【Python数据处理】:字符串转列表技巧的深度优化
发布时间: 2024-09-19 20:42:26 阅读量: 105 订阅数: 30 
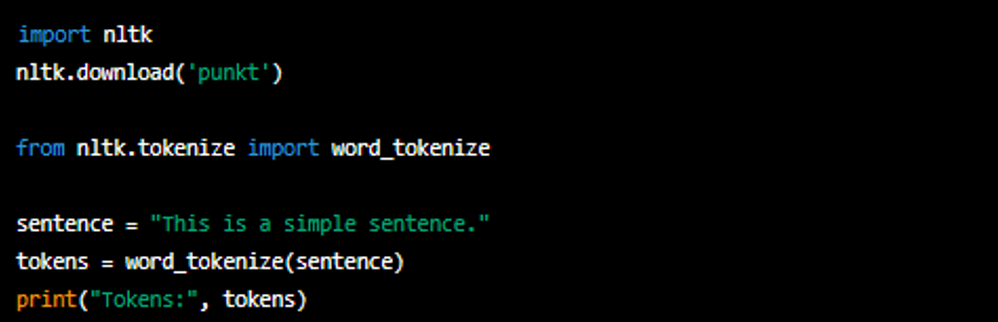
# 1. Python字符串与列表处理基础
在Python编程中,字符串和列表是两种最基本的数据结构,它们的处理能力直接影响到程序的效率和可读性。字符串可以看作是字符的序列,而列表则是包含多个元素的有序集合。尽管它们在概念上有所不同,但在很多情况下,我们需要在它们之间进行转换以满足不同的需求。例如,我们可能需要将输入的字符串数据分割成多个部分,或者需要将多个独立的字符串组合成一个列表。本章将介绍Python字符串与列表处理的基础知识,为后续章节的进阶操作和性能优化打下坚实的基础。
# 2. 字符串转列表的常规方法
字符串转列表是数据处理中的基础操作之一,它涉及到将单一的字符串分割成多个子字符串,这些子字符串随后被存储在列表结构中以便于后续的处理和分析。本章将介绍几种在Python中实现这一操作的常规方法,包括使用内置的`split()`方法、列表推导式以及正则表达式等。
### 2.1 使用split()方法进行转换
#### 2.1.1 split()方法的基本用法
Python中的字符串对象提供了一个非常方便的方法`split()`,它可以根据指定的分隔符将字符串分割成列表。`split()`方法的基本语法如下:
```python
str.split(sep=None, maxsplit=-1)
```
- `sep`是可选的分隔符,默认是任何空白字符。
- `maxsplit`定义了分割的最大次数,使用`-1`表示不限制。
例如,将一个以逗号分隔的字符串转换为列表:
```python
s = "apple,banana,cherry"
result = s.split(',')
print(result) # 输出: ['apple', 'banana', 'cherry']
```
`split()`方法适用于简单的分割任务,它快速且易于理解。但当涉及到更复杂的字符串时,它就显得有些力不从心。
#### 2.1.2 处理不同分隔符的情况
`split()`方法能够处理多种分隔符,只需在参数中指定一个包含所有分隔符的字符串。例如,以逗号或分号为分隔符的字符串:
```python
s = "apple,banana,cherry;orange"
result = s.split(',;')
print(result) # 输出: ['apple', 'banana', 'cherry', 'orange']
```
### 2.2 利用列表推导式进行转换
#### 2.2.1 列表推导式简介
列表推导式提供了一种简洁的方式来创建列表。对于字符串转列表的需求,列表推导式可以与字符串的`split()`方法结合使用,形成一种直观且易于理解的转换方式。列表推导式的一般形式如下:
```python
[expression for item in iterable if condition]
```
- `expression`是处理`item`后要放入列表的表达式。
- `iterable`是迭代的对象。
- `condition`是可选的,用于过滤元素。
例如,使用列表推导式对字符串进行分割:
```python
s = "apple,banana,cherry"
result = [item for item in s.split(',')]
print(result) # 输出: ['apple', 'banana', 'cherry']
```
列表推导式虽然灵活,但可能在处理非常大字符串时效率稍低,因为会先创建一个中间列表。
#### 2.2.2 列表推导式在字符串转列表中的应用
列表推导式在处理复杂条件和转换逻辑时特别有用。例如,当我们想要过滤掉某些特定的元素时:
```python
s = "apple,banana,cherry,banana"
result = [item for item in s.split(',') if item != "banana"]
print(result) # 输出: ['apple', 'cherry']
```
此外,列表推导式可以与字符串的其他方法结合使用,如`strip()`方法去除每个元素的空白字符:
```python
s = " apple , banana , cherry "
result = [item.strip() for item in s.split(',')]
print(result) # 输出: ['apple', 'banana', 'cherry']
```
列表推导式是一种强大的工具,但需要谨慎使用,因为其复杂性随条件的增加而增加,可能影响代码的可读性。
### 2.3 使用正则表达式进行高级转换
#### 2.3.1 正则表达式的基本概念
正则表达式是用于匹配字符串中字符组合的模式。在Python中,`re`模块提供了对正则表达式的支持。正则表达式具有强大的灵活性,能够识别各种复杂的字符串模式。基本语法如下:
```python
import re
# 编译一个正则表达式模式
pattern = ***pile('正则表达式')
# 使用编译后的模式进行匹配
match = pattern.search(string)
```
- `***pile()`编译正则表达式,提高后续匹配的效率。
- `pattern.search()`在字符串中搜索第一个匹配正则表达式的部分。
例如,使用正则表达式匹配单词边界:
```python
import re
s = "The rain in Spain"
pattern = ***pile(r'\b\w+\b')
matches = pattern.findall(s)
print(matches) # 输出: ['The', 'rain', 'in', 'Spain']
```
#### 2.3.2 正则表达式在字符串处理中的高级应用
正则表达式可以用来处理复杂和多样化的字符串分割需求。例如,使用正则表达式处理字符串中的多种分隔符:
```python
import re
s = "apple,banana,cherry;orange"
pattern = ***pile(r'[;,]')
result = pattern.split(s)
print(result) # 输出: ['apple', 'banana', 'cherry', 'orange']
```
正则表达式还可以用来匹配和捕获字符串中的特定信息,例如从字符串中提取电子邮件地址:
```python
import re
s = "Contact us at: ***"
pattern = ***pile(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b')
matches = pattern.findall(s)
print(matches) # 输出: ['***']
```
正则表达式提供了强大的文本处理能力,但是它们的语法相对复杂,对于初学者来说可能需要更多的时间去理解和学习。
本章节对字符串转列表的常规方法进行了详细探讨,覆盖了`split()`方法、列表推导式以及正则表达式的应用。接下来的章节,我们将探讨如何对这些方法进行性能优化,以及实际应用案例。
# 3. 字符串转列表的性能优化
在这一章节,我们将深入探讨字符串转换为列表的过程中常见的性能瓶颈,提供优化策略,并实现自定义的高效转换函数。性能优化是提高程序效率的重要环节,特别是在处理大量数据时,性能优化可以显著减少资源消耗和提高程序运行速度。
## 3.1 分析常见方法的性能瓶颈
### 3.1.1 时间复杂度和空间复杂度分析
在处理字符串到列表的转换时,不同的方法有着不同的时间和空间复杂度。例如,使用`split()`方法将字符串按照空格分割成列表,通常在时间复杂度上是线性的,即`O(n)`,其中`n`是字符串的长度。这是因为`split()`方法需要遍历整个字符串来查找分隔符。然而,在某些情况下,如果分割符特别稀少或者字符串非常长,这种方法可能会导致内存使用量增加。
### 3.1.2 真实环境下的性能测试
为了具体了解这些方法在真实环境下的性能表现,我们可以设计一些基准测试。这包括在不同的输入大小和不同的分隔符情况下,测量不同方法的执行时间和内存占用。通过基准测试,我们可以得到更准确的性能数据,用于指导我们进行优

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中字符串转换为列表的各种方法,涵盖了从基础技巧到高级优化。通过九种不同的方法,读者可以掌握字符串与列表之间的完美转换。专栏还提供了五种必备技巧,十种实用技巧和进阶技巧,以及字符串转列表的最佳实践、性能考量和 Pythonic 方式。此外,专栏还揭示了字符串与列表转换的内部机制,并提供了深度优化技巧、调试指南和常见错误解决方案。通过掌握这些技巧,读者可以提升 Python 编码效率、性能和优雅性,并深入理解 Python 数据处理的核心机制。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
贝叶斯统计入门:learnbayes包在R语言中的基础与实践

# 1. 贝叶斯统计的基本概念和原理
## 1.1 统计学的两大流派
统计学作为数据分析的核心方法之一,主要分为频率学派(Frequentist)和贝叶斯学派(Bayesian)。频率学派依赖于大量数据下的事件频率,而贝叶斯学派则侧重于使用概率来表达不确定性的程度。前者是基于假设检验和置信区间的经典方法,后者则是通过概率更新来进行推理。
## 1.2
【rgl数据包稀缺资源】:掌握不为人知的高级功能与技巧
# 1. rgl数据包的基本概念和作用
## 1.1 rgl数据包的简介
rgl数据包,即Remote Graphics Library数据包,是用于远程图形和数据传输的一种技术。它是通过网络将图形数据封装
【R语言shinydashboard机器学习集成】:预测分析与数据探索的终极指南
# 1. R语言shinydashboard简介与安装
## 1.1 R语言Shinydashboard简介
Shinydashboard是R语言的一个强大的包,用于构建交互式的Web应用。它简化了复杂数据的可视化过程,允许用户通过拖放和点击来探索数据。Shinydashboard的核心优势在于它能够将R的分析能力与Web应用的互动性结合在一起,使得数据分析结果能够以一种直观、动态的方式呈现给终端用户。
## 1.2 安
【R语言数据包的错误处理】:编写健壮代码,R语言数据包运行时错误应对策略

# 1. R语言数据包的基本概念与环境搭建
## 1.1 R语言数据包简介
R语言是一种广泛应用于统计分析和图形表示的编程语言,其数据包是包含了数据集、函数和其他代码的软件包,用于扩展R的基本功能。理解数据包的基本概念,能够帮助我们更高效地进行数据分析和处理
【knitr包测试与验证】:如何编写测试用例,保证R包的稳定性与可靠性

# 1. knitr包与R语言测试基础
在数据科学和统计分析的世界中,R语言凭借其强大的数据处理和可视化能力,占据了不可替代的地位。knitr包作为R语言生态系统中一款重要的文档生成工具,它允许用户将R代码与LaTeX、Markdown等格式无缝结合,从而快速生成包含代码执行结果的报告。然而,随着R语言项目的复杂性增加,确保代码质量的任务也随之变得尤为重要。在本章中,我们将探讨knitr包的基础知识,并引入R语
R语言空间数据分析:sf和raster包的地理空间分析宝典
# 1. R语言空间数据分析基础
## 简介
R语言作为数据分析领域广受欢迎的编程语言,提供了丰富的空间数据处理和分析包。在空间数据分析领域,R语言提供了一套强大的工具集,使得地理信息系统(GIS)的复杂分析变得简洁高效。本章节将概述空间数据分析在R语言中的应用,并为读者提供后续章节学习所需的基础知识。
## 空间数据的
【R语言数据包使用】:shinythemes包的深度使用与定制技巧

# 1. shinythemes包概述
`shinythemes` 包是R语言Shiny Web应用框架的一个扩展,提供了一组预设计的HTML/CSS主题,旨在使用户能够轻松地改变他们Shiny应用的外观。这一章节将简单介绍`shinythemes`包的基本概念和背景。
在数据科
【R语言多变量分析】:三维散点图在变量关系探索中的应用

# 1. R语言多变量分析基础
在数据分析领域,多变量分析扮演着至关重要的角色。它不仅涉及到数据的整理和分析,还包含了从数据中发现深层次关系和模式的能力。R语言作为一种广泛用于统计分析和图形表示的编程语言,其在多变量分析领域中展现出了强大的功能和灵活性。
## 1.1 多变量数据分析的重要性
多变量数据分析能够帮助研究者们同时对多个相关变量进行分析,以理解它们之间的关系。这种分析方法在自然科学、
【R语言shiny数据管道优化法】:高效数据流管理的核心策略
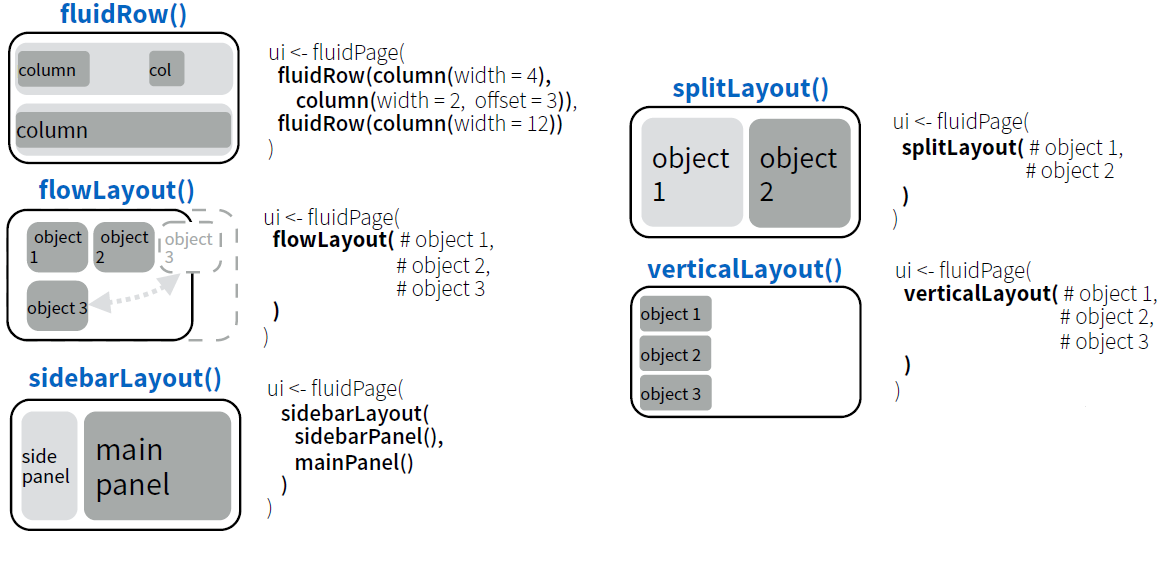
# 1. R语言Shiny应用与数据管道简介
## 1.1 R语言与Shiny的结合
R语言以其强大的统计分析能力而在数据科学领域广受欢迎。Shiny,作为一种基于R语言的Web应用框架,使得数据分析师和数据科学家能够通过简单的代码,快速构建交互式的Web应用。Shiny应用的两大核心是UI界面和服务器端脚本,UI负责用户界面设计,而服务器端脚本则处
R语言3D图形创新指南
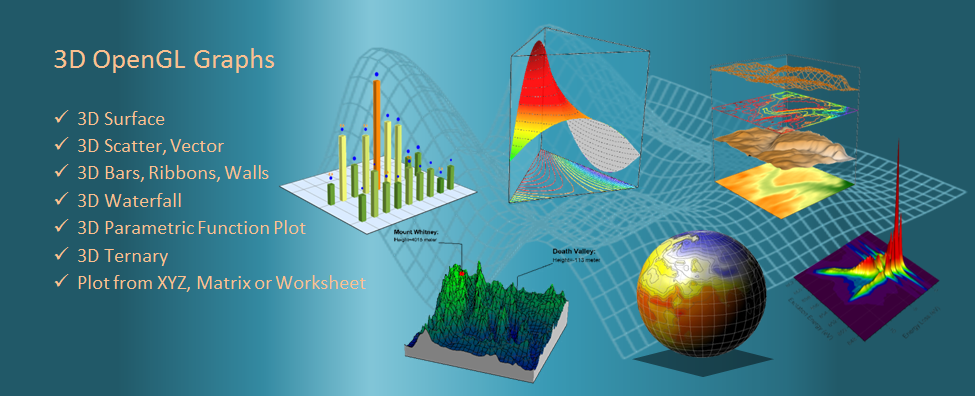
# 1. R语言与3D图形基础
## 1.1 R语言在数据可视化中的角色
R语言作为数据分析和统计计算的领域内备受欢迎的编程语言,其强大的图形系统为数据可视化提供了无与伦比的灵活性和深度。其中,3D图形不仅可以直观展示多维度数据,还可以增强报告和演示的视觉冲击力。R语言的3D图形功能为研究人员、分析师和数据科学家提供了一种直观展示复杂数据关系的手段。
## 1.2 基础知识概述
在进入3D图形
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )