构建库文件:利用 CMake 构建和管理库文件
发布时间: 2024-04-10 09:05:29 阅读量: 43 订阅数: 40 
# 1. 利用 CMake 构建和管理库文件
## 第一章:理解库文件和 CMake 基础
在本章中,我们将介绍库文件的概念以及如何利用 CMake 来构建和管理库文件。
### 什么是库文件
- 库文件是预先编译好的代码模块,可被其他程序调用和使用。库文件有静态库和动态库两种形式,静态库在编译时被静态地链接到可执行文件中,动态库在运行时被动态地加载到内存中。
### CMake 简介
- CMake 是一个跨平台的项目构建工具,可以自动生成各种不同操作系统和编译器的构建脚本。通过 CMake,我们可以更方便地管理项目的构建过程,包括编译、链接、安装等。
### CMake 的基本概念与用法
- CMake 的基本概念包括项目、源文件、目标、生成器等。通过编写 CMakeLists.txt 文件来描述项目的构建规则和依赖关系,然后使用 cmake 命令生成对应的构建系统文件。
- CMake 提供了丰富的命令和变量,可以用来定义项目的各种属性、设置编译选项、管理依赖库等。
通过本章的内容,读者将对库文件和 CMake 的基础知识有一个全面的了解,为后续学习和实践打下基础。
# 2. 准备开发环境
在这一章中,我们将介绍如何准备开发环境,包括配置和安装 CMake,配置 IDE 与 CMake 的集成,以及设置工作目录和项目结构。
### 配置并安装 CMake
在这一部分,我们将介绍如何在不同操作系统上配置并安装 CMake。
- Windows 系统下,可以通过以下步骤安装 CMake:
1. 访问[CMake官方网站](https://cmake.org/download/)下载最新的 Windows 版本安装程序。
2. 打开安装程序,按照提示进行安装,选择添加 CMake 到系统路径。
3. 验证安装是否成功,在命令行输入 `cmake --version` 可以查看安装的版本信息。
- 对于 macOS 用户,可以使用 Homebrew 进行安装:
```bash
brew install cmake
```
### 配置 IDE 以便与 CMake 集成
在这部分中,我们将以 Visual Studio Code 为例介绍如何配置 IDE 与 CMake 集成。
- 打开 Visual Studio Code,安装 CMake Tools 插件。
- 设置 CMake 工具链路径,可以在 VS Code 设置中搜索 "cmake:toolchain" 进行配置。
- 添加 CMake 配置文件,例如 CMakeSettings.json,定义项目的构建选项和路径。
### 设置工作目录和项目结构
在本节中,我们将说明如何设置工作目录和项目结构,使项目组织清晰。
- 创建一个新的文件夹作为项目的根目录。
- 在根目录下创建子文件夹,如 `src` 存放源代码,`include` 存放头文件,`build` 存放构建中间文件等。
- 编写 CMakeLists.txt 文件,定义项目的构建规则和依赖关系。
下面是一个简单的项目结构示例:
```plaintext
project/
├── CMakeLists.txt
├── src/
│ └── main.cpp
├── include/
│ └── mylibrary.h
└── build/
```
通过这些步骤,我们可以成功配置开发环境,准备好开始构建和管理库文件项目。接下来,我们将详细介绍如何创建基本的库文件。
# 3. 创建基本的库文件
在本章中,我们将学习如何创建一个简单的 C/C++ 库文件项目,并通过编写 CMakeLists.txt 文件来管理这个库文件的构建和版本控制。
### 创建一个简单的 C/C++ 库文件项目
首先,我们需要创建一个简单的 C/C++ 库文件项目,例如一个包含加法函数的库文件。
```cpp
// adder.h
#ifndef ADDER_H
#define ADDER_H
int add(int a, int b);
#endif
```
```cpp
// adder.cpp
#include "adder.h"
int add(int a, int b) {
return a + b;
}
```
### 编写 CMakeLists.txt 文件
接下来,我们需要编写 CMakeLists.txt 文件来配置项目的构建规则和依赖。
```cmake
cmake_minimum_required(VERSION 3.10)
project(Adder)
add_library(adder STATIC
adder.cpp
)
target_include_directories(adder PUBLIC ${CMAKE_CURRENT_SOURCE_DIR})
```
### 设置库文件的版本控制
在 CMakeLists.txt 文件中,我们也可以设置库文件的版本控制信息,以便管理库文件的不同版本。
```cmake
set(ADD_LIBRA
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**CMake 专栏简介**
本专栏深入探讨 CMake,一种用于跨平台构建管理的强大工具。从初学者指南到高级特性,该专栏涵盖了 CMake 的方方面面。
文章涵盖了以下主题:
* CMake 的基本概念和作用
* 安装和配置 CMake
* 变量、条件语句、循环和模块化设计
* 函数和宏的使用
* 构建库文件和可执行程序
* 配置工具链和多目录管理
* 生成器表达式和外部库集成
* 定制构建规则和调试技巧
* 配置文件处理、版本控制和多平台适配
* CMake 的高级特性和性能优化技巧
通过阅读本专栏,您将掌握 CMake 的强大功能,并能够利用它有效地管理您的构建过程。无论您是新手还是经验丰富的开发者,本专栏都将帮助您提升 CMake 技能,并创建更强大、更可维护的项目。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据分片技术】:实现在线音乐系统数据库的负载均衡
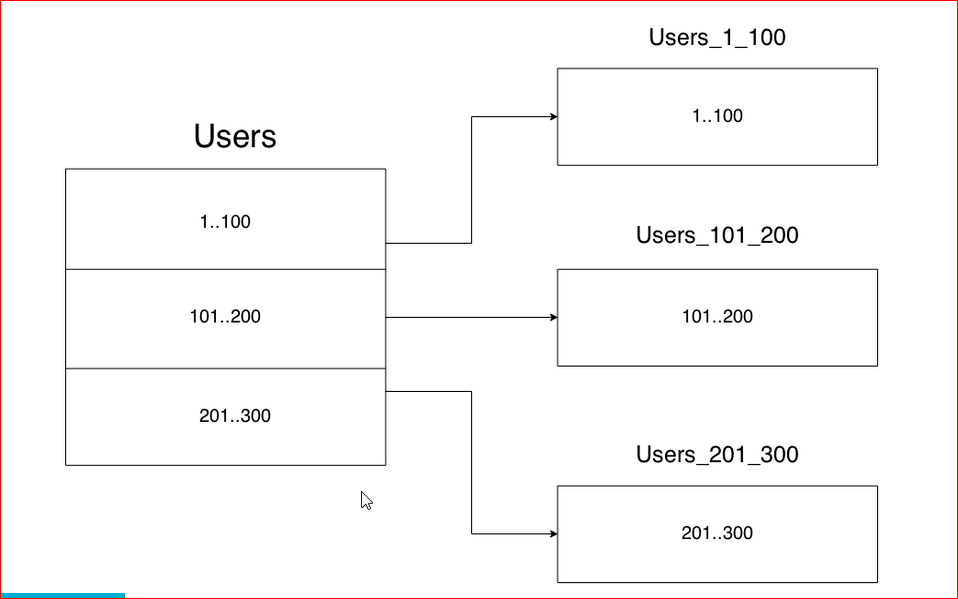
# 1. 数据分片技术概述
## 1.1 数据分片技术的作用
数据分片技术在现代IT架构中扮演着至关重要的角色。它将大型数据库或数据集切分为更小、更易于管理和访问的部分,这些部分被称为“分片”。分片可以优化性能,提高系统的可扩展性和稳定性,同时也是实现负载均衡和高可用性的关键手段。
## 1.2 数据分片的多样性与适用场景
数据分片的策略多种多样,常见的包括垂直分片和水平分片。垂直分片将数据
【数据集不平衡处理法】:解决YOLO抽烟数据集类别不均衡问题的有效方法

# 1. 数据集不平衡现象及其影响
在机器学习中,数据集的平衡性是影响模型性能的关键因素之一。不平衡数据集指的是在分类问题中,不同类别的样本数量差异显著,这会导致分类器对多数类的偏好,从而忽视少数类。
## 数据集不平衡的影响
不平衡现象会使得模型在评估指标上产生偏差,如准确率可能很高,但实际上模型并未有效识别少数类样本。这种偏差对许多应
微信小程序登录后端日志分析与监控:Python管理指南
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
【新文档标准】:Java开发者如何集成OpenAPI与Swagger
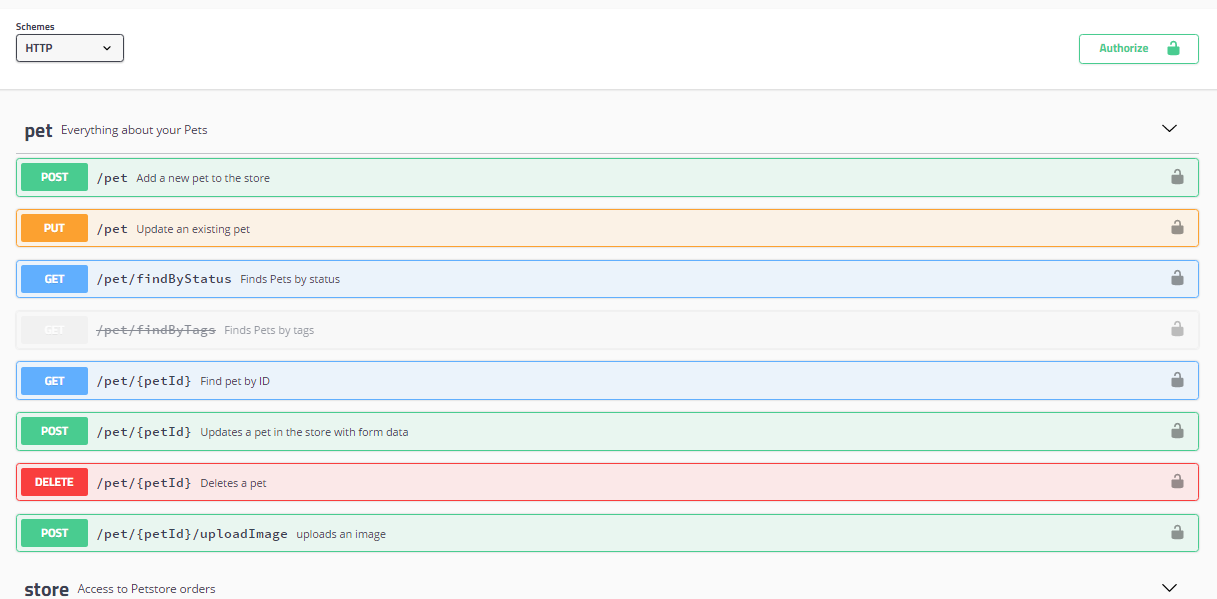
# 1. OpenAPI与Swagger概述
随着微服务架构和API经济的兴起,API的开发、测试和文档化变得日益重要。OpenAPI和Swagger作为业界领先的API规范和工具,为企业提供了一种标准化、自动化的方式来处理这些任务。
Swagger最初由Wordnik公司创建,旨在提供一个简单的方式,来描述、生产和消费RESTful Web服务。Swagger不仅定义了一种标准的API描述格式,还提供了一
Java中JsonPath与Jackson的混合使用技巧:无缝数据转换与处理

# 1. JSON数据处理概述
JSON(JavaScript Object Notation)数据格式因其轻量级、易于阅读和编写、跨平台特性等优点,成为了现代网络通信中数据交换的首选格式。作为开发者,理解和掌握JSON数
【集群技术详解】:构建大规模MySQL数据处理平台
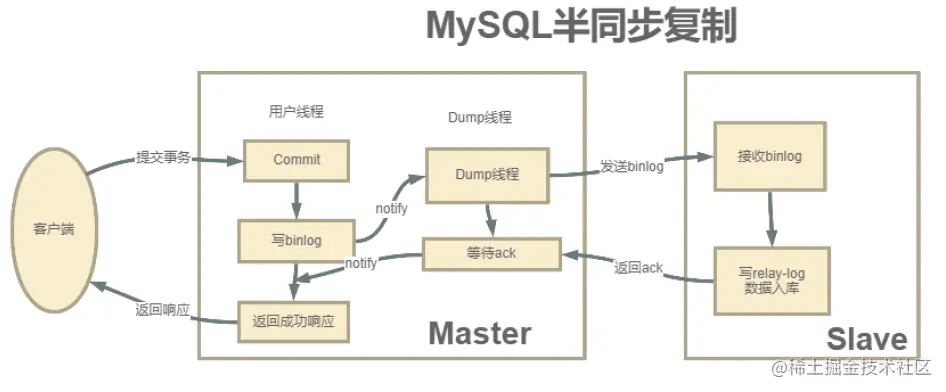
# 1. 集群技术概述与MySQL数据处理基础
## 1.1 集群技术简介
集群技术是构建高可用、高性能计算环境的关键技术之一。它通过将多个计算机联合起来,协同工作,从而提供比单一计算机更强的处理能力、更高的系统稳定性和更好的扩展性。集群的类型主要包括负载均衡集群、高
提高计算机系统稳定性:可靠性与容错的深度探讨
# 1. 计算机系统稳定性的基本概念
计算机系统稳定性是衡量一个系统能够持续无故障运行时间的指标,它直接关系到用户的体验和业务的连续性。在本章中,我们将介绍稳定性的一些基本概念,比如系统故障、可靠性和可用性。我们将定义这些术语并解释它们在系统设计中的重要性。
系统稳定性通常由几个关键指标来衡量,包括:
- **故障率(MTB
【数据库连接池管理】:高级指针技巧,优化数据库操作

# 1. 数据库连接池的概念与优势
数据库连接池是管理数据库连接复用的资源池,通过维护一定数量的数据库连接,以减少数据库连接的创建和销毁带来的性能开销。连接池的引入,不仅提高了数据库访问的效率,还降低了系统的资源消耗,尤其在高并发场景下,连接池的存在使得数据库能够更加稳定和高效地处理大量请求。对于IT行业专业人士来说,理解连接池的工作机制和优势,能够帮助他们设计出更加健壮的应用架构。
# 2. 数据库连
Rhapsody 7.0消息队列管理:确保消息传递的高可靠性

# 1. Rhapsody 7.0消息队列的基本概念
消息队列是应用程序之间异步通信的一种机制,它允许多个进程或系统通过预先定义的消息格式,将数据或者任务加入队列,供其他进程按顺序处理。Rhapsody 7.0作为一个企业级的消息队列解决方案,提供了可靠的消息传递、消息持久化和容错能力。开发者和系统管理员依赖于Rhapsody 7.0的消息队
【MySQL大数据集成:融入大数据生态】
# 1. MySQL在大数据生态系统中的地位
在当今的大数据生态系统中,**MySQL** 作为一个历史悠久且广泛使用的关系型数据库管理系统,扮演着不可或缺的角色。随着数据量的爆炸式增长,MySQL 的地位不仅在于其稳定性和可靠性,更在于其在大数据技术栈中扮演的桥梁作用。它作为数据存储的基石,对于数据的查询、分析和处理起到了至关重要的作用。
## 2.1 数据集成的概念和重要性
数据集成是
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )