HTMLParser项目实战:高效网页内容分析工具构建手册
发布时间: 2024-10-05 11:36:33 阅读量: 55 订阅数: 32 

Python HTML解析模块HTMLParser用法分析【爬虫工具】
:max_bytes(150000):strip_icc()/ScreenShot2018-01-13at9.43.10AM-5a5a3756d92b09003679607e.png)
# 1. HTMLParser项目概述
HTMLParser是一个用于解析HTML文档,并从中提取所需信息的工具库。它旨在简化网络爬虫、数据抓取和内容解析等任务。由于HTML文档结构通常比较复杂,传统的字符串匹配方法无法有效地处理嵌套、属性、特殊字符等复杂情况,因此需要一个能够理解HTML结构并进行精确解析的系统。本章将介绍HTMLParser的基本概念、应用场景及其在现代Web开发中的重要性。
HTMLParser不仅仅是一个解析器,它更像一个框架,允许开发者根据自己的需求进行定制化开发。无论是简单的网页内容提取还是复杂的动态内容解析,HTMLParser都提供了强大的支持。
理解HTMLParser的项目概述是使用这一工具并发挥其潜力的前提。接下来,我们将深入探讨HTMLParser的核心解析技术,以及如何将其应用到各种实际场景中,为开发者提供更为高效、准确的解决方案。
# 2. HTMLParser核心解析技术
## 2.1 HTML文档结构解析
HTML文档的结构解析是HTMLParser中最为基础和核心的技术之一。通过深入理解HTML的DOM树结构,开发者可以准确地进行节点遍历与搜索,这对于后续的网页数据处理和内容提取至关重要。
### 2.1.1 HTML DOM树结构理解
HTML文档被浏览器解析成一个结构化的树形模型,这个模型被称为DOM(文档对象模型)。每一个HTML元素都成为DOM树的一个节点。理解DOM树是进行HTML解析的基础。
```html
<!-- HTML 示例 -->
<html>
<head>
<title>页面标题</title>
</head>
<body>
<h1>这是一个标题</h1>
<p>这是一个段落。</p>
<div>
<p>这是一个嵌套的段落。</p>
</div>
</body>
</html>
```
在上述HTML文档中,`<html>` 是根节点,`<head>` 和 `<body>` 是它的两个子节点。每个 `<p>`、`<h1>` 和 `<div>` 都是进一步的子节点。通过这种结构,我们可以逐层深入地访问每一个元素。
### 2.1.2 节点遍历与搜索技术
节点遍历是获取DOM树中所有节点的过程,包括子节点、同级节点及父节点。这一步骤通常使用深度优先搜索(DFS)或广度优先搜索(BFS)算法。
```python
# Python示例代码:HTMLParser节点遍历
from html.parser import HTMLParser
from html.parser import HTMLParseError
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print(f"Start tag: {tag}")
def handle_endtag(self, tag):
print(f"End tag: {tag}")
def handle_data(self, data):
print(f"Data: {data}")
# 解析HTML文档
parser = MyHTMLParser()
parser.feed('<html><head><title>Test</title></head><body><p>Sample paragraph.</p></body></html>')
```
在上面的Python代码中,我们创建了一个 `MyHTMLParser` 类,它继承自 `HTMLParser` 并重写了 `handle_starttag`, `handle_endtag`, 和 `handle_data` 方法以处理HTML标签的开始、结束以及数据节点。
## 2.2 HTML解析算法原理
解析算法是HTMLParser性能和准确性的核心,选择合适的解析算法对于处理各种复杂的HTML文档至关重要。
### 2.2.1 解析算法的选择与比较
解析算法主要分为两大类:自顶向下(Top-Down)和自底向上(Bottom-Up)。自顶向下的算法从HTML的根节点开始,逐步解析每个子节点。自底向上的算法则从叶子节点开始,向上构建DOM树。
每种算法都有其优缺点。例如,自顶向下算法易于实现,但可能会遇到解析歧义;自底向上算法则在处理闭合标签时更为准确,但实现起来复杂度更高。
### 2.2.2 解析过程中的性能优化
性能优化在HTML解析中同样重要,特别是在处理大型文档时。优化可以从多个方面入手,如缓存机制、异步解析以及减少回溯。
```mermaid
graph TD
A[开始解析HTML文档] --> B[初始化缓冲区]
B --> C[读取HTML片段]
C --> D{是否已解析完毕}
D -- 是 --> E[构建DOM树]
D -- 否 --> F[应用缓冲区优化]
F --> C
E --> G[优化加载时间]
```
在上述流程图中,我们展示了HTML解析的一个优化过程。通过不断地读取HTML片段并构建DOM树,我们最终优化了加载时间,这主要通过应用缓冲区优化来实现。
## 2.3 HTMLParser的定制化扩展
HTMLParser允许开发者基于其核心功能进行定制化扩展,使得解析器更加灵活,能够处理特定场景下的需求。
### 2.3.1 解析规则的定制
开发者可以通过定制解析规则来适应不同的HTML结构和内容需求。这些规则可以是正则表达式,也可以是基于特定属性的匹配规则。
```python
# Python示例代码:定制化解析规则
import re
def custom_parse_rule(tag):
if re.search(r'^h\d$', tag): # 匹配h1, h2, h3...
return "标题标签"
elif tag == "p":
return "段落标签"
# 其他规则定义...
else:
return "未知标签"
# 使用定制化解析规则
rule = custom_parse_rule('h2')
print(f"标签 <{rule}> 被识别")
```
在此示例中,我们定义了一个 `custom_parse_rule` 函数,它根据标签名返回相应的类型描述。这样的定制化规则可以帮助开发者更细致地控制HTML内容的解析。
### 2.3.2 解析器的自定义扩展点
HTMLParser框架也提供了自定义扩展点,允许开发者在解析过程中插入自定义逻辑。
```python
# Python示例代码:解析器自定义扩展点
class ExtendedHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
if tag in ['img', 'video']: # 特定元素处理
_, value = next((a for a in attrs if a[0] == 'src'), (None, None))
if value:
print(f"找到媒体文件: {value}")
# 使用自定义扩展点处理HTML
parser = ExtendedHTMLParser()
parser.feed('<html><body><img src="image.png"><video src="video.mp4"></body></html>')
```
在此代码中,`ExtendedHTMLParser` 类通过重写 `handle_starttag` 方法来检测并处理媒体文件。这种方式提供了一个扩展点,允许开发者在HTML文档的解析过程中实现自定义功能。
以上为HTMLParser核心解析技术的详细解读,下一章节将介绍HTMLParser项目在实战应用中的具体实现和优化方法。
# 3. HTMLParser项目实战应用
## 3.1 高效网页爬虫构建
### 3.1.1 网页内容抓取技术
网页内容抓取是构建高效爬虫的基础。HTMLParser提供了强大的解析支持,通过与Request库或Selenium结合使用,可以实现对静态和动态网页内容的高效抓取。
在静态网页抓取场景中,通常使用Python的`requests`库获取网页的HTML源代码。以下是一个简单的示例代码,用于展示如何使用`requests`和`HTMLParser`进行网页内容抓取:
```python
import requests
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
def __init__(self):
super().__init__()
self.data = ""
def handle_data(self, data):
self.data += data
def get_data(self):
return self.data
response = requests.get("***")
parser = MyHTMLParser()
parser.feed(response.text)
print(parser.get_data())
```
在此代码中,`MyHTMLParser`类继承自`HTMLParser`,并重写了`handle_data`方法用于收集数据。实例化`MyHTMLParser`后,通过`feed`方法将获取到的网页内容传递给解析器进行处理。最后,通过调用`get_data`方法获取到抓取到的数据。
在动态网页抓取方面,因为内容可能由JavaScript动态加载,所以需要使用`Selenium`来模拟浏览器的行为。示例如下:
```python
from s
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面深入地介绍了Python库文件HTMLParser,从入门到精通,涵盖了10大实用技巧、5大高级用法、实战攻略、性能优化指南、与BeautifulSoup的对比、自定义解析器构建、常见问题解析、项目实战、安全指南、自动化测试中的应用、与正则表达式的协同使用、异步处理和多线程应用、深度使用指南、用户案例分析等内容。专栏旨在帮助读者全面掌握HTMLParser,轻松解析网页数据,打造高效的网页内容分析工具,提升自动化测试效率,并安全地处理网页内容。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【OMP算法:10大性能优化技巧】:专家级算法调优指南

# 摘要
本文全面介绍了正交匹配追踪(OMP)算法的理论基础、性能调优以及实践应用。首先,概述了OMP算法的起源、理论框架和核心概念,随后深入分析了算法的性能指标,包括时间复杂度和空间复杂度,并探讨了算法的适用场景
JBoss搭建企业级应用实战:一步一步教你构建高性能环境

# 摘要
本文全面介绍了JBoss应用服务器的搭建、性能优化、企业级应用部署与管理以及高可用性集群配置。首先概述了JBoss服务器的功能特点,随后详细阐述了搭建环境的步骤,包括系统要求、兼容性分析、软件依赖安装以及安全设置。接着,文章重点探讨了JBoss服务器性能优化的方法,包括监控工具使用、性能数据处理和调优技巧。在应用部署与管理方面,
【结论提取的精确方法】:如何解读CCD与BBD实验结果
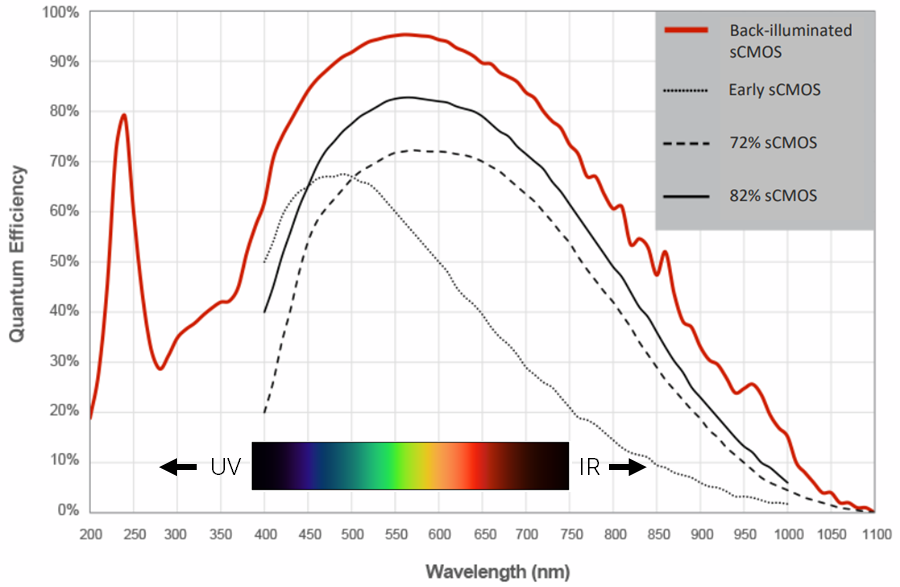
# 摘要
本文系统性地分析了CCD(电荷耦合器件)与BBD(声波延迟线)在不同实验条件下的结果,并对它们的实验结果进行了理论和实践分析。文章首先概述了CCD和BBD实验结果的解读方法和优化技巧,然后深入探讨了CCD与BBD技术的基础理论及各自实验结果的解读方法,包括图像传感器特性和信号处理原理。接着,文章综合对比了CCD与BBD在成像性能和应用领域的差异,并提出了一系列的交叉验证方法和综合评价
【分析工具选择指南】:在Patran PCL中挑选正确的分析类型

# 摘要
本文旨在探讨Patran PCL在工程分析中的应用和重要性,涵盖了基础知识、分析类型及其在实际中的运用。首先,介绍了Patran PCL的基础知识和主要分析类型,包括理论基础和分析类型的选择。接着,深入探讨了材料力学、结构力学和动力学分析在不同工程应用中的关键点,如静力学、模态、热力学和动力学分析等。此外,本文还提供了高级分
从零开始:掌握PLC电动机顺序启动设计的5个步骤

# 摘要
本文旨在介绍和分析基于PLC技术的电动机顺序启动设计的全过程,涵盖了理论基础、设计实践以及高级应用案例分析。首先,文章概述了电动机顺序启动的基本概念、启动原理以及PLC技术在电动机控制中的应用。随后,深入到设计实践,包括需求分析、硬件选择、控制逻辑设计、PLC程序编写与调试,以及系统测试与性能优化。最后,通过对工业应用案例的分析,探讨了
跨平台应用开发:QT调用DLL的兼容性问题及12个对策

# 摘要
跨平台应用开发已成为软件开发领域的常见需求,QT框架因其卓越的跨平台性能而广受欢迎。本文首先概述了跨平台应用开发和QT框架的基本概念,接着深入分析了QT框架中调用DLL的基本原理,包括DLL的工作机制和QT特定的调用方式。文章第三章探讨了在不同操作系统和硬件架构下QT调用DLL时遇到的兼容性问题,并在第四章提出了一系列针对性的解决对策,包括预处理、动态加载、适配层和抽象接口等技
【Oracle视图与物化视图揭秘】
# 摘要
Oracle数据库中的视图和物化视图是数据抽象的重要工具,它们不仅提高了数据的安全性和易用性,还优化了查询性能。本文首先对视图和物化视图的概念、原理、优势、限制以及在实践中的应用进行了详细介绍。深入分析了它们如何通过提供数据聚合和隐藏来提高数据仓库和OLAP操作的效率,同时阐述了视图和物化视图在安全性和权限管理方面的应用。本文还探讨了视图和物化视图在性能优化和故障排除中的关键作用,并对高级视图技术和物化视图的高级特性进行了探讨,最后展望了这些技术的未来趋势。本论文为数据库管理员、开发人员和架构师提供了全面的视图和物化视图应用指南。
# 关键字
Oracle视图;物化视图;数据安全性
【正确设置ANSYS中CAD模型材料属性】:材料映射与分析精度

# 摘要
本文详细探讨了在ANSYS中CAD模型导入的流程及其材料属性的定义和应用。首先,介绍了CAD模型导入的重要性和材料属性的基本概念及其在模型中的作用。接着,本文阐述了材料数据库的使用,以及如何精确映射CAD模型中的材料属性。随后,分析了材料属性设置对静态、动态分析以及热分析的影响,并提供了相关的案例分析。最后,探讨了
【GNU-ld-V2.30链接器调试手册】:深入链接过程的分析与技巧
# 摘要
GNU ld链接器在软件构建过程中扮演着关键角色,涉及将目标文件和库文件转换成可执行程序的多个阶段。本文首先介绍了链接器的基础理论,包括其与编译器的区别、链接过程的各阶段、符号解析与重定位的概念及其技术细节,以及链接脚本的编写与应用。随后,文章深入探讨了GNU ld链接器实践技巧,涵盖了链接选项解析、链接过程的调试和优化,以及特殊目标文件和库的处理。进阶应用章节专注于自定义链接器行为、跨平台链接挑战和架构优化。最后,通过实战案例分析,文章展示了GNU ld在复杂项目链接策略、内存管理,以及开源项目中的应用。本文旨在为软件开发人员提供一套全面的GNU ld链接器使用指南,帮助他们在开发
工业4.0与S7-1500 PLC:图形化编程的未来趋势与案例
# 摘要
随着工业4.0时代的到来,S7-1500 PLC作为核心工业自动化组件,其图形化编程方法备受关注。本文首先概述了工业4.0的兴起以及S7-1500 PLC的基本情况,然后深入探讨了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )