【Django Manager在大型项目中的应用】:揭秘高效使用Manager的策略
发布时间: 2024-10-13 21:47:43 阅读量: 23 订阅数: 28 

# 1. Django Manager的基本概念和作用
## 什么是Django Manager?
Django Manager是Django ORM(对象关系映射)的核心组件之一,它负责管理数据库查询,并返回QuerySet对象。简单来说,Manager就是数据库查询的入口点。每个Django模型至少有一个默认的Manager,通常通过模型类的objects属性访问。
## Manager的作用
Manager的主要作用是提供一系列的数据库操作方法,使得开发者能够方便地与数据库进行交互,而无需直接编写SQL语句。它隐藏了底层的复杂性,允许开发者使用Python代码来查询、更新和删除数据库中的记录。
## Manager的重要性
在Django中,Manager的作用不仅仅是简化数据库操作,它还支持自定义查询方法,使得开发者可以根据特定的需求扩展Manager的功能。这是Django强大和灵活的一个体现,也是为什么在大型项目中,正确使用和优化Manager是提升性能的关键。
通过以上内容,我们可以看出,理解和掌握Django Manager对于开发高效的Django应用至关重要。接下来的章节将深入探讨Manager的常用方法、高级应用以及如何在实际项目中进行性能优化和应用。
# 2. Django Manager的常用方法和扩展
在本章节中,我们将深入探讨Django Manager的核心功能,包括其常用方法以及如何通过自定义Manager类和QuerySet类来扩展其功能。我们还将介绍一些高级应用,如聚合查询、分组、事务和数据库锁定等。
## 2.1 Django Manager的常用方法
Django Manager提供了一系列的方法来帮助我们更有效地查询和操作数据库。以下是最常用的几种方法:
### 2.1.1 filter()和exclude()方法
`filter()`方法用于获取满足特定条件的对象集合,而`exclude()`方法则用于获取不满足条件的对象集合。这两个方法都接受关键字参数,其中关键字的参数名是模型字段名,参数值是要匹配的值。
#### 示例代码:
```python
from django.db.models import Q
from myapp.models import Article
# 获取所有标题包含"django"的文章
articles_with_django = Article.objects.filter(title__contains="django")
# 获取所有标题不包含"django"的文章
articles_without_django = Article.objects.exclude(title__contains="django")
# 使用Q对象进行复杂查询
articles_with_or_without_django = Article.objects.filter(
Q(title__contains="django") | Q(author="John Doe")
)
```
#### 参数说明和逻辑分析:
- `filter()`和`exclude()`方法接受的参数是一个或多个关键字参数,其中关键字的参数名是模型字段名,参数值是要匹配的值。
- `Q`对象允许我们构建复杂的查询条件。例如,`Q(title__contains="django") | Q(author="John Doe")`表示查询标题包含"django"或者作者是"John Doe"的文章。
### 2.1.2 order_by()和distinct()方法
`order_by()`方法用于指定返回对象的排序方式,而`distinct()`方法用于返回唯一不同的查询集。
#### 示例代码:
```python
# 按标题升序排序的文章
articles_ordered_by_title = Article.objects.order_by('title')
# 按标题降序排序的文章
articles_ordered_by_title_desc = Article.objects.order_by('-title')
# 获取不同标题的文章
articles_with_distinct_titles = Article.objects.order_by('title').distinct()
```
#### 参数说明和逻辑分析:
- `order_by()`方法接受字段名作为参数,可以使用`-`表示降序排序。
- `distinct()`方法在使用时需要注意,虽然它可以返回不同的对象,但并非所有数据库后端都支持这一操作。在PostgreSQL中,可以使用`distinct('field_name')`来指定对某个字段进行去重。
## 2.2 Django Manager的自定义方法
在本节中,我们将介绍如何自定义Manager类和QuerySet类,以便提供更丰富的查询功能。
### 2.2.1 自定义Manager类
自定义Manager类允许我们添加自定义方法,这些方法将作为QuerySet方法来使用。
#### 示例代码:
```python
from django.db.models import Manager
class ArticleManager(Manager):
def get_queryset(self):
return super().get_queryset().filter(published=True)
class Article(models.Model):
# ...
objects = ArticleManager()
```
#### 参数说明和逻辑分析:
- 在自定义Manager类中,`get_queryset()`方法被重写以改变默认的查询集。
- 在上述例子中,`ArticleManager`过滤掉未发布的文章,只返回已发布的文章。
### 2.2.2 自定义QuerySet类
自定义QuerySet类可以让我们创建更复杂的查询操作。
#### 示例代码:
```python
from django.db.models import QuerySet
class CustomQuerySet(QuerySet):
def published(self):
return self.filter(published=True)
class ArticleManager(Manager):
def get_queryset(self):
return CustomQuerySet(self.model, using=self._db)
published = published
class Article(models.Model):
# ...
objects = ArticleManager()
```
#### 参数说明和逻辑分析:
- `CustomQuerySet`类继承自`QuerySet`,并添加了一个`published()`方法。
- `ArticleManager`使用`CustomQuerySet`作为其查询集,这样就可以在`Article.objects.published()`中调用`published`方法。
## 2.3 Django Manager的高级应用
在本节中,我们将介绍一些高级应用,如聚合查询和分组、事务和数据库锁定。
### 2.3.1 聚合查询和分组
使用Django的聚合框架可以执行SQL中的`COUNT`、`SUM`、`AVG`等聚合操作。
#### 示例代码:
```python
from django.db.models import Count, Avg
# 计算文章的总数
total_articles = Article.objects.aggregate(Count('id'))
# 计算每个作者的文章数
articles_per_author = Article.objects.values('author').annotate(count=Count('id'))
```
#### 参数说明和逻辑分析:
- `aggregate()`方法执行一个单一的聚合查询,返回一个字典。
- `annotate()`方法在查询集的每个对象上添加一个新的字段,这里计算每个作者的文章数。
### 2.3.2 事务和数据库锁定
Django提供了事务控制工具,可以帮助我们确保数据库的完整性和一致性。
#### 示例代码:
```python
from django.db import transaction
@transaction.atomic
def update_author的文章(author):
# 这个代码块中的所有数据库操作都将作为一个单一的事务执行
author.article_set.update(published=True)
```
#### 参数说明和逻辑分析:
- `@transaction.atomic`装饰器确保被装饰的函数在一个事务中执行。
- 如果函数执行过程中发生异常,整个事务将回滚,数据库将保持不变。
通过本章节的介绍,我们深入了解了Django Manager的常用方法和如何通过自定义Manager类和QuerySet类来扩展其功能。同时,我们也探索了一些高级应用,如聚合查询、分组、事务和数据库锁定。在接下来的章节中,我们将继续深入探讨Django Manager的性能优化和在大型项目中的应用。
# 3. Django Manager在大型项目中的性能优化
在本章节中,我们将深入探讨如何通过Django Manager来优化大型项目中的数据库查询,以及如何实施有效的缓存策略和并发控制,以提高应用的性能和响应速度。
## 3.1 Django Manager的查询优化
在大型项目中,数据库查询优化是至关重要的,因为它直接关系到应用的响应时间和用户体验。Django Manager提供了多种工具和方法来帮助我们实现这一目标。
### 3.1.1 使用select_related和prefetch_related优化查询
`select_related`和`prefetch_related`是Django ORM中的两个强大功能,它们可以帮助我们减少数据库的查询次数,从而优化查询性能。
#### select_related
`select_related`用于优化外键和一对一关系的查询。它通过SQL的JOIN语句来获取相关对象,从而减少数据库的查询次数。
```python
# 假设我们有一个Author模型和一个Book模型,它们之间是一对多的关系
class Author(models.Model):
name = models.CharField(max_length=100)
class Book(models.Model):
title = models.CharField(max_length=100)
author = models.ForeignKey(Author, on_delete=models.CASCADE)
# 使用select_related优化查询
authors = Author.objects.select_related('book_set').all()
for author in authors:
print(author.book_set.all()) # 这里不会触发额外的数据库查询
```
`select_related`通过在一次查询中连接`author`和`book_set`表,减少了后续访问`Book`对象时的数据库查询次数。
#### prefetch_related
`prefetch_related`用于优化多对多关系和反向外键关系的查询。它通过两个独立的SQL查询获取相关对象列表,然后在Python中进行组合,减少了数据库的查询次数。
```python
# 假设我们有一个Publisher模型和一个Book模型,它们之间是多对多的关系
class Publisher(models.Model):
name = models.CharField(max_length=100)
class Book(models.Model):
title = models.CharField(max_length=100)
publisher = models.ManyToManyField(Publisher)
# 使用prefetch_related优化查询
publishers = Publisher.objects.prefetch_related('book_set').all()
for publisher in publishers:
print(publisher.book_set.all()) # 这里不会触发额外的数据库查询
```
`prefetch_related`通过两个独立的SQL查询获取`Publisher`对象及其关联的`Book`对象列表,减少了对数据库的查询次数。
### 3.1.2 使用values()和values_list()优化查询
`values()`和`values_list()`是Django ORM中用于优化数据检索的工具,它们可以帮助我们减少传输的数据量,从而优化查询性能。
#### values()
`values()`方法返回一个`ValuesQuerySet`,它包含字典形式的记录,这样可以减少数据传输量。
```python
# 使用values()优化查询
books = Book.objects.values('id', 'title')
for book in books:
print(book['id'], book['title'])
```
`values()`通过返回字典形式的记录,减少了数据传输量,提高了查询效率。
#### values_list()
`values_list()`方法返回一个`ValuesListQuerySet`,它包含元组形式的记录,这样可以减少数据传输量。
```python
# 使用values_list()优化查询
titles = Book.objects.values_list('title', flat=True)
for title in titles:
print(title)
```
`values_list()`通过返回元组形式的记录,减少了数据传输量,提高了查询效率。
## 3.2 Django Manager的缓存策略
缓存是提高大型项目性能的关键策略之一。Django Manager提供了多种方法来实现对象缓存和使用Django缓存框架。
### 3.2.1 使用django对象缓存
Django对象缓存是通过`django.core.cache`模块实现的,它可以将

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Django.db.models.manager,这是 Django ORM 中一个强大的工具,用于管理和查询数据库数据。它涵盖了从基础用法到高级优化技巧的广泛主题,包括自定义管理器、扩展查询集、优化数据库交互、处理事务、利用信号、实施缓存策略、支持多数据库、处理自定义字段类型、集成 REST API、进行数据迁移、实现数据同步、异步操作和性能监控。通过深入的分析、示例代码和最佳实践,本专栏旨在帮助 Django 开发人员掌握 Manager 的核心概念,并将其应用于构建高效、可扩展和可维护的 Web 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【51单片机矩阵键盘扫描终极指南】:全面解析编程技巧及优化策略

# 摘要
本论文主要探讨了基于51单片机的矩阵键盘扫描技术,包括其工作原理、编程技巧、性能优化及高级应用案例。首先介绍了矩阵键盘的硬件接口、信号特性以及单片机的选择与配置。接着深入分析了不同的扫
【Pycharm源镜像优化】:提升下载速度的3大技巧

# 摘要
Pycharm作为一款流行的Python集成开发环境,其源镜像配置对开发效率和软件性能至关重要。本文旨在介绍Pycharm源镜像的重要性,探讨选择和评估源镜像的理论基础,并提供实践技巧以优化Pycharm的源镜像设置。文章详细阐述了Pycharm的更新机制、源镜像的工作原理、性能评估方法,并提出了配置官方源、利用第三方源镜像、缓存与持久化设置等优化技巧。进一步,文章探索了多源镜像组
【VTK动画与交互式开发】:提升用户体验的实用技巧
# 摘要
本文旨在介绍VTK(Visualization Toolkit)动画与交互式开发的核心概念、实践技巧以及在不同领域的应用。通过详细介绍VTK动画制作的基础理论,包括渲染管线、动画基础和交互机制等,本文阐述了如何实现动画效果、增强用户交互,并对性能进行优化和调试。此外,文章深入探讨了VTK交互式应用的高级开发,涵盖了高级交互技术和实用的动画
【转换器应用秘典】:RS232_RS485_RS422转换器的应用指南
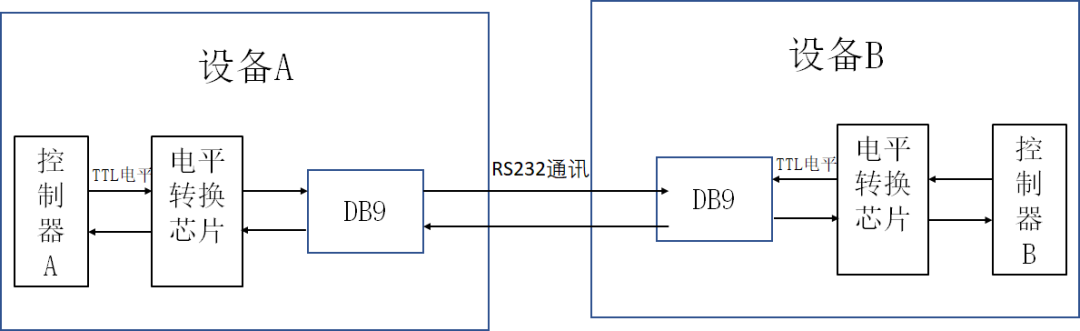
# 摘要
本论文全面概述了RS232、RS485、RS422转换器的原理、特性及应用场景,并深入探讨了其在不同领域中的应用和配置方法。文中不仅详细介绍了转换器的理论基础,包括串行通信协议的基本概念、标准详解以及转换器的物理和电气特性,还提供了转换器安装、配置、故障排除及维护的实践指南。通过分析多个实际应用案例,论文展示了转
【Strip控件多语言实现】:Visual C#中的国际化与本地化(语言处理高手)

# 摘要
本文全面探讨了Visual C#环境下应用程序的国际化与本地化实施策略。首先介绍了国际化基础和本地化流程,包括本地化与国际化的关系以及基本步骤。接着,详细阐述了资源文件的创建与管理,以及字符串本地化的技巧。第三章专注于Strip控件的多语言实现,涵盖实现策略、高级实践和案例研究。文章第四章则讨论了多语言应用程序的最佳实践和性能优化措施。最后,第五章通过具体案例分析,总结了国际化与本地化的核心概念,并展望了未来的技术趋势。
# 关
C++高级话题:处理ASCII文件时的异常处理完全指南
# 摘要
本文旨在探讨异常处理在C++编程中的重要性以及处理ASCII文件时如何有效地应用异常机制。首先,文章介绍了ASCII文件的基础知识和读写原理,为理解后续异常处理做好铺垫。接着,文章深入分析了C++中的异常处理机制,包括基础语法、标准异常类使用、自定义异常以及异常安全性概念与实现。在此基础上,文章详细探讨了C++在处理ASCII文件时的异常情况,包括文件操作中常见异常分析和异常处理策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )