【Linux内核并发编程】:社区资源与解决方案助你突破难点
发布时间: 2024-12-09 22:31:22 阅读量: 12 订阅数: 18 

Linux系统编程与内核优化详解

# 1. Linux内核并发编程基础
## 1.1 并发编程概述
在现代操作系统中,多任务处理是常态。Linux内核作为一个多任务操作系统,提供了强大的并发编程支持。开发者可以利用内核提供的并发机制来编写响应快速、性能优越的内核模块。理解并发编程的基础对于编写高效、稳定的内核代码至关重要。
## 1.2 Linux内核并发编程特点
Linux内核支持多线程和多进程的并发执行。内核中的并发编程与用户空间的多线程编程有所不同,主要表现在同步机制、并发模型和资源管理等方面。在内核中,开发者需要更加谨慎地处理并发访问共享资源,避免竞态条件、死锁等问题。
## 1.3 同步机制的重要性
在并发环境中,确保数据的一致性和完整性是至关重要的。Linux内核提供了多种同步机制,如互斥锁、自旋锁和原子操作等,这些机制可以帮助开发者保护临界区,协调不同线程或进程间的工作。在本章中,我们将重点介绍这些基本同步机制的原理和使用方法。
# 2. Linux内核并发机制详解
### 2.1 Linux内核同步原语
#### 2.1.1 互斥锁(Mutex)的原理和使用
在Linux内核中,互斥锁是一种常用的同步机制,用于控制对共享资源的互斥访问。互斥锁的主要思想是在临界区内只允许一个线程访问资源,从而避免并发带来的数据不一致问题。互斥锁分为不可递归锁和可递归锁两种类型,不可递归锁不能在持有锁的情况下再次请求该锁,而可递归锁则可以。
在使用互斥锁时,通常需要包括头文件 `<linux/mutex.h>`,然后使用mutex_init初始化互斥锁,再通过mutex_lock获取锁,或者使用mutex_trylock尝试获取锁。在完成对共享资源的操作后,使用mutex_unlock释放锁。
以下是一个简单的互斥锁使用示例代码:
```c
#include <linux/mutex.h>
static DEFINE_MUTEX(my_mutex);
void my_function(void) {
mutex_lock(&my_mutex);
// 执行需要互斥访问的代码
mutex_unlock(&my_mutex);
}
```
在这个示例中,`DEFINE_MUTEX`宏用于静态初始化一个互斥锁。`mutex_lock`和`mutex_unlock`函数分别用于获取和释放锁。如果互斥锁已被其他线程持有,则`mutex_lock`会阻塞调用线程直到锁被释放。
互斥锁在内核中是通过底层的futex机制实现的,它允许锁操作在不发生锁争用时以极低的开销进行。当多个线程同时尝试获取锁时,futex机制会将线程放入等待队列,这样可以有效地管理线程的睡眠和唤醒。
#### 2.1.2 自旋锁(Spinlock)的实现与优化
自旋锁与互斥锁类似,也是用来解决多线程并发访问共享资源的一种同步机制。然而,自旋锁在尝试获取锁时,如果锁已经被其他线程持有,它不是阻塞线程,而是让CPU持续地轮询检查锁状态,直到锁被释放。这种机制适用于短时间的锁持有,如果等待时间过长,则自旋会浪费CPU资源。
在Linux内核中,自旋锁的使用同样需要包含 `<linux/spinlock.h>` 头文件,然后使用spinlock_t来定义一个自旋锁变量。初始化自旋锁可以使用SPIN_LOCK_UNLOCKED或spin_lock_init。获取和释放锁通常使用spin_lock和spin_unlock函数。
一个典型的自旋锁使用示例代码如下:
```c
#include <linux/spinlock.h>
static spinlock_t my_lock = SPIN_LOCK_UNLOCKED;
void my_function(void) {
spin_lock(&my_lock);
// 执行需要互斥访问的代码
spin_unlock(&my_lock);
}
```
为了提高效率,自旋锁支持多种优化机制,例如自适应自旋锁(adaptive spinning)。自适应自旋锁会在锁释放前估计锁的平均保持时间,并根据这个估计决定是否继续自旋。如果预计锁很快会被释放,则继续自旋,否则放弃自旋转而进入睡眠。
自旋锁在多处理器系统上通常比互斥锁更高效,因为它不需要上下文切换开销。但在单处理器系统上,自旋锁则会退化成一个简单的禁用抢占机制。
### 2.2 Linux内核中的原子操作
#### 2.2.1 原子变量的操作与应用场景
原子操作是指在多线程环境中,执行不可中断的一系列操作,这些操作要么全部完成,要么全部不执行。Linux内核提供了原子操作的API,这使得开发者能够实现线程安全的代码,尤其是在进行共享资源的计数或更新操作时。
原子操作主要通过 `<asm/atomic.h>` 和 `<linux/atomic.h>` 头文件提供的接口实现。内核提供了一组宏来执行原子读取、修改和写入,这些操作保证了在任何情况下,数据的读写都是原子性的。
以下是一个原子操作的示例,使用atomic_inc来增加一个原子变量的值:
```c
#include <asm/atomic.h>
atomic_t my_atomic_var = ATOMIC_INIT(0);
void my_function(void) {
atomic_inc(&my_atomic_var);
// 其他代码
}
```
在这个例子中,`atomic_inc`函数将原子变量`my_atomic_var`的值加1。由于这是原子操作,它保证了即使在并发环境中,也不会出现数据竞争的问题。
原子操作适用于多种场景,如引用计数、性能统计、状态标志等。它们通常用于实现简单的锁机制,如自旋锁的实现就依赖于原子操作。
#### 2.2.2 原子操作的实现机制
原子操作的实现机制在不同的硬件架构上有所差异。在x86架构上,原子操作通常通过特殊的汇编指令来实现,如`lock`前缀的`xadd`(交换并累加)、`cmpxchg`(比较并交换)指令等。
在内核中,原子变量通常由一个结构体表示,其中包含了一个整数和一系列用于保证原子性的操作。例如,`atomic_t`类型就是这样一种结构体。内核提供了一系列原子操作的函数和宏,包括但不限于:`atomic_read`、`atomic_set`、`atomic_add`、`atomic_sub`、`atomic_inc`、`atomic_dec`等。
以`atomic_add`为例,其操作基本上都是通过汇编指令实现的,例如在x86上,可能是这样的:
```c
static inline void atomic_add(int i, atomic_t *v)
{
__asm__ __volatile__ (
"lock; xaddl %0, %1"
: "+r" (i), "+m" (v->counter)
:
: "memory", "cc");
}
```
这段代码中的`lock; xaddl`指令组合是一种原子性操作,它确保了即使在多处理器系统上,`i`的值也会安全地加到`v->counter`上。
### 2.3 Linux内核中的锁机制比较
#### 2.3.1 不同锁机制的性能考量
Linux内核提供了多种锁机制,包括互斥锁、自旋锁、顺序锁(seqlock)和读写锁(rwlock)等。每种锁都有其特定的使用场景和性能考量。
- **互斥锁**:适用于保护时间较长的代码块,可以在获取锁失败时让出CPU,从而允许其他任务执行。
- **自旋锁**:适用于保护时间短且获取锁失败时等待时间很短的情况,可以减少上下文切换的开销。
- **顺序锁**:适用于读多写少的场景,通过序列计数保证读取操作的原子性,读操作可以并行,而写操作则会独占。
- **读写锁**:适用于读多写少的场景,允许多个读操作并行,但写操作时所有读和写操作都会被阻塞。
在性能考量上,需要考虑锁争用的频率和持有时间。高争用频率和短持有时间的场景适合使用自旋锁,而低争用频率和长持有时间的场景适合使用互斥锁。读写锁和顺序锁则分别针对读多写少的场景提供了优化。
#### 2.3.2 锁的选择和使用策略
选择合适的锁机制是保证内核并发代码性能的关键。开发者在选择锁时需要考虑以下几个方面:
- **锁争用的预期**:如果锁争用非常频繁,应考虑使用性能更好的锁,比如顺序锁或读写锁。
- **持有时间**:持有时间短适合使用自旋锁,而持有时间长则应考虑互斥锁。
- **上下文切换开销**:频繁的上下文切换会降低系统性能。在上下文切换开销大的环境中,自旋锁可能不是最佳选择。
- **代码的可读性和可维护性**:某些锁机制虽然提供了性能优势,但会降低代码的清晰度。在可维护性和性能之间需要进行权衡。
例如,在实现文件系统时,由于读操作非常频繁,可以使用读写锁来提升读操作的性能。但在网络子系统中,由于操作通常比较快速,自旋锁可能是更好的选择。
### 2.4 Linux内核中的读写锁(rwlock)
#### 2.4.1 读写锁的工作原理
读写锁(rwlock)是另一种常用的同步机制,它允许多个读者同时对共享资源进行读取,但在写入时,需要独占访问权。这种锁机制特别适用于读多写少的场景,能够显著提高并发读取的性能。
在Linux内核中,读写锁通过 `<linux/rwlock.h>` 头文件定义,提供了`rwlock_t`结构体来实现读写锁。读写锁的操作包括初始化、读锁定、读解锁、写锁定和写解锁等。
以下是一个读写锁使用示例:
```c
#include <linux/rwlock.h>
static DECLARE_RWLOCK(my_rwlock);
void read_function(void) {
read_lock(&my_rwlock);
// 执行需要读取的代码
read_unlock(&my_rwlock);
}
void write_function(void) {
write_lock(&my_rwlock);
// 执行需要写的代码
write_un
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在为 Linux 开发者提供全面的社区资源指南,涵盖从内核优化到模块开发、调试和测试的各个方面。通过深入探索社区工具、最佳实践和成功案例,开发者可以显著提升他们的开发效率、解决复杂调试难题并优化系统性能。本专栏还提供对 Linux 内核最新特性和社区动态的深入见解,帮助开发者跟上技术前沿。无论您是经验丰富的内核黑客还是刚起步的 Linux 爱好者,本专栏都将为您提供宝贵的资源和见解,帮助您充分利用 Linux 开发者社区的力量。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
AES算法深度解码:MixColumn变换的内部机制大公开

参考资源链接:[AES加密算法:MixColumn列混合详解](https://wenku.csdn.net/doc/2rcwh8h7ph
【SolidWorks建模速成】:零基础到复杂零件构建,只需5步!

参考资源链接:[SolidWorks初学者教程:从基础到草图绘制](https://wenku.csdn.net/doc/1zpbmv5282?spm=1055.2635.3001.10343)
# 1. SolidWorks建模入门基础
SolidWorks 是一款广受欢迎的3D CAD设计软件,适用于各种工程领域,包括机械设计、汽车、航空和其他工业设计。对于刚刚接触SolidWo
【HFSS栅球建模问题全攻略】:快速识别与解决建模难题

参考资源链接:[2015年ANSYS HFSS BGA封装建模教程:3D仿真与分析](https://wenku.csdn.net/doc/840stuyum7?spm=1055.2635.3001.10343)
# 1. HFSS栅球建模基础
在现代电磁工程领域,高频结构仿真软件(HFSS)已成为不可或缺的工具之一。本章将介绍HFSS栅球建模的基础知识,旨在为初学
Sonic Visualiser插件开发入门:打造个性化音频分析工具
参考资源链接:[Sonic Visualiser新手指南:详尽功能解析与实用技巧](https://wenku.csdn.net/doc/r1addgbr7h?spm=1055.2635.3001.10343)
# 1. Sonic Visualiser插件开发入门
## 简介
Sonic Visualiser 是一个功能强大的音频分析软件,它不仅提供了一个用户友好的界面用于查看和处理音频文件,还允许开发者通过插件机制扩展其功能。本章旨在为初学者介绍Sonic Visualiser插件开发的基本概念和入门步骤。
## 开发环境准备
在开始之前,你需要准备开发环境。推荐使用Python语言进
最优化案例研究
参考资源链接:[《最优化导论》习题答案](https://wenku.csdn.net/doc/6412b73fbe7fbd1778d499de?spm=1055.2635.3001.10343)
# 1. 最优化理论基础
最优化是数学和计算机科学中的一个重要分支,旨在找到问题中的最优解,即在
【机器学习优化高频CTA策略入门】:掌握数据预处理、回测与风险管理
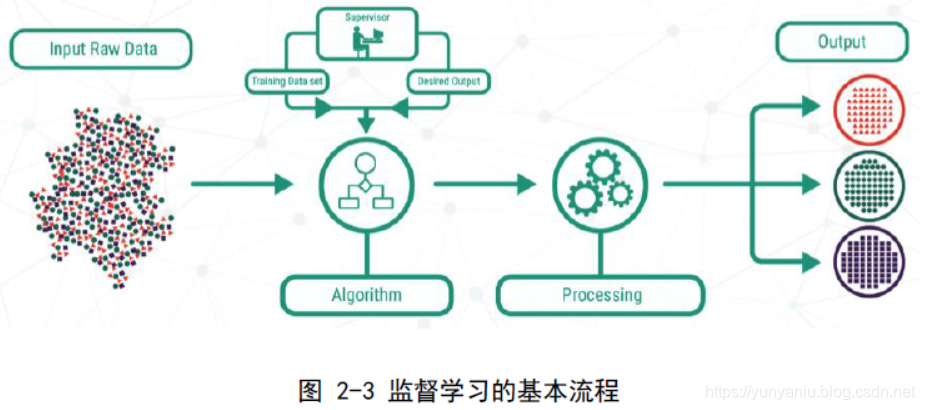
参考资源链接:[基于机器学习的高频CTA策略研究:模型构建与策略回测](https://wenku.csdn.net/doc/4ej0nwiyra?spm=1055.2635.3001.10343)
# 1. 机器学习与高频CTA策略概述
## 机器学习与高频交易的交叉
在金融领域,尤其是高频交易(CTA)策略中,机器学习技术已成为一种创新力量,它使交易者能够从历史数据中发现复杂的模
【监控与优化】实时监控Wonderware Historian性能,提升效率

参考资源链接:[Wonderware Historian与DAServer配置详解:数据采集与存储教程](https://wenk
【TIA博途V16新用户必读】:5个快速上手项目的小技巧
参考资源链接:[TIA博途V16仿真问题全解:启动故障与解决策略](https://wenku.csdn.net/doc/4x9dw4jntf?spm=1055.2635.3001.10343)
# 1. TIA博途V16界面概览
## 1.1 用户界面的初识
初识TIA博途V16,用
RK3588原理图设计深度解析:基础到高级优化技巧

参考资源链接:[RK3588硬件设计全套资料,原理图与PCB文件下载](https://wenku.csdn.net/doc/89nop3h5no?spm=1055.2635.3001.10343)
# 1. RK3588芯片架构概述
RK3588是Rockchip推出的一款高性能多核处理器,主要面向AI计算、高清视频处理和高端多媒体应用。本章将介绍RK3588的硬件架构,包括其内部构成、核心性能参数以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )