【数据科学家必备】:掌握Gini指数,解锁决策树学习新境界
发布时间: 2024-09-04 20:16:23 阅读量: 24 订阅数: 17 

# 1. Gini指数的理论基础
在数据科学和机器学习的决策树算法中,Gini指数(又称基尼不纯度)是一个关键概念。Gini指数起源于经济学领域,用于衡量社会收入分配的不平等程度。在机器学习的分类问题中,Gini指数描述了一个数据集的随机选择项被错误分类的几率。它通过计算各个类别的概率乘以其概率的总和来得出一个介于0到1之间的值,数值越低表示数据集的纯度越高。简言之,Gini指数是反映数据集内每个类别分布均匀程度的指标。
## 2.1 Gini指数的计算
计算Gini指数的公式如下:
\[ Gini(p) = 1 - \sum_{i=1}^{J} p_i^2 \]
其中,\( p \)表示数据集中某节点上样本属于某一类的概率,\( J \)表示类别的总数。简单来说,如果一个集合中所有的实例都属于同一类,则基尼指数为0;如果数据集中的实例均匀地分布在所有可能的类别上,则基尼指数最大。
通过这种计算方式,我们能够量化数据集的随机变量的不确定性。在决策树的每个节点,算法会选择导致数据集基尼指数减小最多的属性进行分裂,从而逐步构建出一棵能够最佳分类训练数据的树。因此,理解Gini指数的计算与应用对于掌握决策树算法至关重要。
# 2. Gini指数在决策树算法中的应用
## 2.1 决策树算法概述
### 2.1.1 决策树的工作原理
决策树是一种典型的监督学习算法,它通过一系列规则对数据进行分组,以预测目标变量的值。它由节点(Node)和边(Edge)构成,一个节点代表一个属性(特征),边代表属性的可能取值,而叶节点代表最终的结果或预测值。
工作原理上,决策树从根节点开始,对数据集进行测试,根据测试结果将数据分配到不同的子节点。这个过程递归地执行,直到到达叶节点为止。叶节点是决策树算法的输出,可以是类的标号(分类问题),也可以是数值(回归问题)。
### 2.1.2 常见的决策树算法比较
有多种决策树算法,其中最著名的包括ID3、C4.5、CART等。
- **ID3(Iterative Dichotomiser 3)**: 利用信息增益(Information Gain)作为特征选择标准,仅适用于离散特征。
- **C4.5**: ID3的改进版,解决了ID3对连续值和缺失值处理的不足。C4.5使用信息增益比(Gain Ratio)来选择特征,以避免对具有许多取值的特征的偏好。
- **CART(Classification And Regression Trees)**: 既可以用于分类问题也可以用于回归问题。CART使用基尼不纯度(Gini Impurity)来构建二叉树。
## 2.2 Gini指数与决策树的构建
### 2.2.1 Gini指数在节点分裂中的作用
Gini指数(或称为基尼不纯度)是一个衡量数据集纯度的指标,它表示从数据集中随机选择两个样本,其类别标签不一致的概率。Gini指数越低,数据集纯度越高。
在决策树的每个节点分裂过程中,算法会选择导致子节点Gini指数和最小的那个特征进行分裂。目的是使得分裂后的子节点数据集的纯度尽可能高,从而使得整棵树的预测能力更强。
### 2.2.2 构建决策树的Gini指数优化过程
在构建决策树时,我们从根节点开始,对所有特征进行评估,选择一个最佳特征进行分裂。该过程会递归地在每个子节点上重复进行,直到满足停止条件,比如树的最大深度、节点内样本数的最小值、Gini指数小于某个阈值等。
该过程可以用以下伪代码表示:
```python
def build_tree(data, max_depth, min_samples_split, gini_threshold):
if (depth >= max_depth or
len(data) < min_samples_split or
gini(data) < gini_threshold):
return create_leaf(data)
best_feature, best_gini = None, 1
for feature in data.features:
gini = calculate_gini_impurity(data, feature)
if gini < best_gini:
best_gini = gini
best_feature = feature
node = Node(best_feature)
for value in feature_values(best_feature):
subset = data.subset(best_feature, value)
child_node = build_tree(subset, max_depth, min_samples_split, gini_threshold)
node.add_child(child_node)
return node
```
在上述伪代码中,`calculate_gini_impurity` 是计算Gini指数的函数,`best_feature` 是会导致最小Gini指数的特征。这个过程会递归地调用`build_tree`函数,直到满足提前终止条件。
## 2.3 Gini指数在特征选择中的应用
### 2.3.1 特征重要性的衡量
在决策树中,每个特征对分类的重要性可以通过其被用来分裂节点的频率来衡量。Gini指数在计算这个频率时起到关键作用,因为它直接关联到节点分裂的标准。
具体来说,如果一个特征在一个树中被多次用于分裂,而每次分裂都显著降低了Gini指数,那么可以认为该特征具有较高的重要性。这种方法不仅直观,而且容易实现,并且在许多决策树实现中都有所体现,比如在Scikit-learn中的决策树算法。
### 2.3.2 特征选择策略与模型优化
在构建决策树模型时,特征选择是一个重要步骤。使用Gini指数可以有效地减少特征数量,从而简化模型并提高运算速度,尤其是在面对高维度数据时。
一种常见的特征选择策略是通过递归地从当前最优特征集中移除Gini指数最小的特征,然后重新评估剩余特征集合的Gini指数,以此来决定是否保留该特征。通过这种方式,我们可以选择那些对模型性能影响最大的特征,从而优化决策树模型。
```python
def feature_selection(data, target_feature, remaining_features, selected_features, max_features):
if len(selected_features) >= max_features or not remaining_features:
return selected_features
min_gini = float('inf')
best_feature = None
for feature in remaining_features:
gini = calculate_gini_impurity(data, feature, target_feature
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以Gini指数为核心,深入探讨了其在决策树中的应用。文章首先全面解析了Gini指数的定义、计算方式和意义,揭示了其作为决策树节点划分准则的原理。
随后,专栏重点分析了Gini指数对决策树模型泛化误差的影响。通过案例和理论推导,探讨了Gini指数过高或过低对模型泛化能力的负面影响。最后,文章提出了优化Gini指数的策略,包括数据预处理、特征选择和正则化,以提高决策树模型的泛化性能。
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【持久化存储】:将内存中的Python字典保存到磁盘的技巧

# 1. 内存与磁盘存储的基本概念
在深入探讨如何使用Python进行数据持久化之前,我们必须先了解内存和磁盘存储的基本概念。计算机系统中的内存指的
索引与数据结构选择:如何根据需求选择最佳的Python数据结构

# 1. Python数据结构概述
Python是一种广泛使用的高级编程语言,以其简洁的语法和强大的数据处理能力著称。在进行数据处理、算法设计和软件开发之前,了解Python的核心数据结构是非常必要的。本章将对Python中的数据结构进行一个概览式的介绍,包括基本数据类型、集合类型以及一些高级数据结构。读者通过本章的学习,能够掌握Python数据结构的基本概念,并为进一步深入学习奠
Python并发控制:在多线程环境中避免竞态条件的策略

# 1. Python并发控制的理论基础
在现代软件开发中,处理并发任务已成为设计高效应用程序的关键因素。Python语言因其简洁易读的语法和强大的库支持,在并发编程领域也表现出色。本章节将为读者介绍并发控制的理论基础,为深入理解和应用Python中的并发工具打下坚实的基础。
## 1.1 并发与并行的概念区分
首先,理解并发和并行之间的区别至关重要。并发(Concurre
Python索引的局限性:当索引不再提高效率时的应对策略

# 1. Python索引的基础知识
在编程世界中,索引是一个至关重要的概念,特别是在处理数组、列表或任何可索引数据结构时。Python中的索引也不例外,它允许我们访问序列中的单个元素、切片、子序列以及其他数据项。理解索引的基础知识,对于编写高效的Python代码至关重要。
## 理解索引的概念
Python中的索引从0开始计数。这意味着列表中的第一个元素
Python列表与数据库:列表在数据库操作中的10大应用场景

# 1. Python列表与数据库的交互基础
在当今的数据驱动的应用程序开发中,Python语言凭借其简洁性和强大的库支持,成为处理数据的首选工具之一。数据库作为数据存储的核心,其与Python列表的交互是构建高效数据处理流程的关键。本章我们将从基础开始,深入探讨Python列表与数据库如何协同工作,以及它们交互的基本原理。
## 1.1
Python测试驱动开发(TDD)实战指南:编写健壮代码的艺术

# 1. 测试驱动开发(TDD)简介
测试驱动开发(TDD)是一种软件开发实践,它指导开发人员首先编写失败的测试用例,然后编写代码使其通过,最后进行重构以提高代码质量。TDD的核心是反复进行非常短的开发周期,称为“红绿重构”循环。在这一过程中,"红"代表测试失败,"绿"代表测试通过,而"重构"则是在测试通过后,提升代码质量和设计的阶段。TDD能有效确保软件质量,促进设计的清晰度,以及提高开发效率。尽管它增加了开发初期的工作量,但长远来
Python列表的函数式编程之旅:map和filter让代码更优雅

# 1. 函数式编程简介与Python列表基础
## 1.1 函数式编程概述
函数式编程(Functional Programming,FP)是一种编程范式,其主要思想是使用纯函数来构建软件。纯函数是指在相同的输入下总是返回相同输出的函数,并且没有引起任何可观察的副作用。与命令式编程(如C/C++和Java)不同,函数式编程
【Python排序进阶】:探索并发环境下的多线程排序与大数据处理策略
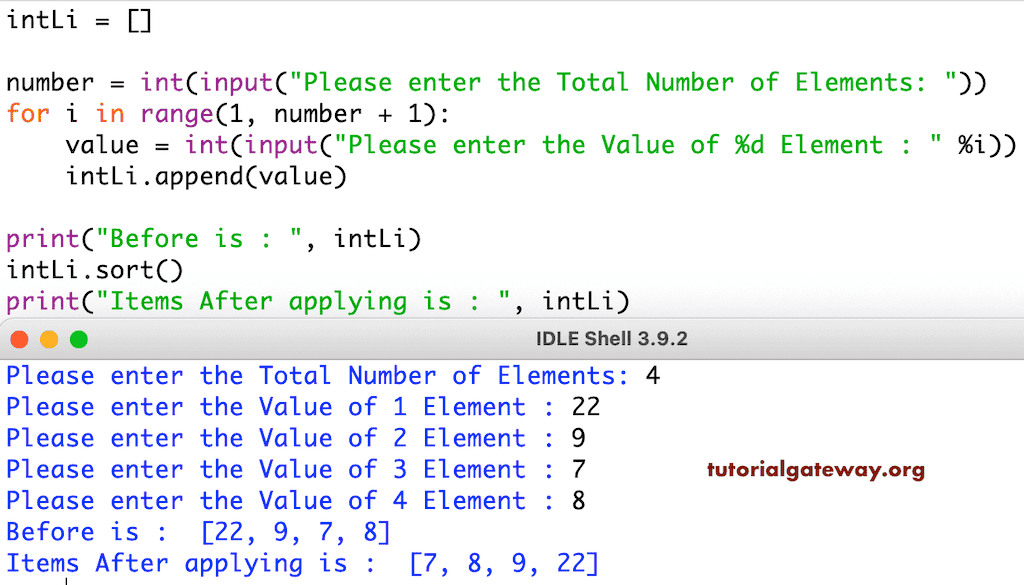
# 1. Python排序基础和并发概念
## Python排序基础
Python提供了多种内置的排序方法,如列表的`sort()`方法和`sorted()`函数,它们都可以实现对序列的快速排序。为了深入理解排序,我们需要了解一些基础的排序算法,比如冒泡排序、选择排序、插入排序等,这些算法虽然在实际应用中效率不是最高的,但它们是学习更高级排序算法的基础
Python list remove与列表推导式的内存管理:避免内存泄漏的有效策略
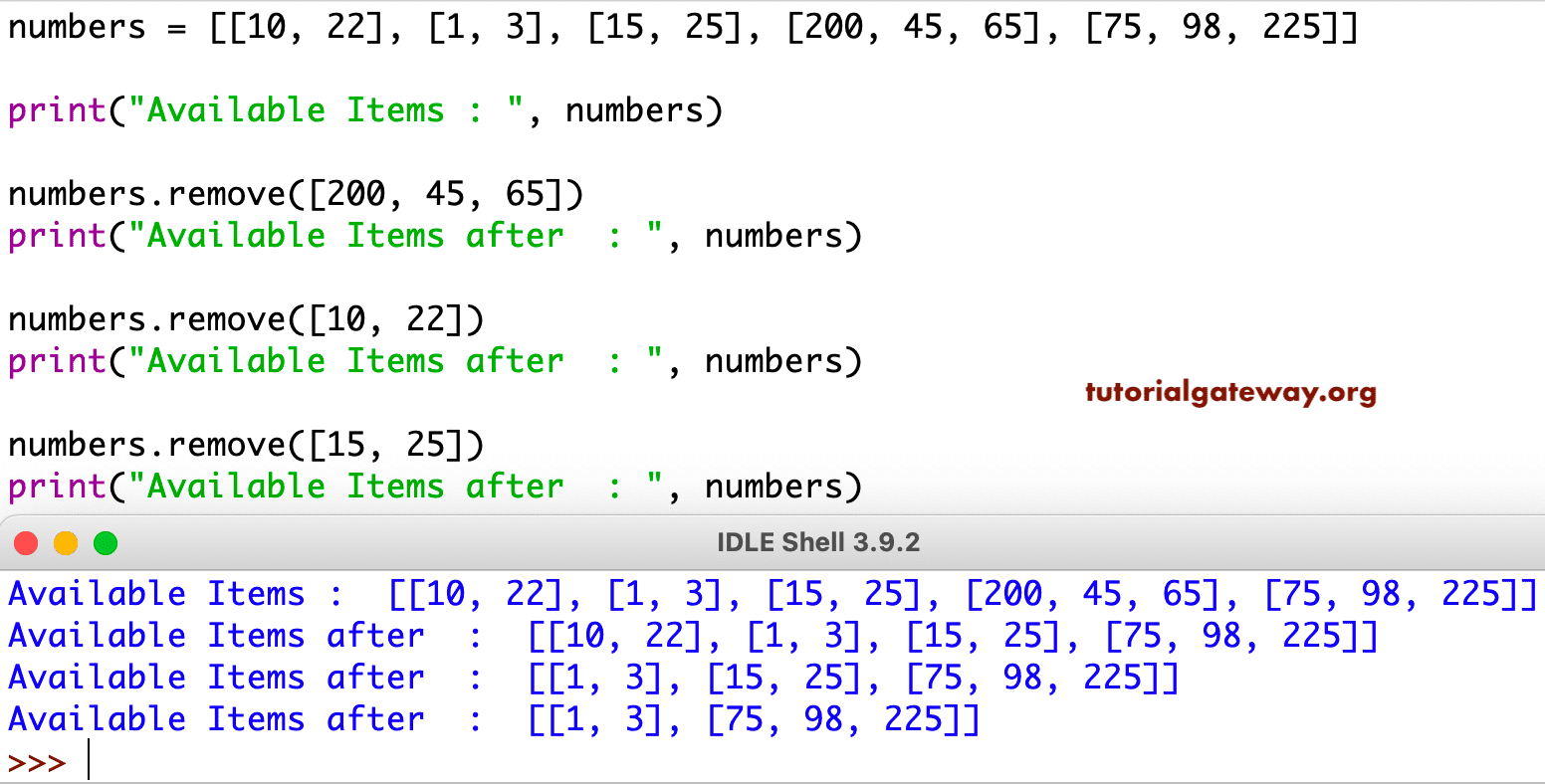
# 1. Python列表基础与内存管理概述
Python作为一门高级编程语言,在内存管理方面提供了众多便捷特性,尤其在处理列表数据结构时,它允许我们以极其简洁的方式进行内存分配与操作。列表是Python中一种基础的数据类型,它是一个可变的、有序的元素集。Python使用动态内存分配来管理列表,这意味着列表的大小可以在运行时根据需要进
【Python项目管理工具大全】:使用Pipenv和Poetry优化依赖管理

# 1. Python依赖管理的挑战与需求
Python作为一门广泛使用的编程语言,其包管理的便捷性一直是吸引开发者的亮点之一。然而,在依赖管理方面,开发者们面临着各种挑战:从包版本冲突到环境配置复杂性,再到生产环境的精确复现问题。随着项目的增长,这些挑战更是凸显。为了解决这些问题,需求便应运而生——需要一种能够解决版本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )