【Django Manager与多数据库支持】:配置与使用,一文搞定
发布时间: 2024-10-13 22:00:17 阅读量: 33 订阅数: 29 

django 多数据库配置教程

# 1. Django Manager的介绍和基本用法
## 简介
Django是一个高级的Python Web框架,它鼓励快速开发和干净、实用的设计。在Django中,`Manager`是模型与数据库之间的接口,它负责与数据库进行所有交流。默认情况下,每个Django模型都有一个名为`objects`的Manager,它能够处理与数据库相关的大多数操作。
## 基本用法
### 创建记录
要创建一个新的记录,您可以直接调用模型的`objects.create()`方法:
```python
from myapp.models import MyModel
new_record = MyModel.objects.create(field1="value1", field2="value2")
```
### 更新记录
更新记录可以使用`update()`方法,这将更新所有匹配查询条件的记录:
```python
MyModel.objects.filter(field1="value1").update(field2="new_value")
```
### 删除记录
删除记录可以使用`delete()`方法,这将删除所有匹配查询条件的记录:
```python
MyModel.objects.filter(field1="value1").delete()
```
### 查询记录
查询记录是通过调用`objects`上的查询方法实现的,例如`all()`, `filter()`, `get()`等:
```python
all_records = MyModel.objects.all()
filtered_records = MyModel.objects.filter(field1="value1")
```
以上是Django Manager的基本用法,通过这些方法可以轻松地进行数据库的增删改查操作。在接下来的章节中,我们将深入探讨如何配置Django以支持多数据库,并利用Manager进行更高级的数据库操作。
# 2. 配置Django以支持多数据库
在本章节中,我们将深入探讨如何在Django项目中配置和使用多数据库。我们将从基本的数据库配置开始,逐步深入到数据库路由的创建和自定义,以及如何使用不同的数据库进行操作。通过本章节的介绍,你将能够掌握Django多数据库配置的核心概念和技术细节。
## 2.1 Django项目的数据库配置
Django默认使用单一数据库配置,但是随着应用的扩展,可能需要连接多个数据库。本节将介绍如何在Django项目中配置默认数据库,以及如何添加额外的数据库。
### 2.1.1 配置默认数据库
在Django项目的`settings.py`文件中,你会找到名为`DATABASES`的配置项,这是Django的数据库配置核心。默认情况下,Django使用SQLite作为数据库,但在生产环境中,我们通常会配置为MySQL、PostgreSQL或Oracle等更强大的数据库系统。
```python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'mydatabase',
'USER': 'mydatabaseuser',
'PASSWORD': 'mypassword',
'HOST': '***.*.*.*',
'PORT': '5432',
}
}
```
在上述配置中,我们定义了默认数据库的数据库引擎、数据库名称、用户、密码、主机和端口。这里使用的是PostgreSQL数据库,你也可以根据实际情况选择其他数据库引擎。
### 2.1.2 添加额外的数据库
为了支持多数据库,我们可以在`DATABASES`设置中添加额外的数据库配置。每个数据库配置都是一个字典,可以有多个键值对来配置不同的数据库。
```python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'mydatabase',
'USER': 'mydatabaseuser',
'PASSWORD': 'mypassword',
'HOST': '***.*.*.*',
'PORT': '5432',
},
'extra': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'myoth数据库',
'USER': 'myothuser',
'PASSWORD': 'myothpassword',
'HOST': '***.*.*.*',
'PORT': '3306',
}
}
```
在这个例子中,我们添加了一个名为`extra`的额外数据库配置,它使用MySQL数据库。通过这样的配置,你可以在Django项目中使用多个数据库。
## 2.2 Django的数据库路由
数据库路由是Django多数据库配置的关键,它允许你定义在哪个数据库上执行哪些操作。本节将介绍数据库路由的基本概念和如何创建自定义的数据库路由。
### 2.2.1 数据库路由的基本概念
数据库路由可以通过`DATABASE_ROUTERS`设置来定义。这个设置是一个包含数据库路由器类的字符串列表。当Django需要执行数据库操作时,它会根据数据库路由来确定使用哪个数据库。
```python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'mydatabase',
# ... 其他配置
},
'extra': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'myoth数据库',
# ... 其他配置
}
}
DATABASE_ROUTERS = ['path.to.MyCustomRouter']
```
在这个例子中,我们定义了一个自定义的数据库路由器`MyCustomRouter`,并将其添加到`DATABASE_ROUTERS`设置中。
### 2.2.2 创建自定义的数据库路由
自定义数据库路由器需要继承`BaseDatabaseRouter`类,并实现`db_for_read`、`db_for_write`、`allow_relation`和`allow_migrate`方法。这些方法决定了模型在读取、写入、关联和迁移时应该使用哪个数据库。
```python
from django.db import routers
class MyCustomRouter(routers.BaseDatabaseRouter):
def db_for_read(self, model, **hints):
if model._meta.app_label == 'myapp':
return 'extra'
return None
def db_for_write(self, model, **hints):
if model._meta.app_label == 'myapp':
return 'extra'
return None
def allow_relation(self, obj1, obj2, **hints):
if obj1._meta.app_label == 'myapp' or obj2._meta.app_label == 'myapp':
return True
return None
def allow_migrate(self, db, app_label, model_name=None, **hints):
if app_label == 'myapp':
return db == 'extra'
return None
```
在这个例子中,我们创建了一个自定义数据库路由器`MyCustomRouter`,它将`myapp`应用的所有读写操作路由到`extra`数据库。
## 2.3 Django的数据库连接和操作
Django提供了强大的API来连接和操作数据库。本节将介绍如何使用不同的数据库进行查询,以及如何管理数据库事务。
### 2.3.1 使用不同的数据库进行查询
在Django中,你可以使用默认的查询集API来对不同数据库进行操作。Django会根据模型的数据库路由器来决定使用哪个数据库。
```python
from myapp.models import MyModel
# 使用默认数据库
default_obj = MyModel.objects.using('default').get(id=1)
# 使用额外的数据库
extra_obj = MyModel.objects.using('extra').get(id=1)
```
在这个例子中,我们使用`using`方法来指定查询应该使用的数据库。
### 2.3.2 数据库事务的管理
Django提供了事务控制API,可以帮助你确保数据的一致性。你可以使用`transaction`模块来管理数据库事务。
```python
from django.db import transaction
def my_view(request):
with transaction.atomic():
# 在这个代码块中,所有的数据库操作都会作为一个事务来执行
# 如果其中一个操作失败,所有的操作都会被回滚
pass
```
在这个例子中,我们使用`transaction.atomic`来创建一个事务块。在这个块中的所有数据库操作都会作为一个事务来执行,如果其中一个操作失败,所有的操作都会被回滚。
通过本章节的介绍,我们了解了如何在Django项目中配置和使用多数据库,包括默认数据库的配置、额外数据库的添加、数据库路由的创建和自定义,以及如何使用不同的数据库进行查询和管理数据库事务。在下一章节中,我们将进一步探讨如何使用Django Manager进行数据库操作。
# 3. 使用Django Manager进行数据库操作
在本章节中,我们将深入探讨如何使用Django Manager进行数据库操作。我们将从基本操作开始,然后逐步介绍高级功能,并最终讲解如何进行自定义Manager以满足特定需求。
## 3.1 Django Manager的基本操作
### 3.1.1 创建、更新和删除记录
Django Manager提供了一系列内置的方法来处理数据库中的记录。其中最基本的三个操作是创建、更新和删除。
#### 创建记录
在Django中,创建记录通常使用模型实例的`save()`方法。例如:
```python
from myapp.models import MyModel
obj = MyModel(field1='value1', field2='value2')
obj.save()
```
在这个例子中,我们首先导入了`MyModel`模型,然后创建了一个新的实例,并设置了其字段的值,最后调用`save()`方法将记录保存到数据库中。
#### 更新记录
更新记录可以通过两种方式完成:使用`update()`方法更新多条记录,或者使用`save()`方法更新单条记录。
```python
# 更新多条记录
MyModel.objects.filter(field1='value1').update(field2='new_value')
# 更新单条记录
obj = MyModel.objects.get(id=1)
obj.field2 = 'new_value'
obj.save()
```
在这个例子中,我们使用`filter()`方法来获取所有`field1`为`value1`的记录,并将它们的`field2`字段更新为`new_value`。对于单条记录的更新,我们首先获取了一个具体的实例,然后修改了其字段的值,最后调用`save()`方法保存更改。
#### 删除记录
删除记录可以使用`delete()`方法。例如:
```python
# 删除多条记录
MyModel.objects.filter(field1='value1').delete()
# 删除单条记录
obj = MyModel.objects.
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Django.db.models.manager,这是 Django ORM 中一个强大的工具,用于管理和查询数据库数据。它涵盖了从基础用法到高级优化技巧的广泛主题,包括自定义管理器、扩展查询集、优化数据库交互、处理事务、利用信号、实施缓存策略、支持多数据库、处理自定义字段类型、集成 REST API、进行数据迁移、实现数据同步、异步操作和性能监控。通过深入的分析、示例代码和最佳实践,本专栏旨在帮助 Django 开发人员掌握 Manager 的核心概念,并将其应用于构建高效、可扩展和可维护的 Web 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Adblock Plus高级应用:如何利用过滤器提升网页加载速度

# 摘要
本文全面介绍了Adblock Plus作为一款流行的广告拦截工具,从其基本功能到高级过滤策略,以及社区支持和未来的发展方向进行了详细探讨。首先,文章概述了Adb
【QCA Wi-Fi源代码优化指南】:性能与稳定性提升的黄金法则

# 摘要
本文对QCA Wi-Fi源代码优化进行了全面的概述,旨在提升Wi-Fi性能和稳定性。通过对QCA Wi-Fi源代码的结构、核心算法和数据结构进行深入分析,明确了性能优化的关键点。文章详细探讨了代码层面的优化策略,包括编码最佳实践、性能瓶颈的分析与优化、以及稳定性改进措施。系统层面
网络数据包解码与分析实操:WinPcap技术实战指南
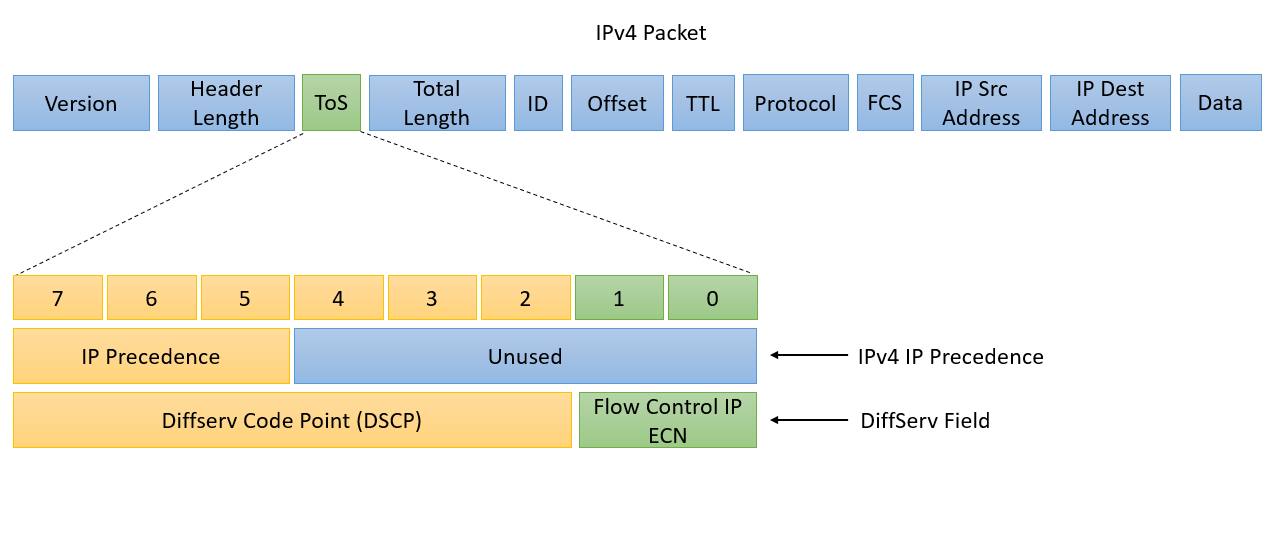
# 摘要
随着网络技术的不断进步,网络数据包的解码与分析成为网络监控、性能优化和安全保障的重要环节。本文从网络数据包解码与分析的基础知识讲起,详细介绍了WinPcap技术的核心组件和开发环境搭建方法,深入解析了数据包的结构和解码技术原理,并通过实际案例展示了数据包解码的实践过程。此外,本文探讨了网络数据分析与处理的多种技术,包括数据包过滤、流量分析,以及在网络安全中的应用,如入侵检测系统和网络
【EMMC5.0全面解析】:深度挖掘技术内幕及高效应用策略

# 摘要
EMMC5.0技术作为嵌入式存储设备的标准化接口,提供了高速、高效的数据传输性能以及高级安全和电源管理功能。本文详细介绍了EMMC5.0的技术基础,包括其物理结构、接口协议、性能特点以及电源管理策略。高级特性如安全机制、高速缓存技术和命令队列技术的分析,以及兼容性和测试方法的探讨,为读者提供了全面的EMMC5.0技术概览。最后,文章探讨了EMMC5.0在嵌入式系统中的应用以及未来的发展趋势和高效应用策略,强调了软硬
【高级故障排除技术】:深入分析DeltaV OPC复杂问题

# 摘要
本文旨在为DeltaV系统的OPC故障排除提供全面的指导和实践技巧。首先概述了故障排除的重要性,随后探讨了理论基础,包括DeltaV系统架构和OPC技术的角色、故障的分类与原因,以及故障诊断和排查的基本流程。在实践技巧章节中,详细讨论了实时数据通信、安全性和认证
手把手教学PN532模块使用:NFC技术入门指南
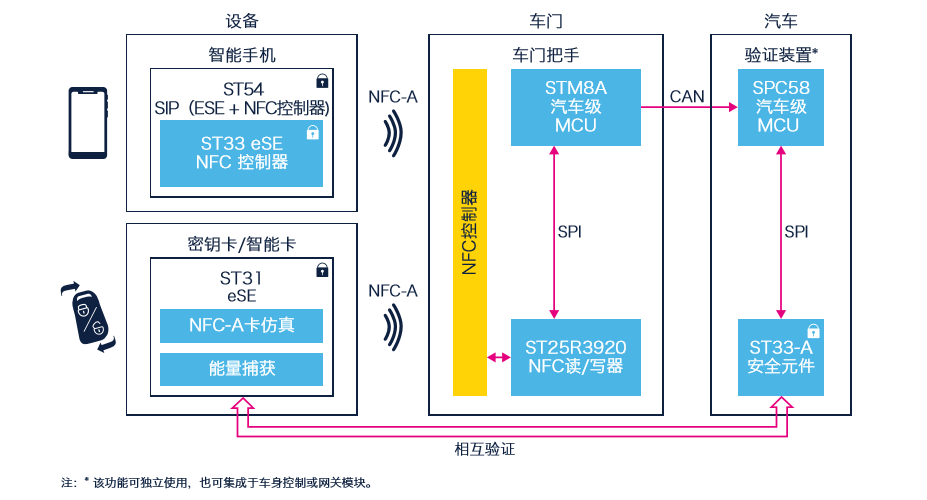
# 摘要
NFC(Near Field Communication,近场通信)技术是一项允许电子设备在短距离内进行无线通信的技术。本文首先介绍了NFC技术的起源、发展、工作原理及应用领域,并阐述了NFC与RFID(Radio-Frequency Identification,无线射频识别)技术的关系。随后,本文重点介绍了PN532模块的硬件特性、配置及读写基础,并探讨了
PNOZ继电器维护与测试:标准流程和最佳实践

# 摘要
PNOZ继电器作为工业控制系统中不可或缺的组件,其可靠性对生产安全至关重要。本文系统介绍了PNOZ继电器的基础知识、维护流程、测试方法和故障处理策略,并提供了特定应用案例分析。同时,针对未来发展趋势,本文探讨了新兴技术在PNOZ继电器中的应用前景,以及行业标准的更新和最佳实践的推广。通过对维护流程和故障处理的深入探讨,本文旨在为工程师提供实用的继电器维护与故障处
【探索JWT扩展属性】:高级JWT用法实战解析

# 摘要
本文旨在介绍JSON Web Token(JWT)的基础知识、结构组成、标准属性及其在业务中的应用。首先,我们概述了JWT的概念及其在身份验证和信息交换中的作用。接着,文章详细解析了JWT的内部结构,包括头部(Header)、载荷(Payload)和签名(Signature),并解释了标准属性如发行者(iss)、主题(sub)、受众(aud
Altium性能优化:编写高性能设计脚本的6大技巧

# 摘要
本文系统地探讨了基于Altium设计脚本的性能优化方法与实践技巧。首先介绍了Altium设计脚本的基础知识和性能优化的重要性,强调了缩短设计周期和提高系统资源利用效率的必要性。随后,详细解析了Altium设计脚本的运行机制及性能分析工具的应用。文章第三章到第四章重点讲述了编写高性能设计脚本的实践技巧,包括代码优化原则、脚
Qt布局管理技巧

# 摘要
本文深入探讨了Qt框架中的布局管理技术,从基础概念到深入应用,再到实践技巧和性能优化,系统地阐述了布局管理器的种类、特点及其适用场景。文章详细介绍了布局嵌套、合并技术,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )