数据库设计与优化技巧
发布时间: 2024-03-03 07:22:20 阅读量: 53 订阅数: 19 
# 1. 数据库设计基础
## 1.1 数据库设计概述
数据库设计是数据库应用系统开发的第一步,它直接影响到系统的性能、扩展性和稳定性。数据库设计的目标是通过合理地组织数据,使得数据存取更加高效、方便和安全。在数据库设计中,需考虑数据的组织结构、关系建立以及数据完整性等方面。良好的数据库设计是一个系统高效运行的基础。
## 1.2 实体关系模型(ER模型)
实体关系模型是数据库设计中常用的概念模型,用于描述系统中的实体及其之间的关系。在ER模型中,实体用实体框表示,关系用连接实体的线表示,具体可以划分为实体、属性和关系三部分。通过ER模型的构建,可以更直观地了解系统中的数据模型,为数据库的逻辑设计提供参考。
## 1.3 数据范式
数据范式是数据库设计中用来规范关系型数据库中字段的一种标准化方法。数据范式分为不同级别,主要包括第一范式(1NF)、第二范式(2NF)、第三范式(3NF)等。通过将数据规范化到不同的范式中,可以减少数据冗余、提高数据的一致性和完整性,使得数据库更易于维护和扩展。
# 2. 数据库优化原理
数据库优化是提升数据库性能和效率的重要手段,下面将介绍数据库优化的基本原理以及常用技巧。
### 2.1 数据库优化概述
数据库优化是指通过改进数据库结构设计、优化SQL查询语句、合理使用索引等手段,提高数据库系统的性能、可靠性和稳定性,从而更好地满足业务需求。
### 2.2 查询优化
在进行数据库查询时,需要注意以下几点以提高查询效率:
#### 索引的使用
合理添加索引可以加快查询速度,但过多的索引会影响性能,需要权衡利弊。
#### 避免全表扫描
尽量避免在大表上进行全表扫描,可以通过添加索引或优化查询条件来避免全表扫描。
#### 优化查询语句
避免在查询语句中使用“SELECT *”和“SELECT DISTINCT”,只选择需要的字段并使用合适的条件和排序。
### 2.3 索引优化
索引在数据库中起着重要作用,它可以加速数据的查找速度。但是索引的不当使用也会导致性能下降,因此需要注意以下几点:
#### 组合索引
合理使用组合索引来覆盖常用的查询条件,避免创建过多单列索引。
#### 索引的选择
根据查询频率和字段的选择性来选择合适的索引类型,如单列索引、组合索引、唯一索引等。
#### 定期维护索引
定期对索引进行优化和重建,保持索引的有效性和高效性。
通过以上数据库优化原理和技巧,可以帮助优化数据库性能,提升系统的整体运行效率。
# 3. 数据表设计与优化
在数据库设计中,数据表的设计是至关重要的一环。一个合理优化的数据表设计可以有效提高数据库的性能和可维护性。本章将介绍数据表设计与优化的相关内容。
#### 3.1 数据表设计原则
在设计数据表时,需要遵循一些基本原则:
- 将数据拆分为逻辑上的单元,避免数据冗余和混乱。
- 设计符合实际业务场景的数据表结构,避免过度设计。
- 合理选择字段的数据类型和长度,避免浪费存储空间。
- 设计适当的索引以提高查询性能。
- 考虑数据表之间的关系,合理设置主键和外键。
#### 3.2 数据类型选择与优化
正确选择数据类型可以减少数据存储空间的占用,提高数据操作效率。常见的数据类型包括整型、浮点型、字符型、日期型等。在选择数据类型时,需要考虑存储范围、精度和性能消耗等因素。
例如,在MySQL数据库中,可以选择合适的整型存储用户ID:
```sql
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50)
);
```
#### 3.3 主键和外键设计
主键是用来唯一标识数据表中的记录,通常使用自增长的整型。外键用于建立表与表之间的关联,确保数据的完整性和一致性。
在设计数据表时,需要考虑以下几点:
- 为每个数据表选择合适的主键,确保唯一性和稳定性。
- 使用外键建立表与表之间的关系,避免数据错乱和冗余。
- 在需要进行联表查询时,通过外键建立关联,提高查询效率。
以上是关于数据表设计与优化的内容,合理设计数据表结构和优化数据类型选择,对于提升数据库性能和减少数据存储空间都具有重要意义。
# 4. 查询性能优化
### 4.1 SQL语句优化技巧
SQL语句的性能优化是数据库优化的重要一环,下面列举几条SQL语句优化技巧:
1. 使用索引:通过为经常查询的字段添加索引,可以加快查询速度。
2. 避免使用SELECT *:只选择需要的字段,避免查询不必要的数据。
3. 使用JOIN语句代替子查询:JOIN通常比子查询效率更高。
4. 使用EXPLAIN分析SQL语句:可以查看SQL语句的执行计划,帮助找出慢查询。
5. 优化WHERE子句:尽量避免在WHERE子句中对字段进行函数操作,可以影响索引的使用。
示例代码(Python):
```python
import mysql.connector
# 连接数据库
mydb = mysql.connector.connect(
host="localhost",
user="yourusername",
password="yourpassword",
database="mydatabase"
)
# 创建游标
mycursor = mydb.cursor()
# 查询优化示例:避免使用SELECT *
mycursor.execute("SELECT name, age FROM customers")
result = mycursor.fetchall()
for row in result:
print(row)
# 关闭游标和连接
mycursor.close()
mydb.close()
```
代码总结:以上示例展示了避免使用SELECT *以提高查询效率的技巧。
结果说明:通过选择特定字段而非使用SELECT *,可以减少数据传输量,提高查询效率。
### 4.2 查询计划分析与优化
查询计划是数据库系统为了执行SQL语句而生成的一种元组,包含了SQL语句的执行顺序、访问路径等信息。通过分析查询计划可以优化查询性能。
示例代码(Java):
```java
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class QueryPlanOptimization {
public static void main(String[] args) {
Connection con = null;
PreparedStatement pst = null;
ResultSet rs = null;
try {
con = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydatabase", "yourusername", "yourpassword");
pst = con.prepareStatement("SELECT * FROM customers WHERE age > ?");
pst.setInt(1, 18);
rs = pst.executeQuery();
while (rs.next()) {
System.out.println(rs.getString("name") + ", " + rs.getInt("age"));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
if (rs != null) rs.close();
if (pst != null) pst.close();
if (con != null) con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
```
代码总结:以上Java示例展示了如何使用PreparedStatement来执行SQL语句,并通过传入参数进行优化。
结果说明:通过使用PreparedStatement可以预编译SQL语句,减少SQL注入的风险,提高查询性能。
### 4.3 索引设计与优化
索引在数据库中起到加快查询速度的作用,但不合理使用索引也可能导致性能下降。索引设计与优化需要根据具体场景和需求来综合考虑。
示例代码(Go):
```go
package main
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
)
func main() {
db, err := sql.Open("mysql", "yourusername:yourpassword@tcp(localhost:3306)/mydatabase")
if err != nil {
panic(err.Error())
}
defer db.Close()
// 创建索引
_, err = db.Exec("CREATE INDEX idx_name ON customers(name)")
if err != nil {
panic(err.Error())
}
fmt.Println("Index created successfully")
}
```
代码总结:以上Go示例展示了如何在MySQL数据库中创建索引来优化查询性能。
结果说明:通过合理创建索引可以加快查询速度,提高数据库性能。
通过以上示例代码和技术总结,可以帮助开发人员更好地优化SQL查询性能,提高数据库的效率和响应速度。
# 5. 存储优化技巧
在数据库设计与优化中,存储优化技巧是非常重要的一部分。通过合理的存储引擎选择与优化、数据库空间管理以及数据备份与恢复策略,可以提升数据库的性能和可靠性。
以下是本章节的详细内容:
#### 5.1 存储引擎选择与优化
- 存储引擎概述
- 不同存储引擎的特点及适用场景
- 存储引擎的选择原则
- 存储引擎优化技巧
#### 5.2 数据库空间管理
- 空间管理概述
- 数据文件和日志文件的管理
- 表空间的管理与优化
- 空间的监控与扩展策略
#### 5.3 数据备份与恢复策略
- 备份策略设计
- 数据备份类型与选择
- 数据恢复技巧与方案
- 备份与恢复的自动化与监控
本章将深入探讨存储优化技巧,帮助读者更好地管理和优化数据库存储,提高数据库性能与稳定性。
# 6. 性能监控与调优
在数据库设计与优化过程中,性能监控与调优是至关重要的一环。通过监控数据库的性能表现,及时发现潜在问题并进行调优,可以保证数据库系统的稳定性和高效性。下面将介绍性能监控与调优的相关知识点:
### 6.1 性能监控工具介绍
为了实时监控数据库的性能表现,我们需要借助专业的性能监控工具。常用的数据库性能监控工具有:
1. **MySQL Performance Schema**: MySQL自带的性能监控工具,可以监控数据库实例、会话和查询的性能数据,帮助识别慢查询、瓶颈等问题。
```sql
-- 示例代码:查看最耗时的SQL语句
SELECT SUM(t.timer_wait) AS total_latency, t.sql_text
FROM performance_schema.events_statements_summary_by_digest t
GROUP BY t.sql_text
ORDER BY total_latency DESC
LIMIT 10;
```
2. **Prometheus**: 开源的监控系统,支持多种数据库的性能监控,通过配置exporter将数据库性能数据导入Prometheus,再通过Grafana等工具展示监控数据。
```yaml
# 示例配置:Prometheus的MySQL Exporter
- job_name: 'mysql'
static_configs:
- targets: ['localhost:9104']
```
### 6.2 数据库参数调优
数据库参数的配置对于数据库性能有着至关重要的影响,合理调优参数可以提升数据库的性能表现。以下是一些常见的数据库参数调优技巧:
- **调整缓冲池大小**:根据数据库实际负载情况,合理设置缓冲池大小,如Innodb Buffer Pool Size对于InnoDB存储引擎的重要性不言而喻。
```ini
# 示例配置:InnoDB缓冲池大小设置
innodb_buffer_pool_size = 2G
```
- **调整连接数限制**:根据实际并发连接情况,适当调整最大连接数,避免因连接数不足导致性能瓶颈。
```ini
# 示例配置:MySQL最大连接数设置
max_connections = 100
```
### 6.3 高可用与容灾设计
保证数据库系统的高可用性是数据库设计的关键目标之一,常见的高可用与容灾设计方案包括:
- **主从复制**:通过主从复制实现数据的热备份和读写分离,提高系统的可用性。
```sql
-- 示例代码:MySQL主从复制配置
CHANGE MASTER TO MASTER_HOST='master_host',MASTER_USER='repl',MASTER_PASSWORD='repl_password';
START SLAVE;
```
- **数据库集群**:采用数据库集群技术,如MySQL Cluster、Galera Cluster等,实现数据库的自动故障转移和负载均衡。
```yaml
# 示例配置:MySQL Galera Cluster
wsrep_cluster_address="gcomm://node1,node2,node3"
```
通过以上性能监控与调优的方法,可以有效提升数据库系统的性能和稳定性,保障系统的高效运行。在实际应用中,需要根据业务特点和需求进行具体的调优策略制定和实施。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏着重于产品创意设计与实现,力求通过多个方面的技术和工具,为读者展现产品设计的全貌。文章包括从软件设计模式的基础概念到实际应用,利用HTML5和CSS3打造响应式网页设计的技巧,数据库设计与优化技巧的分享,Jenkins CI_CD在软件开发中的实际应用案例,以及Git版本控制工具的深入学习。此外,还讨论了AWS云计算平台的搭建与优化,大数据处理与分析平台的搭建经验以及智能物联网设备的开发与实现。这些内容涵盖了产品设计和开发的方方面面,旨在为读者提供全面的视角和实用的知识,让他们在产品创意设计方面得以更加全面的认识和应用。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Kraken框架自定义指令与过滤器:提升开发效率的扩展功能(自定义指令与过滤器)

参考资源链接:[KRAKEN程序详解:简正波声场计算与应用](https://wenku.csdn.net/doc/6412b724be7fbd1778d493e3?spm=1055.2635.3001.10343)
# 1. Kraken框架简介与自定义指令与过滤器的概念
## 1.1 Kraken框架简介
Kraken 是一个基于 Node.js 的高效 Web 开发框架,它以灵活和
系统监控与日志分析:ICC平台性能指标实时跟踪
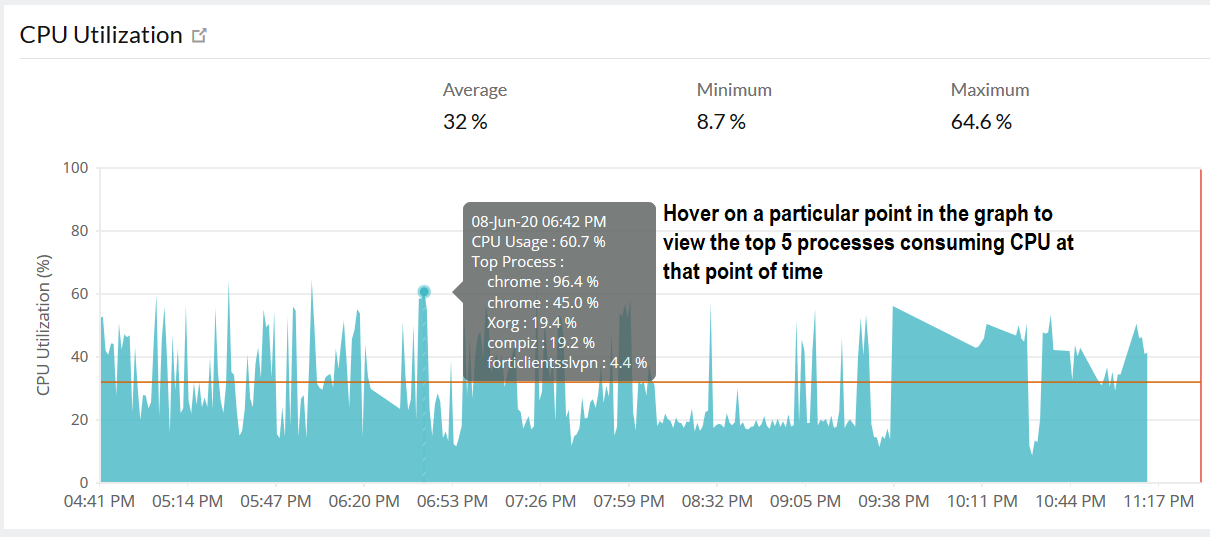
参考资源链接:[大华ICC平台V1.2.0使用手册:智能物联管理](https://wenku.csdn.net/doc/5b2ai5kr8o?spm=1055.2635.3001.10343)
# 1. ICC平台性能监控概述
ICC平台作为一款先进的监控解决方案,其性能监控是确保系统稳定运行和优化用户体验的关键。性能监控通常需要从多个维度进行,包括但不限于系统资源使用、网络响应时间、应用性能状态等。在这一章节中,我们将首先概述性能
Abaqus高级模拟:重力载荷在冲击载荷仿真中的动态响应
参考资源链接:[Abaqus CAE教程:施加重力载荷步骤详解](https://wenku.csdn.net/doc/2rn8c98egs?spm=1055.2635.3001.10343)
# 1. Abaqus基础与仿真概览
## 简介
在这一章节中,我们将对Abaqus这一著名的有限元分析(FEA)软件进行基础性介绍,并概括其在工程仿真领域的应用概览。Abaqus软件以其强
【数据管理高效策略】:Star CCM+场函数命令规则在大规模数据处理中的角色
参考资源链接:[STAR-CCM+场函数详解与自定义实例](https://wenku.csdn.net/doc/758tv4p6go?spm=1055.2635.3001.10343)
# 1. 数据管理与高效策略概述
数据管理是确保
数控机床编程高级技巧:进阶之路全解析
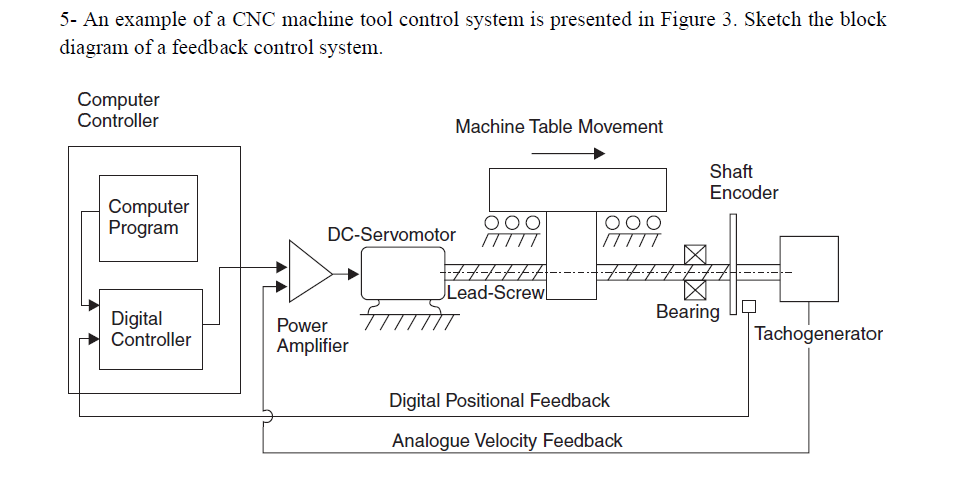
参考资源链接:[宝元数控系统操作与编程手册](https://wenku.csdn.net/doc/52g0s1dmof?spm=1055.2635.3001.10343)
# 1. 数控机床编程概述
数控机床编程是制造业中的核心技术之一,它允许我们通过精确的代码指令控制机床的加工过程。本章将简要介绍数控编程的相关概念和基础知识,为深入学习后续章节打下坚实的基础。
## 1.1 数控编程的含义与重要性
模拟电路中的555定时器:1Hz脉冲生成与应用全解析
参考资源链接:[使用555定时器创建1Hz脉冲方波发生器](https://wenku.csdn.net/doc/6401ad28cce7214c316ee808?spm=1055.2635.3001.10343)
# 1. 555定时器基础知识
## 1.1 555定时器的起源与应用
555定时器是一种广泛应用的模拟集成电路,最初由Signetics公司于1970年代推出,因其功能多样、可靠性高、成本低廉而成为电子爱好者和专业工程师的常用部件。它可以通过简单的外部连接,实现定时、延时、振荡等多种功能,广泛应用于工业控制、家用电器、玩具、汽车电子和各类实验电路中。
## 1.2 555定
惠普Smart Tank 510打印机:如何选择最佳耗材以降低成本

参考资源链接:[HP Smart Tank 510 打印机全面指南](https://wenku.csdn.net/doc/pkku1wvj9h?spm=1055.2635.3001.10343)
# 1. 理解惠普Smart Tank 510打印机及其耗材需求
惠普Smart Tank 510是一款
PPT VBA点名程序调试艺术:专家手把手解决常见难题
参考资源链接:[PPT VBA 课堂点名随机程序](https://wenku.csdn.net/doc/6412b708be7fbd1778d48d9d?spm=1055.2635.3001.10343)
# 1. PPT VBA点名程序的理论基础
在开始制作PPT VBA点名程序之前,理解其理论基础是至关重要的。VBA(Visual Basic for Applications)是一种编程语言,允许用户通过宏来自动化和自定义各种Office应用程序。点名程序作为一种应用,其核心在于通过VBA来控制PPT的界面和行为,实现随机或顺序点名的功能。
首先,要熟悉VBA的基本编程概念,如变量、
Ubuntu 20.04显卡驱动兼容性测试:理论与实践的完美结合

参考资源链接:[Ubuntu20.04 NVIDIA 显卡驱动与 CUDA、cudnn 安装指南](https://wenku.csdn.net/doc/3n29mzafk8?spm=1055.2635.3001.10343)
# 1. Ubuntu 20.04显卡驱动概述
## 显卡驱动的重要性
在U
GreenHills编译器预编译头文件:构建速度的秘密武器揭秘

参考资源链接:[GreenHills 2017.7 编译器使用手册](https://wenku.csdn.net/doc/6412b714be7fbd1778
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )