Prometheus数据存储与备份策略最佳实践
发布时间: 2023-12-30 02:48:27 阅读量: 105 订阅数: 46 
# 1. Prometheus数据存储概述
## 1.1 Prometheus数据存储基本原理
Prometheus是一种开源的监控系统,使用时间序列数据来记录监测指标。在Prometheus中,数据存储是其核心组件之一。本节将介绍Prometheus数据存储的基本原理,包括数据的组织方式、数据的存储结构以及相关的数据存储策略。
## 1.2 Prometheus数据存储架构分析
Prometheus数据存储的架构是由多个组件构成的,包括存储引擎、索引、存储层和查询层等。每个组件都扮演着不同的角色,并通过协作来完成数据存储和查询的功能。本节将对Prometheus数据存储的架构进行详细的分析,并介绍各个组件的作用和相互关系。
## 1.3 存储指标与数据模型
在Prometheus中,指标是指要监测和记录的数据。每个指标都有一个唯一的名称和一组标签,用于区分不同的时间序列数据。数据模型定义了指标的结构和存储方式。本节将介绍Prometheus的指标和数据模型,包括指标的命名规则、标签的使用方法以及时间序列数据的存储方式。
以上是第一章的章节内容。如果需要详细的代码示例或其他章节内容,请告诉我具体需求。
# 2. Prometheus数据备份策略
### 2.1 数据备份的重要性
数据备份是任何系统中都至关重要的一项任务。在Prometheus中,数据备份的重要性不言而喻。通过对数据进行备份,可以在意外故障、数据丢失或其他灾难性事件发生时,能够方便快速地恢复数据,确保数据的完整性和可用性。
### 2.2 Prometheus数据备份方法介绍
在Prometheus中,有多种方法可以进行数据备份。这里介绍两种常用的备份方法:手动备份和自动备份。
#### 2.2.1 手动备份
手动备份是最简单的数据备份方法之一。通过手动备份,可以自主选择备份的时间点和目标位置。具体操作步骤如下:
1. 停止Prometheus服务,确保数据不在变动状态。
2. 复制Prometheus数据目录(默认情况下是`/data`)到备份位置,可以使用`cp`命令或其他文件复制方式。
3. 启动Prometheus服务,确保数据恢复正常。
#### 2.2.2 自动备份
自动备份是一种更加方便和可靠的备份方法。通过配置自动备份,可以定期自动执行数据备份任务,减少人工干预和避免忘记备份的风险。以下是一个使用Cron定时任务进行自动备份的示例:
```shell
# 编辑定时任务
crontab -e
# 添加以下内容
0 0 * * * cp -R /data /backup_data
# 保存退出
```
以上示例会在每天午夜(0点)执行备份操作,将`/data`目录下的数据复制到`/backup_data`目录中。
### 2.3 自动备份与定时备份配置
在Prometheus中,可以通过配置`prometheus.yml`文件来实现自动备份和定时备份。
以下是一个示例的`prometheus.yml`配置文件,实现每天午夜自动备份数据:
```yaml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
rule_files:
- /path/to/alert.rules
remote_write:
- url: http://remote-storage.example.com/write
write_relabel_configs:
- source_labels: ['__name__']
regex: 'up'
action: drop
remote_read:
- url: http://remote-storage.example.com/read
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# 自动备份配置
external_labels:
backup_directory: '/backup_data'
backup_interval: '0 0 * * *'
```
在上述示例中,配置了`external_labels`字段来指定备份目录和备份时

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《Prometheus》是一个综合性的监控系统学习指南,涵盖了从入门到深入的各个方面知识。通过本专栏的文章,读者可以学习使用Prometheus监控系统,并掌握如何与Grafana打造强大的可视化监控平台。专栏还详细介绍了Prometheus的数据模型及其在监控中的应用,以及深入理解PromQL语言的查询语言。此外,专栏还包括了Prometheus的告警规则及实践技巧,使用Prometheus Operator实现Kubernetes集群监控,以及与Golang和Docker的整合,构建高性能的监控数据采集程序和容器化监控环境。专栏还讨论了Prometheus与传统监控系统的对比及应用场景,数据存储与备份策略的最佳实践,性能优化和调优技巧,以及与Tracing、微服务架构、时序数据处理、JVM应用程序、云原生环境、Elasticsearch、大数据领域、网络监控和安全监控的实践。无论是初学者还是有一定经验的技术人员,都能从本专栏中获得实用的知识和技巧,提升自己在监控领域的能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
市场营销的未来:随机森林助力客户细分与需求精准预测

# 1. 市场营销的演变与未来趋势
市场营销作为推动产品和服务销售的关键驱动力,其演变历程与技术进步紧密相连。从早期的单向传播,到互联网时代的双向互动,再到如今的个性化和智能化营销,市场营销的每一次革新都伴随着工具、平台和算法的进化。
## 1.1 市场营销的历史沿
细粒度图像分类挑战:CNN的最新研究动态与实践案例

# 1. 细粒度图像分类的概念与重要性
随着深度学习技术的快速发展,细粒度图像分类在计算机视觉领域扮演着越来越重要的角色。细粒度图像分类,是指对具有细微差异的图像进行准确分类的技术。这类问题在现实世界中无处不在,比如对不同种类的鸟、植物、车辆等进行识别。这种技术的应用不仅提升了图像处理的精度,也为生物多样性
自然语言处理新视界:逻辑回归在文本分类中的应用实战

# 1. 逻辑回归与文本分类基础
## 1.1 逻辑回归简介
逻辑回归是一种广泛应用于分类问题的统计模型,它在二分类问题中表现尤为突出。尽管名为回归,但逻辑回归实际上是一种分类算法,尤其适合处理涉及概率预测的场景。
## 1.2 文本分类的挑战
文本分类涉及将文本数据分配到一个或多个类别中。这个过程通常包括预处理步骤,如分词、去除停用词,以及特征提取,如使用词袋模型或TF-IDF方法
支持向量机在语音识别中的应用:挑战与机遇并存的研究前沿

# 1. 支持向量机(SVM)基础
支持向量机(SVM)是一种广泛用于分类和回归分析的监督学习算法,尤其在解决非线性问题上表现出色。SVM通过寻找最优超平面将不同类别的数据有效分开,其核心在于最大化不同类别之间的间隔(即“间隔最大化”)。这种策略不仅减少了模型的泛化误差,还提高了模型对未知数据的预测能力。SVM的另一个重要概念是核函数,通过核函数可以将低维空间线性不可分的数据映射到高维空间,使得原本难以处理的问题变得易于
梯度下降在线性回归中的应用:优化算法详解与实践指南

# 1. 线性回归基础概念和数学原理
## 1.1 线性回归的定义和应用场景
线性回归是统计学中研究变量之间关系的常用方法。它假设两个或多个变
RNN可视化工具:揭秘内部工作机制的全新视角

# 1. RNN可视化工具简介
在本章中,我们将初步探索循环神经网络(RNN)可视化工具的核心概念以及它们在机器学习领域中的重要性。可视化工具通过将复杂的数据和算法流程转化为直观的图表或动画,使得研究者和开发者能够更容易理解模型内部的工作机制,从而对模型进行调整、优化以及故障排除。
## 1.1 RNN可视化的目的和重要性
可视化作为数据科学中的一种强
K-近邻算法多标签分类:专家解析难点与解决策略!

# 1. K-近邻算法概述
K-近邻算法(K-Nearest Neighbors, KNN)是一种基本的分类与回归方法。本章将介绍KNN算法的基本概念、工作原理以及它在机器学习领域中的应用。
## 1.1 算法原理
KNN算法的核心思想非常简单。在分类问题中,它根据最近的K个邻居的数据类别来进行判断,即“多数投票原则”。在回归问题中,则通过计算K个邻居的平均
决策树在金融风险评估中的高效应用:机器学习的未来趋势
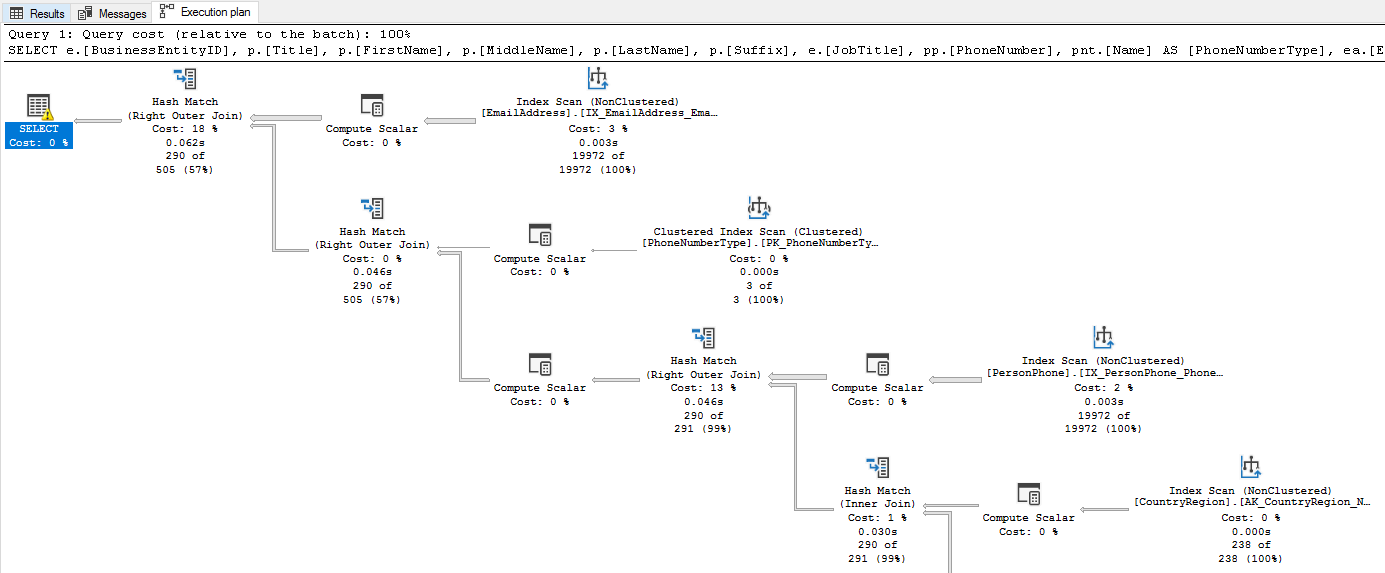
# 1. 决策树算法概述与金融风险评估
## 决策树算法概述
决策树是一种被广泛应用于分类和回归任务的预测模型。它通过一系列规则对数据进行分割,以达到最终的预测目标。算法结构上类似流程图,从根节点开始,通过每个内部节点的测试,分支到不
LSTM股票市场预测实录:从成功与失败中学习
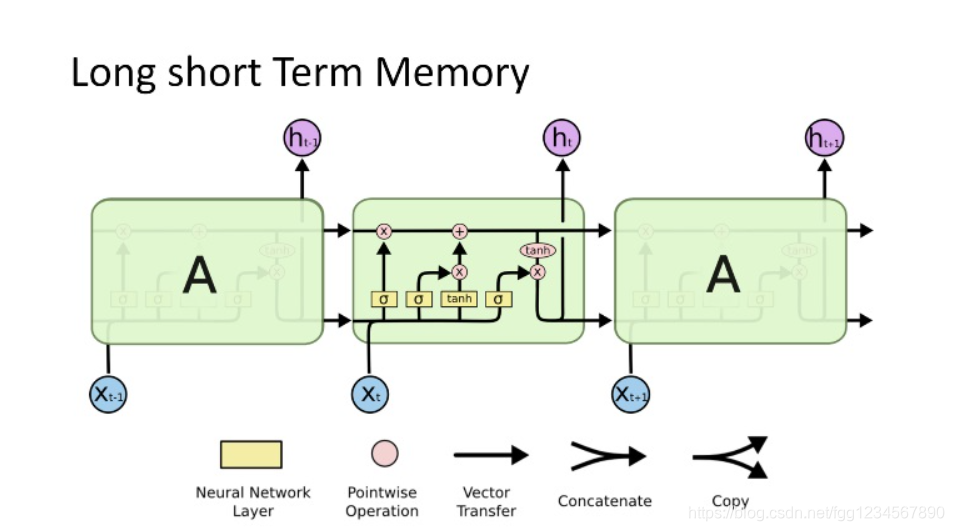
# 1. LSTM神经网络概述与股票市场预测
在当今的金融投资领域,股票市场的波动一直是投资者关注的焦点。股票价格预测作为一项复杂的任务,涉及大量的变量和
神经网络硬件加速秘技:GPU与TPU的最佳实践与优化

# 1. 神经网络硬件加速概述
## 1.1 硬件加速背景
随着深度学习技术的快速发展,神经网络模型变得越来越复杂,计算需求显著增长。传统的通用CPU已经难以满足大规模神经网络的计算需求,这促使了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )