【OrderedDict实战案例】:打造基于OrderedDict的高效LRU缓存
发布时间: 2024-10-16 07:26:17 阅读量: 22 订阅数: 25 

Java实现LRU缓存机制:深入解析与高效编码实践

# 1. OrderedDict的基本概念与原理
## 什么是OrderedDict?
在Python中,`OrderedDict`是一个字典子类,它记住了元素添加的顺序。这是通过维护一个双向链表来实现的,该链表记录了元素插入的顺序。这意味着,与普通字典不同,`OrderedDict`的迭代顺序与元素添加的顺序一致。
## 为什么需要OrderedDict?
在某些应用场景下,我们需要保持元素的顺序,例如实现一个缓存系统,需要根据最近最少使用(LRU)原则来移除元素。普通字典无法满足这种需求,因为它们不保留元素的插入顺序,而是通过哈希表来保持键值对,这意味着元素的顺序是不确定的。
## OrderedDict的工作原理
`OrderedDict`内部维护了一个双向链表来跟踪元素的顺序。当元素被插入时,它会被添加到双向链表的末尾,并且它的`__dictitem__`对象会被修改以包含前驱和后继指针。当元素被移除时,它的位置也会从双向链表中移除,以保持双向链表的顺序与字典中的元素顺序一致。
```python
from collections import OrderedDict
# 创建一个OrderedDict实例
ordered_dict = OrderedDict()
ordered_dict["a"] = 1
ordered_dict["b"] = 2
ordered_dict["c"] = 3
# 迭代OrderedDict,输出将是按照插入顺序
for key in ordered_dict:
print(key, ordered_dict[key])
```
通过上述代码,我们可以看到`OrderedDict`在插入时保持了元素的顺序,并且在迭代时按照这个顺序输出键值对。这使得`OrderedDict`成为实现LRU缓存等需要保持顺序的数据结构的理想选择。
# 2. OrderedDict在LRU缓存中的应用
### 2.1 LRU缓存的原理和重要性
#### 2.1.1 LRU缓存的工作机制
LRU(Least Recently Used)缓存是一种广泛使用的缓存策略,旨在通过淘汰最长时间未被访问的数据来维护缓存中数据的新鲜度。其工作机制可以概括为以下几个步骤:
1. 当缓存未满时,新访问的数据直接添加到缓存中。
2. 当缓存已满时,将访问的数据移动到缓存的最前端,表示最近被访问过。
3. 当需要淘汰数据时,移除最长时间未被访问的数据,即位于缓存最后的数据。
这种策略确保了缓存中总是保存了最近访问过的数据,从而提高了数据的访问命中率,减少了对后端存储的频繁访问,进而提升了系统的整体性能。
#### 2.1.2 LRU缓存与性能优化
在实际应用中,LRU缓存的引入可以显著减少对数据库的访问次数,尤其是在数据访问模式有明显热点的情况下。性能优化可以从以下几个方面着手:
1. **缓存大小的选择**:缓存大小需要根据系统的实际负载和数据访问模式来确定,以平衡内存的使用和性能的提升。
2. **缓存淘汰策略**:除了传统的LRU策略,还可以使用其他变种,如LRU-K、LFU等,根据具体需求选择最优策略。
3. **缓存预热**:在系统启动时,可以将热点数据预加载到缓存中,减少启动初期的数据库访问。
### 2.2 Python中的OrderedDict实现LRU缓存
#### 2.2.1 Python标准库中的OrderedDict
Python标准库中的`collections.OrderedDict`是一个可以记住元素添加顺序的字典类,这对于实现LRU缓存来说至关重要。`OrderedDict`保持了元素的插入顺序,使得我们可以轻松地跟踪元素的使用顺序,从而实现LRU算法。
#### 2.2.2 构建LRU缓存的数据结构
使用`OrderedDict`构建LRU缓存的基本步骤如下:
1. 初始化一个`OrderedDict`对象,用于存储缓存数据及其访问顺序。
2. 定义一个访问方法,每次访问缓存中的数据时,将其移动到`OrderedDict`的前端。
3. 定义一个淘汰方法,当缓存满时,移除`OrderedDict`末尾的数据。
以下是一个简单的Python代码示例,展示了如何使用`OrderedDict`实现一个基本的LRU缓存:
```python
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity):
self.cache = OrderedDict()
self.capacity = capacity
def get(self, key):
if key not in self.cache:
return -1
else:
self.cache.move_to_end(key)
return self.cache[key]
def put(self, key, value):
if key in self.cache:
self.cache.move_to_end(key)
self.cache[key] = value
if len(self.cache) > self.capacity:
self.cache.popitem(last=False)
# 使用示例
lru_cache = LRUCache(2)
lru_cache.put(1, 1)
lru_cache.put(2, 2)
print(lru_cache.get(1)) # 输出 1
lru_cache.put(3, 3)
print(lru_cache.get(2)) # 输出 -1,因为 2 已经被淘汰
```
### 2.3 LRU缓存的算法实现
#### 2.3.1 双向链表与哈希表的结合
在实现LRU缓存时,通常会使用双向链表来维护元素的访问顺序,同时使用哈希表来保证元素访问的O(1)时间复杂度。`OrderedDict`内部正是基于这样的数据结构,它提供了元素插入顺序的维护,同时允许O(1)时间复杂度的访问。
#### 2.3.2 缓存淘汰策略的细节处理
在缓存淘汰策略的实现中,需要考虑以下细节:
1. **缓存的容量管理**:当缓存达到其容量限制时,需要淘汰最少使用的元素。
2. **元素访问的跟踪**:每次访问元素时,需要更新其在双向链表中的位置。
3. **元素移除的处理**:在淘汰元素时,需要同时从双向链表和哈希表中移除。
### 2.3.3 缓存淘汰策略的代码实现
以下是一个简化的LRU缓存淘汰策略的代码实现,展示了如何结合双向链表和哈希表来实现高效的缓存管理:
```python
class LRUCache:
def __init__(self, capacity):
self.cache = {} # 哈希表
self.size = 0 # 当前缓存大小
self.capacity = capacity # 缓存容量
self.recently_used = {} # 最近使用的元素的顺序
def get(self, key):
if key in self.recently_used:
self.recently_used.move_to_end(key)
return self.cache[key]
else:
return -1
def put(self, key, value):
if key in self.cache:
self.recently_used.move_to_end(key)
else:
if self.size == self.capacity:
oldest_key = next(iter(self.recently_used))
del self.recently_used[oldest_key]
del self.cache[oldest_key]
self.size -= 1
self.cache[key] = value
self.recently_used[key] = None
self.size += 1
# 使用示例
lru_cache = LRUCache(2)
lru_cache.put(1, 1)
lru_cache.put(2, 2)
print(lru_cache.get(1)) # 输出 1
lru_cache.put(3, 3)
print(lru_cache.get(2)) # 输出 -1
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中的 OrderedDict,一种保留元素插入顺序的有序字典数据结构。从基础概念到高级应用,该专栏涵盖了 OrderedDict 的方方面面,包括其内部机制、性能优势、多线程应用、内存优化策略和自定义实现。通过深入的分析和实际示例,该专栏旨在帮助读者掌握 OrderedDict 的强大功能,并将其应用于各种场景中,包括数据处理、排序算法、状态机模式和数据分析。无论是 Python 新手还是经验丰富的开发人员,本专栏都提供了全面的指南,帮助读者提升字典处理技能并优化代码性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
红外技术的革命:关键组件电路图设计与连接要点深度解读

# 摘要
红外技术在现代电子设备中广泛应用,从基础传感器到复杂通信协议均扮演关键角色。本文对红外技术的基础和应用进行概述,深入探讨了红外传感器与发射器的电路设计、连接策略以及红外通信协议和信号处理技术。文中详细分析了传感器的工作原理、发射器设计要点、信号的编码解码技术以及信号干扰与噪声抑制方法。此外,本文提供了红外系统电路图设计实战案例,包括电路图的整体布局、元件选择与匹配,以及调试与优化电路图的
YRC1000与工业物联网:5大智能工厂数据通信解决方案

# 摘要
YRC1000控制器在工业物联网领域扮演着关键角色,本文首先介绍了工业物联网的基础理论框架与技术组成,接着深入探讨了智能工厂数据通信的关键技术,包括数据采集、边缘计算、通信技术和数据安全。文章进一步分析了YRC1000控制器与五大智能工厂解决方案的集成实践,并通过案例研究展示了其在
【提升开发效率】:深度解析Firefox ESR 78.6的高级功能,加速Linux项目开发
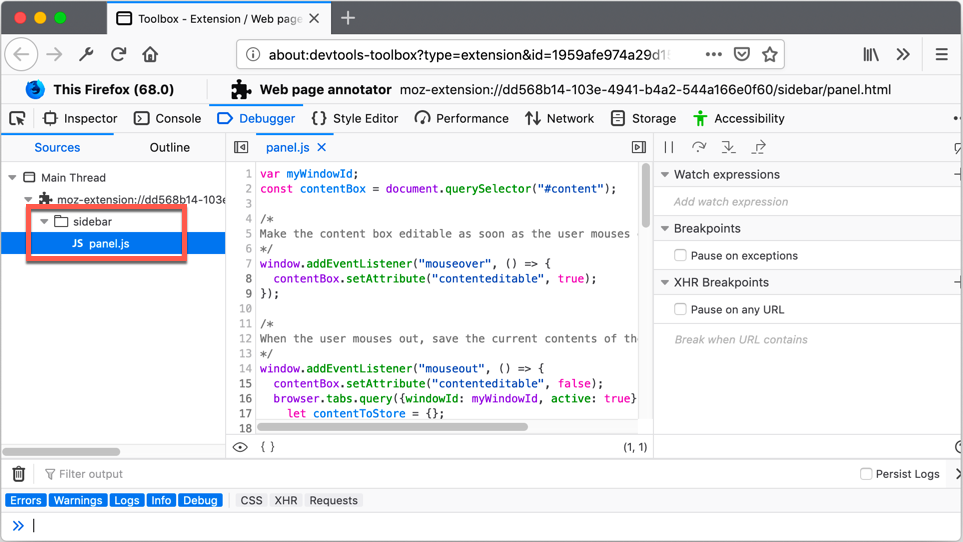
# 摘要
本文深入探讨了Firefox ESR(Extended Support Release)在企业级环境中的应用及其高级功能。首先概述了Firefox ESR的特点和优势,随后详述了其环境配置、性能优化工具、安全性增强功能和集成开发工具。文章还专章介绍了Firefox ESR在Lin
DENON天龙AVR-X2700H用户反馈精华:常见问题快速解决指南

# 摘要
本文针对DENON天龙AVR-X2700H型号的家庭影院接收器进行了全面的介绍和操作指南。文章首先提供了一个快速概览,接着详细介绍了设备的连接与设置步骤,包括硬件连接、初始化设置、无线网络配置以及音频优化。随后,本文深入探讨了接收器的智能功能,如HDMI和ARC功能的使用、多房间音频系统设置和音频源管理。此外,还专门讨论了用户可能遇到的问题诊断与故障排除方法,包括电源、音频视频同步以
mini_LVDS在高清显示系统中的应用:优势全面解析与挑战应对策略
# 摘要
本文介绍了mini_LVDS技术的基本概念、原理及特性,并探讨了其在高清显示系统中应用的优势。通过与传统LVDS技术的对比,本文分析了mini_LVDS在支持高分辨率、优化能耗和散热性能方面的需求和优势。文章还讨论了mini_LVDS在商业、工业和医疗等领域的应用案例,以及面临的技术挑战与限制。在此基础上,提出了一系列应对策略和实践经验,包括信号完整性优化、设计创新与集成技术,以及成本控制与市场适应性。最后,对mini_LVDS技术的发展前景和市场潜力进行了展望,包括融合新一代显示技术和市场应用场景的拓展。
# 关键字
mini_LVDS技术;高清显示系统;信号完整性;布线设计;成
无线通信系统性能升级:模拟IC设计的五大效能提升方法

# 摘要
本文综合介绍了无线通信系统中模拟集成电路(IC)设计的核心概念、理论基础、效能提升方法、先进技术工具,以及实际应用案例。文中详尽阐述了模拟信号处理原理、设计流程及性能指标分析与优化的重要性,并
【iStylePDF命令行操作详解】:简化批量任务与自定义工作流程
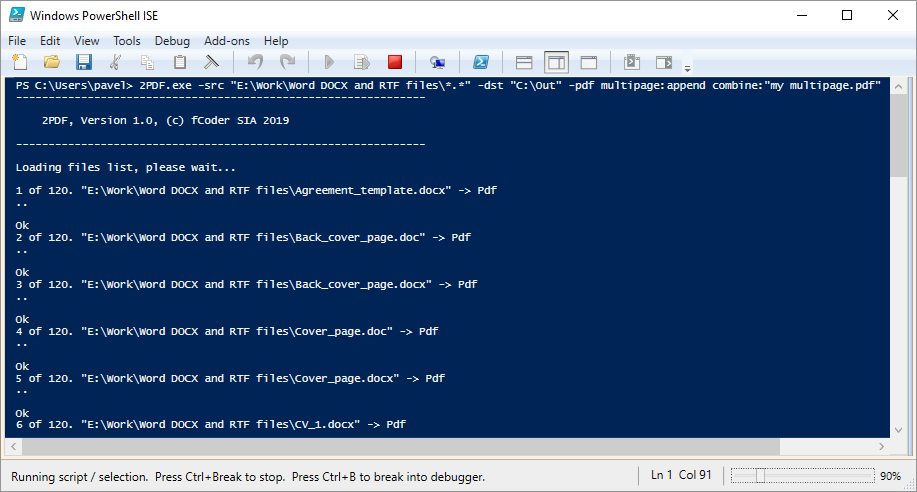
# 摘要
iStylePDF是一款功能丰富的命令行工具,旨在简化PDF文件的处理和管理。本文首先介绍了iStylePDF的基本概念及其在不同场景下的应用。随后,详细探讨了iStylePDF的基础操作,包括安装配置、基本命令语法以及文档转换、加密、合并和元数据编辑等核心功能。接着,文章深入介绍了高级自定义操作,如脚本自动化、条件逻辑控制以及数据管理和报告
【系统建模优化指南】:提升SIMULINK模型仿真准确性和效率的技巧

# 摘要
本文旨在深入探讨SIMULINK作为一款强大的系统建模与仿真工具,其在系统建模和仿真领域的应用。文章首先介绍SIMULINK环境的基本操作和模型构建方法,随后详细分析了提升模型准确性和仿真效率的策略,包括参数设定、模型验证、优化策略以及仿真性能的优化。此外,通过案例研究展示了如何应用高级技巧于复杂系统建模,并展望了仿真技术的未来发展趋势,包括新兴技术的应用和仿真工作流程的持续改进。
#
【KEPServerEX与OPC整合】:数据交换与通信机制的深入探讨
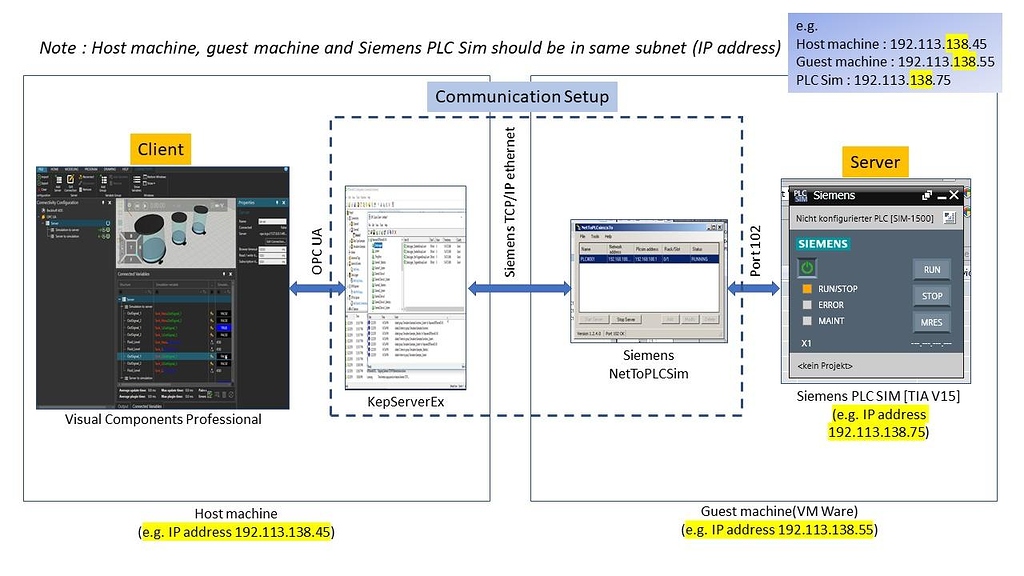
# 摘要
本文详细探讨了KEPServerEX平台与OPC技术整合的各个方面。首先回顾OPC标准及其通信原理,并分析其在工业自动化中的重要角色。接着,深入解析KEPServerEX的架构、功能、客户端支持以及高级特性。文章还包括了KEPServerEX与OPC整合的实践指南
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )