HTMLParser实战攻略:轻松打造网页数据抓取工具
发布时间: 2024-10-05 11:15:23 阅读量: 37 订阅数: 44 

htmlparser实现从网页上抓取数据

# 1. HTMLParser的基础知识与安装配置
## HTMLParser简介
HTMLParser是一个用于解析HTML文档的库,它能够将复杂的HTML文档分解成一系列的标签和属性,便于程序读取和处理。使用HTMLParser可以有效地进行网页数据的抓取、清洗和分析。
## 安装HTMLParser
在Python环境中安装HTMLParser非常简单,可以通过pip安装命令快速完成:
```bash
pip install html.parser
```
此过程仅需数秒,完成后即可在Python代码中导入并使用HTMLParser库。
## 配置与基本使用
HTMLParser库通过`HTMLParser`类实现HTML文档的解析。首先,需要从`html.parser`模块导入该类,然后创建解析器实例,并提供自己的处理方法来处理标签和文本。以下是一个简单的示例:
```python
from html.parser import HTMLParser
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print(f"Start tag: {tag}")
for attr in attrs:
print(f"Attribute {attr[0]}={attr[1]}")
def handle_endtag(self, tag):
print(f"End tag: {tag}")
def handle_data(self, data):
print(f"Data: {data}")
parser = MyHTMLParser()
parser.feed('<html><head><title>Test</title></head><body><p>Test paragraph</p></body></html>')
```
在上述代码中,`MyHTMLParser`类定义了如何处理开始标签、结束标签和数据。`feed`方法用于向解析器提供HTML文档字符串,并触发相关处理方法。这个简单的例子展示了HTMLParser的基本用法,为深入学习和应用HTMLParser打下基础。
# 2. HTML文档结构分析与解析
## 2.1 HTML基本结构解析
### 2.1.1 HTML元素与标签
HTML (HyperText Markup Language) 是构成网页内容的主要语言,它通过一系列预定义的标签(tags)来表示各种信息,如段落、标题、图片、链接等。HTML元素是构成网页的基石,它由一个标签的起始部分(start tag)、内容和结束标签(end tag)组成。
在解析HTML文档时,我们通常会遇到两种类型的标签:空标签(void tags)和容器标签(container tags)。空标签如`<img>`、`<br>`等,它们不包含任何内容,因此不需要结束标签。而容器标签如`<p>`、`<div>`等,则需要一个结束标签来表示内容的结束。
下面是一个简单的HTML元素示例:
```html
<p>This is a paragraph.</p>
```
在这个例子中,`<p>`是起始标签,`This is a paragraph.`是内容,而`</p>`是结束标签。HTMLParser库能够将这些标签和内容解析为可操作的对象。
### 2.1.2 属性与属性值的提取方法
HTML标签常常伴随属性(attributes),它们为标签提供额外的信息,如图片的源地址、链接的目标URL等。HTMLParser库提供了方法来获取这些属性,这对于抓取特定信息至关重要。
例如,一个带有多个属性的`<a>`标签如下:
```html
<a href="***" title="Example Domain">Example Domain</a>
```
在这个例子中,`href`和`title`是属性名,对应的值分别是`***`和`Example Domain`。通过HTMLParser的API,我们可以提取出这些属性值来进行进一步的处理。
## 2.2 DOM树的构建与遍历
### 2.2.1 DOM树模型的理论基础
DOM(Document Object Model)树是一种以树状结构表示HTML文档的模型。在这个模型中,每个HTML元素都是树中的一个节点。树的根节点是`document`对象,而所有其他节点则是这个根节点的子节点。
构建DOM树的过程涉及将HTML文档中的所有元素按照它们在文档中出现的顺序,以及它们之间的父子关系,组织成一个树形结构。这个过程对于理解文档的结构以及之后的页面操作非常关键。
### 2.2.2 使用HTMLParser进行DOM遍历
HTMLParser库提供了遍历DOM树的功能,允许开发者按照特定的顺序访问每一个节点。遍历操作通常遵循深度优先搜索(DFS)或广度优先搜索(BFS)的策略。
深度优先搜索在每次遍历到子节点时,会先遍历子节点的所有后代,然后才遍历兄弟节点。而广度优先搜索则是按照节点在文档中出现的顺序进行遍历。
下面是一个简单的代码示例,展示如何使用HTMLParser来遍历DOM树:
```python
from HTMLParser import HTMLParser
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print(f"Start tag: {tag}")
for attr in attrs:
print(f"\t{attr[0]}={attr[1]}")
def handle_endtag(self, tag):
print(f"End tag: {tag}")
def handle_data(self, data):
print(f"Data: {data}")
parser = MyHTMLParser()
parser.feed('<html><head><title>My Page</title></head><body><p>Sample paragraph.</p></body></html>')
```
在这个例子中,`handle_starttag`和`handle_endtag`分别在遇到起始标签和结束标签时被调用。`handle_data`方法用于处理标签之间的文本数据。
## 2.3 CSS选择器的运用
### 2.3.1 CSS选择器的概念与功能
CSS选择器是CSS规则中的一个基本组件,用于指定规则应用于哪些元素。在HTML解析过程中,CSS选择器也可以用来定位具有特定特征的DOM节点。
CSS选择器有多种类型,包括类选择器、ID选择器、标签选择器、属性选择器等。它们可以根据元素的类名、ID、标签名、属性及其值来选取元素。
例如,选择器`.my-class`定位所有`class`属性为`my-class`的元素,而选择器`[href="***"]`则选取所有`href`属性值为`***`的元素。
### 2.3.2 在HTMLParser中使用CSS选择器进行节点选择
HTMLParser提供了一个灵活的接口来使用CSS选择器,允许用户根据元素的标签名、类名、ID、属性等进行查询和过滤。这对于抓取具有特定特征的内容非常有用。
使用HTMLParser时,可以通过CSS选择器查询方法来获取特定元素,例如:
```python
from HTMLParser import HTMLParser
parser = HTMLParser()
parser.feed('<html><body><p class="my-class">Hello World</p></body></html>')
# 使用CSS选择器找到class为my-class的段落元素
elements = parser.find_elements_by_class_name('my-class')
for element in elements:
print(element)
```
在这个代码段中,`find_elements_by_class_name`方法利用CSS选择器来定位具有特定类名的元素。这个功能在解析复杂文档并提取有用信息时尤其有用。
在接下来的章节中,我们将深入探讨HTMLParser在网页数据抓取中的应用,包括抓取特定内容的技巧、数据清洗与格式化,以及数据存储与管理等关键话题。
# 3. HTMLParser在网页数据抓取中的应用
### 3.1 抓取特定内容的实战技巧
#### 3.1.1 使用HTMLParser定位并提取信息
在当前网络信息爆炸的时代,从网页中抓取特定内容成为了自动化处理数据的一个重要手段。HTMLParser库作为Python的一个内置库,为处理HTML文档提供了便捷的API。它允许我们以编程方式遍历HTML文档,并提取有用信息。
下面是一个简单的例子,我们将使用HTMLParser来提取一个网页中所有的段落文本。
```python
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == "p":
self.in_p = True
print(f"Found a paragraph starting with: {attrs}")
def handle_endtag(self, tag):
if tag == "p":
self.in_p = False
print("End of paragraph")
def handle_data(self, data):
if self.in_p:
print(f"Paragraph text: {data.strip()}")
# 示例HTML文档
html_doc = """
<html>
<head><title>Example</title></head>
<body>
<p>This is a paragraph.</p>
<p>Another paragraph here.</p>
</body>
</html>
parser = MyHTMLParser()
parser.feed(html_doc)
```
在上述代码中,我们首先导入了`HTMLParser`类,并定义了一个子类`MyHTMLParser`,重写了`handle_starttag`、`handle_endtag`和`handle_data`方法来专门处理段落标签`<p>`。当我们遇到`<p>`标签时,通过`self.in_p`状态变量来控制只在段落内容出现时打印数据。
#### 3.1.2 处理动态加载内容的方法
随着现代网页技术的发展,越来越多的内容是通过JavaScript动态加载的。这就意味着,传统的HTMLParser可能无法直接抓取到这部分内容,因为这些内容在HTML文档加载时并不存在。为了解决这个问题,我们可以使用Selenium或Pyppeteer这样的工具来模拟浏览器行为。
下面使用Selenium来抓取一个动态加载的内容作为例子:
```python
from selenium import webdriver
# 用Selenium启动一个Chrome浏览器实例
driver = webdriver.Chrome()
# 打开目标网页
driver.get('***')
# 等待JavaScript加载完成,这里需要根据实际网页情况调整等待策略
***mon.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
element = wait.until(EC.presence_of_element_located((By.ID, "dynamic-content")))
# 提取动态加载的内容
dynamic_content = element.text
# 关闭浏览器
driver.quit()
print(f"Dynamic content extracted: {dynamic_content}")
```
在上述代码中,我们首先导入了selenium模块,然后通过`webdriver`创建了一个浏览器实例。`driver.get`方法用于打开目标网页。接下来,我们使用`WebDriverWait`和`expected_conditions`等待特定的元素加载完成,最后提取并打印了动态加载的内容。
### 3.2 数据清洗与格式化
#### 3.2.1 清洗数据的重要性
在实际抓取网页数据时,我们常常会得到一些格式不规范、含有无效或多余信息的数据。为了确保数据质量,提高后续数据分析的准确性,数据清洗成了一个不可或缺的步骤。通过数据清洗,我们可以去除噪声和异常值,校正数据格式,并填补缺失值。
#### 3.2.2 使用HTMLParser进行数据预处理
使用HTMLParser,我们不仅可以抓取网页数据,还可以在提取数据的同时进行初步的预处理。下面是如何在抓取过程中去除一些常见的HTML标记和多余空格的例子:
```python
from html.parser import HTMLParser
class CleanerHTMLParser(HTMLParser):
def __init__(self):
super().__init__()
self.current_data = ""
self.data = []
def handle_data(self, data):
self.current_data = data
# 去除文本周围的空白字符
stripped_data = data.strip()
# 进一步清洗数据,例如去除HTML标签
cleaned_data = self.cleanHTML(stripped_data)
self.data.append(cleaned_data)
def cleanHTML(self, html):
return html.replace("<br>", "").replace(" ", "").replace("<p>", "").replace("</p>", "")
parser = CleanerHTMLParser()
# 示例HTML文档,包含一些无用的HTML标签和空白字符
html_doc = """
<html>
<body>
<p> Some text <br> with <p>HTML tags</p> and spaces </p>
</body>
</html>
parser.feed(html_doc)
print("Cleaned data:")
for d in parser.data:
print(d)
```
在这个例子中,`CleanerHTMLParser`类扩展了`HTMLParser`并重写了`handle_data`方法来去除文本周围的空白字符,并通过`cleanHTML`方法进一步去除HTML标签。
### 3.3 抓取数据的存储与管理
#### 3.3.1 常见的数据存储方案
抓取到的数据需要存储到某种媒介中,以便之后的分析和使用。常见的数据存储方案包括但不限于:文本文件、数据库、JSON或XML文件等。每种存储方式有其特定的应用场景和优缺点。选择合适的存储方案可以提高数据处理的效率和准确性。
#### 3.3.2 利用HTMLParser整合存储流程
使用HTMLParser整合存储流程时,我们需要考虑如何将解析后数据与存储方案结合。例如,如果选择将数据存储到CSV文件中,我们可以使用Python的`csv`模块:
```python
import csv
from html.parser import HTMLParser
# 假设我们已经从HTMLParser中得到了清洗后的数据
data = [
{"title": "Article 1", "author": "John Doe"},
{"title": "Article 2", "author": "Jane Smith"}
]
# 使用CSV存储数据
with open("articles.csv", "w", newline="", encoding="utf-8") as csv***
*** ["title", "author"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# 写入表头
writer.writeheader()
# 写入数据
for row in data:
writer.writerow(row)
print("Data stored in articles.csv")
```
以上代码段使用了HTMLParser提取数据之后,通过CSV文件存储数据,使数据管理变得更加清晰和规范。在实际应用中,我们还可以结合其他存储方案(如数据库)和相应的库来整合存储流程,进一步提高处理效率。
# 4. HTMLParser高级应用技巧
在这一章节中,我们将深入探讨HTMLParser在高级场景中的使用技巧。HTMLParser作为一款强大的库,不仅能够处理基础的HTML文档解析,还能够应对更加复杂的网络数据抓取任务。本章节将涵盖处理异步加载页面、复杂页面结构的数据抓取,以及如何提高抓取效率和进行异常处理等主题。
## 4.1 异步加载页面的处理
随着现代网页技术的发展,越来越多的网页使用了异步加载技术(例如Ajax或JavaScript动态生成内容)来提升用户体验。传统的页面解析方式已经无法满足这类内容抓取的需求。这时,我们需要掌握如何使用HTMLParser来应对异步加载页面的挑战。
### 4.1.1 分析异步加载机制
首先,让我们分析一下异步加载页面的常见机制。这些页面通常会有专门的API接口响应异步请求,并返回数据,然后由JavaScript动态地将这些数据渲染到页面上。因此,为了抓取这些动态生成的内容,我们需要理解页面加载过程中HTTP请求的细节。
通过开发者工具(F12)进行网络请求的监控,我们可以观察到哪些请求是异步加载的。每个请求都可能对应着页面的一部分内容,了解这些请求的URL、参数以及返回的数据格式是关键的第一步。
### 4.1.2 利用HTMLParser抓取异步内容
一旦我们识别出关键的异步请求,就可以使用HTMLParser来解析返回的数据。例如,如果异步加载的内容是JSON格式的,我们首先需要解析JSON,然后再将解析出来的数据构建成DOM结构进行解析。
```python
import json
from html.parser import HTMLParser
# 假设这是从API获取的JSON格式数据
json_data = '{"title": "Async Content Example", "content": "<p>This is dynamically loaded content.</p>"}'
# 解析JSON数据
data = json.loads(json_data)
# 创建一个HTMLParser对象
parser = HTMLParser()
# 将JSON字符串中的HTML内容转换为可解析的字符串
clean_content = data['content'].replace('<', '<').replace('>', '>')
# 将清洗后的字符串传递给HTMLParser处理
parser.feed(clean_content)
# 获取解析结果
parsed_html = parser.get_data()
print(parsed_html)
```
上面的代码展示了如何将异步加载的数据转换为HTMLParser可解析的字符串,进而进行后续的解析和数据处理。处理后的数据可以用于进一步的分析或存储。
## 4.2 复杂页面结构的数据抓取
处理嵌套表格和列表,以及抓取JavaScript渲染的内容,是复杂页面结构数据抓取场景中的两个典型案例。这些任务涉及到的内容较为复杂,对解析技术的要求较高。
### 4.2.1 处理嵌套表格和列表
当遇到大量嵌套的表格和列表时,需要逐层遍历DOM树,并根据需要提取数据。对于表格,可能需要遍历`<table>`, `<tr>`, `<td>`标签;对于列表,则可能是`<ul>`, `<ol>`, `<li>`标签。我们利用HTMLParser的事件方法(如`handle_starttag`, `handle_data`等)来实现这一过程。
```python
class MyHTMLParser(HTMLParser):
def __init__(self):
super().__init__()
self.current_tag = ''
self.data = []
def handle_starttag(self, tag, attrs):
self.current_tag = tag
def handle_data(self, data):
if self.current_tag in ['td', 'li']:
self.data.append(data.strip())
def handle_endtag(self, tag):
self.current_tag = ''
# 示例代码展示
parser = MyHTMLParser()
parser.feed('<table><tr><td>Item 1</td></tr></table>')
print(parser.data)
```
### 4.2.2 抓取JavaScript渲染的内容
对于完全由JavaScript动态生成的内容,传统的HTMLParser已经无能为力。这时,我们可以借助Selenium或Pyppeteer这样的浏览器自动化工具来模拟浏览器操作,获取页面加载后的数据。
```python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
# 设置Selenium的WebDriver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# 加载含有JavaScript内容的页面
driver.get('***')
# 使用Selenium获取页面源代码
html = driver.page_source
# 关闭浏览器
driver.quit()
# 使用BeautifulSoup解析获取到的HTML源代码
soup = BeautifulSoup(html, 'html.parser')
```
在这个例子中,我们首先使用Selenium获取到了JavaScript渲染完毕后的页面源代码,然后利用BeautifulSoup进行解析。这样就能够抓取到原本无法通过HTMLParser直接获取的数据了。
## 4.3 高效抓取与异常处理
在进行大量数据抓取时,效率和稳定性是至关重要的。一个高效且健壮的抓取脚本能够显著提高数据处理的速率,并且减少因异常情况导致的程序中断。
### 4.3.1 提升HTMLParser数据抓取效率
为了提高抓取效率,我们可以通过以下几种方式:
- **并行处理多个请求**:使用多线程或异步请求来并行抓取多个页面,减少等待时间。
- **智能缓存机制**:对于已经抓取过的内容,我们可以实现智能缓存,避免重复抓取。
- **优化解析策略**:只关注需要的数据,而不是整个页面。例如,使用CSS选择器直接定位到目标内容,而不是遍历整个DOM树。
### 4.3.2 设计健壮的异常处理机制
在编写爬虫脚本时,我们几乎不可避免地会遇到各种异常,例如网络请求失败、解析错误等。一个健壮的爬虫应该能够处理这些异常,确保程序稳定运行。
```python
try:
# 尝试执行抓取和解析操作
parser.feed(html_content)
except Exception as e:
# 处理异常情况,例如记录日志、重试等
print(f"An error occurred: {e}")
```
在上述代码段中,我们使用try-except结构来捕获异常,并进行相应的错误处理。这有助于确保在发生异常时,程序能够平滑地继续执行,而不是直接崩溃。
通过本章节的介绍,我们学习了如何运用HTMLParser处理更高级的抓取任务,包括异步加载页面的处理、复杂页面结构的数据抓取,以及如何提升效率与稳定性的策略。这些技巧对于希望深入挖掘网页数据的开发者来说,是非常有价值的。在下一章节中,我们将探讨HTMLParser与其他技术的整合应用,包括与Scrapy框架的结合,以及如何将抓取的数据存储到数据库和构建Web应用以可视化抓取结果。
# 5. HTMLParser与其他技术的整合应用
## 5.1 使用HTMLParser结合Scrapy框架
### 5.1.1 Scrapy框架的介绍
Scrapy是一个快速的高层次的网页抓取和网页爬取框架,用于抓取网页数据并从页面中提取结构化的数据。Scrapy被广泛用于数据挖掘、信息处理或历史记录存档。其主要特点包括快速的处理速度、强大的选择器、支持多种序列化格式和强大的扩展能力。
Scrapy使用Twisted异步网络框架来处理网络请求和数据流,这使得Scrapy能够进行高效的并发请求,大大提升了数据爬取的速度。在开发Scrapy爬虫时,通常会定义一个Spider来处理网页抓取的逻辑,包括请求URL、解析响应内容以及提取数据。
### 5.1.2 HTMLParser在Scrapy中的应用案例
为了在Scrapy框架中使用HTMLParser,我们需要创建一个自定义的解析器类,继承自`scrapy.Selector`或`scrapy.XmlXPathSelector`,然后使用HTMLParser来解析响应内容。下面是一个整合HTMLParser到Scrapy的例子:
```python
import scrapy
from scrapy.selector import Selector
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.data = []
def handle_starttag(self, tag, attrs):
# 每个标签开始时执行的操作
pass
def handle_endtag(self, tag):
# 每个标签结束时执行的操作
pass
def handle_data(self, data):
# 每个数据节点时执行的操作
self.data.append(data)
class MySpider(scrapy.Spider):
name = 'my_spider'
start_urls = ['***']
def parse(self, response):
parser = MyHTMLParser()
parser.feed(response.body.decode('utf-8'))
# 此时parser.data中保存了页面中的所有文本数据
# 可以进一步进行数据提取和清洗
yield {
'data': parser.data
}
```
上面的代码展示了一个简单的Scrapy爬虫,其中定义了一个`MyHTMLParser`类,它继承自`HTMLParser`。在`parse`方法中,我们创建了一个`MyHTMLParser`实例,并将响应体传递给`feed`方法来解析页面。最后,将解析得到的数据通过yield返回。
## 5.2 结合数据库存储抓取数据
### 5.2.1 数据库选择与连接设置
在实际的网页数据抓取项目中,常常需要将抓取到的数据存储到数据库中,以便进行进一步的分析和处理。选择合适的数据库是存储过程中的关键一步。常见的数据库类型包括关系型数据库如MySQL、PostgreSQL,以及NoSQL数据库如MongoDB、Redis等。
选择数据库后,我们需要设置与数据库的连接。例如,使用Python连接MySQL数据库,可以使用`pymysql`或`sqlalchemy`这样的库。下面是一个使用`pymysql`连接MySQL数据库的示例:
```python
import pymysql
# 连接到数据库
connection = pymysql.connect(host='localhost',
user='user',
password='password',
db='database',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
try:
with connection.cursor() as cursor:
# 创建一个简单的SQL查询语句
sql = "SELECT `id`, `name` FROM `my_table`"
cursor.execute(sql)
# 获取所有数据记录
results = cursor.fetchall()
for row in results:
print(row)
finally:
connection.close()
```
### 5.2.2 使用HTMLParser将数据存入数据库
在将数据存入数据库之前,首先需要对数据进行解析和提取。这可以通过HTMLParser来完成。以下是一个使用HTMLParser提取数据并将其存入MySQL数据库的例子:
```python
class MyHTMLParser(HTMLParser):
# 假设我们提取文章标题
def __init__(self, conn):
super().__init__()
self.conn = conn
self.data = []
def handle_starttag(self, tag, attrs):
self.current_tag = tag
def handle_endtag(self, tag):
self.current_tag = None
def handle_data(self, data):
if self.current_tag == 'title':
self.data.append(data)
# 假设我们已经建立了数据库连接
connection = ... # 与5.2.1节中相同的数据库连接代码
try:
parser = MyHTMLParser(connection)
parser.feed(response.body.decode('utf-8'))
# 此时parser.data中保存了所有标题数据
for title in parser.data:
sql = "INSERT INTO my_table (name) VALUES (%s)"
with connection.cursor() as cursor:
cursor.execute(sql, (title,))
***mit()
finally:
connection.close()
```
在该代码示例中,我们定义了`MyHTMLParser`类,它将解析HTML响应并提取所有的文章标题。然后,我们将这些标题插入到数据库表`my_table`中。
## 5.3 构建Web应用以可视化抓取结果
### 5.3.1 Web应用的开发基础
为了将抓取的数据更直观地展示给用户,或者为了提供数据的交互式查询功能,我们常常需要构建一个Web应用。构建Web应用的基础通常包括前端和后端的开发。前端负责展示和与用户的交互,后端则处理业务逻辑、数据库交互和数据处理。
流行的Web应用开发框架包括Flask、Django(Python)、Express(Node.js)、Ruby on Rails(Ruby)等。以Python的Flask框架为例,其轻量级且灵活的特点,非常适合用于快速开发Web应用。
### 5.3.2 利用HTMLParser集成数据可视化功能
当数据被抓取和存储到数据库后,我们需要提供一种方式来展示这些数据。数据可视化是将数据转换为图形表示的一种方式,它可以帮助用户更好地理解数据。
以Flask为例,我们可以在Web应用中集成HTMLParser,然后使用如Highcharts、D3.js等JavaScript库来实现数据可视化。下面是一个简单的例子,说明如何将抓取的数据展示为一个图表:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Data Visualization</title>
<script src="***"></script>
<script src="***"></script>
</head>
<body>
<div id="chart-container" style="width: 100%; height: 400px;"></div>
<script>
// 假设从服务器端接收到的数据格式如下:
var chartData = [
{ name: 'January', data: 121 },
{ name: 'February', data: 106 },
// ... 其他月份的数据
];
// 使用Highcharts绘制图表
Highcharts.chart('chart-container', {
chart: {
type: 'column'
},
title: {
text: 'Monthly Average Rainfall'
},
subtitle: {
text: 'Source: ***'
},
xAxis: {
categories: chartData.map(function(d) {
return d.name;
})
},
yAxis: {
title: {
text: 'Rainfall (mm)'
}
},
series: [{
name: 'Rainfall',
data: chartData.map(function(d) {
return d.data;
})
}]
});
</script>
</body>
</html>
```
在后端的Flask应用中,我们需要定义路由和视图函数来返回JSON格式的抓取数据,然后在前端的JavaScript代码中接收并处理这些数据以生成图表。
这一系列的步骤展示了如何将HTMLParser与其他技术整合应用。首先,我们介绍了如何使用HTMLParser在Scrapy框架中提取数据。接着,我们讲解了如何将抓取的数据存入数据库,并且给出了连接数据库和存储数据的示例代码。最后,我们展示了如何通过构建Web应用来可视化抓取结果,结合了Flask框架和Highcharts图表库实现数据的图形化展示。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面深入地介绍了Python库文件HTMLParser,从入门到精通,涵盖了10大实用技巧、5大高级用法、实战攻略、性能优化指南、与BeautifulSoup的对比、自定义解析器构建、常见问题解析、项目实战、安全指南、自动化测试中的应用、与正则表达式的协同使用、异步处理和多线程应用、深度使用指南、用户案例分析等内容。专栏旨在帮助读者全面掌握HTMLParser,轻松解析网页数据,打造高效的网页内容分析工具,提升自动化测试效率,并安全地处理网页内容。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
并行编程多线程指南:精通线程同步与通信技术(权威性)

# 摘要
随着现代计算机系统的发展,多线程编程已成为实现并行计算和提高程序性能的关键技术。本文首先介绍了并行编程和多线程的基础概念,随后深入探讨了线程同步机制,包括同步的必要性、锁机制、其他同步原语等。第三章详细描述了线程间通信的技术实践,强调了消息队列和事件/信号机制的应用。第四章着重讨论并行算法设计和数据竞争问题,提出了有效的避免策略及锁无关同步技术。第五章分析了多线程编程的高级主题,包括线程池、异步编程模型以及调试与性能分析。最后一章回
【Groops安全加固】:保障数据安全与访问控制的最佳实践
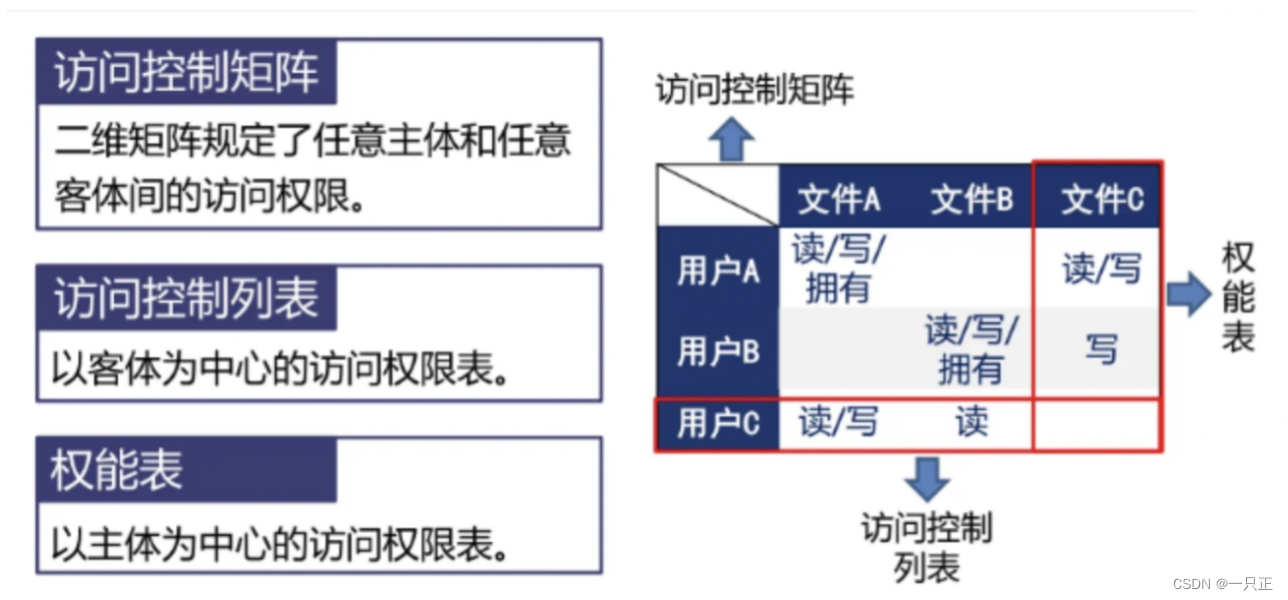
# 摘要
本文全面探讨了Groovy编程语言在不同环境下的安全实践和安全加固策略。从Groovy基础和安全性概述开始,深入分析了Groovy中的安全实践措施,包括脚本执行环境的安全配置、输入验证、数据清洗、认证与授权机制,以及代码审计和静态分析工具的应用。接着,文章探讨了Groovy与Java集成的安全实践,重点关注Java安全API在Groovy中的应用、JVM安全模型以及安全框架集成。此外,本
CMOS数据结构与管理:软件高效操作的终极指南

# 摘要
本文系统地探讨了CMOS数据结构的理论基础、管理技巧、高级应用、在软件中的高效操作,以及未来的发展趋势和挑战。首先,定义了CMOS数据结构并分析了其分类与应用场景。随后,介绍了CMOS数据的获取、存储、处理和分析的实践技巧,强调了精确操作的重要性。深入分析了CMOS数据结构在数据挖掘和机器学习等高级应用中的实例,展示了其在现代软件开发和测试中的
【服务器性能调优】:深度解析,让服务器性能飞跃提升的10大技巧
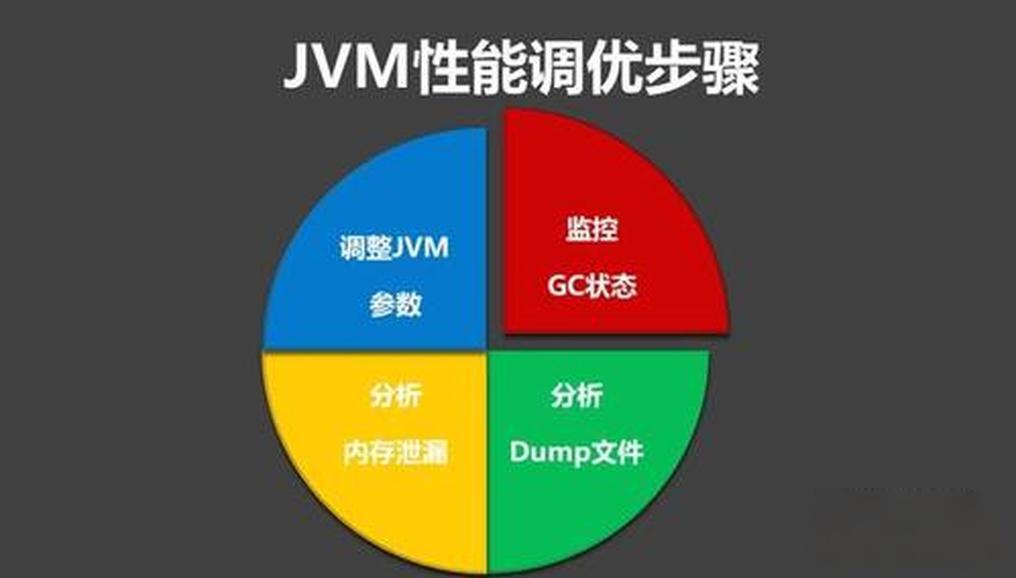
# 摘要
服务器性能调优是确保高效稳定服务运行的关键环节。本文介绍了服务器性能调优的基础概念、硬件优化策略、操作系统级别的性能调整、应用层面的性能优化以及监控和故障排除的实践方法。文章强调了硬件组件、网络设施、电源管理、操作系统参数以及应用程序代码和数据库性能的调优重要性。同时,还探讨了如何利用虚拟化、容器技术和自动化工具来实现前瞻性优化和管理。通过这些策略的实施
【逆变器测试自动化】:PIC单片机实现高效性能测试的秘诀
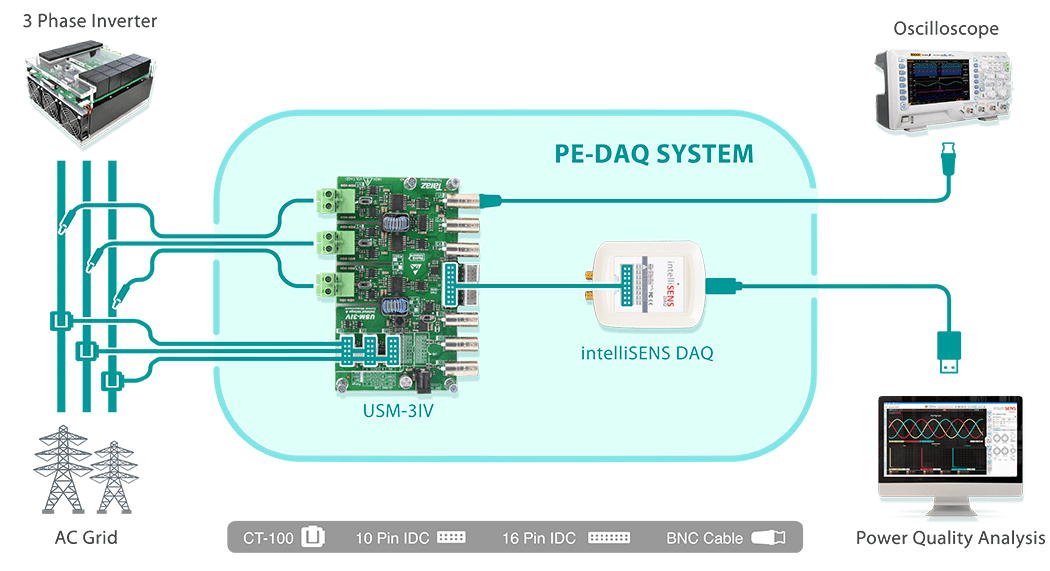
# 摘要
逆变器测试自动化是一个复杂过程,涉及对逆变器功能、性能参数的全面评估和监控。本文首先介绍了逆变器测试自动化与PIC单片机之间的关系,然后深入探讨了逆变器测试的原理、自动化基础以及PIC单片机的编程和应用。在第三章中,着重讲述了PIC单片机编程基础和逆变器性能测试的具体实现。第四章通过实践案例分析,展示了测试自动化系统的构建过程、软件设计、硬件组成以及测试结果的分
分布式数据库扩展性策略:构建可扩展系统的必备知识
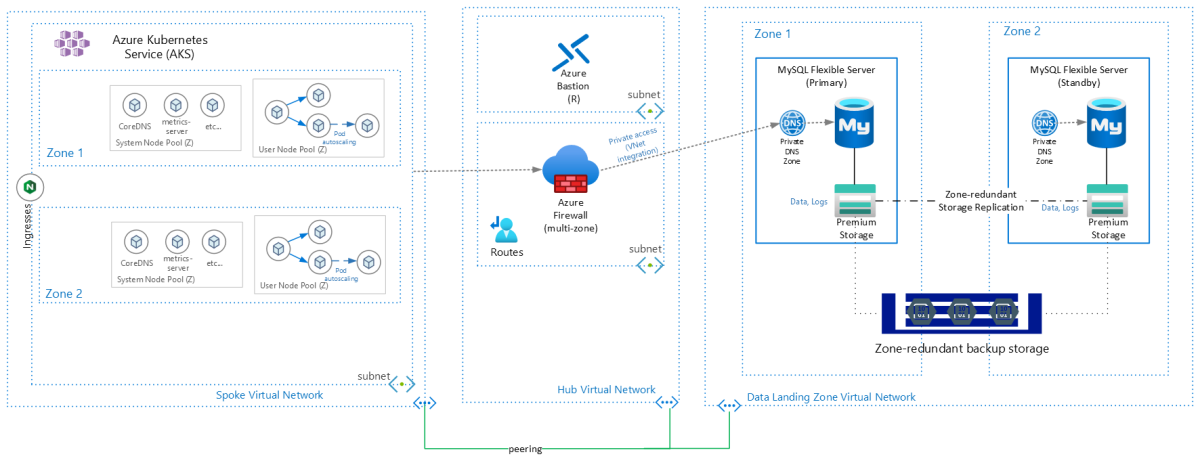
# 摘要
分布式数据库作为支持大规模数据存储和高并发处理的关键技术,其扩展性、性能优化、安全性和隐私保护等方面对于现代信息系统至关重要。本文全面探讨了分布式数据库的基本概念和架构,分析了扩展性理论及其在实际应用中的挑战与解决方案,同时深入研究了性能优化策略和安全隐私保护措施。通过对理论与实践案例的综合分析,本文展望了未
【IAR嵌入式软件开发必备指南】:从安装到项目创建的全面流程解析

# 摘要
本文全面介绍IAR嵌入式开发环境的安装、配置、项目管理及代码编写与调试方法。文章首先概述了IAR Embedded Workbench的优势和安装系统要求,然后详述了项目创建、源文件管理以及版本控制等关键步骤。接下来,探讨了嵌入式代码编写、调试技巧以及性能分析与优化工具,特别强调了内
【冠林AH1000系统安装快速指南】:新手必看的工程安装基础知识
# 摘要
本文全面介绍了冠林AH1000系统的安装流程,包括安装前的准备工作、系统安装过程、安装后的配置与优化以及系统维护等关键步骤。首先,我们分析了系统的硬件需求、环境搭建、安装介质与工具的准备,确保用户能够顺利完成系统安装前的各项准备工作。随后,文章详细阐述了冠林AH1000系统的安装向导、分区与格式化、配置与启动等关键步骤,以保证系统能够正确安装并顺利启动。接着,文章探讨了安装后的网络与安全设置、性能调
【MS建模工具全面解读】:深入探索MS建模工具的10大功能与优势

# 摘要
本文全面介绍了MS建模工具的各个方面,包括其核心功能、高级特性以及在不同领域的应用实践。首先,概述了MS建模工具的基
电力系统创新应用揭秘:对称分量法如何在现代电网中大显身手
# 摘要
对称分量法是电力系统分析中的一种基本工具,它提供了处理三相电路非对称故障的有效手段。本文系统地回顾了对称分量法的理论基础和历史沿革,并详述了其在现代电力系统分析、稳定性评估及故障定位等领域的应用。随着现代电力系统复杂性的增加,特别是可再生能源与电力电子设备的广泛应用,对称分量法面临着新的挑战和创新应用。文章还探讨了对称分量法在智能电网中的潜在应用前景,及其与自动化、智能化技术的融合,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )