【Jupyter Notebook搭配】:Anaconda的使用心得与最佳实践
发布时间: 2024-12-10 05:07:06 阅读量: 3 订阅数: 14 
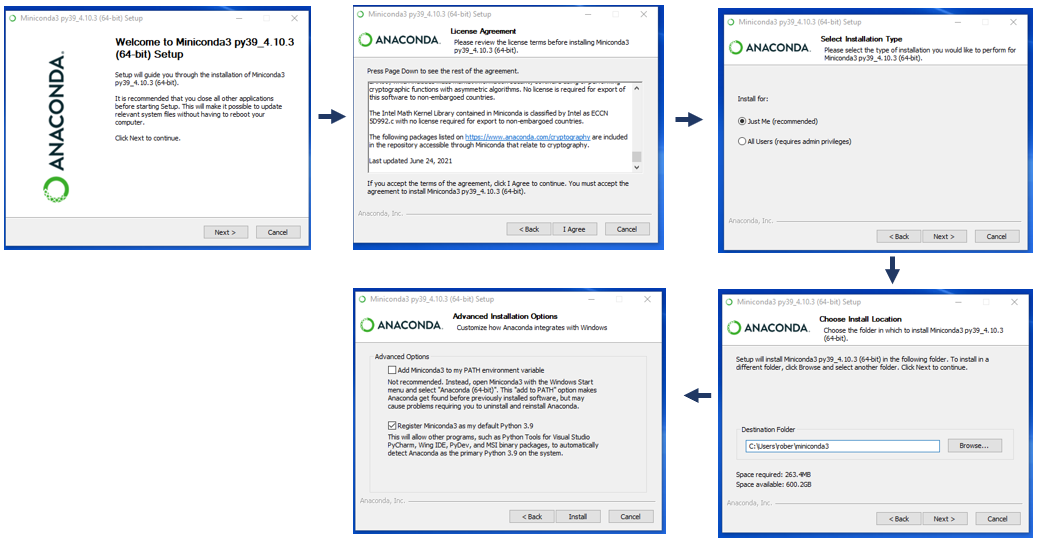
# 1. Anaconda概述与安装
Anaconda是一个流行的Python和R语言的科学计算平台,它包含了大量的科学包和环境管理工具,为数据科学、机器学习和AI等领域的开发提供了一个便利的环境。Anaconda的核心优势在于包管理和环境隔离,它通过conda这一包管理工具,让我们能够轻松安装和更新包,同时conda环境允许我们在隔离的状态下安装不同版本的包,避免了版本冲突的问题。
## 1.1 Anaconda简介与特点
Anaconda的一个显著特点是易于使用和维护。它预装了众多数据科学和机器学习常用的库,如NumPy、SciPy、Pandas、Scikit-learn、Matplotlib等,用户可以直接开始数据分析和建模工作,无需花大量时间配置环境。此外,Anaconda提供了一套集成开发环境Anaconda Navigator,使得非技术用户也可以方便地管理和运行应用程序,大大降低了Python科学计算的门槛。
## 1.2 安装Anaconda与配置环境
在安装Anaconda之前,首先需要下载适合您操作系统(Windows、macOS、Linux)的安装包。安装过程简单,只需遵循安装向导的指示即可。安装完成后,可以在命令行中输入`conda`或`jupyter`来检查是否正确安装。接下来配置环境时,可以使用conda来创建一个新的环境,然后激活它,例如:
```bash
conda create -n myenv python=3.8
conda activate myenv
```
这段代码创建了一个名为`myenv`的新环境,并指定了Python版本为3.8。
## 1.3 Anaconda Navigator的使用
Anaconda Navigator是Anaconda的图形界面工具,提供了一个直观的方式来管理和使用conda环境及安装的包。在Navigator中,用户可以轻松地搜索包,管理已安装的包,以及启动Jupyter Notebook、JupyterLab等应用程序。通过点击相应的图标即可启动应用,对于熟悉传统桌面应用程序的用户来说非常友好。
通过本章内容,我们将建立一个基础的Anaconda环境,为接下来在Jupyter Notebook中的数据科学项目实战打下坚实的基础。
# 2. Jupyter Notebook环境配置
### 2.1 Jupyter Notebook启动与界面介绍
Jupyter Notebook 是一个开源的 Web 应用程序,允许用户创建和共享包含实时代码、方程、可视化和解释文本的文档。它支持超过 40 种编程语言,特别是对 Python 的支持非常友好。
#### 启动 Jupyter Notebook
安装完成后,启动 Jupyter Notebook 的步骤十分简便。在命令行界面中输入以下命令即可启动 Jupyter Notebook:
```bash
jupyter notebook
```
执行后,您的默认网页浏览器应该会自动打开 Jupyter Notebook 的主界面。
#### 用户界面解析
Jupyter Notebook 的主界面大致可以分为以下几个部分:
1. **文件浏览区域**:这里列出了当前工作目录下的所有文件和文件夹,可以进行新建笔记本、上传文件、创建文件夹等操作。
2. **运行状态指示**:顶部的蓝色条显示了当前 Kernel 的运行状态和是否正在运行其他任务。
3. **菜单栏**:提供了文件、编辑、视图、插入、细胞、小部件、帮助等菜单项,每个菜单项下有多个子项可以进行各种操作。
4. **工具栏**:位于菜单栏下方,提供了一些快捷操作,例如保存笔记本、剪切、复制、粘贴、运行单元格等。
5. **单元格**:这是笔记本的主要部分,单元格是代码、文本和公式等输入的地方,用户通过执行单元格来得到输出。
### 2.2 Kernel管理与环境变量配置
#### Kernel 管理
Kernel 是 Jupyter Notebook 的核心组件,它负责执行用户的代码。一个 Kernel 与一种编程语言绑定,Jupyter Notebook 支持多种语言的 Kernel。
在 Jupyter Notebook 中管理 Kernel 包括启动、停止和重启 Kernel,以及查看已安装的 Kernel 列表。可以使用以下命令来管理 Kernel:
```bash
# 列出所有已安装的 Kernel
jupyter kernelspec list
# 删除一个指定的 Kernel
jupyter kernelspec remove <kernel_name>
```
#### 环境变量配置
有时为了确保 Notebook 中的代码能正确执行,可能需要对环境变量进行配置。这可以通过配置文件或命令行参数实现。在启动 Jupyter Notebook 之前,可以设置环境变量:
```bash
# 使用命令行设置环境变量
export MY_ENV_VAR=foo
jupyter notebook
# 在 Notebook 中设置环境变量
import os
os.environ['MY_ENV_VAR'] = 'foo'
```
环境变量的配置会影响到 Notebook 中所有运行的代码,因此在使用时需要特别注意。
### 2.3 插件扩展与自定义设置
#### 插件扩展
Jupyter Notebook 提供了一个丰富的插件生态系统,通过插件可以扩展和增强 Notebook 的功能。要安装插件,可以使用 Jupyter 的扩展命令:
```bash
# 安装一个 Jupyter 插件
jupyter labextension install @jupyterhub/jupyterlab-hub-extension
```
安装后,需要重启 JupyterLab 才能让插件生效。
#### 自定义设置
Jupyter Notebook 允许用户通过修改配置文件来自定义其行为。可以在用户的主目录下找到 Jupyter 的配置文件夹,该文件夹通常包含默认的配置文件。也可以通过下面的命令创建一个配置文件,并在其中添加自定义设置:
```bash
jupyter notebook --generate-config
```
然后编辑生成的配置文件,例如设置密码保护或者改变工作目录等:
```python
c.NotebookApp.password = 'sha1:xxxx'
c.NotebookApp.notebook_dir = '/path/to/your/directory'
```
上述介绍为 Jupyter Notebook 环境配置的基础知识。通过学习 Kernel 管理、环境变量配置和插件扩展,可以让您的数据科学工作流程更加顺畅高效。在下一章节中,我们将深入探讨数据科学项目中的实战技巧。
# 3. 数据科学项目实战技巧
在数据科学项目中,实战技巧的掌握程度往往决定了项目的成败。数据探索、模型训练、数据预处理和可视化等关键步骤需要熟练的运用各种工具和技术来完成。本章节将介绍数据科学项目中的关键实战技巧,帮助读者提升项目实施效率和模型质量。
## 3.1 数据探索与可视化工具使用
### 3.1.1 Pandas库的高效使用
Pandas库是数据科学中不可或缺的工具,它提供了高性能、易于使用的数据结构和数据分析工具。要想在数据科学项目中游刃有余,对Pandas的高效使用是基础中的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到专栏“Anaconda的在线课程与学习平台”,在这里,您将找到一系列全面的文章,旨在帮助您掌握Anaconda的各个方面。从环境配置和包管理的高级技巧,到数据处理和分析的进阶技术,再到个性化学习路径和自动化部署,本专栏涵盖了Anaconda的方方面面。此外,您还将了解虚拟环境的高级管理技巧、Python数据分析环境的构建、云服务和资源管理、高性能计算中的Anaconda应用,以及Anaconda学习资源的总汇。通过深入浅出的讲解和实用的教程,本专栏将助您充分利用Anaconda,提升您的数据科学和机器学习技能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘音频数据的神秘面纱:Sonic Visualiser深度应用与高级技巧
参考资源链接:[Sonic Visualiser新手指南:详尽功能解析与实用技巧](https://wenku.csdn.net/doc/r1addgbr7h?spm=1055.2635.3001.10343)
# 1. 音频数据解析与Sonic Visualiser简介
音频数据解析是数字信号处理领域的一个重要分支,涉
ST-Link V2 原理图解读:从入门到精通的6大技巧
参考资源链接:[STLink V2原理图详解:构建STM32调试下载器](https://wenku.csdn.net/doc/646c5fd5d12cbe7ec3e52906?spm=1055.2635.3001.10343)
# 1. ST-Link V2简介与基础应用
ST-Link V2是一种广泛使用的调试器/编
Cognex VisionPro 标定流程优化攻略:8个秘诀帮你提升效率与准确性
参考资源链接:[Cognex VisionPro视觉标定流程详解:从九点标定到旋转中心计算](https://wenku.csdn.net/doc/6401abe0cce7214c316e9d24?spm=1055.2635.3001.10343)
# 1. Cognex VisionPro 标定流程概述
在现代工业自动化和计算机视觉领域中,准确的标定是至关重要的,它确保了系统可以正确理
【IEC62055-41数据交换全解】:智能电表通信的STS单程通信分析

参考资源链接:[IEC62055-41标准传输规范(STS).单程令牌载波系统的应用层协议.doc](https://wenku.csdn.net/doc/6401ad0ecce7214c316ee1f8?spm=1055.2635.3001.10343)
# 1. IEC62055-41标准概述
## 1.1 IEC62055-41标准
【WPF摄像头应用性能优化】:MediaKit实践中的8个关键提升点
参考资源链接:[WPF使用MediaKit调用摄像头](https://wenku.csdn.net/doc/647d456b543f84448829bbfc?spm=1055.2635.3001.10343)
# 1. WPF摄像头应用性能优化概述
在当今数字时代,视频捕获和处理是许多软件应用的核心部分,尤其是对于WPF(Windows Presentation Foun
逼真3D效果的秘密:Geomagic Studio高级渲染技术
参考资源链接:[GeomagicStudio全方位操作教程:逆向工程与建模宝典](https://wenku.csdn.net/doc/6z60butf22?spm=1055.2635.3001.10343)
# 1. Geomagic Studio渲染技术概述
Geomagic Studio是一款被广泛使用的3D扫描和建模软件,其强大的渲
深度学习革新:NVIDIA Ampere架构的AI训练优化攻略

参考资源链接:[NVIDIA Ampere架构白皮书:A100 Tensor Core GPU详解与优势](https://wenku.csdn
用友U8备份策略灵活性:如何制定可扩展的备份计划
参考资源链接:[用友U8自动备份失效解决方案全攻略](https://wenku.csdn.net/doc/2h5qv6x3e0?spm=1055.2635.3001.10343)
# 1. 用友U8备份策略概述
在当今信息化时代,企业数据的完整性和安全性已经成为企业竞争力的重要组成部分。用友U8作为一款广泛应用于企业资源规划(ERP)的软件,其数据备份工作显得尤为重要。本章将从整体上对用友U
提升燃料电池仿真精度:ANSYS Fluent参数调整与案例分析
参考资源链接:[ANSYS_Fluent_15.0_燃料电池模块手册(en).pdf](https://wenku.csdn.net/doc/64619ad4543f844488937562?spm=1055.2635.3001.10343)
# 1. 燃料电池仿真概述
燃料电池作为清洁能源技术的核心设备之一,其性能与效率的提升对环境可持续
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )