Python代码库维护
发布时间: 2024-09-20 02:34:38 阅读量: 53 订阅数: 29 

让代码变得更易维护的7个Python库

# 1. Python代码库维护概述
维护一个高质量的Python代码库是一项复杂且重要的任务,它不仅仅是为了保持代码的可读性和可维护性,也关乎于项目的长期成功和可持续性发展。本章将概述Python代码库维护的核心概念,包括代码库结构组织的基本原则,以及如何确保代码质量,同时提供文档和用户支持,最后关注性能优化和安全性。
在随后的章节中,我们将深入探讨如何选择并应用适合的项目结构,如何有效地使用版本控制系统和依赖管理工具。同时,我们还将了解如何建立和维护代码质量、编写详尽的文档,并处理社区反馈,以及如何优化性能和增强代码库的安全性。通过这些章节,我们将为读者提供一个全面的Python代码库维护实践框架。
# 2. 代码库结构和组织
## 2.1 选择合适的项目结构
在构建代码库时,选择一个合适的项目结构对于代码的可维护性、可扩展性和可理解性至关重要。项目结构不仅影响开发者的工作效率,也影响其他参与者,如文档编写者、测试工程师,甚至最终用户的体验。
### 2.1.1 标准库结构
Python的标准库遵循一种特定的结构模式,为广泛的应用提供了可预测的文件组织和命名约定。通常,这种结构包括以下几个主要部分:
- `bin/`:包含可执行脚本。
- `lib/`:包含Python模块和包。
- `tests/`:包含测试代码。
- `docs/`:存放文档,如Sphinx生成的文档。
- `setup.py`:用于安装和分发项目的脚本。
以Python标准库的`datetime`模块为例,其源代码结构如下:
```
datetime/
├── __init__.py
├── __main__.py
├── arithmetic.py
├── date.py
├── datetime.py
├── folds.py
├── timezone.py
├── tzinfo.py
└── utils.py
```
这个结构清晰地表明了每个Python文件所扮演的角色,便于维护和扩展。
### 2.1.2 第三方库兼容性
在设计代码库结构时,必须考虑到与第三方库的兼容性。例如,我们可能需要确保我们的代码能够使用如`requests`、`numpy`等流行的第三方库。
为实现这一点,通常需要创建一个`requirements.txt`文件,列出了项目依赖的所有库及其版本:
```plaintext
requests==2.25.1
numpy==1.19.5
```
依赖管理工具如`pip`将会根据`requirements.txt`安装对应的库版本,保证项目的依赖环境一致。
## 2.2 版本控制系统的选择与应用
版本控制系统是代码库维护的关键部分,它记录代码的所有变更历史,便于团队协作和代码回溯。
### 2.2.1 Git版本控制基础
Git是最流行的版本控制系统之一。它使用一个分布式的模型,这意味着每个开发者都有一个包含完整项目历史的本地仓库副本。
以下是基本的Git工作流程:
1. **初始化仓库**:使用`git init`创建一个新仓库。
2. **提交更改**:使用`git add`添加更改,然后用`git commit`提交这些更改到本地仓库。
3. **分支管理**:使用`git branch`创建和管理分支。
4. **合并更改**:使用`git merge`将分支更改合并到主分支。
5. **远程协作**:使用`git push`和`git pull`与远程仓库同步更改。
例如,创建一个新的分支并切换到该分支的命令为:
```bash
git checkout -b feature-branch
```
### 2.2.2 分支策略与合并流程
分支策略定义了如何组织和管理分支,以及如何在分支之间合并更改。
一个常见的分支策略是Git Flow,它定义了主分支(master),开发分支(develop)和特性分支(feature)。开发新功能时,在特性分支上进行,开发完成后,将特性分支合并到开发分支,最后将开发分支的更改合并到主分支。
合并流程涉及多个步骤,确保代码的整合性和稳定性:
```mermaid
flowchart LR
A[开始] --> B[特性分支开发]
B --> C[推送特性分支到远程仓库]
C --> D{是否需要合并到开发分支?}
D -- 是 --> E[拉取最新的开发分支更改]
E --> F[解决可能的合并冲突]
F --> G[推送特性分支到远程仓库]
D -- 否 --> H[等待下一次合并]
G --> I[在远程仓库创建合并请求]
I --> J[代码审查和测试]
J --> K{合并请求是否批准?}
K -- 是 --> L[将特性分支合并到开发分支]
L --> M[推送更改到远程仓库]
M --> N[关闭合并请求]
K -- 否 --> O[修复问题并重新提交]
O --> I
N --> P[结束]
H --> P
```
## 2.3 依赖管理和打包工具
随着项目的发展,管理项目依赖变得至关重要。`pip`和`setuptools`是Python项目管理依赖和打包的重要工具。
### 2.3.1 pip和虚拟环境
`pip`是Python的包安装程序,用于安装和管理Python包。使用`pip`可以轻松安装、更新和移除Python包。
为了确保不同项目的依赖不会相互干扰,建议使用虚拟环境。`virtualenv`是一个创建隔离的Python环境的工具,可以针对每个项目创建独立的依赖环境。
创建虚拟环境的命令如下:
```bash
virtualenv myenv
source myenv/bin/activate
```
### 2.3.2 setuptools和wheel
`setuptools`是Python的另一个打包工具,它扩展了`distutils`,提供了更多的功能,如安装脚本、包数据处理等。
`wheel`是Python的另一种打包格式,它可以加速安装过程,因为它预先构建了分发包的一部分,安装时无需重新编译。
使用`setuptools`创建一个`setup.py`文件,配置项目的依赖、包的入口点等信息:
```python
from setuptools import setup, find_packages
setup(
name='myproject',
version='1.0',
packages=find_packages(),
install_requires=[
'requests',
'numpy'
]
)
```
打包项目时,可以使用`wheel`和`setuptools`:
```bash
python setup.py bdist_wheel
```
这将创建一个`.whl`文件,可以使用`pip install`直接安装。
以上章节介绍了项目结构、版本控制和依赖管理的基本概念和工具。随着项目的增长,这些工具和概念将为代码库的稳定性和可维护性奠定基础。在下一章节中,我们将探讨如何确保代码的质量,包括编码标准、自动化测试和持续集成。
# 3. 代码质量保证
## 3.1 编码标准和规范
### 3.1.1 PEP 8编码规范
PEP 8是Python Enhancement Proposal #8的缩写,它是Python代码编写的标准风格指南。遵循PEP 8规范可以帮助编写易于阅读和维护的代码,同时保持代码风格的一致性。规范内容包括但不限于命名约定、空格的使用、注释和文档字符串、表达式和语句的限制等。
遵循PEP 8的一个关键原则是代码的可读性。例如,在行长度方面,建议每个独立的语句不超过79个字符,而对于长的导入语句则推荐使用圆括号。此外,变量名、函数名应该使用小写字母和下划线组合(snake_case),而类名使用驼峰命名法(CapWords),缩写词在类名中大写等。
为了方便地检查代码是否符合PEP 8规范,可以使用`flake8`工具进行自动化检查。`flake8`是一个流行的Python包,它可以对代码进行风格检查,并标记不符合规范的部分。
```python
# 示例代码
def calculate_area(radius):
area = 3.14 * rad
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python 字符串替换终极指南》专栏深入探讨了 Python 中字符串替换的方方面面。它涵盖了 Python replace 方法的全面解析、文本处理技巧、性能优化秘诀、数据清洗实战、陷阱大揭秘、算法原理、安全编码技巧、Pandas 数据预处理、脚本调试技巧、性能测试、代码库维护、可读性提升、国际化和本地化处理以及代码优化实践。该专栏旨在为 Python 开发人员提供全面的指南,帮助他们掌握字符串替换的复杂性,提高代码效率和可靠性。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
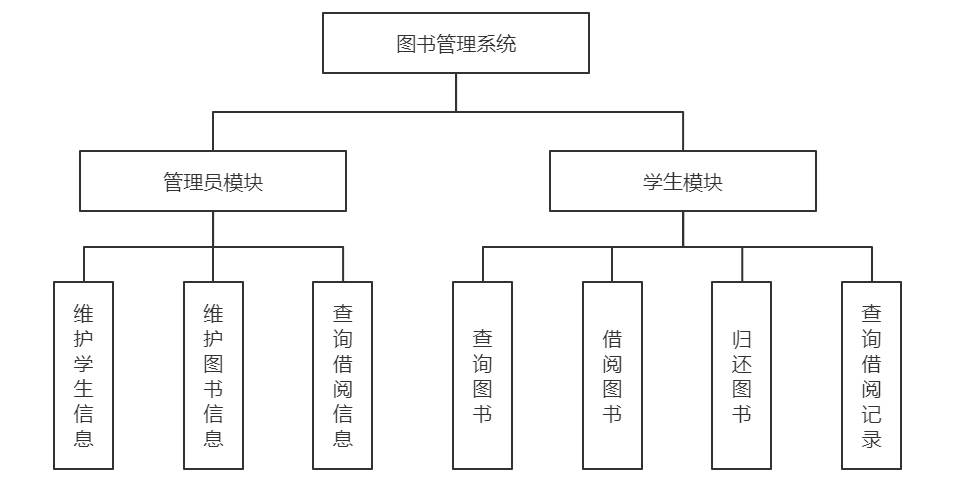
【图书馆管理系统的UML奥秘】:全面解码用例、活动、类和时序图(5图表精要)
# 摘要
本文探讨了统一建模语言(UML)在图书馆管理系统设计中的重要性,以及其在分析和设计阶段的核心作用。通过构建用例图、活动图和类图,本文揭示了UML如何帮助开发者准确捕捉系统需求、设计交互流程和定义系统结构。文中分析了用例图在识别主要参与者和用例中的应用,活动图在描述图书检索、借阅和归还流程中的作用,以及类图在定义图书类、读者类和管理员类之间的关系。
NVIDIA ORIN NX开发指南:嵌入式开发者的终极路线图

# 摘要
本文详细介绍了NVIDIA ORIN NX平台的基础开发设置、编程基础和高级应用主题。首先概述了该平台的核心功能,并提供了基础开发设置的详细指南,包括系统要求、开发工具链安装以及系统引导和启动流程。在编程基础方面,文章探讨了NVIDIA GPU架构、CUDA编程模型以及并行计算框架,并针对系统性能调优提供了实用
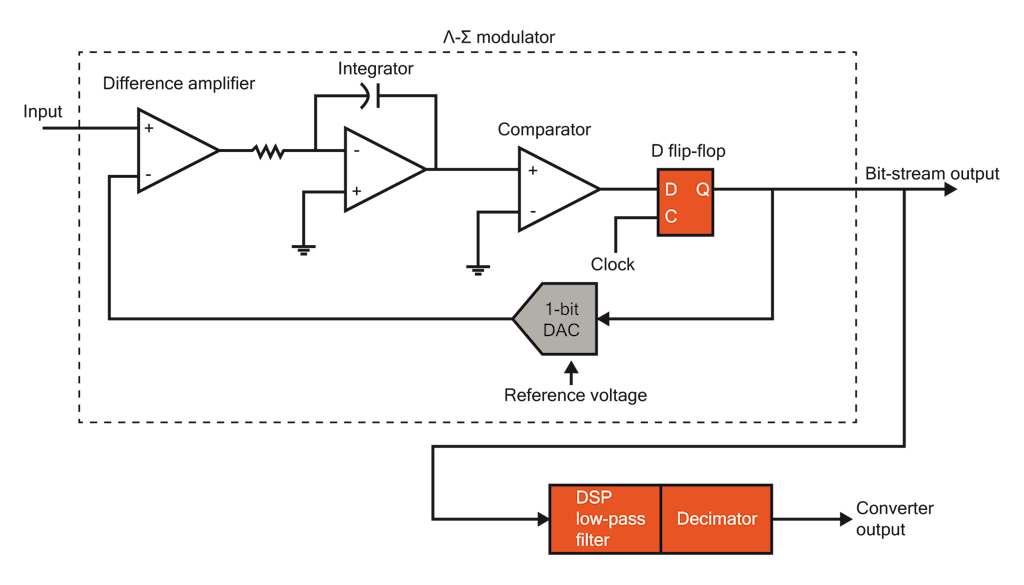
【Sigma-Delta ADC性能优化】:反馈与前馈滤波器设计的精髓
# 摘要
Sigma-Delta模数转换器(ADC)因其高分辨率和高信噪比(SNR)而广泛应用于数据采集和信号处理系统中。本文首先概述了Sigma-Delta ADC性能优化的重要性及其基本原理,随后重点分析了反馈和前馈滤波器的设计与优化,这两者在提高转换器性能方面发挥着关键作用。文中详细探讨了滤波器设计的理论基础、结构设计和性能优化策略,并对Sigma-Delta
【实战演练】:富士伺服驱动器报警代码全面解析与应对手册
# 摘要
本文详细介绍了富士伺服驱动器及其报警代码的基础知识、诊断流程和应对策略。首先概述了伺服驱动器的结构和功能,接着深入探讨了报警代码的分类、定义、产生原因以及解读方法。在诊断流程章节中,提出了有效的初步诊断步骤和深入分析方法,包括使用富士伺服软件和控制程序的技巧。文章还针对硬件故障、软件配置错误提出具体的处理方法,并讨论了维护与预防措施的重要性。最后,通过案例分析和实战演练,展示了报警分析与故障排除的实际应用,并总结了相关经验与
【单片微机系统设计蓝图】:从原理到实践的接口技术应用策略
# 摘要
单片微机系统作为一种集成度高、功能全面的微处理器系统,广泛应用于自动化控制、数据采集、嵌入式开发和物联网等多个领域。本文从单片微机系统的基本原理、核心理论到接口设计和实践应用进行了全面的介绍,并探讨了在现代化技术和工业需求推动下该系统的创新发展方向。通过分析单片微机的工作原理、指令集、接口技术以及控制系统和数据采集系统的设计原理,本文为相关领域工程师和研究人员提供了理论支持和
【Java内存管理秘籍】:掌握垃圾回收和性能优化的艺术
# 摘要
本文全面探讨了Java内存管理的核心概念、机制与优化技术。首先介绍了Java内存管理的基础知识,然后深入解析了垃圾回收机制的原理、不同垃圾回收器的特性及选择方法,并探讨了如何通过分析垃圾回收日志来优化性能。接下来,文中对内存泄漏的识别、监控工具的使用以及性能调优的案例进行了详细的阐述。此外,文章还探讨了内存模型、并发编程中的内存管理、JVM内存参数调优及高级诊断工具的应用。最
信号处理进阶:FFT在音频分析中的实战案例研究

# 摘要
本文综述了信号处理领域中的快速傅里叶变换(FFT)技术及其在音频信号分析中的应用。首先介绍了信号处理与FFT的基础知识,深入探讨了FFT的理论基础和实现方法,包括编程实现与性能优化。随后,分析了音频信号的特性、采样与量化,并着重阐述了FFT在音频频谱分析、去噪与增强等方面的应用。进一步,本文探讨了音频信号的进阶分析技术,如时间-频率分析和高
FCSB1224W000升级秘籍:无缝迁移至最新版本的必备攻略

# 摘要
本文综述了FCSB1224W000升级的全过程,涵盖从理论分析到实践执行,再到案例分析和未来展望。首先,文章介绍了升级前必须进行的准备工作,包括系统评估、理论路径选择和升级后的系统验证。其次,详细阐述了实际升级过程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )