行详细讨论,帮助您更好地优化和提升Hive的性能。
### 5.1 Hive查询优化
在这一节中,我们将重点关注Hive查询的优化技巧。我们将介绍一些常用的查询优化方法,包括数据压缩、分区表优化、索引的使用、统计信息的收集等。我们会通过详细的代码示例和实际场景的演示来说明这些优化技巧的作用和效果。
```java
// 代码示例:使用分区表优化查询
SELECT * FROM user_logs WHERE date='20220101' AND event='login';
// 优化后的查询
SET hive.optimize.ppd=true;
SET hive.optimize.ppd.storage=true;
SELECT * FROM user_logs WHERE date='20220101' AND event='login';
```
上述代码示例展示了通过启用Hive的查询优化属性来优化查询性能的过程。我们将详细分析优化前后的执行计划和性能表现。
### 5.2 数据存储优化
在这一节中,我们将介绍如何通过优化数据存储格式和压缩方式来提升Hive的性能。我们将详细介绍Parquet、ORC等常用的数据存储格式,以及Snappy、Gzip等常用的数据压缩方式,并通过实际案例来说明它们的优化效果。
```python
# 代码示例:使用Parquet存储格式
CREATE TABLE user_data
STORED AS PARQUET
AS
SELECT * FROM raw_user_data;
# 优化后的查询
SET hive.exec.compress.output=true;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
```
上述代码示例展示了如何使用Parquet存储格式以及Snappy数据压缩方式来优化数据存储,我们将详细说明优化后的性能提升。
### 5.3 Hive执行计划优化
在这一节中,我们将深入解析Hive的执行计划,探讨如何通过理解和优化执行计划来提升查询性能。我们将介绍如何使用EXPLAIN关键字来查看和分析执行计划,以及如何根据执行计划进行优化调整。
```go
// 代码示例:查看查询执行计划
EXPLAIN SELECT * FROM user_logs WHERE date='20220101' AND event='login';
// 优化调整后的查询执行计划
SET hive.cbo.enable=true;
SET hive.compute.query.using.stats=true;
EXPLAIN SELECT * FROM user_logs WHERE date='20220101' AND event='login';
```
上述代码示例展示了通过查看和调整执行计划来优化查询性能的过程,我们将详细说明优化后的执行计划和性能提升效果。
### 5.4 Hive性能调优实例
在这一节中,我们将通过实际的性能调优案例来说明如何对Hive进行综合性能优化。我们将选择一个复杂的查询任务,并结合各种优化技巧来逐步优化和提升其性能,通过实验结果来展示优化效果。
```javascript
// 代码示例:综合性能优化调整
SET hive.auto.convert.join=true;
SET hive.optimize.distinct.rewrite=true;
SET hive.vectorized.execution.enabled=true;
SELECT * FROM user_logs JOIN user_info ON user_logs.user_id = user_info.user_id WHERE user_logs.date='20220101';
```
上述代码示例展示了综合应用各种性能优化技巧来提升查询性能的过程,我们将通过实验结果和性能对比来说明综合性能优化的效果。
通过本章的学习,相信您能更加全面地了解Hive的性能优化与调优方法,从而更好地应用于实际场景中。
# 6. 实际应用案例
#### 6.1 Hive在大数据分析中的应用
Hive在大数据分析中扮演着重要的角色,它可以帮助我们从海量数据中提取有用的信息。以下是一个示例代码,展示了如何使用Hive进行大数据分析:
```java
import org.apache.hadoop.hive.cli.CliDriver;
import org.apache.hadoop.hive.conf.HiveConf;
import org.apache.hadoop.hive.ql.Driver;
import org.apache.hadoop.hive.ql.processors.CommandProcessorResponse;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
public class HiveAnalysisExample {
private static final String DRIVER_CLASS = "org.apache.hadoop.hive.jdbc.HiveDriver";
private static final String CONNECT_STRING = "jdbc:hive2://localhost:10000/default";
private static final String USERNAME = "hiveuser";
private static final String PASSWORD = "hivepassword";
public static void main(String[] args) {
try {
Class.forName(DRIVER_CLASS);
HiveConf hiveConf = new HiveConf();
hiveConf.set("hive.execution.engine", "tez");
Driver driver = new Driver(hiveConf);
// Connect to Hive server
CliDriver cliDriver = new CliDriver();
CommandProcessorResponse response = cliDriver.run("CONNECT " + CONNECT_STRING + " USER " + USERNAME + " PASSWORD " + PASSWORD);
if (response.getResponseCode() != 0) {
throw new Exception("Failed to connect to Hive server");
}
// Run a Hive query
response = cliDriver.run("SELECT year, COUNT(*) as count FROM sales GROUP BY year");
if (response.getResponseCode() != 0) {
throw new Exception("Failed to run Hive query");
}
// Process the query result
StructObjectInspector inspector = (StructObjectInspector) driver.getSchema();
List<Object> row = new ArrayList<>();
while (driver.getResults(row)) {
System.out.println("Year: " + row.get(0) + ", Count: " + row.get(1));
row.clear();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
该示例中,我们首先通过JDBC连接到Hive服务器,然后执行一个查询语句,统计了销售表中每年的销售总量。最后,我们通过遍历查询结果并打印出来。
这只是一个简单的示例,实际中可根据具体需求进行更复杂的大数据分析操作。
#### 6.2 Hive在数据仓库中的应用
Hive在数据仓库中的应用也十分广泛。它可以将结构化和非结构化数据以表的形式进行组织和管理,方便数据仓库的查询和分析。以下是一个示例代码,展示了如何使用Hive构建一个简单的数据仓库:
```python
from pyhive import hive
# Connect to Hive server
conn = hive.Connection(host="localhost", port=10000, username="hiveuser", database="default")
cursor = conn.cursor()
# Create a table to store sales data
cursor.execute("CREATE TABLE IF NOT EXISTS sales (id INT, product STRING, quantity INT)")
# Load data into the table from a CSV file
cursor.execute("LOAD DATA INPATH '/path/to/sales.csv' INTO TABLE sales")
# Query the data warehouse
cursor.execute("SELECT product, SUM(quantity) as total FROM sales GROUP BY product")
# Fetch and print the query result
result = cursor.fetchall()
for row in result:
print("Product: {0}, Total Quantity: {1}".format(row[0], row[1]))
# Close the connection
cursor.close()
conn.close()
```
这个示例中,我们使用Python的Hive客户端(pyhive)连接到Hive服务器,并通过执行HiveQL语句来创建表、导入数据,并进行查询。最后,我们通过遍历查询结果并打印出来。
#### 6.3 Hive在数据挖掘和机器学习中的应用
Hive在数据挖掘和机器学习领域的应用也越来越多。它可以处理大规模的数据集,并提供了数据处理、特征工程和模型训练等功能。以下是一个示例代码,展示了如何使用Hive进行机器学习任务:
```python
from pyhive import hive
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Connect to Hive server
conn = hive.Connection(host="localhost", port=10000, username="hiveuser", database="default")
cursor = conn.cursor()
# Load data from Hive table into pandas DataFrame
cursor.execute("SELECT * FROM iris_dataset") # assuming iris_dataset is a table in Hive
result = cursor.fetchall()
data = []
labels = []
for row in result:
data.append(row[:-1])
labels.append(row[-1])
# Split the data into training set and test set
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
# Train a random forest classifier using the training set
classifier = RandomForestClassifier(n_estimators=100)
classifier.fit(X_train, y_train)
# Predict the labels for the test set
predictions = classifier.predict(X_test)
# Calculate the accuracy of the classifier
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: {0}".format(accuracy))
# Close the connection
cursor.close()
conn.close()
```
在这个示例中,我们首先通过Hive连接到Hive服务器,并从一个Hive表中加载数据到pandas DataFrame中。然后,我们将数据集拆分成训练集和测试集,使用随机森林分类器进行训练,并对测试集进行预测。最后,我们计算分类器的准确率并打印出来。
#### 6.4 Hive在实时数据处理中的应用
虽然Hive主要用于批处理操作,但它也可以与其他实时处理框架(如Storm、Spark Streaming)结合使用,以实现实时数据处理。以下是一个示例代码,展示了如何使用Hive与Spark Streaming进行实时数据处理:
```java
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.api.java.JavaStreamingContextFactory;
public class HiveRealTimeProcessingExample {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("HiveRealTimeProcessingExample");
JavaStreamingContextFactory factory = new JavaStreamingContextFactory() {
@Override
public JavaStreamingContext create() {
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkContext, Durations.seconds(1));
// Read data from Kafka topic
JavaPairDStream<String, String> kafkaStream = KafkaUtils.createStream(streamingContext,
"localhost:2181", "group-id", Collections.singletonMap("topic", 1), StorageLevel.MEMORY_ONLY());
// Process the data
JavaDStream<String> processedStream = kafkaStream.flatMap(new FlatMapFunction<Tuple2<String, String>, String>() {
@Override
public Iterator<String> call(Tuple2<String, String> input) throws Exception {
// Process the input data
return Arrays.asList(input._2().split(" ")).iterator();
}
});
// Perform some aggregation
JavaPairDStream<String, Integer> wordCountStream = processedStream.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<>(word, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer count1, Integer count2) throws Exception {
return count1 + count2;
}
});
// Store the result in Hive table
wordCountStream.foreachRDD(new VoidFunction<JavaPairRDD<String, Integer>>() {
@Override
public void call(JavaPairRDD<String, Integer> rdd) throws Exception {
rdd.foreachPartition(new VoidFunction<Iterator<Tuple2<String, Integer>>>() {
@Override
public void call(Iterator<Tuple2<String, Integer>> iterator) throws Exception {
Connection conn = DriverManager.getConnection("jdbc:hive2://localhost:10000/default", "hiveuser", "hivepassword");
Statement stmt = conn.createStatement();
while (iterator.hasNext()) {
Tuple2<String, Integer> tuple = iterator.next();
stmt.executeUpdate("INSERT INTO word_count(word, count) VALUES('" + tuple._1() + "', " + tuple._2() + ")");
}
stmt.close();
conn.close();
}
});
}
});
return streamingContext;
}
};
JavaStreamingContext streamingContext = JavaStreamingContext.getOrCreate("/tmp/checkpoint", factory);
streamingContext.start();
streamingContext.awaitTermination();
}
}
```
在这个示例中,我们首先创建一个Spark Streaming上下文,并从Kafka主题中读取数据。然后,我们对数据进行处理和聚合,并将结果存储到Hive表中。
这只是一个简单的示例,实际中可根据具体需求进行更复杂的实时数据处理操作。
以上是Hive在实际应用中的一些案例,它在大数据分析、数据仓库、数据挖掘和实时数据处理等领域都发挥着重要的作用。无论是处理海量数据还是进行复杂的数据分析,Hive都是一个强大的工具选择。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
WiFi信号穿透力测试:障碍物影响分析与解决策略!

# 摘要
本文探讨了WiFi信号穿透力的基本概念、障碍物对WiFi信号的影响,以及提升信号穿透力的策略。通过理论和实验分析,阐述了不同材质障碍物对信号传播的影响,以及信号衰减原理。在此基础上,提出了结合理论与实践的解决方案,包括技术升级、网络布局、设备选择、信号增强器使用和网络配置调整等。文章还详细介绍了WiFi信
【Rose状态图在工作流优化中的应用】:案例详解与实战演练
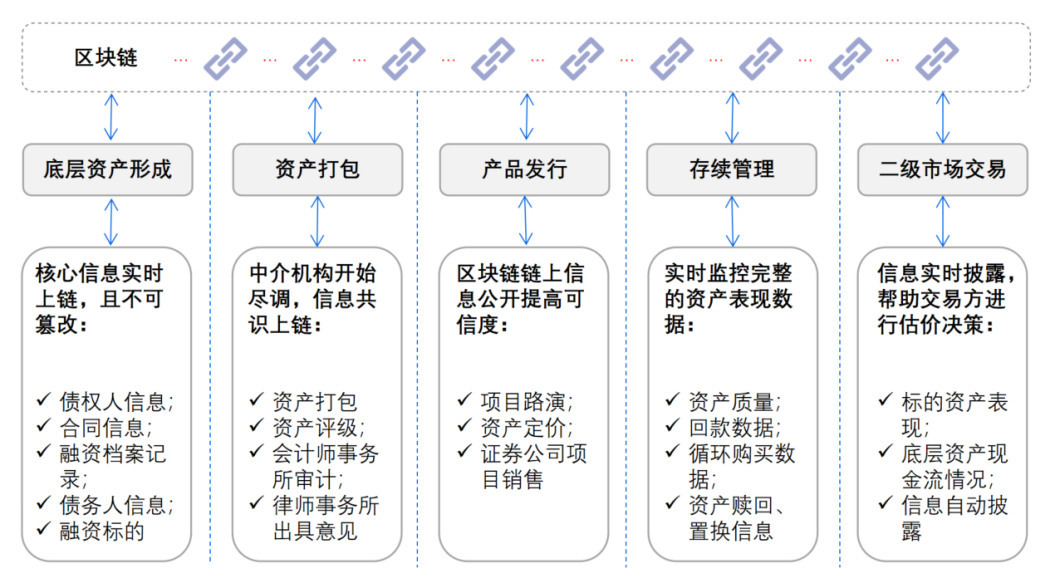
# 摘要
Rose状态图作为一种建模工具,在工作流优化中扮演了重要角色,提供了对复杂流程的可视化和分析手段。本文首先介绍Rose状态图的基本概念、原理以及其在工作流优化理论中的应用基础。随后,通过实际案例分析,探讨了Rose状态图在项目管理和企业流程管理中的应用效果。文章还详细阐述了设计和绘制Rose状态图的步骤与技巧,并对工作流优化过程中使用Rose状态图的方
Calibre DRC_LVS集成流程详解:无缝对接设计与制造的秘诀

# 摘要
Calibre DRC_LVS作为集成电路设计的关键验证工具,确保设计的规则正确性和布局与原理图的一致性。本文深入分析了Calibre DRC_LVS的理论基础和工作流程,详细说明了其在实践操作中的环境搭建、运行分析和错误处理。同时,文章探讨了Calibre DRC_LVS的高级应用,包括定制化、性能优化以及与制造工艺的整合。通过具体案例研究,本文展示了Calibre在解决实际设计
【DELPHI图形编程案例分析】:图片旋转功能实现与优化的详细攻略

# 摘要
本文专注于DELPHI图形编程中图片旋转功能的实现和性能优化。首先从理论分析入手,探讨了图片旋转的数学原理、旋转算法的选择及平衡硬件加速与软件优化。接着,本文详细阐述了在DELPHI环境下图片旋转功能的编码实践、性能优化措施以及用户界面设计与交互集成。最后,通过案例分析,本文讨论了图片旋转技术的实践应用和未来的发展趋势,提出了针对新兴技术的优化方向与技术挑战。
台达PLC程序性能优化全攻略:WPLSoft中的高效策略
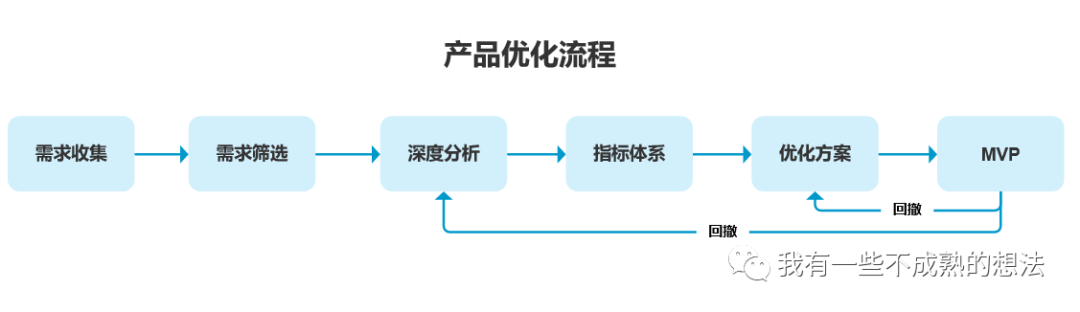
# 摘要
本文详细介绍了台达PLC及其编程环境WPLSoft的基本概念和优化技术。文章从理论原理入手,阐述了PLC程序性能优化的重要性,以及关键性能指标和理论基础。在实践中,通过WPLSoft的编写规范、高级编程功能和性能监控工具的应用,展示了性能优化的具体技巧。案例分析部分分享了高速生产线和大型仓储自动化系统的实际优化经验,为实际工业应用提供了宝贵的参考。进阶应用章节讨论了结合工业现场的优化
【SAT文件实战指南】:快速诊断错误与优化性能,确保数据万无一失
+Error.jpg)
# 摘要
SAT文件作为一种重要的数据交换格式,在多个领域中被广泛应用,其正确性与性能直接影响系统的稳定性和效率。本文旨在深入解析SAT文件的基础知识,探讨其结构和常见错误类型,并介绍理论基础下的错误诊断方法。通过实践操作,文章将指导读者使用诊断工具进行错误定位和修复,并分析性能瓶颈,提供优化策略。最后,探讨SAT文件在实际应用中的维护方法,包括数据安全、备份和持
【MATLAB M_map个性化地图制作】:10个定制技巧让你与众不同
# 摘要
本文深入探讨了MATLAB环境下M_map工具的配置、使用和高级功能。首先介绍了M_map的基本安装和配置方法,包括对地图样式的个性化定制,如投影设置和颜色映射。接着,文章阐述了M_map的高级功能,包括自定义注释、图例的创建以及数据可视化技巧,特别强调了三维地图绘制和图层管理。最后,本文通过具体应用案例,展示了M_map在海洋学数据可视化、GIS应用和天气气候研究中的实践。通过这些案例,我们学习到如何利用M_map工具包增强地图的互动性和动画效果,以及如何创建专业的地理信息系统和科学数据可视化报告。
# 关键字
M_map;数据可视化;地图定制;图层管理;交互式地图;动画制作
【ZYNQ缓存管理与优化】:降低延迟,提高效率的终极策略
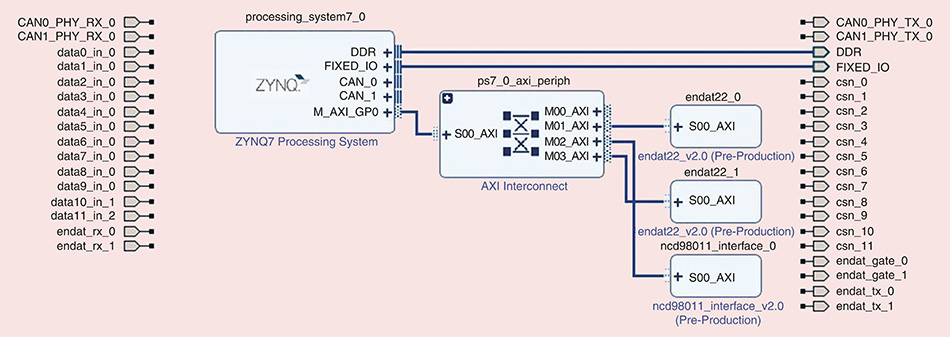
# 摘要
ZYNQ缓存管理是优化处理器性能的关键技术,尤其在多核系统和实时应用中至关重要。本文首先概述了ZYNQ缓存管理的基本概念和体系结构,探讨了缓存层次、一致性协议及性能优化基础。随后,分析了缓存性能调优实践,包括命中率提升、缓存污染处理和调试工具的应用。进一步,本文探讨了缓存与系统级优化的协同
RM69330 vs 竞争对手:深度对比分析与最佳应用场景揭秘

# 摘要
本文全面比较了RM69330与市场上其它竞争产品,深入分析了RM69330的技术规格和功能特性。通过核心性能参数对比、功能特性分析以及兼容性和生态系统支持的探讨,本文揭示了RM69330在多个行业中的应用潜力,包括消费电子、工业自动化和医疗健康设备。行业案例与应用场景分析部分着重探讨了RM69330在实际使用中的表现和效益。文章还对RM69330的市场表现进行了评估,并提供了应
Proton-WMS集成应用案例深度解析:打造与ERP、CRM的完美对接

# 摘要
本文综述了Proton-WMS(Warehouse Management System)在企业应用中的集成案例,涵盖了与ERP(Enterprise Resource Planning)系统和CRM(Customer Relationship Managemen
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )