【Python缓存机制】: Weakref模块在内存管理中的5种用途
发布时间: 2024-10-04 09:18:45 阅读量: 25 订阅数: 30 

# 1. Python缓存机制概述
缓存是一种常见的数据管理策略,它利用计算机内存快速访问的特性,存储临时数据以减少对持久存储的访问次数和延迟。在Python中,缓存机制尤为重要,因为它可以在多线程和多进程环境中提高数据处理的效率。Python的缓存主要依赖于引用计数和垃圾回收机制。引用计数是Python判断对象生命周期的基本手段,当对象的引用数量为零时,该对象将被垃圾回收器回收。然而,在复杂的应用场景中,如循环引用会导致内存泄漏,这时候就需要弱引用技术来解决。
缓存策略的实现方式多种多样,根据应用场景的不同,可以采用基于时间的LRU(最近最少使用)缓存、基于大小的缓存或者简单的全局缓存等。合理选择和设计缓存策略,可以显著提升程序的性能。Python中的Weakref模块为弱引用提供了支持,使得开发者可以在不影响对象生命周期的同时引用对象。接下来,我们将深入了解Weakref模块的基础知识和高级应用。
# 2. Weakref模块基础
## 2.1 Weakref模块简介
### 2.1.1 Weakref模块的作用与特点
在Python中,弱引用(weak references)是一个特殊的引用类型,它们不会增加对象的引用计数。这意味着,弱引用不会阻止对象被垃圾回收器回收,这在某些应用场景下非常有用,尤其是在需要长时间生存的对象和需要避免内存泄漏的场景中。
使用弱引用的好处在于,它们提供了一种方式来引用对象,而不会增加对象的生命周期。这在实现缓存时尤其有用,因为一旦缓存的项目不再被强引用,它们就可以被自动清理。
Weakref模块支持两种类型的弱引用:`ref` 对象用于创建弱引用,以及`proxy` 对象,它提供了一个活动对象的代理,该代理在对象还活着时行为像一个普通引用,在对象被回收时变为无效。
### 2.1.2 Weakref与其他引用类型的区别
在Python中,我们通常遇到的引用类型有两种:强引用和弱引用。强引用会增加对象的引用计数,从而增加对象的生命期。而在弱引用的情况下,引用对象不会增加对象的引用计数。
让我们以一个简单的例子来说明这一点:
```python
import weakref
class A:
pass
# 创建对象和强引用
a = A()
strong_ref = a
# 创建弱引用
weak_ref = weakref.ref(a)
# 输出引用计数
import sys
print(sys.getrefcount(strong_ref)) # 输出 3,因为传递给 getrefcount 增加了 1
print(sys.getrefcount(weak_ref)) # 输出 2,同样的原因
```
在上面的代码中,`sys.getrefcount` 返回的是传递的参数在函数内部的引用计数,因此实际对象的引用计数还要减去1。
强引用使得对象保持活跃状态,即使在不再需要它时。而弱引用可以在对象的生命周期结束时自动消失,这使得它可以用于避免内存泄漏,管理缓存大小,或为不可变对象建立缓存。
## 2.2 Weakref的基本使用方法
### 2.2.1 创建弱引用
创建弱引用非常简单,我们可以使用 Weakref 模块中的 `ref` 函数来创建弱引用。
```python
import weakref
class MyClass:
def __del__(self):
print("Deleting")
obj = MyClass()
# 创建弱引用
weak = weakref.ref(obj)
print(weak) # 输出类似 <weakref at 0x地址; to 'MyClass' at 0x地址>
print(weak()) # 通过调用弱引用获取对象
del obj # 删除强引用
print(weak()) # 尝试通过弱引用来访问对象
# 输出 Deleting
# 再次尝试访问将抛出异常,因为对象已被删除
```
上面的例子展示了创建和使用弱引用的基本方法。一旦弱引用的原始对象被删除,通过弱引用来访问它将返回 `None` 或抛出异常。
### 2.2.2 弱引用与强引用的区别
弱引用与强引用最显著的区别在于它们对对象生命周期的影响。强引用保持对象活着,而弱引用不会。这使得弱引用特别适合缓存场景。
考虑以下情况:
```python
import weakref
class MyClass:
def __init__(self, value):
self.value = value
cache = {}
def get_obj(value):
# 创建强引用
strong_ref = MyClass(value)
# 将强引用存入缓存
cache[value] = strong_ref
# 创建弱引用
weak_ref = weakref.ref(strong_ref)
# 删除强引用
del strong_ref
return weak_ref
obj_ref = get_obj(10)
obj = obj_ref()
if obj is not None:
print(f"Object with value {obj.value} is still alive.")
else:
print("The object was garbage collected.")
```
在这个例子中,对象 `MyClass` 被 `get_obj` 函数创建并存储在缓存中。随后,我们创建了一个弱引用 `obj_ref`,然后删除了对象的强引用。尽管对象被删除,由于缓存仍然有一个强引用,对象并不会被垃圾回收器回收。如果我们删除缓存中的强引用,那么对象将会被垃圾回收,通过弱引用访问它将返回 `None`。
### 2.2.3 清理循环引用
循环引用是指两个或更多对象相互引用,从而阻止它们的引用计数归零,即使它们被其他部分的程序逻辑所丢弃。在Python中,循环引用会导致内存泄漏,因为这些对象不会被垃圾回收。
Python的垃圾回收器会在检测到对象没有活动引用时自动清理它们,但是循环引用的存在会阻止这一过程。弱引用可以用来打破循环引用。
让我们看一个循环引用的例子:
```python
import weakref
class Node:
def __init__(self, value):
self.value = value
self.next = None
def set_next(self, next_node):
self.next = weakref.ref(next_node)
node1 = Node(1)
node2 = Node(2)
node1.set_next(node2)
node2.set_next(node1)
del node1
del node2
# 强制执行垃圾回收
import gc
gc.collect()
# 通过 Weakref 查看对象是否被垃圾回收
print(node1.next()) # None,node2已被回收
print(node2.next()) # None,node1已被回收
```
在这个例子中,我们创建了一个简单的节点链表,节点之间通过弱引引来互相引用。这样,即使两个节点互相引用,它们也可以被垃圾回收。需要注意的是,当尝试通过弱引用访问时,如果目标节点已被回收,那么弱引用会返回 `None`。
# 3. Weakref在内存管理中的应用
## 3.1 使用Weakref进行缓存
### 3.1.1 缓存对象的创建与管理
在处理大量数据或执行复杂计算时,缓存是一种常见的优化手段。然而,传统的缓存方法可能导致内存泄漏,因为缓存项(即原始对象)无法被垃圾回收机制回收。这时,使用`weakref`模块可以创建一种特殊的缓存,这种缓存允许对象在没有其他强引用指向它们时被垃圾回收。
使用`weakref`模块创建缓存对象的基本思路是,将缓存键映射到一个弱引用上,而不是直接映射到对象本身。这样,当对象没有其他强引用存在时,它就可以被垃圾回收器回收。
```python
import weakref
class MyCache:
def __init__(self):
self._cache = weakref.WeakValueDictionary()
def get(self, key):
# 获取缓存项,如果该键对应的对象已被回收,则返回None
return self._cache.get(key)
def put(self, key, value):
# 将对象添加到缓存中,使用弱引用存储
self._cache[key] = value
# 使用缓存
cache = MyCache()
cache.put('some_key', expensive_computation())
print(cache.get('some_key')) # 缓存中存在则返回对象,否则返回None
```
在上述代码中,`WeakValueDictionary`是由`weakref`模块提供的一个字典类型,它可以存储对对象的弱引用。当对象的强引用数量降为零时,这些弱引用将自动从字典中消失。
### 3.1.2 缓存策略与效率分析
在设计缓存策略时,需要考虑多个因素,包括内存使用、性能以及对象的生命周期。`weakref`提供了灵活性来实现这些策略,允许对象在适当的时候被回收。
为了分析缓存的效率,通常需要进行基准测试和性能分析。可以使用Python的`timeit`模块来测试获取缓存项和添加到缓存中的操作的执行时间。这可以帮助我们理解在不同操作规模下缓存的表现。
```python
import timeit
# 测试缓存获取速度
time_to_get = timeit.timeit('cache.get("some_key")', globals=globals(), number=1000)
# 测试添加到缓存的速度
time_to_put = timeit.timeit('cache.put("another_key", another_value)', globals=globals(), number=1000)
print(f"Time to get from cache: {time_to_get} seconds")
print(f"Time to put into cache: {time_to_put} seconds")
```
## 3.2 Weakref在集合中的应用
### 3.2.1 WeakKeyDicti

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
TSPL2高级打印技巧揭秘:个性化格式与样式定制指南

# 摘要
TSPL2打印语言作为工业打印领域的重要技术标准,具备强大的编程能力和灵活的控制指令,广泛应用于各类打印设备。本文首先对TSPL2打印语言进行概述,详细介绍其基本语法结构、变量与数据类型、控制语句等基础知识。接着,探讨了TSPL2在高级打印技巧方面的应用,包括个性化打印格式设置、样
JFFS2文件系统设计思想:源代码背后的故事
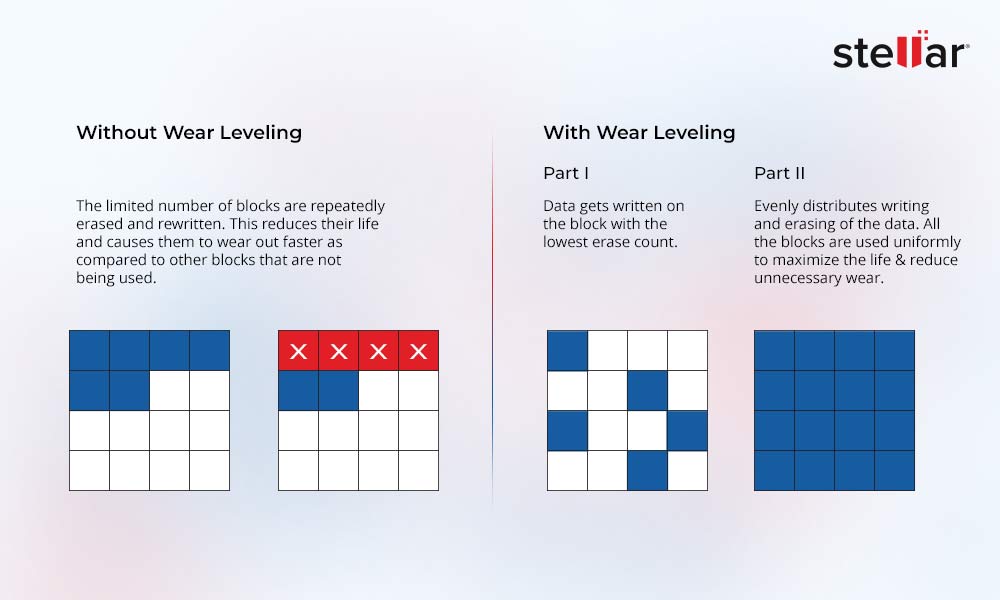
# 摘要
本文对JFFS2文件系统进行了全面的概述和深入的分析。首先介绍了JFFS2文件系统的基本理论,包括文件系统的基础概念和设计理念,以及其核心机制,如红黑树的应用和垃圾回收机制。接着,文章深入剖析了JFFS2的源代码,解释了其结构和挂载过程,以及读写操作的实现原理。此外,针对JFFS2的性能优化进行了探讨,分析了性能瓶颈并提出了优化策略。在此基础上,本文还研究了J
EVCC协议版本兼容性挑战:Gridwiz更新维护攻略

# 摘要
本文对EVCC协议进行了全面的概述,并探讨了其版本间的兼容性问题,这对于电动车充电器与电网之间的有效通信至关重要。文章分析了Gridwiz软件在解决EVCC兼容性问题中的关键作用,并从理论和实践两个角度深入探讨了Gridwiz的更新维护策略。本研究通过具体案例分析了不同EVCC版本下Gridwiz的应用,并提出了高级维护与升级技巧。本文旨在为相关领域的工程师和开发者提供有关EVCC协议及其兼容性维护
计算机组成原理课后答案解析:张功萱版本深入理解

# 摘要
计算机组成原理是理解计算机系统运作的基础。本文首先概述了计算机组成原理的基本概念,接着深入探讨了中央处理器(CPU)的工作原理,包括其基本结构和功能、指令执行过程以及性能指标。然后,本文转向存储系统的工作机制,涵盖了主存与缓存的结构、存储器的扩展与管理,以及高速缓存的优化策略。随后,文章讨论了输入输出系统与总线的技术,阐述了I/O系统的
CMOS传输门故障排查:专家教你识别与快速解决故障
# 摘要
CMOS传输门故障是集成电路设计中的关键问题,影响电子设备的可靠性和性能。本文首先概述了CMOS传输门故障的普遍现象和基本理论,然后详细介绍了故障诊断技术和解决方法,包括硬件更换和软件校正等策略。通过对故障表现、成因和诊断流程的分析,本文旨在提供一套完整的故障排除工具和预防措施。最后,文章展望了CMOS传输门技术的未来挑战和发展方向,特别是在新技术趋势下如何面对小型化、集成化挑战,以及智能故障诊断系统和自愈合技术的发展潜力。
# 关键字
CMOS传输门;故障诊断;故障解决;信号跟踪;预防措施;小型化集成化
参考资源链接:[cmos传输门工作原理及作用_真值表](https://w
KEPServerEX秘籍全集:掌握服务器配置与高级设置(最新版2018特性深度解析)
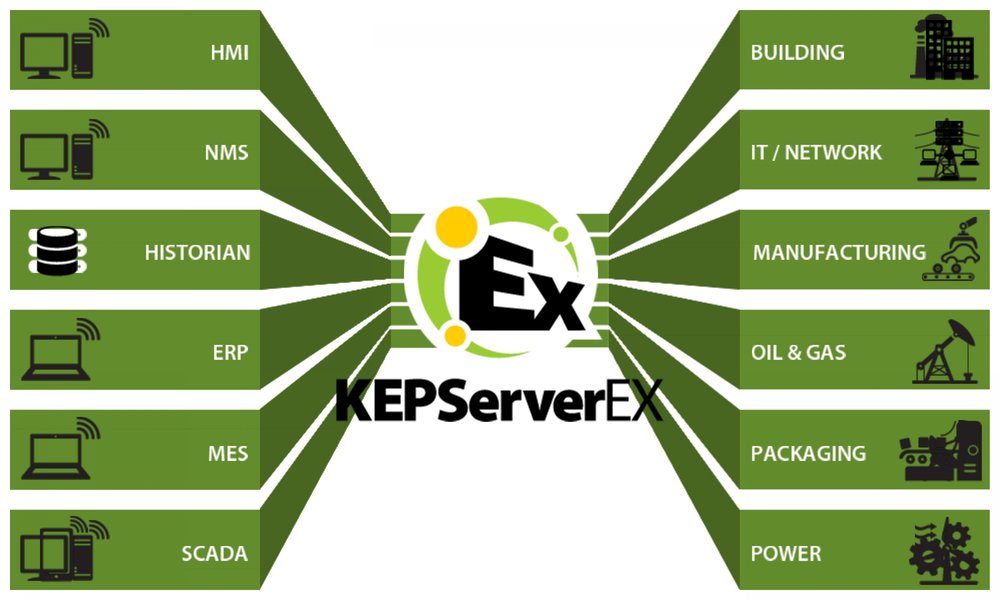
# 摘要
KEPServerEX作为一种广泛使用的工业通信服务器软件,为不同工业设备和应用程序之间的数据交换提供了强大的支持。本文从基础概述入手,详细介绍了KEPServerEX的安装流程和核心特性,包括实时数据采集与同步,以及对通讯协议和设备驱动的支持。接着,文章深入探讨了服务器的基本配置,安全性和性能优化的高级设
【域控制新手起步】:一步步掌握组策略的基本操作与应用
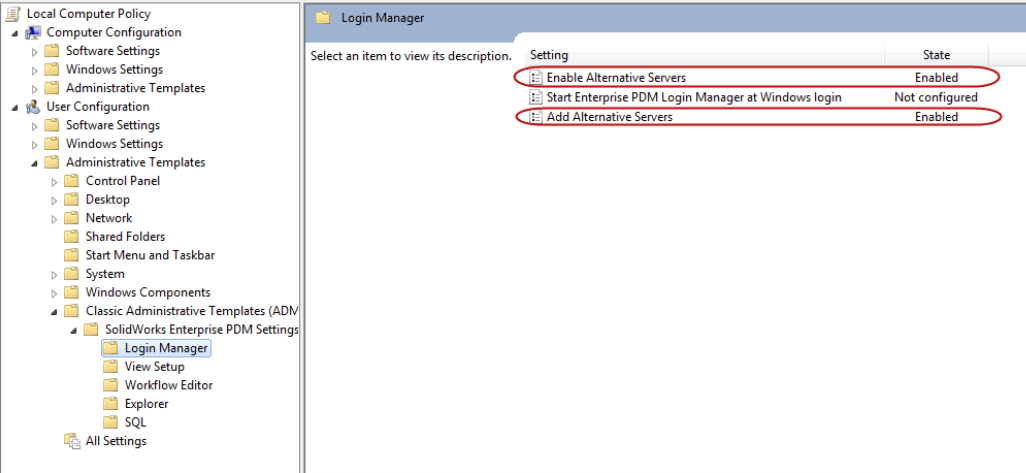
# 摘要
组策略是域控制器中用于配置和管理网络环境的重要工具。本文首先概述了组策略的基本概念和组成部分,并详细解释了其作用域与优先级规则,以及存储与刷新机制。接着,文章介绍了组策略的基本操作,包括通过管理控制台GPEDIT.MSC的使用、组策略对象(GPO)的管理,以及部署和管理技巧。在实践应用方面,本文探讨了用户环境管理、安全策略配置以及系统配置与优化。此
【SolidWorks自动化工具】:提升重复任务效率的最佳实践

# 摘要
本文全面探讨了SolidWorks自动化工具的开发和应用。首先介绍了自动化工具的基本概念和SolidWorks API的基础知识,然后深入讲解了编写基础自动化脚本的技巧,包括模型操作、文件处理和视图管理等。接着,本文阐述了自动化工具的高级应用
Android USB音频设备通信:实现音频流的无缝传输
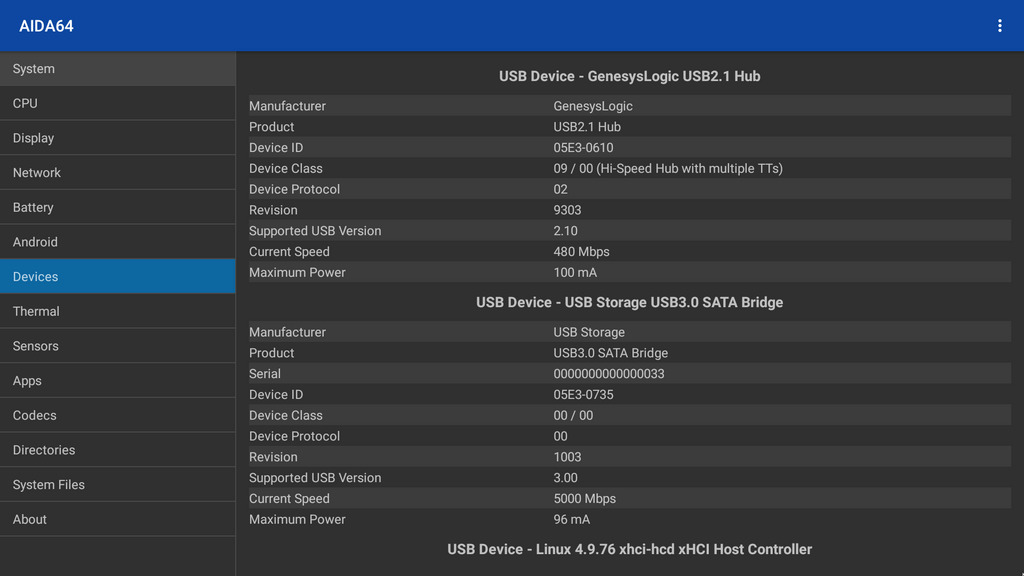
# 摘要
随着移动设备的普及,Android平台上的USB音频设备通信已成为重要话题。本文从基础理论入手,探讨了USB音频设备工作原理及音频通信协议标准,深入分析了Android平台音频架构和数据传输流程。随后,实践操作章节指导读者了解如何设置开发环境,编写与测试USB音频通信程序。文章深入讨论了优化音频同步与延迟,加密传输音频数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )