【Python包开发全攻略】:distutils实战,打造完美Python包
发布时间: 2024-10-11 06:46:15 阅读量: 37 订阅数: 30 

python-innosetup:distutils扩展模块-通过InnoSetup创建安装程序

# 1. Python包开发基础
Python的包开发是每个开发者都可能涉及到的一个重要话题。在这一章节中,我们将从基础的概念和步骤开始,带领读者进入Python包开发的世界。
## 1.1 什么是Python包?
在Python中,包是一种管理模块命名空间的方式,通过使用点号`.`来分隔模块名中的不同部分,例如`package.module`。这些模块可能存放在文件系统中的不同目录里,Python通过包的结构来管理这些模块。
## 1.2 Python包的基本结构
一个典型的Python包通常包括一个包含`__init__.py`文件的文件夹,这个文件可以为空,也可以包含一些初始化Python包所需的代码。此外,包中还可以包含多个模块文件(.py)和子包,子包结构与普通包相似,也可以包含自己的`__init__.py`文件。
## 1.3 开始编写你的第一个Python包
创建Python包的第一步是设置包结构。让我们从创建一个简单的包开始:
```bash
mkdir mypackage
cd mypackage
mkdir mypackage
touch mypackage/__init__.py
touch mymodule.py
```
然后在`mymodule.py`中编写一些代码,比如一个简单的函数,并在`__init__.py`中导入这个函数。为了构建和分发这个包,你需要创建一个`setup.py`文件并使用`setuptools`来定义包的元数据和依赖项。完成后,可以使用命令`python setup.py sdist`来创建源代码分发包,并使用`pip`安装你的包。
通过这个过程,读者可以初步了解Python包的基本结构和构建方法,并为进一步学习包开发的高级主题打下坚实的基础。接下来,我们将深入了解`distutils`工具,这是Python包开发中一个重要的构建和分发工具。
# 2. 深入理解distutils
### 2.1 distutils核心概念
#### 2.1.1 distutils的定义和作用
distutils是Python的一个模块,提供了一组标准的脚本和工具来构建和安装Python模块,无论是在本机还是其他机器上。它使得开发者能够轻松地创建安装包,这些安装包可以使用`python setup.py install`命令在其他系统上安装,这使得模块的分发和安装变得方便快捷。distutils是早期Python包管理和分发的事实标准,在PEP 262中进行了规范。
使用distutils的好处主要在于简化了Python包的打包和分发过程。开发者可以不用关心平台特定的构建和安装细节,只需编写一个`setup.py`文件,指定包的基本信息,然后使用标准的命令来进行打包和安装。
#### 2.1.2 安装和配置distutils
通常来说,如果你安装了Python,distutils已经被包含在内了。对于Linux用户来说,大多数发行版都会默认安装Python,包括distutils。对于Windows用户,官方的Python安装包中也包含了distutils。如果你使用的是Python标准安装,就不需要额外安装distutils。
如果需要对distutils进行配置,可以在`setup.cfg`文件中指定配置项,或者通过环境变量进行配置,例如设置`PYTHONPATH`环境变量来指定Python解释器搜索模块的位置。可以通过以下命令查看distutils的版本和安装位置:
```shell
python -m distutils --version
```
该命令会输出当前系统中安装的distutils的版本信息。如果存在配置问题或者未找到distutils,这个命令会报错,提示无法找到模块。
### 2.2 使用distutils构建包
#### 2.2.1 setup.py的编写
`setup.py`是distutils的核心,它是一个Python脚本,用于定义包的相关信息,如包名、版本、依赖、打包后的文件等。下面是一个简单的`setup.py`示例:
```python
from distutils.core import setup, Extension
module1 = Extension('module1', sources = ['module1.c'])
setup(
name = 'PackageName',
version = '1.0',
description = 'This is a demo package',
ext_modules = [module1],
)
```
在这个例子中,定义了一个名为`PackageName`的包,它包含一个C扩展模块`module1`。`name`和`version`是必须指定的字段,分别代表包的名称和版本号。`ext_modules`列表中包含了`Extension`对象,该对象描述了如何构建C扩展模块。
编写`setup.py`时,需要注意以下几点:
- 如果你使用了第三方库,可以通过`install_requires`参数来指定依赖。
- 使用`scripts`参数可以将脚本安装到Python脚本路径的特定位置。
- `packages`参数可以指定自动找到所有子包并包含它们。
#### 2.2.2 包的构建和分发
构建包的命令是`python setup.py build`。执行这个命令会生成编译后的`.pyc`文件和`.so`文件(对于C扩展),并将它们放在`build`目录下。这个目录是临时的,通常不会被包含在分发包中。
分发包通常是指将包打包成`tar.gz`或者`whl`(Python的wheel包)格式,以便于分发和安装。你可以使用以下命令来创建分发包:
```shell
python setup.py sdist bdist_wheel
```
执行完上述命令后,会在`dist/`目录下发现生成的分发包文件,例如`PackageName-1.0.tar.gz`和`PackageName-1.0-py3-none-any.whl`。
### 2.3 distutils的高级应用
#### 2.3.1 打包和依赖管理
打包时,除了源代码和数据文件外,包可能还依赖于其他Python包或外部库。distutils允许开发者在`setup.py`中声明这些依赖,确保在安装时这些依赖能够被自动下载和安装。
```python
setup(
# ...
install_requires=[
'requests>=2.0',
'beautifulsoup4',
],
)
```
依赖项的版本可以被指定为最小版本号或者使用比较运算符来指定版本范围。当安装包时,如果指定的依赖项未被满足,`pip`会自动下载并安装所需版本的依赖包。
#### 2.3.2 跨平台构建和部署
distutils支持跨平台构建,这意味着可以在一个平台上创建分发包,然后在另一个平台上安装它。distutils会根据平台特定的方式处理构建过程中的不同需求,例如在Windows上编译C扩展可能需要不同的参数。
要创建适用于不同平台的分发包,开发者应该在不同的平台上运行`python setup.py sdist bdist_wheel`命令。对于Windows平台,可能需要使用特定的编译器,如Microsoft Visual C++编译器。对于Linux平台,可能会需要一个完整的编译环境来编译C扩展。
部署时,可以使用`pip`来安装wheel包。由于wheel包是二进制格式,所以安装速度更快,也避免了编译过程中的潜在问题。
```shell
pip install PackageName-1.0-py3-none-any.whl
```
通过这种方式,可以轻松地在不同平台上安装和部署Python包。
# 3. Python包的代码实践
## 3.1 编写高质量代码
### 3.1.1 遵循PEP 8编码规范
PEP 8是Python Enhancement Proposal #8的缩写,它定义了Python代码的风格指南。遵循PEP 8不仅能让代码更容易被他人阅读和理解,而且可以避免一些常见的编程错误。它涵盖了诸如缩进、空白、命名约定、注释和文档字符串等多个方面。
为了遵循PEP 8规范,我们可以使用`flake8`这样的工具来帮助我们自动检测代码中不符合规范的地方。`flake8`可以集成到大多数代码编辑器中,也可以作为CI流程中的一个环节。
下面是一个简单的`flake8`检查的例子:
```bash
flake8 mymodule.py
```
如果代码中存在PEP 8违规情况,`flake8`将输出错误代码和对应的行号,提示开发者进行修改。
### 3.1.2 测试驱动开发(TDD)的实践
测试驱动开发(Test-Driven Development, TDD)是一种软件开发方法,它要求开发者先编写测试用例,然后编写满足测试条件的代码。TDD鼓励编写简洁且功能单一的代码,使代码更加可维护和可测试。
在Python中,我们通常使用`unittest`、`pytest`等框架来实现TDD。以下是一个使用`pytest`编写测试用例的例子:
```python
# test_module.py
import module_to_test
def test_add_function():
assert module_to_test.add(2, 3) == 5
assert module_to_test.add(-1, 1) == 0
```
运行测试:
```bash
pytest test_module.py
```
如果`add`函数能够通过测试,它应该返回正确的结果。否则,`pytest`会报告失败,并指出哪部分代码不符合预期。
## 3.2 设计良好的包结构
### 3.2.1 模块和子包的组织
良好的模块和子包组织可以帮助其他开发者更快地理解和使用你的代码。在Python中,一个包通常包含多个模块和子包。以下是一个典型的包结构示例:
```
mypackage/
|-- __init__.py
|-- module1.py
|-- module2.py
|-- submodule/
| |-- __init__.py
| |-- submodule1.py
| |-- submodule2.py
```
在`__init__.py`中,我们可以导出模块级别的接口,使得用户可以简单地通过`import mypackage`来使用这些接口。
### 3.2.2 __init__.py和包文档
`__init__.py`文件用于初始化Python包。它可以为空,也可以包含初始化代码或者包级别的变量和函数。例如,如果你想要将特定模块自动导入到包的命名空间中,可以在`__init__.py`中实现。
```python
# mypackage/__init__.py
from .module1 import some_function
from .submodule.submodule1 import another_function
```
另外,一个良好的包文档(`README.rst`或`README.md`)是必不可少的,它描述了包的用途、安装方法、使用示例和维护信息。文档也可以直接在`__init__.py`中通过多行字符串形式存在,但更推荐单独创建文档文件,并在`__init__.py`中引用。
## 3.3 包的版本管理和发布
### 3.3.1 版本号的约定和变更
版本号是软件包中非常关键的信息。通常遵循`主版本号.次版本号.修订号`的格式。版本号的变更遵循语义化版本控制规则:
- 主版本号(Major): 当你做了不兼容的API更改时。
- 次版本号(Minor): 当你添加了向下兼容的新功能时。
- 修订号(Patch): 当你做了向下兼容的问题修正时。
版本号变更应当在变更日志中进行记录,这对于包的用户来说是一个重要的参考。变更日志的一个简单示例如下:
```
### 1.1.0 - 2023-03-12
* 添加了新的功能
* 改进了性能
### 1.0.1 - 2023-03-01
* 修复了几个小问题
```
### 3.3.2 发布到PyPI的步骤和策略
发布Python包到Python Package Index (PyPI)是使其对公众可用的重要步骤。这可以通过`setuptools`和`twine`来完成。首先确保包的`setup.py`文件已经配置正确,然后使用`twine`上传到PyPI。
在上传之前,你需要在`setup.py`中配置必要的信息,如包名、版本号、作者和描述等。完成这些配置后,运行以下命令:
```bash
python setup.py sdist bdist_wheel
twine upload dist/*
```
`twine`是一个安全地上传发行版包到PyPI的工具。上传之前,建议在一个私有仓库中测试发布流程,以确保一切按照预期进行。
发布到PyPI的策略包括:
- 持续集成(CI)与自动化测试确保每次提交都经过验证。
- 使用版本控制来管理包的版本和发布历史。
- 通过适当的标签和发布说明来管理GitHub仓库。
- 使用CI工具自动构建和上传到PyPI。
这些实践确保了Python包可以安全、持续地更新和发布给最终用户。
# 4. 扩展和第三方库集成
在现代软件开发中,构建一个功能强大的应用往往需要多种技术栈的支持,而Python社区提供了丰富的第三方库来协助我们。本章节将深入探讨如何集成第三方库到Python项目中,并如何创建扩展模块以提升性能。
## 4.1 集成第三方库
第三方库可以看做是项目开发过程中的“调味品”,恰到好处地使用它们可以大大加快开发速度和提高代码质量。Python的包管理工具pip使得集成第三方库变得异常简单。除此之外,处理依赖关系和解决可能出现的冲突也是本章节的焦点。
### 4.1.1 使用pip管理依赖
**pip**是Python包安装的主要工具,它支持从Python包索引(PyPI)下载并安装包。在集成第三方库时,首先需要在项目的`requirements.txt`文件中列出所有依赖。这样,项目就可以通过一个简单的命令安装所有依赖。
```bash
pip install -r requirements.txt
```
使用`requirements.txt`文件的好处在于,它为项目提供了一个清晰的依赖列表,也使得其他开发者和部署环境能够轻松地复制相同的环境。
### 4.1.2 管理和解决依赖冲突
依赖冲突是集成第三方库时可能遇到的问题之一。例如,库A依赖于`Django<2.0`,而库B依赖于`Django>2.0`,这将导致无法同时安装这两个库。为了解决这类问题,可以使用`pip-tools`和`pipenv`这样的工具来管理依赖并生成锁定文件。
```bash
pip install pip-tools
pip-sync requirements.txt
```
`pip-tools`命令`pip-sync`将尝试同步环境中包的版本,确保它们与`requirements.txt`中指定的版本相匹配,从而避免冲突。
## 4.2 创建扩展模块
在某些情况下,纯Python代码可能无法满足性能要求,这时候就需要创建扩展模块来提升性能。扩展模块通常是用其他编程语言(如C或C++)编写的,并且可以被Python直接调用。
### 4.2.1 使用Cython创建C扩展
**Cython**是一个编译器,它可以将Python代码和C/C++代码混合编译成扩展模块。使用Cython创建扩展模块能够显著提高执行速度,尤其是在计算密集型任务中。
首先,需要编写一个`.pyx`文件,这个文件是Cython的源文件,它可以包含Python代码和C类型声明。
```cython
# example.pyx
def add(int a, int b):
return a + b
```
然后,创建一个`setup.py`文件来编译`.pyx`文件,并将其打包成一个Python可导入模块。
```python
# setup.py
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize("example.pyx")
)
```
通过运行`python setup.py build_ext --inplace`,Cython将会生成C代码并将其编译为扩展模块。
### 4.2.2 优化扩展模块性能
创建扩展模块之后,下一步就是确保其性能达到预期。性能分析工具如`cProfile`可以帮助我们找出性能瓶颈,然后可以通过修改C代码来优化性能。
假设我们已经创建了一个名为`example.c`的C扩展模块,并且在Python中导入和使用它。如果发现性能不足,可以使用`cProfile`进行性能分析。
```bash
python -m cProfile -s time myscript.py
```
这个命令会运行`myscript.py`脚本,并根据时间对函数进行排序。得到的输出可以指导我们确定哪些函数需要优化。如果性能瓶颈出现在扩展模块中,我们就需要回到C代码,利用更高效的算法或数据结构进行优化。
通过Cython和性能分析工具的使用,我们不仅可以将Python代码转换为扩展模块,还能确保这些模块运行得足够快,满足应用的需求。
# 5. 持续集成和自动化测试
持续集成(CI)是一种软件开发实践,在这种实践中,开发人员频繁地(甚至每天多次)将代码集成到共享的仓库中。每次集成都通过自动化构建进行测试,包括单元测试、集成测试和功能测试,从而尽早发现集成错误。CI能够减少集成问题,让产品可以快速发布,并且持续改进。而自动化测试是CI实践中的重要组成部分,它减少了手动测试的时间和工作量,并且确保了软件质量的稳定性。
## 5.1 持续集成(CI)的理论和工具
### 5.1.1 CI的基本概念和好处
持续集成的核心思想是软件开发过程中频繁地集成新代码,通常每个开发人员每天至少集成一次。这样做可以更快地发现和定位问题,避免缺陷的累积,使得项目更加稳定。
持续集成的好处包括但不限于:
- **减少集成问题:** 经常集成代码可以及早发现和修复冲突。
- **快速反馈:** 自动化构建和测试可以在几分钟内提供关于代码质量的反馈。
- **提升产品质量:** 定期运行的全面测试套件可以持续监控和提升软件质量。
- **提高开发效率:** 自动化流程减少了重复性工作,使开发人员可以专注于更富创造性的任务。
### 5.1.2 Jenkins、Travis CI和GitLab CI的使用
不同的CI工具提供了不同的功能和服务,下面介绍当前流行的一些CI工具:
#### Jenkins
Jenkins是一个开源的自动化服务器,可以用来自动化各种任务,包括构建、测试和部署。其主要特点是:
- **强大的插件生态:** Jenkins拥有数千个插件,可以扩展其功能。
- **可配置性强:** 几乎所有的Jenkins功能都是可配置的。
- **易于安装和使用:** 提供了Web界面,使得用户可以轻松地进行操作。
Jenkins的使用流程通常包括安装Jenkins、配置构建任务、编写构建脚本和设置测试用例等。
```groovy
pipeline {
agent any
stages {
stage('Build') {
steps {
// 构建代码的指令
}
}
stage('Test') {
steps {
// 运行测试的指令
}
}
}
}
```
在上面的Groovy代码中,定义了一个CI流程,包括构建和测试阶段。每个阶段都包含一组步骤。
#### Travis CI
Travis CI是一个托管的CI服务,特别适合开源项目。其特点包括:
- **易于使用:** 与GitHub集成紧密,用户只需要在项目中添加`.travis.yml`文件即可。
- **免费提供开源项目:** 对于开源项目,Travis CI提供免费的构建服务。
Travis CI的配置文件`.travis.yml`允许用户定义构建环境、运行的测试脚本等。
```yaml
language: python
python:
- "2.7"
- "3.5"
install:
- pip install -r requirements.txt
script:
- python setup.py test
```
在YAML配置文件中,指定了项目使用的编程语言、Python版本、安装步骤和测试命令。
#### GitLab CI
GitLab CI是GitLab提供的一个持续集成服务,与Jenkins和Travis CI相比,它更注重与GitLab仓库的集成。
- **集成了代码仓库:** GitLab CI与代码仓库同为一个平台,管理更方便。
- **流水线功能:** 提供了一套完整的CI/CD流水线工具,使得整个软件发布周期更加自动化。
与Travis CI类似,GitLab CI的配置也是通过仓库中的`.gitlab-ci.yml`文件进行的。
```yaml
stages:
- build
- test
- deploy
build_job:
stage: build
script:
- echo "Building the project..."
- make build
test_job:
stage: test
script:
- echo "Running tests..."
- make test
```
在YAML文件中,定义了不同阶段的作业(如构建、测试和部署)以及每个作业需要执行的脚本。
## 5.2 测试框架和策略
### 5.2.* 单元测试、集成测试和功能测试
在软件测试中,不同类型和级别的测试确保软件的质量。单元测试、集成测试和功能测试是常用的测试类型。
#### 单元测试
单元测试关注最小可测试单元,通常是函数或方法。目的是确保每个单元按预期工作。
单元测试框架如`unittest`(Python内置)和`pytest`(流行的第三方库)常用于Python项目。
```python
def test_addition():
assert add(2, 3) == 5
```
这个简单的例子演示了如何使用`assert`语句进行单元测试。
#### 集成测试
集成测试确保应用程序的不同模块按预期协同工作。
集成测试通常需要在测试数据库中进行,以避免影响生产数据。
```python
def test_user_creation():
assert len(User.query.all()) == 1
user = User('new_user')
assert user in User.query.all()
```
在上述代码段中,测试了用户模型创建操作是否正确。
#### 功能测试
功能测试,也称为端到端测试,模拟了真实的用户操作流程。
Selenium和Robot Framework常用于自动化功能测试。
```***
***mon.keys import Keys
driver = webdriver.Firefox()
driver.get("***")
assert "Example" in driver.title
elem = driver.find_element_by_name('q')
elem.clear()
elem.send_keys('seleniumhq' + Keys.RETURN)
assert 'seleniumhq' in driver.title
driver.quit()
```
上述脚本使用Selenium进行浏览器自动化测试,验证了搜索功能。
### 5.2.2 模拟对象和测试覆盖率
在测试中,模拟对象(Mock)被用于替代那些难以在测试中直接访问的组件。这对于集成测试尤其重要。
Python的`unittest.mock`模块提供了一套模拟工具。
```python
from unittest.mock import patch
def test_search():
with patch('module.ClassName.search') as mock_search:
mock_search.return_value = 'mocked result'
assert search_function() == 'mocked result'
```
在这段代码中,`patch`函数用于模拟`search`方法的返回值。
测试覆盖率衡量测试覆盖了多少代码,是衡量测试质量的重要指标。Python的`coverage`包可以用来评估代码的测试覆盖率。
```bash
coverage run --source='.' -m unittest discover
coverage report -m
```
这两条命令首先运行所有测试用例,然后报告代码的测试覆盖率。
在本章节中,我们介绍了CI的基本概念、好处和几种流行的CI工具。同时,我们也讲解了在Python项目中使用不同的测试类型、模拟对象和测试覆盖率的重要性。通过深入这些内容,读者可以构建一个更加健壮和可靠的开发流程,从而提升软件产品的质量和交付速度。下一章节我们将继续探讨如何通过文档和性能分析进一步优化Python包的维护和优化工作。
# 6. 维护和优化Python包
Python包发布后,维护和优化是保持其长期健康和活力的关键。良好的维护不仅可以提升用户满意度,还能吸引新用户。优化则可以保证软件运行高效,为用户带来更好的使用体验。本章节将探讨Python包文档编写、性能分析和优化、以及社区管理等几个方面的实践。
## 6.1 包的文档和帮助
编写清晰且易于理解的文档是提升用户使用体验的首要步骤。文档可以帮助用户快速了解如何安装、配置和使用你的包。
### 6.1.1 编写清晰的README和文档
README文件是用户获取项目信息的第一站,通常包括以下内容:
- 项目简介
- 安装指南
- 快速上手指南
- 功能列表和使用示例
- 常见问题解答(Q&A)
- 贡献指南
在Markdown格式中,我们可以编写一个结构化的README文档,例如:
```markdown
# Project Title
## Overview
A brief description of the project.
## Installation
Installation steps.
```shell
pip install my-package
```
## Quick Start
A simple example to get started.
```python
import my_package
# Do something...
```
## Features
- Feature 1
- Feature 2
- ...
## FAQ
Common questions answered here.
## Contributing
Guidelines for contributing to the project.
```
对于更详细的文档,推荐使用Sphinx工具。Sphinx可以生成HTML、PDF等多种格式的文档,并支持自动从源代码中提取注释生成文档。
### 6.1.2 文档的自动构建和部署
Sphinx生成文档后,可以结合GitHub Actions或GitLab CI进行自动化构建和部署。以GitHub Actions为例,可以在项目中添加一个`.github/workflows`目录,并在其中创建一个YAML配置文件,如`deploy.yml`,来自动执行构建和部署过程。
```yaml
name: Deploy documentation
on:
push:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install sphinx
pip install sphinx-rtd-theme
- name: Build documentation
run: |
sphinx-build -b html docs/ build/
- name: Deploy to GitHub Pages
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./build
```
## 6.2 包的性能分析和优化
性能分析和优化是软件开发中的一项重要工作。对Python包而言,合理地分析性能瓶颈并进行针对性优化可以带来巨大的效率提升。
### 6.2.1 性能分析工具的使用
常用的性能分析工具有cProfile、line_profiler等。
cProfile可以直接在Python中使用,来分析程序运行时的性能瓶颈。例如:
```python
import cProfile
cProfile.run('some_function()')
```
line_profiler是一种更细致的分析工具,可以分析代码中每一行的执行时间。使用line_profiler前,需要安装该工具,并通过`@profile`装饰器来标记需要分析的函数。
```python
# some_function.py
@profile
def some_function():
# Do something...
```
然后使用`kernprof`命令来运行程序:
```shell
kernprof -v -l some_function.py
```
### 6.2.2 优化策略和代码重构
在获取了性能分析报告后,根据报告中显示的性能瓶颈进行针对性的优化。常见的优化策略包括:
- 利用更高效的数据结构
- 使用生成器减少内存消耗
- 使用多进程来利用多核CPU
- 对热点代码使用Cython或C扩展进行优化
重构代码时,要注重代码的可读性和维护性。避免过度优化,因为过于复杂的代码可能在未来的维护中带来问题。
## 6.3 社区管理和用户反馈
一个活跃的社区能够提升包的知名度,并吸引更多的贡献者。有效管理社区和处理用户反馈是提升包质量的重要手段。
### 6.3.1 社区建立和维护
- 建立一个社区论坛,如使用Discourse。
- 在GitHub上设置一个活跃的issue跟踪器。
- 定期发布版本更新和新功能介绍。
- 举办线上或线下活动,加强与用户的互动。
### 6.3.2 收集和处理用户反馈
- 在文档中提供反馈渠道。
- 对收到的反馈进行归类和优先级排序。
- 制定计划定期处理高优先级的反馈。
- 将处理结果反馈给用户,增强用户满意度。
通过上述措施,Python包的维护和优化不仅能够提高用户的体验,而且能够提升项目的整体质量,为未来的开发打下坚实的基础。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库文件学习中必不可少的 distutils 工具。通过一系列文章,专栏涵盖了从 distutils 原理到实践应用的各个方面,包括:
* distutils 的安装和使用
* Python 包的打包和分发
* distutils 高级技巧和优化指南
* distutils 与 setuptools 的对比
* distutils 在企业级应用中的最佳实践
* distutils 常见问题的诊断和解决
* 自定义安装脚本和钩子应用
* distutils 与 Sphinx 集成实现包文档自动化
本专栏旨在为 Python 开发人员提供全面的 distutils 指南,帮助他们高效管理 Python 库的打包、分发和文档,从而构建稳定可靠的 Python 代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【EDA课程进阶秘籍】:优化仿真流程,强化设计与仿真整合

# 摘要
随着集成电路设计复杂性的增加,EDA(电子设计自动化)课程与设计仿真整合的重要性愈发凸显。本文全面探讨了EDA工具的基础知识与应用,强调了设计流程中仿真验证和优化的重要性。文章分析了仿真流程的优化策略,包括高
DSPF28335 GPIO故障排查速成课:快速解决常见问题的专家指南

# 摘要
本文详细探讨了DSPF28335的通用输入输出端口(GPIO)的各个方面,从基础理论到高级故障排除策略,包括GPIO的硬件接口、配置、模式、功能、中断管理,以及在实践中的故障诊断和高级故障排查技术。文章提供了针对常见故障类型的诊断技巧、工具使用方法,并通过实际案例分析了故障排除的过程。此外,文章还讨论了预防和维护GPIO的策略,旨在帮助
掌握ABB解包工具的最佳实践:高级技巧与常见误区

# 摘要
本文旨在介绍ABB解包工具的基础知识及其在不同场景下的应用技巧。首先,通过解包工具的工作原理与基础操作流程的讲解,为用户搭建起使用该工具的初步框架。随后,探讨了在处理复杂包结构时的应用技巧,并提供了编写自定义解包脚本的方法。文章还分析了在实际应用中的案例,以及如何在面对环境配置错误和操
【精确控制磁悬浮小球】:PID控制算法在单片机上的实现
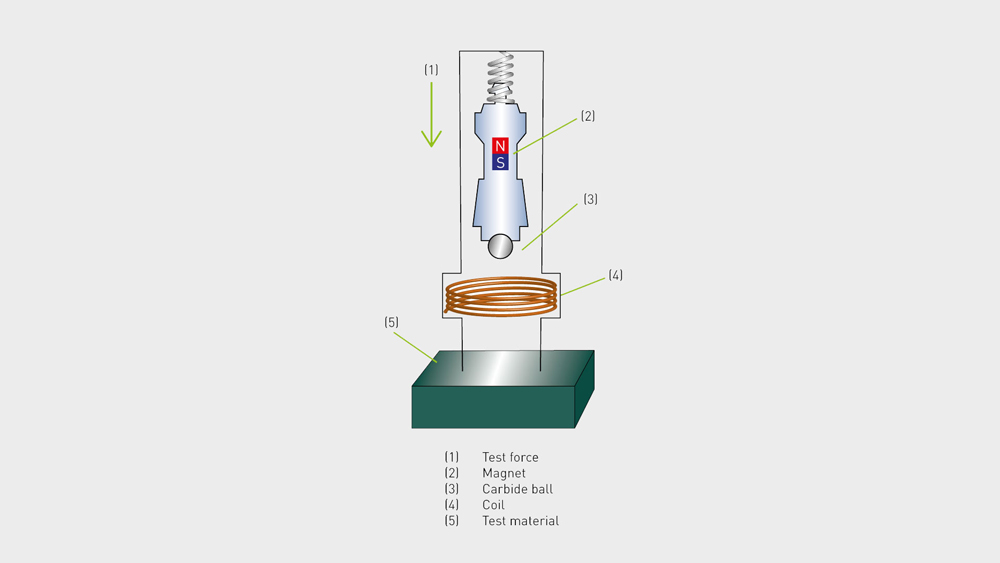
# 摘要
本文综合介绍了PID控制算法及其在单片机上的应用实践。首先概述了PID控制算法的基本原理和参数整定方法,随后深入探讨了单片机的基础知识、开发环境搭建和PID算法的优化技术。通过理论与实践相结合的方式,分析了PID算法在磁悬浮小球系统中的具体实现,并展示了硬件搭建、编程以及调试的过程和结果。最终,文章展望了PID控制算法的高级应用前景和磁悬浮技术在工业与教育中的重要性。本文旨在为控制工程领
图形学中的纹理映射:高级技巧与优化方法,提升性能的5大策略
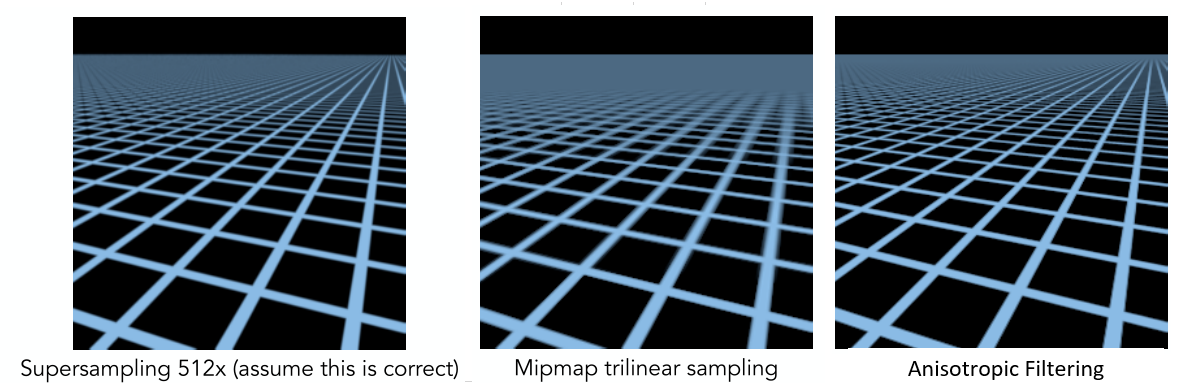
# 摘要
本文系统地探讨了纹理映射的基础理论、高级技术和优化方法,以及在提升性能和应用前景方面的策略。纹理映射作为图形渲染中的核心概念,对于增强虚拟场景的真实感和复杂度至关重要。文章首先介绍了纹理映射的基本定义及其重要性,接着详述了不同类型的纹理映射及应用场景。随后,本文深入探讨了高级纹理映射技术,包括纹理压缩、缓存与内存管理和硬件加速,旨在减少资源消耗并提升
【Typora插件应用宝典】:提升写作效率与体验的15个必备插件
# 摘要
本论文详尽探讨了Typora这款Markdown编辑器的界面设计、编辑基础以及通过插件提升写作效率和阅读体验的方法。文章首先介绍了Typora的基本界面与编辑功能,随后深入分析了多种插件如何辅助文档结构整理、代码编写、写作增强、文献管理、多媒体内容嵌入及个性化定制等方面。此外,文章还讨论了插件管理、故障排除以及如何保证使用插件时
RML2016.10a字典文件深度解读:数据结构与案例应用全攻略
# 摘要
本文全面介绍了RML2016.10a字典文件的结构、操作以及应用实践。首先概述了字典文件的基本概念和组成,接着深入解析了其数据结构,包括头部信息、数据条目以及关键字与值的关系,并探讨了数据操作技术。文章第三章重点分析了字典文件在数据存储、检索和分析中的应用,并提供了实践中的交互实例。第四章通过案例分析,展示了字典文件在优化、错误处理、安全分析等方面的应用及技巧。最后,第五章探讨了字典文件的高
【Ansoft软件精通秘籍】:一步到位掌握电磁仿真精髓
# 摘要
本文详细介绍了Ansoft软件的功能及其在电磁仿真领域的应用。首先概述了Ansoft软件的基本使用和安装配置,随后深入讲解了基础电磁仿真理论,包括电磁场原理、仿真模型建立、仿真参数设置和网格划分的技巧。在实际操作实践章节中,作者通过多个实例讲述了如何使用Ansoft HFSS、Maxwell和Q3D Extractor等工具进行天线、电路板、电机及变压器等的电磁仿真。进而探讨了Ansoft的高级技巧
负载均衡性能革新:天融信背后的6个优化秘密
# 摘要
负载均衡技术是保障大规模网络服务高可用性和扩展性的关键技术之一。本文首先介绍了负载均衡的基本原理及其在现代网络架构中的重要性。继而深入探讨了天融信的负载均衡技术,重点分析了负载均衡算法的选择标准、效率与公平性的平衡以及动态资源分配机制。本文进一步阐述了高可用性设计原理,包括故障转移机制、多层备份策略以及状态同步与一致性维护。在优化实践方面,本文讨论了硬件加速、性能调优、软件架构优化以及基于AI的自适应优化算法。通过案例
【MAX 10 FPGA模数转换器时序控制艺术】:精确时序配置的黄金法则
# 摘要
本文主要探讨了FPGA模数转换器时序控制的基础知识、理论、实践技巧以及未来发展趋势。首先,从时序基础出发,强调了时序控制在保证FPGA性能中的重要性,并介绍了时序分析的基本方法。接着,在实践技巧方面,探讨了时序仿真、验证、高级约束应用和动态时序调整。文章还结合MAX 10 FPGA的案例,详细阐述了模数转换器的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )