【C语言链表排序与递归】:算法探究与应用剖析(附实例对比)
发布时间: 2024-12-09 20:17:41 阅读量: 15 订阅数: 18 

数据结构与算法分析--C语言描述_数据结构与算法_
# 1. 链表排序与递归算法概述
链表排序与递归算法是数据结构与算法领域中的经典主题,它们不仅是理解数据如何高效管理的基础,而且在软件开发中扮演着重要角色。本章旨在为读者提供一个全面的概览,涵盖排序和递归的基本概念,以及它们在处理链表数据结构时的重要性和应用。
## 1.1 排序与递归的重要性
排序算法使我们能够对数据进行有效地组织,无论是在内存中还是存储设备上。它们是数据库、搜索引擎、数据挖掘等许多应用程序的核心组件。递归算法则是将大问题分解为更小的子问题,并以重复的方式解决这些子问题的方法。递归在处理具有自然递归结构的数据(如树和图)时特别有用。
## 1.2 链表数据结构简介
链表是一种广泛使用的线性数据结构,由一系列节点组成,每个节点包含数据域和指向下一个节点的引用。链表的这种动态性质允许我们在运行时有效地插入和删除节点,但是由于它们不提供直接的索引访问,所以对链表进行排序需要特别的算法设计。
## 1.3 递归与链表操作的结合
递归天然地适合解决链表问题,因为链表的线性递归性质。在许多链表操作中,例如查找、删除或者反转链表,递归提供了一种直观且简洁的解决方案。然而,递归也带来了性能上的考量,比如栈空间的使用和可能的栈溢出问题。
通过本章,我们将为读者建立起链表排序和递归算法的知识框架,为其后续章节的深入探究奠定坚实基础。
# 2. ```
# 第二章:链表数据结构深入解析
在数据结构的世界里,链表是一个基础但至关重要的概念。它不仅仅是一个简单的线性数据结构,其灵活的特性使其在各种场景下都扮演着重要的角色。本章节将对链表进行深入的探讨,包括其基本概念、组成、以及如何进行操作技术。
## 2.1 链表的基本概念和组成
### 2.1.1 链表的定义与特点
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列节点组成,每个节点包含数据部分和一个或两个指针,用于指向下一个或前一个节点。链表的特点是增加和删除元素非常方便,不需要移动其他元素,只需要调整相应指针即可。
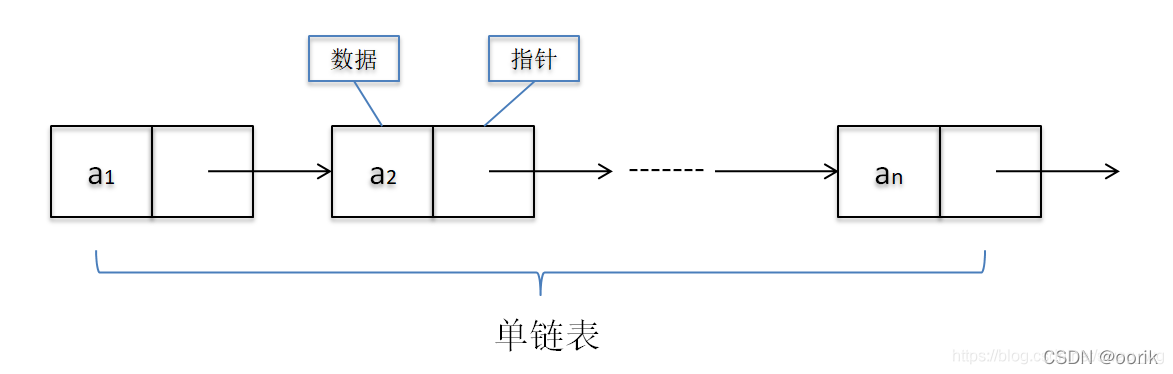
### 2.1.2 单链表、双链表与循环链表
根据链表节点的指针类型,链表可以分为单链表、双链表和循环链表。
- **单链表**:每个节点包含一个数据域和一个指向下一个节点的指针。它是最简单的链表类型,但不支持反向遍历。
- **双链表**:每个节点包含一个数据域、一个指向前一个节点的指针和一个指向下一个节点的指针。双链表支持正反两个方向的遍历,因此在某些操作上具有更高的灵活性。
- **循环链表**:循环链表是一种特殊的单链表,其尾节点的指针指向了头节点,形成了一个环。循环链表的遍历可以无限进行,直到程序被外部因素终止。
## 2.2 链表的操作技术
### 2.2.1 链表节点的创建与插入
创建链表节点通常需要先定义一个结构体(在C语言中)或类(在面向对象的编程语言中),包含数据域和指针域。插入操作则是链表操作的核心之一,它涉及到修改节点之间的指针关系。
以下是一个简单的单链表节点结构体定义和节点插入的示例代码(以C语言为例):
```c
// 定义链表节点结构体
typedef struct Node {
int data; // 数据域
struct Node* next; // 指针域
} Node;
// 向链表头部插入节点
Node* insertHead(Node** head, int value) {
Node* newNode = (Node*)malloc(sizeof(Node)); // 分配内存
newNode->data = value; // 设置节点数据
newNode->next = *head; // 新节点指向原头节点
*head = newNode; // 更新头指针为新节点
return *head; // 返回新的头节点
}
```
### 2.2.2 链表的查找与删除
链表的查找操作是从头节点开始遍历链表,根据给定值与节点数据进行比较,直到找到匹配项或遍历完成。删除操作更为复杂,需要考虑三种情况:删除头节点、删除中间节点和删除尾节点。
这里是一个查找和删除节点的示例代码:
```c
// 查找链表中的节点
Node* search(Node* head, int value) {
Node* current = head;
while (current != NULL) {
if (current->data == value) {
return current;
}
current = current->next;
}
return NULL; // 未找到返回NULL
}
// 删除链表中的节点
void deleteNode(Node** head, int value) {
Node* temp = search(*head, value);
if (temp == NULL) return; // 未找到节点
if (*head == temp) {
// 删除的是头节点
*head = temp->next;
} else {
// 删除的是中间或尾节点
Node* prev = *head;
while (prev->next != temp) {
prev = prev->next;
}
prev->next = temp->next;
}
free(temp); // 释放节点内存
}
```
### 2.2.3 链表的遍历方法
链表的遍历通常使用指针进行,从头节点开始,逐个访问直到尾节点。以下是一个遍历链表的函数示例:
```c
// 遍历链表并打印节点数据
void traverse(Node* head) {
Node* current = head;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
}
```
## 2.3 递归的原理与应用
### 2.3.1 递归函数的工作原理
递归是一种常见的编程技术,一个函数调用自身以解决问题的方法称为递归。递归函数的工作原理包括两个基本要素:基本情况(解决的最小子问题)和递归步骤(将问题缩小并调用自身)。
一个递归函数的例子是计算阶乘:
```c
// 计算阶乘的递归函数
int factorial(int n) {
if (n <= 1) {
return 1; // 基本情况:0! = 1 和 1! = 1
} else {
return n * factorial(n - 1); // 递归步骤
}
}
```
### 2.3.2 递归与迭代的比较
递归和迭代是解决重复问题的两种主要方法。递归方法更接近于数学上的定义,代码通常更简洁易懂,但可能会因为重复调用而消耗较多的内存和性能
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 C 语言中链表的数据结构,涵盖了从基础概念到高级应用的方方面面。我们从单链表的创建、插入和删除操作开始,逐步深入到双链表和环形链表的实现和应用技巧。此外,我们还比较了链表和数组的性能,帮助您选择最适合您需求的数据结构。
专栏还探讨了链表在并发编程中的挑战,并提供了高效解决多线程数据共享问题的解决方案。我们还介绍了将链表与文件操作相结合的数据持久化技术。最后,我们探讨了链表设计模式,指导您构建灵活且可扩展的 C 语言链表库。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
图像处理中的【海康威视SDK错误码】案例研究:异常处理技巧大公开

参考资源链接:[海康威视SDK开发常见错误码解析与排查](https://wenku.csdn.net/doc/4s9yhznz71?spm=1055.2635.3001.10343)
# 1. 海康威视SDK错误码概述
在开发工作中,SDK(Software Development Kit)是我们与硬件交互时不可或缺的工具之一。海康威视作为监控领域的领军企业,其SDK提供了丰富的
【仿真案例分析】:掌握RobotStudio 6.0复杂任务仿真,一文搞定!
参考资源链接:[RobotStudio 6.0 操作手册:初学者入门指南](https://wenku.csdn.net/doc/6412b6b9be7fbd1778d47bf7?spm=1055.2635.3001.10343)
# 1. RobotStudio 6.0概述
RobotStudio 6.0作为一款先进的机器人仿真软件,它将复杂的设计和仿真流程变得直观易懂。它允许工程师在虚拟环境中创建、测试、优化机器人工作单元,无需物理设备即可预测实际生产中可能遇到的问题。在本章中,我们将简要了解RobotStudio 6.0的界面布局、核心功能以及如何快速开始一个新项目。
RobotSt
PELCO-D协议在不同监控平台的兼容性问题分析(跨平台兼容性挑战:PELCO-D协议的解决之道)

参考资源链接:[PELCO-D协议中文.docx](https://wenku.csdn.net/doc/6412b6c4be7fbd1778d47e68?spm=1055.2635.3001.10343)
# 1. PELCO-D协议概述
## 1.1 协议简介
PELCO-D协议是一种广泛应用于闭路电视(CCTV)监控系统中的通讯协议,用于远程控制云台摄像机的动作。它是由美国PELCO公司开发,因其简单、稳定和易于实现的
SynCovery v7.40数据备份与恢复教程:确保数据安全无忧的黄金法则

参考资源链接:[SynCovery v7.40 网络备份教程:自动设置与高级操作](https://wenku.csdn.net/doc/3oyris6fhc?spm=1055.2635.3001.10343)
# 1. SynCovery v7.40概览
## 1.1 产品简介
SynCovery 是业界领先的备份解决方案之一,提供全面的数据保护和灾难恢复服务。其第七版(v7.40)引入了多项改进,
【WinCE桌面故障快速诊断指南】:5分钟解决常见问题

参考资源链接:[导航仪Wince桌面解锁教程:进入真实系统与个性化定制](https://wenku.csdn.net/doc/6412b799be7fbd1778d4addd?spm=1055.2635.3001.10343)
# 1. WinCE桌面故障诊断概述
在现代嵌入式系统中,Windows Embedded Compact
iTek相机兼容性解决之道:轻松集成到各种系统
参考资源链接:[Vulcan-CL采集卡与国产线扫相机设置指南](https://wenku.csdn.net/doc/4d2ufe0152?spm=1055.2635.3001.10343)
# 1. iTek相机兼容性问题概述
在当今的IT生态系统中,硬件设备的兼容性已成为不可忽视的议题。iTek相机作为市场上的一个重要角色,其兼容性问题对于确保不同系统和应用能够顺畅对接至关重要。本章将概述iTek相机兼容性问题,为读者提供一个全局的视角,了解兼容性问题的普遍性和它在日常工作中的重要性。
## 1.1 兼容性问题的普遍性
随着技术的快速发展,计算机系统和软件变得越来越多样化。iTek
EES数据备份与恢复:保证数据安全的专家指南

参考资源链接:[EES官方教程:精通EES V9.x版本方程处理](https://wenku.csdn.net/doc/6412b4dcbe7fbd1778d41169?spm=1055.2635.3001.10343)
# 1. EES数据备份与恢复概述
## 数据备份与恢复的重要性
在信息技术高速发展的今天,数据已成为企
【FPGA新手必备】:从零开始的Cyclone IV学习之旅
参考资源链接:[Cyclone IV FPGA系列中文手册:全面介绍与规格](https://wenku.csdn.net/doc/64730c43d12cbe7ec307ce50?spm=1055.2635.3001.10343)
# 1. FPGA和Cyclone IV的基础介绍
## FPGA简介
现场可编程门阵列(FPGA)是一种可以通过软件重新配置硬
【IRB-6700维护与故障排除】:日常维护要点及常见问题解决,让你的机器人工作更稳定

参考资源链接:[ABB IRB6700机器人手册:安全与操作指南](https://wenku.csdn.net/doc/6401ab99cce7214c316e8d13?spm=1055.2635.3001.10343)
# 1. IRB-6700机器人概述
工业自动化领域不断进步,IRB-6700机器人作为ABB旗下的一款杰出产品,已经成为现代工厂和仓库自动化中的核心组件。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )