初识UNet(PyTorch)图像语义分割
发布时间: 2024-02-22 09:36:21 阅读量: 74 订阅数: 46 

图像分割u-net网络代码,基于pytorch
# 1. 介绍UNet网络结构
UNet网络结构在图像语义分割领域具有重要意义,本章将从UNet的历史背景、网络结构概述以及在图像语义分割中的应用方面进行介绍。
## 1.1 UNet的历史背景
UNet由Ronneberger等人于2015年提出,最初应用于生物医学图像分割领域。其创新性的网络结构设计为图像语义分割任务带来了新的思路。
## 1.2 UNet网络结构概述
UNet网络结构分为编码器和解码器两部分,其中编码器部分用于提取特征,解码器部分用于恢复空间信息。同时,UNet还引入了跳跃连接(skip connection)来保留不同层次特征。
## 1.3 UNet在图像语义分割中的应用
UNet在图像语义分割任务中表现出色,成为许多研究者和工程师的首选模型之一。其优异的性能和灵活的结构使其适用于不同场景下的图像分割任务。
# 2. PyTorch简介与安装
PyTorch是一个基于Python的科学计算库,专门针对深度学习应用而设计。它提供了丰富的工具和库,使得深度学习模型的实现变得更加简单和高效。在本章中,我们将介绍PyTorch的基本概念和安装方法,并探讨PyTorch在深度学习领域的重要性。
#### 2.1 PyTorch入门指南
PyTorch是由Facebook的人工智能研究团队开发的开源深度学习框架。它具有动态计算图的特性,这意味着可以使用常规的Python控制流结构(如循环、条件语句等)进行定义和修改神经网络模型。这使得PyTorch在实现复杂模型时更加灵活和直观。
#### 2.2 安装PyTorch及相关依赖
安装PyTorch通常需要先安装Python和pip包管理器。完成这些准备工作后,可以通过pip来安装PyTorch的最新版本。此外,为了充分利用PyTorch的功能,还需要安装一些相关的依赖库,如NumPy、Matplotlib等。
#### 2.3 PyTorch在深度学习领域的重要性
PyTorch已经成为了深度学习领域中最受欢迎的框架之一,得到了学术界和工业界的广泛应用。同时,PyTorch社区活跃,拥有众多开发者为其贡献代码和文档,为用户提供了丰富的资源和支持。其灵活性和易用性使得PyTorch成为了许多深度学习研究和项目的首选框架。
以上是第二章节的内容,满足了Markdown格式的要求,接下来我们将逐一补充完整的章节内容。
# 3. 数据准备与预处理
在进行图像语义分割任务之前,我们首先需要对数据进行准备和预处理,以确保模型的训练和评估能够顺利进行。
#### 3.1 数据集介绍
对于图像语义分割任务,通常会使用带有像素级标签的数据集,其中每个像素都标注了所属类别。常用的数据集包括PASCAL VOC、Cityscapes、COCO等,这些数据集包含了各种场景和类别的图像数据。
#### 3.2 图像数据预处理步骤
1. 读取图像数据:使用库如OpenCV或PIL读取图像数据。
2. 标签处理:处理标签数据,确保与输入图像对应且格式正确。
3. 图像尺寸调整:将输入图像和标签调整为相同的尺寸,通常会将它们裁剪或缩放至统一大小。
4. 归一化处理:对图像进行归一化处理,将像素值缩放至0-1范围。
5. 数据转换:将图像和标签转换为模型所需的张量格式。
#### 3.3 数据增强技术的应用
数据增强是一种有效的方法,可以扩充训练数据集,提高模型的泛化能力。常见的数据增强技术包括:
- 随机翻转:随机水平或垂直翻转图像。
- 随机裁剪:在图像中随机裁剪出感兴趣区域。
- 色彩抖动:对图像的色彩进行随机变化。
- 旋转缩放:随机旋转或缩放图像。
通过合理应用数据准备和数据增强技术,可以提高图像语义分割模型的性能和稳定性。
# 4. 搭建UNet模型
在本章中,我们将详细介绍如何使用PyTorch搭建UNet模型,包括构建网络结构、定义损失函数、设置优化器和超参数等步骤。
#### 4.1 构建UNet网络结构
首先,我们需要定义UNet的网络结构。UNet由对称的U形结构组成,包括下采样路径和上采样路径。下采样路径用于提取图像特征,上采样路径用于将特征图像恢复到原始尺寸。我们可以通过继承`torch.nn.Module`类来实现UNet网络结构。
```python
import torch
import torch.nn as nn
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
# 定义网络结构
# 编码器部分
self.encoder = nn.Sequential(
# 下采样步骤
...
)
# 解码器部分
self.decoder = nn.Sequential(
# 上采样步骤
...
)
def forward(self, x):
# 前向传播过程
# 编码器
enc_features = self.encoder(x)
# 解码器
out = self.decoder(enc_features)
return out
```
#### 4.2 定义损失函数
在训练UNet模型时,我们需要定义损失函数来衡量模型预测结果和真实标签之间的差异。在图像语义分割任务中,常用的损失函数是交叉熵损失函数。
```python
criterion = nn.CrossEntropyLoss()
```
#### 4.3 设置优化器和超参数
接下来,我们需要选择合适的优化器和设置超参数,以便训练UNet模型。常用的优化器包括Adam、SGD等。
```python
import torch.optim as optim
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 设置学习率等超参数
epochs = 10
batch_size = 16
```
通过以上步骤,我们成功搭建了UNet模型,并准备好进行训练和评估。
# 5. 模型训练与评估
在这一章节中,我们将详细介绍如何训练UNet模型并进行评估,在图像语义分割任务中,模型的训练和评估是非常重要的环节。
#### 5.1 划分训练集、验证集和测试集
在进行模型训练之前,首先需要将数据集划分为训练集、验证集和测试集。这样可以帮助我们评估模型的泛化能力,并避免过拟合。
```python
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_val, y_val, test_size=0.5, random_state=42)
```
#### 5.2 模型训练过程解析
在训练过程中,我们需要定义损失函数、设置优化器,并通过迭代更新模型参数来最小化损失函数。
```python
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
```
#### 5.3 模型评估指标及可视化结果
在模型训练完成后,我们需要评估模型的性能。常用的评估指标包括IoU(Intersection over Union)、Dice系数等,同时也可以通过可视化的方式展示模型在测试集上的预测结果。
```python
model.eval()
with torch.no_grad():
for data, target in test_loader:
output = model(data)
# 计算评估指标
iou = calculate_iou(output, target)
dice = calculate_dice(output, target)
# 可视化预测结果
visualize_results(data, output, target)
```
通过以上步骤,我们可以对训练好的UNet模型进行评估,并得出模型的性能指标和可视化结果。
# 6. 实际应用与展望
在本章节中,我们将探讨UNet在实际应用中的场景,并展望UNet在图像语义分割领域的未来发展方向。
#### 6.1 UNet在医学图像分割中的应用
UNet由于其在图像分割任务中的卓越表现,已经被广泛应用于医学图像领域。医学图像分割对于疾病诊断、治疗方案制定等方面具有重要意义。UNet网络结构能够有效地定位和识别医学图像中的感兴趣区域,其应用包括但不限于肿瘤分割、器官定位、病变区域检测等。通过结合深度学习模型和医学影像技术,UNet在医学图像分割领域取得了许多令人瞩目的成果。
#### 6.2 UNet的改进与扩展
尽管UNet在图像语义分割任务中表现出色,但在实际应用中仍然存在一些局限性,例如对小目标的检测能力有限,对边界模糊的对象分割效果不理想等。因此,许多研究人员针对UNet进行了改进和扩展。例如,引入注意力机制的注意力UNet(Attention UNet)、加入密集连接的DenseUNet等,均取得了一定的效果提升。未来,UNet在结构设计、损失函数优化、模型加速等方面仍有许多改进空间,可以进一步提高其在图像分割任务中的性能。
#### 6.3 图像语义分割领域的研究热点
除了UNet模型本身,图像语义分割领域还存在许多研究热点。例如,基于深度学习的实例分割、跨领域的图像语义分割、快速高效的实时分割算法等,均是当前研究的热点方向。随着计算机视觉和深度学习技术的不断发展,我们相信图像语义分割领域将会迎来更多的创新突破,为各行业带来更多实际应用场景。
通过对UNet的实际应用和未来发展进行探讨,我们可以更好地理解该模型在图像语义分割领域的重要性和潜力。希望本章内容能够为读者提供对UNet及图像语义分割领域发展趋势的全面认识。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以UNet(PyTorch)图像语义分割为主线,通过一系列文章带领读者深入理解UNet网络的原理与实践。从初识UNet(PyTorch)图像语义分割开始,逐步介绍PyTorch的基本知识和UNet的简介,引导读者构建UNet网络结构并实现图像语义分割。同时,专栏还详细讲解了利用PyTorch进行图像加载和数据增强的方法,深入探讨了UNet网络中的Encoder部分和Decoder的设计与实现。此外,还涉及了优化器及学习率调度器的选择与配置,以及UNet在卫星图像解译中的实际应用和引入注意力机制的实践。通过本专栏的学习,读者将对UNet图像语义分割有着更加深入和全面的理解,能够应用于实际项目中,并掌握相关技术的实践方法。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【EmuELEC全面入门与精通】:打造个人模拟器环境(7大步骤)

# 摘要
EmuELEC是一款专为游戏模拟器打造的嵌入式Linux娱乐系统,旨在提供一种简便、快速的途径来设置和运行经典游戏机模拟器。本文首先介绍了EmuELEC的基本概念、硬件准备、固件获取和初步设置。接着,深入探讨了如何定制EmuELEC系统界面,安装和配置模拟器核心,以及扩展其功能。文章还详细阐述了游戏和媒体内容的管理方法,包括游戏的导入、媒体内容的集成和网络功能的
【TCAD仿真流程全攻略】:掌握Silvaco,构建首个高效模型
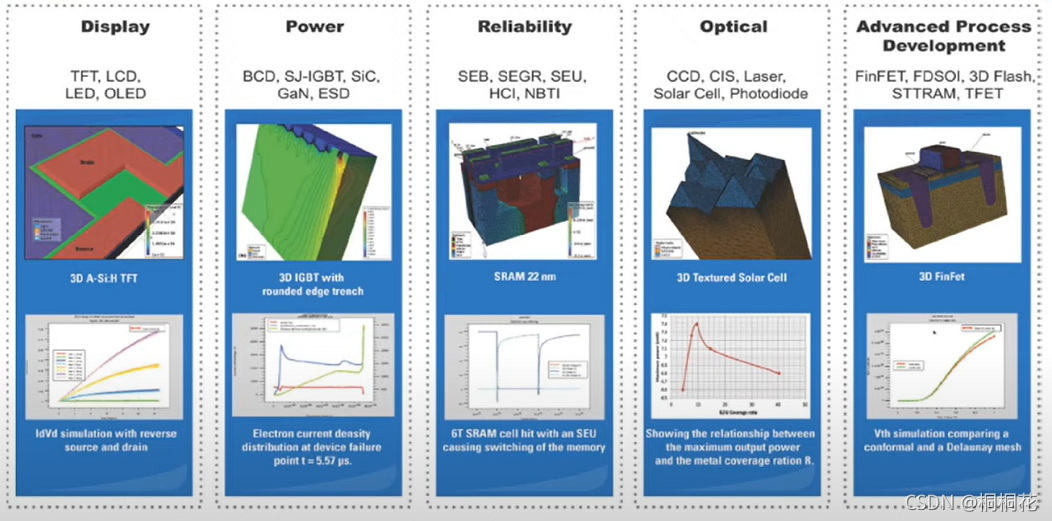
# 摘要
本文首先介绍了TCAD仿真和Silvaco软件的基础知识,然后详细讲述了如何搭建和配置Silvaco仿真环境,包括软件安装、环境变量设置、工作界面和仿真
【数据分析必备技巧】:0基础学会因子分析,掌握数据背后的秘密
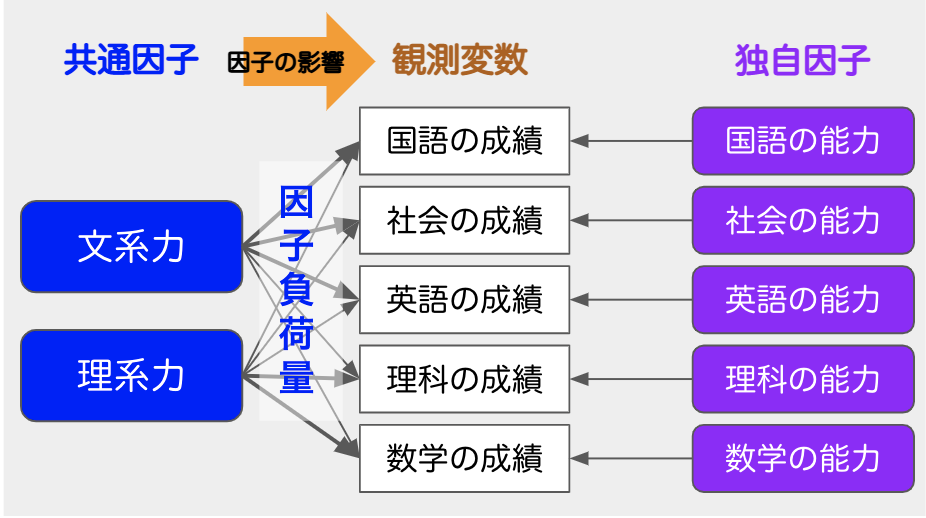
# 摘要
因子分析是一种强有力的统计方法,被广泛用于理解和简化数据结构。本文首先概述了因子分析的基本概念和统计学基础,包括描述性统计、因子分析理论模型及适用场景。随后,文章详细介绍了因子分析的实际操作步骤,如数据的准备、预处理和应用软件操作流程,以及结果的解读与报告撰写。通过市场调研、社会科学统计和金融数据分析的案例实战,本文展现了因子分析在不同领域的应用价值。最后,文章探讨了因子分析
【树莓派声音分析宝典】:从零开始用MEMS麦克风进行音频信号处理

# 摘要
本文详细介绍了基于树莓派的MEMS麦克风音频信号获取、分析及处理技术。首先概述了MEMS麦克风的基础知识和树莓派的音频接口配置,进而深入探讨了模拟信号数字化处理的原理和方法。随后,文章通过理论与实践相结合的方式,分析了声音信号的属性、常用处理算法以及实际应用案例。第四章着重于音频信号处理项目的构建和声音事件的检测响应,最后探讨了树莓派音频项目的拓展方向、
西门子G120C变频器维护速成

# 摘要
西门子G120C变频器作为工业自动化领域的一款重要设备,其基础理论、操作原理、硬件结构和软件功能对于维护人员和使用者来说至关重要。本文首先介绍了西门子G120C变频器的基本情况和理论知识,随后阐述了其硬件组成和软件功能,紧接着深入探讨了日常维护实践和常见故障的诊断处理方法。此外
【NASA电池数据集深度解析】:航天电池数据分析的终极指南
# 摘要
本论文提供了航天电池技术的全面分析,从基础理论到实际应用案例,以及未来发展趋势。首先,本文概述了航天电池技术的发展背景,并介绍了NASA电池数据集的理论基础,包括电池的关键性能指标和数据集结构。随后,文章着重分析了基于数据集的航天电池性能评估方法,包括统计学方法和机器学习技术的应用,以及深度学习在预测电池性能中的作用。此外,本文还探讨了数据可视化在分析航天电池数据集中的重要性和应用,包括工具的选择和高级可视化技巧。案例研究部分深入分析了NASA数据集中的故障模式识别及其在预防性维护中的应用。最后,本文预测了航天电池数据分析的未来趋势,强调了新兴技术的应用、数据科学与电池技术的交叉融合
HMC7044编程接口全解析:上位机软件开发与实例分析
# 摘要
本文全面介绍并分析了HMC7044编程接口的技术规格、初始化过程以及控制命令集。基于此,深入探讨了在工业控制系统、测试仪器以及智能传感器网络中的HMC7044接口的实际应用案例,包括系统架构、通信流程以及性能评估。此外,文章还讨论了HMC7044接口高级主题,如错误诊断、性能优化和安全机制,并对其在新技术中的应用前景进行了展望。
# 关键字
HMC7044;编程接口;数据传输速率;控制命令集;工业控制;性能优化
参考资源链接:[通过上位机配置HMC7044寄存器及生产文件使用](https://wenku.csdn.net/doc/49zqopuiyb?spm=1055.2635
【COMSOL Multiphysics软件基础入门】:XY曲线拟合中文操作指南
# 摘要
本文全面介绍了COMSOL Multiphysics软件在XY曲线拟合中的应用,旨在帮助用户通过高级拟合功能进行高效准确的数据分析。文章首先概述了COMSOL软件,随后探讨了XY曲线拟合的基本概念,包括数学基础和在COMSOL中的应用。接着,详细阐述了在COMSOL中进行XY曲线拟合的具体步骤,包括数据准备、拟合过程,
【GAMS编程高手之路】:手册未揭露的编程技巧大公开!
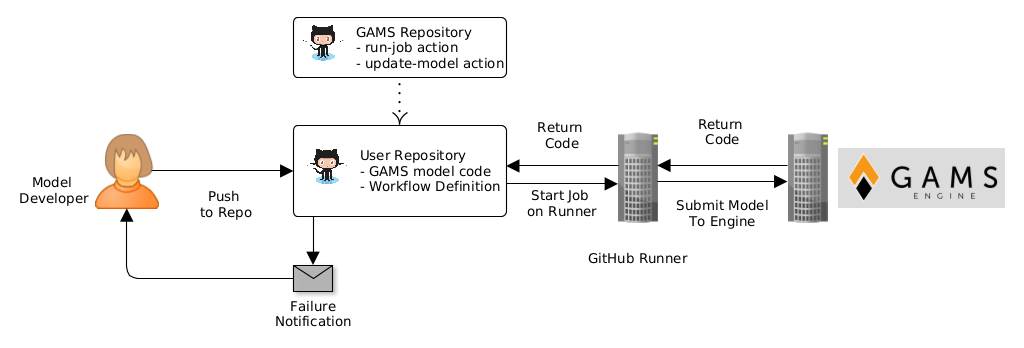
# 摘要
本文全面介绍了一种高级建模和编程语言GAMS(通用代数建模系统)的使用方法,包括基础语法、模型构建、进阶技巧以及实践应用案例。GAMS作为一种强大的工具,在经济学、工程优化和风险管理领域中应用广泛。文章详细阐述了如何利用GAMS进行模型创建、求解以及高级集合和参数处理,并探讨了如何通过高级
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )