奇异值分解(SVD)在向量中的应用
发布时间: 2024-04-07 22:47:15 阅读量: 72 订阅数: 37 

奇异值分解(SVD)
# 1. 简介
## SVD的基本概念
奇异值分解(Singular Value Decomposition,SVD)是线性代数中一种重要的矩阵分解方法,可以将一个矩阵分解为三个矩阵的乘积,其中涉及到原始矩阵的特征和结构信息。对于任意的实数矩阵$A_{m \times n}$,SVD可以表示为:
$$A = U \Sigma V^T$$
其中,$U$是$m \times m$的酉矩阵,$V$是$n \times n$的酉矩阵,$\Sigma$是$m \times n$的非负对角矩阵。SVD在数据降维、特征提取、矩阵逆等方面有着广泛的应用,是一种重要的数学工具。
## SVD在向量分解中的作用
在向量分解中,SVD可以帮助我们理解向量之间的关系,发现隐藏在数据背后的模式和结构。通过对向量进行奇异值分解,我们可以实现数据的降维和特征提取,从而更好地进行数据分析和挖掘。在文本处理、推荐系统、图像处理和机器学习等领域,SVD都扮演着重要的角色,为数据科学提供了有力的支持。
# 2. SVD在文本处理中的应用
奇异值分解(SVD)在文本处理中扮演着重要的角色,特别是在自然语言处理和信息检索领域。通过SVD,可以将文本数据转化为矩阵形式,进而进行降维和特征提取。
### 文本向量化与SVD
在文本处理中,常常需要将文本数据转换成数值形式以便机器学习算法能够处理。一种常见的方法是使用词袋模型,将每个文本表示为一个词频向量。这时可以利用SVD进行文本矩阵的分解。
```python
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from scipy.linalg import svd
# 例子: 创建文本数据
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?'
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus).todense()
# 奇异值分解
U, S, Vt = svd(X, full_matrices=False)
```
### 通过SVD实现文本降维和特征提取
利用SVD,我们可以实现文本数据的降维和特征提取,从而提高文本处理算法的效果。通过保留前n个奇异值对应的特征向量,可以将文本数据降至n维空间,减少特征的复杂度。
```python
n = 2 # 设定降维到2维
X_reduced = np.dot(U[:, :n], np.dot(np.diag(S[:n]), Vt[:n, :]))
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“向量”专栏深入探讨了向量的概念、运算、应用和相关技术。专栏从基础概念开始,涵盖了向量加法、减法、点积、叉积等运算,以及向量的范数、角度和方向表示。此外,专栏还介绍了在 Python 和 NumPy 库中实现向量操作的方法,并探讨了向量的投影、线性相关性、线性组合和线性变换。专栏还介绍了奇异值分解和主成分分析在向量中的应用,以及向量正交性和完备性的分析。最后,专栏探讨了向量库在数据向量化处理中的作用,以及向量量化在图像处理中的应用。通过深入浅出的讲解和丰富的实例,专栏帮助读者全面理解向量及其在各种领域的应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
NVIDIA ORIN NX性能基准测试:超越前代的关键技术突破
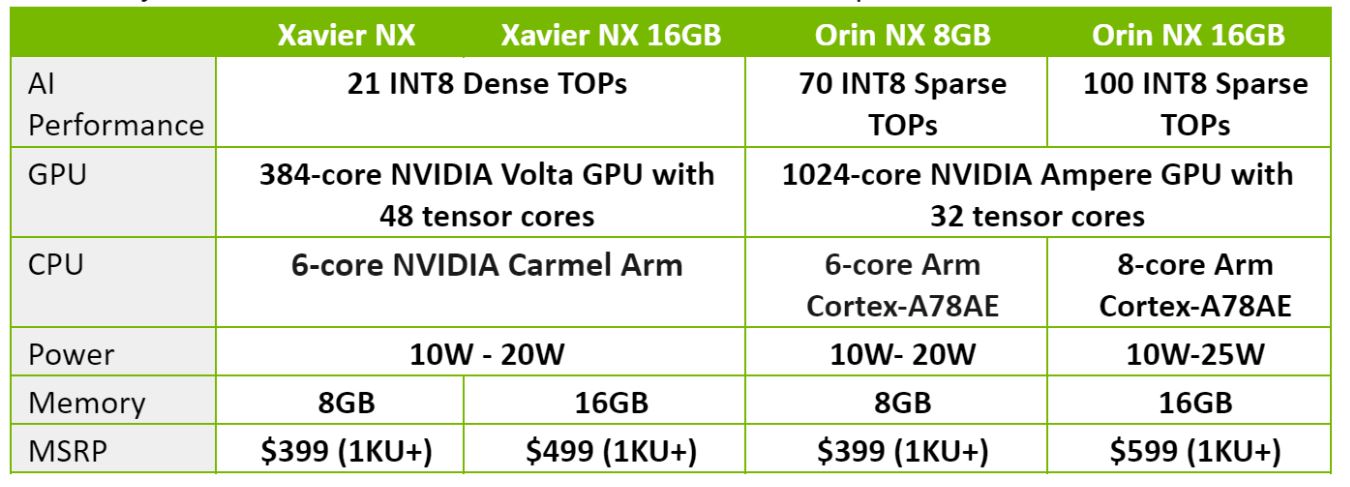
# 摘要
本文全面介绍了NVIDIA ORIN NX处理器的性能基准测试理论基础,包括性能测试的重要性、测试类型与指标,并对其硬件架构进行了深入分析,探讨了处理器核心、计算单元、内存及存储的性能特点。此外,文章还对深度学习加速器及软件栈优化如何影响AI计算性能进行了重点阐述。在实践方面,本文设计了多个实验,测试了NVI
图论期末考试必备:掌握核心概念与问题解答的6个步骤

# 摘要
图论作为数学的一个分支,广泛应用于计算机科学、网络分析、电路设计等领域。本文系统地介绍图论的基础概念、图的表示方法以及基本算法,为图论的进一步学习与研究打下坚实基础。在图论的定理与证明部分,重点阐述了最短路径、树与森林、网络流问题的经典定理和算法原理,包括Dijkstra和Floyd-Warshall算法的详细证明过程。通过分析图论在社交网络、电路网络和交通网络中的实际应用,本文探讨了图论问题解决策略和技巧,包括策略规划、数学建模与软件
【无线电波传播影响因素详解】:信号质量分析与优化指南
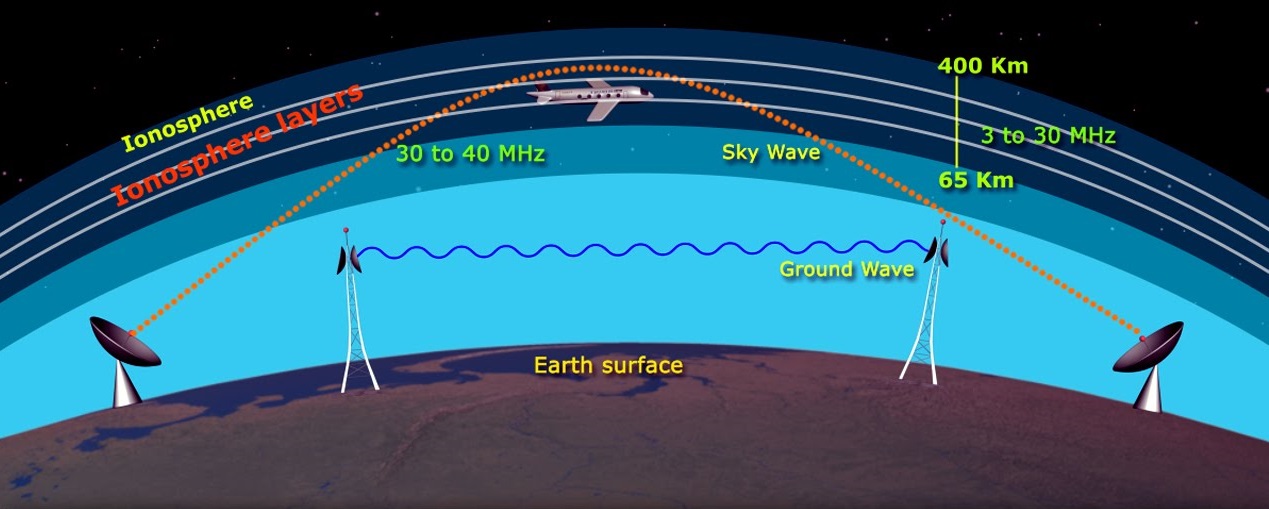
# 摘要
本文综合探讨了无线电波传播的基础理论、环境影响因素以及信号质量的评估和优化策略。首先,阐述了大气层、地形、建筑物、植被和天气条件对无线电波传播的影响。随后,分析了信号衰减、干扰识别和信号质量测量技术。进一步,提出了包括天线技术选择、传输系统调整和网络规划在内的优化策略。最后,通过城市、农村与偏远地区以及特殊环境下无线电波传播的实践案例分析,为实际应用提供了理论指导和解决方案。
# 关键字
无线电波传播;信号衰减;信号干扰;信号
FANUC SRVO-062报警:揭秘故障诊断的5大实战技巧

# 摘要
FANUC SRVO-062报警是工业自动化领域中伺服系统故障的常见表现,本文对该报警进行了全面的综述,分析了其成因和故障排除技巧。通过深入了解FANUC伺服系统架构和SRVO-062报警的理论基础,本文提供了详细的故障诊断流程,并通过伺服驱动器和电机的检测方法,以及参数设定和调整的具体操作
【单片微机接口技术速成】:快速掌握数据总线、地址总线与控制总线
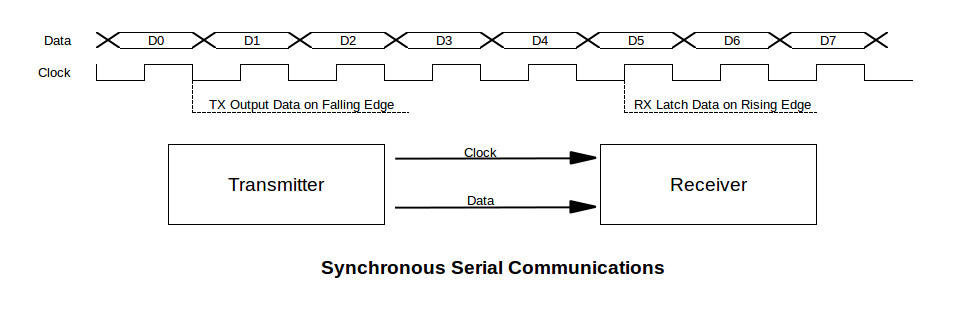
# 摘要
本文深入探讨了单片微机接口技术,重点分析了数据总线、地址总线和控制总线的基本概念、工作原理及其在单片机系统中的应用和优化策略。数据总线的同步与异步机制,以及其宽度对传输效率和系统性能的影响是本文研究的核心之一。地址总线的作用、原理及其高级应用,如地址映射和总线扩展,对提升寻址能力和系统扩展性具有重要意义。同时,控制总线的时序控制和故障处理也是确保系统稳定运行的关键技术。最后
【Java基础精进指南】:掌握这7个核心概念,让你成为Java开发高手

# 摘要
本文全面介绍了Java语言的开发环境搭建、核心概念、高级特性、并发编程、网络编程及数据库交互以及企业级应用框架。从基础的数据类型和面向对象编程,到集合框架和异常处理,再到并发编程和内存管理,本文详细阐述了Java语言的多方面知识。特别地,对于Java的高级特性如泛型和I/O流的使用,以及网络编程和数据库连接技
电能表ESAM芯片安全升级:掌握最新安全标准的必读指南
# 摘要
ESAM芯片作为电能表中重要的安全组件,对于确保电能计量的准确性和数据的安全性发挥着关键作用。本文首先概述了ESAM芯片及其在电能表中的应用,随后探讨了电能表安全标准的演变历史及其对ESAM芯片的影响。在此基础上,深入分析了ESAM芯片的工作原理和安全功能,包括硬件架构、软件特性以及加密技术的应用。接着,本文提供了一份关于ESAM芯片安全升级的实践指南,涵盖了从前期准备到升级实施以及后
快速傅里叶变换(FFT)实用指南:精通理论与MATLAB实现的10大技巧
# 摘要
快速傅里叶变换(FFT)是信号处理和数据分析的核心技术,它能够将时域信号高效地转换为频域信号,以进行频谱分析和滤波器设计等。本文首先回顾FFT的基础理论,并详细介绍了MATLAB环境下FFT的使用,包括参数解析及IFFT的应用。其次,深入探讨了多维FFT、离散余弦变换(DCT)以及窗函数在FFT中的高级应用和优化技巧。此外,本文通过不同领域的应用案例
【高速ADC设计必知】:噪声分析与解决方案的全面解读

# 摘要
高速模拟-数字转换器(ADC)是现代电子系统中的关键组件,其性能受到噪声的显著影响。本文系统地探讨了高速ADC中的噪声基础、噪声对性能的影响、噪声评估与测量技术以及降低噪声的实际解决方案。通过对噪声的分类、特性、传播机制以及噪声分析方法的研究,我们能
【Python3 Serial数据完整性保障】:实施高效校验和验证机制
# 摘要
本论文首先介绍了Serial数据通信的基础知识,随后详细探讨了Python3在Serial通信中的应用,包括Serial库的安装、配置和数据流的处理。本文进一步深入分析了数据完整性的理论基础、校验和验证机制以及常见问题。第四章重点介绍了使用Python3实现Serial数据校验的方法,涵盖了基本的校验和算法和高级校验技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )