【Python字符串处理全攻略】:8大技巧助你成为编码大师
发布时间: 2024-09-20 09:41:07 阅读量: 212 订阅数: 56 

字符串数组反转全攻略:技巧、代码实现与应用场景

# 1. Python字符串基础知识
## 简介
Python字符串是编程中最常用的数据类型之一,用于存储文本数据。理解其基本操作对于任何想要成为有效Python程序员的人都是必不可少的。在本章中,我们将介绍字符串的创建、访问以及一些简单的操作,为读者之后的深入学习打下坚实基础。
## 字符串的创建和表示
在Python中,字符串可以通过单引号、双引号或三引号来创建。例如:
```python
single_quoted = 'Hello World!'
double_quoted = "Hello World!"
triple_quoted = """Hello World!"""
```
所有这些表示方法都创建了相同的字符串值。三引号字符串常用于多行文本。
## 基本操作
字符串可以进行多种基本操作,包括索引、切片、拼接和重复等。例如:
```python
greeting = "Hello"
name = "World"
# 索引和切片
print(greeting[0]) # 输出: H
print(greeting[1:3]) # 输出: el
# 拼接
message = greeting + ", " + name + "!"
print(message) # 输出: Hello, World!
# 重复
repeated_message = message * 2
print(repeated_message) # 输出: Hello, World!Hello, World!
```
这些操作是字符串处理中最基本的技能,理解它们是进行更复杂字符串操作的前提。
通过本章内容,我们为读者提供了一个关于Python字符串使用和操作的初步了解,并为下一章关于字符串处理的深入理论和实践打下了良好的基础。
# 2. 字符串处理的理论基础
## 2.1 字符串的内部表示
### 2.1.1 Unicode和UTF-8编码机制
在深入了解字符串的内部表示之前,我们先要理解字符编码的概念。字符编码是计算机存储和传输文本的方式。Unicode是一个广泛使用的字符集,它为世界上几乎所有的书写系统提供了唯一的数字标识,从基本的拉丁字母到中文、日文、阿拉伯文等。
UTF-8是Unicode的一种实现方式,它是一种可变长度的字符编码,可以用来表示Unicode标准中的任何字符。UTF-8的编码规则如下:
- 对于U+0000 至 U+007F 的字符,UTF-8编码和ASCII编码完全相同。
- 对于U+0080 至 U+07FF 的字符,使用2个字节表示。
- 对于U+0800 至 U+FFFF 的字符,使用3个字节表示。
- 对于U+10000 至 U+10FFFF 的字符,使用4个字节表示。
下面是UTF-8编码的一个简单例子:
```python
text = '你好'
encoded_text = text.encode('utf-8')
print(encoded_text) # 输出编码后的字节序列
```
执行上述代码会得到`你好`两个中文字符的UTF-8编码的字节序列。
### 2.1.2 字符串与字节序列的区别
在Python中,字符串是以Unicode字符序列的形式存在的。当你处理文本数据时,使用的是字符串类型。而字节序列是字节的有序集合,通常用来表示二进制数据,如图片或音频文件等。
字符串可以很容易地转换为字节序列,反之亦然。举一个转换的例子:
```python
# 字符串转字节序列
string = '这是一个字符串'
bytes_sequence = string.encode('utf-8')
print(bytes_sequence)
# 字节序列转字符串
recovered_string = bytes_sequence.decode('utf-8')
print(recovered_string)
```
上述代码中,首先把一个中文字符串编码为UTF-8格式的字节序列,然后通过解码将字节序列恢复成原始的字符串。
理解Unicode和UTF-8编码机制,以及字符串和字节序列之间的区别,是进行任何字符串处理的理论基础。这些概念对于后续深入学习字符串的查找、替换、分割、连接等操作至关重要。
## 2.2 常用字符串方法详解
### 2.2.1 字符串的查找与替换
在Python中,字符串提供了一系列方法来进行查找与替换操作,这些方法包括但不限于`find()`, `index()`, `replace()`等。
- `find(sub[, start[, end]])`方法用于查找子字符串sub第一次出现的索引位置,如果未找到子字符串,则返回-1。start和end参数用于指定查找范围。
- `index(sub[, start[, end]])`与`find()`类似,但如果未找到子字符串,`index()`会抛出`ValueError`异常。
- `replace(old, new[, count])`用于将字符串中的旧字符串old替换为新字符串new,并返回替换后的字符串。如果指定了count,则只替换前count次出现。
下面展示如何使用这些方法:
```python
s = "Hello world, hello Python!"
# 查找
location = s.find("world") # 查找子字符串"world"的位置
print(location) # 输出 6
# 替换
s_new = s.replace("world", "Python")
print(s_new) # 输出 "Hello Python, hello Python!"
```
在实际应用中,根据需求选择合适的方法可以有效提升代码的健壮性和可读性。
### 2.2.2 字符串的分割与连接
字符串的分割与连接是日常处理中最常见的操作之一。Python提供了`split()`, `join()`, 和`partition()`等方法来实现这些功能。
- `split(sep=None, maxsplit=-1)`方法按指定分隔符sep将字符串分割成子字符串列表,默认为任何空白字符,并返回这个列表。maxsplit用于限制分割次数。
- `join(iterable)`方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
- `partition(sep)`方法返回一个包含三个元素的元组,分别是分隔符sep前的部分、分隔符本身和分隔符后的部分。如果字符串中不包含分隔符则返回原字符串组成的元组。
示例如下:
```python
s = "apple,banana,cherry"
# 分割
parts = s.split(',')
print(parts) # 输出 ['apple', 'banana', 'cherry']
# 连接
s_new = ','.join(parts)
print(s_new) # 输出 "apple,banana,cherry"
# 分割为两部分
before, sep, after = s.partition(',')
print(before) # 输出 "apple"
print(sep) # 输出 ","
print(after) # 输出 "banana,cherry"
```
这些操作虽然看起来简单,但是在处理文件数据和网络数据时尤其重要,能够极大地简化数据预处理的步骤。
### 2.2.3 字符串的大小写转换
字符串的大小写转换涉及的方法包括`upper()`, `lower()`, `capitalize()`, `title()`, 和`swapcase()`等。
- `upper()`方法将字符串中所有字符转换为大写。
- `lower()`方法将字符串中所有字符转换为小写。
- `capitalize()`方法将字符串的第一个字符转换为大写,其余为小写。
- `title()`方法将字符串中每个单词的首字母转换为大写。
- `swapcase()`方法将字符串中每个字符的大小写转换。
下面是一些示例:
```python
s = "Python String Handling"
# 大小写转换
upper_case = s.upper()
print(upper_case) # 输出 "PYTHON STRING HANDLING"
lower_case = s.lower()
print(lower_case) # 输出 "python string handling"
# 首字母大写
capitalized = s.capitalize()
print(capitalized) # 输出 "Python string handling"
# 每个单词首字母大写
title_case = s.title()
print(title_case) # 输出 "Python String Handling"
# 大小写转换
swapped_case = s.swapcase()
print(swapped_case) # 输出 "pYTHON sTRING hANDLING"
```
掌握这些大小写转换方法,对于文本格式化和规范化非常有帮助,尤其是在处理用户输入数据时,可以有效避免因大小写不一致导致的问题。
以上内容深入讲解了字符串的内部表示和常用字符串方法。从基础的编码机制到操作方法,这些知识是字符串处理的基石,后续章节将在此基础上,进一步展开对字符串处理技巧的探讨和实战演练。
# 3. 高级字符串处理技巧
## 3.1 正则表达式在字符串处理中的应用
### 3.1.1 正则表达式的基础知识
正则表达式,又称“regex”或“regexp”,是一种强大的文本处理工具,用于在字符串中执行搜索、匹配、查找和替换操作。在Python中,正则表达式通常通过`re`模块实现。一个正则表达式是一个特殊的字符串,它定义了一个搜索模式,用来匹配和操作一系列符合特定规则的字符串。
正则表达式的基本元素包括:
- **字符集**:如`[abc]`匹配任何一个包含在方括号内的字符。
- **重复匹配**:如`a*`匹配0个或多个'a'字符。
- **特殊字符**:如`.`匹配除换行符外的任意单个字符,`?`匹配0次或1次前面的元素。
- **锚点**:如`^`匹配字符串的开始,`$`匹配字符串的结束。
正则表达式的复杂度可以从简单的`a*`(匹配任意数量的'a')到极其复杂的多行模式匹配。理解正则表达式的基本语法是高效处理文本数据的关键。
### 3.1.2 使用正则表达式进行复杂匹配
在处理字符串时,正则表达式可以用来识别复杂的文本模式,提取信息,以及验证数据的格式。一个实用的例子是验证电子邮件地址格式是否正确。
下面是一个使用Python的`re`模块验证电子邮件地址格式的例子:
```python
import re
# 正则表达式模式匹配电子邮件地址
email_pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
# 待验证的电子邮件地址
email_to_test = "***"
# 使用re.match检查电子邮件地址是否符合模式
match = re.match(email_pattern, email_to_test)
if match:
print(f"The email address {email_to_test} is valid.")
else:
print(f"The email address {email_to_test} is invalid.")
```
在这个例子中,正则表达式`^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$`分解为以下组件:
- `^[a-zA-Z0-9._%+-]+`:从字符串的开始到第一个`@`,匹配一个或多个字母、数字、点、下划线、百分号、加号或减号。
- `@`:匹配一个`@`字符。
- `[a-zA-Z0-9.-]+`:匹配一个或多个字母、数字、点或减号,直到点`.`。
- `\.`:匹配点字符。
- `[a-zA-Z]{2,}$`:从点之后直到字符串的结束,匹配两个或更多的字母,确保顶级域名的长度至少是两个字符。
这个例子展示了正则表达式在进行复杂匹配时的强大功能,通过一个简单的正则表达式模式,就可以对字符串进行验证,确保其符合预期格式。
# 4. 字符串处理的实战演练
## 4.1 文本分析与处理
文本分析与处理是数据科学和文本挖掘中的关键步骤,用于理解大量文本数据并从中提取有价值的信息。在Python中,我们可以使用各种字符串处理方法来完成这些任务。
### 4.1.1 统计词频和文本摘要
统计词频是文本分析中最基础的任务之一,它涉及统计文本中单词出现的次数。通常,这个过程包括清洗文本数据,然后对数据进行分词和计数。
```python
import re
from collections import Counter
def count_words(text):
# 移除标点符号和数字
text = re.sub(r'[^\w\s]', '', text)
text = re.sub(r'\d+', '', text)
# 将文本转换为小写并分割为单词列表
words = text.lower().split()
# 使用Counter统计词频
return Counter(words)
text = "This is a sample text. The text is intended to demonstrate how word frequencies are counted."
word_count = count_words(text)
print(word_count)
```
在上述代码中,我们首先使用正则表达式移除了标点符号和数字,然后将所有字符转换为小写,最后使用`Counter`类来统计单词出现的次数。结果是一个字典,其中键是单词,值是对应的频率。
文本摘要则是一个更高级的话题,它可以是提取文本中最重要的句子,或者是一个简短的文本总结。这通常涉及到自然语言处理(NLP)技术,如文本摘要算法。在Python中,我们可以使用`gensim`库来创建文本摘要。
```python
from gensim.summarization import summarize
document = """
Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant indentation. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects.
summary = summarize(document, ratio=0.2) # 生成20%摘要
print(summary)
```
在这段代码中,`summarize`函数从提供的文档中生成了一个摘要,其中`ratio=0.2`参数表示摘要长度将是原始文本长度的20%。
### 4.1.2 文本清洗与标准化
文本清洗是确保数据分析准确性的重要步骤。文本数据中可能包含许多不需要的字符,如HTML标签、特殊符号等。通过清洗,我们可以获得更干净的数据集,用于进一步分析。
```python
import html
def clean_text(text):
# 移除HTML标签
text = html.unescape(text)
# 移除特殊符号
text = re.sub(r'[^\w\s]', '', text)
return text
dirty_text = "<p>Hello, <b>World</b>!</p>"
cleaned_text = clean_text(dirty_text)
print(cleaned_text)
```
在这段代码中,`unescape`函数用于移除HTML标签,而正则表达式则用于移除特殊符号。
## 4.2 文件和数据的读写
在处理字符串时,经常需要读取和写入文件。Python提供了简单的方法来处理文件中的字符串数据。
### 4.2.1 处理文本文件中的字符串
读取和处理文本文件中的字符串是一个常见的任务。Python中可以使用内置的`open()`函数打开文件,并以读取或写入模式操作文件。
```python
def read_text_file(file_path):
with open(file_path, 'r', encoding='utf-8') as ***
***
***
* 对文件内容进行处理
# 例如:统计词频
return count_words(content)
file_path = "example.txt"
text_content = read_text_file(file_path)
processed_content = process_text(text_content)
print(processed_content)
```
在这段代码中,`read_text_file`函数以UTF-8编码格式打开并读取文本文件的内容。然后,`process_text`函数接收文件内容并使用前面定义的`count_words`函数来统计词频。
### 4.2.2 字符串与JSON数据的交互
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。在Python中,处理JSON格式的数据非常方便。
```python
import json
def load_json_data(file_path):
with open(file_path, 'r', encoding='utf-8') as ***
***
***
*** 'w', encoding='utf-8') as ***
***
***"data.json")
print(data)
# 修改数据并保存
data['new_key'] = 'new_value'
save_json_data(data, "data_modified.json")
```
在上述代码中,`load_json_data`函数用于加载JSON文件,并使用`json.load()`方法读取内容。`save_json_data`函数则用于将Python字典保存为JSON文件。
## 4.3 日志分析与处理
日志文件是应用程序运行时生成的记录文件,它们对于监控系统运行状态、调试和安全审计至关重要。
### 4.3.1 日志文件的读取和解析
分析日志文件的第一步是读取和解析。Python中可以使用标准库中的`logging`模块来读取和解析日志文件。
```python
import logging
def configure_logging(log_file):
logging.basicConfig(level=***, filename=log_file, filemode='a')
def read_log_file(log_file):
logs = []
with open(log_file, 'r') as ***
***
***
***
***'example.log')
# 假设有一些日志被写入example.log文件
# 读取并解析日志
log_entries = read_log_file('example.log')
for entry in log_entries:
print(entry)
```
在这段代码中,`configure_logging`函数配置了日志记录器,`read_log_file`函数读取并返回日志文件中的所有行。
### 4.3.2 日志数据的可视化展示
日志数据的可视化是监控和分析系统健康状况的重要步骤。我们可以使用各种图表来展示日志数据,例如时间序列图表、错误统计图表等。
```python
import matplotlib.pyplot as plt
def plot_log_data(log_entries):
# 假设日志文件中包含时间戳和错误代码
timestamps = []
error_codes = []
for entry in log_entries:
if 'ERROR' in entry:
timestamp, error_code = entry.split()
timestamps.append(timestamp)
error_codes.append(error_code)
plt.plot(timestamps, error_codes, 'bo')
plt.xlabel('Timestamp')
plt.ylabel('Error Code')
plt.title('Error Log Visualization')
plt.show()
# 使用前面读取的日志数据
plot_log_data(log_entries)
```
在这段代码中,我们首先解析了日志条目,分离出时间戳和错误代码,然后使用`matplotlib`库来绘制一个简单的散点图,显示错误发生的频率和时间关系。这种可视化可以帮助我们快速定位系统中的问题。
通过上述内容,我们已经了解了如何在Python中实现文本分析、文件读写以及日志分析的实战演练。通过这些具体的例子,我们可以看到字符串处理不仅仅是理论上的知识,而且在实际应用中非常有用,可以帮助我们更好地理解和使用文本数据。
# 5. 字符串处理进阶话题
## 5.1 字符串处理中的性能优化
字符串处理是很多Python程序中的核心部分,但不恰当的处理方式可能会导致性能问题。在这一小节中,我们将讨论如何识别字符串操作的性能瓶颈,以及如何使用Cython来加速字符串处理。
### 5.1.1 识别和优化字符串操作瓶颈
在优化字符串操作之前,我们需要能够识别出程序中的瓶颈。这通常通过分析代码的运行时间来完成。一个常用的工具有cProfile,它是Python的标准库之一,可以用来分析代码的性能。
下面是一个简单的例子,演示如何使用cProfile来找出代码中的性能瓶颈:
```python
import cProfile
def heavy_string_usage():
my_string = "a" * 1000000
my_string.upper()
def main():
cProfile.run('heavy_string_usage()')
if __name__ == "__main__":
main()
```
上述代码会输出函数调用的次数以及消耗的时间,从而帮助我们找到性能瓶颈。
一旦识别了瓶颈,就可以采取以下优化措施:
- 使用更有效的数据结构。
- 避免不必要的字符串复制操作。
- 利用内置函数和方法,因为它们通常比自定义函数更快。
- 使用生成器表达式代替列表推导式,减少内存占用。
### 5.1.2 使用Cython加速字符串处理
Cython是一个编译器,它可以将Python代码转换为C代码,然后编译为共享库,这可以显著提高执行速度。Cython支持静态类型定义,这通常可以大幅提升性能。
下面是一个使用Cython的例子,我们将优化一个字符串拼接的简单函数:
首先安装Cython:
```shell
pip install cython
```
然后,创建一个`setup.py`文件来编译我们的Cython代码:
```python
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize("fast_string.pyx")
)
```
编写`fast_string.pyx`:
```cython
def concat_strings(list_of_strings):
cdef char* sep = " "
cdef int i, size = len(list_of_strings)
cdef char* result = NULL
cdef int result_size = 0
for i in range(size):
result_size += len(list_of_strings[i])
if i > 0:
result_size += len(sep)
result = <char*>malloc(result_size + 1)
if not result:
raise MemoryError()
cdef int start = 0
for i in range(size):
result[start:start+len(list_of_strings[i])] = list_of_strings[i]
start += len(list_of_strings[i])
if i < size - 1:
result[start:start+len(sep)] = sep
start += len(sep)
result[result_size] = '\0'
return result.decode('utf-8')
```
编译并运行:
```shell
python setup.py build_ext --inplace
```
上述操作会生成一个更快的`concat_strings`函数,它执行字符串拼接的操作比Python原生代码要快得多。
## 5.2 字符串处理的国际化和本地化
随着应用程序越来越全球化,国际化(i18n)和本地化(l10n)在软件开发中变得越来越重要。Python提供了强大的工具来帮助开发者处理多语言文本。
### 5.2.1 支持多语言的字符串处理
Python的`gettext`模块是国际化应用程序的标准方式。它允许开发者将字符串翻译成不同的语言。
简单示例:
```python
import gettext
gettext.install('messages', './locale')
print(_("Hello, World!"))
```
为了支持多种语言,你需要为每种语言创建一个消息目录(在本例中为`locale`目录),并在其中为每种语言创建`.mo`文件,这些文件包含了翻译后的字符串。
### 5.2.2 Python的国际化(i18n)和本地化(l10n)策略
Python的国际化策略依赖于几个关键的概念:
- `gettext`模块用于翻译消息。
- `locale`模块用于处理地区设置,例如日期、时间和数字格式。
- Unicode支持,使得字符串可以包含来自世界上任何语言的字符。
本地化策略的关键步骤包括:
- 提取应用程序中的所有可翻译字符串,并将它们放入`.pot`文件中。
- 为每种目标语言创建一个`.po`文件,并将其中的字符串翻译成相应语言。
- 将`.po`文件编译成`.mo`文件,这些文件将被程序加载以提供翻译。
使用这些策略,开发者可以确保他们的程序能够支持多语言,适应不同地区的用户。
## 5.3 Python字符串处理的未来趋势
Python作为一种广泛使用的编程语言,它在字符串处理方面不断进步,满足开发者和用户的新需求。这一小节中,我们将探讨Python字符串处理的新特性以及它在人工智能和大数据领域中的应用。
### 5.3.1 新版本Python中字符串处理的新特性
随着Python 3的持续发展,新的字符串处理特性不断被引入。比如:
- f-string的引入在Python 3.6中,这提供了一种非常直观和快速的方式来格式化字符串。
- 在Python 3.7及以上版本中,字典的插入顺序保持不变,这对于解析和处理格式化的文本数据很有用。
### 5.3.2 字符串处理在人工智能和大数据中的应用
随着数据科学的兴起,字符串处理在机器学习和数据分析中的作用变得越来越重要。
- 自然语言处理(NLP)中,字符串处理用于文本清洗、词性标注、实体识别等。
- 在大数据分析中,字符串处理用于日志分析、数据提取和转换。
这些是Python字符串处理的一些未来趋势。虽然我们着重讲解了性能优化、国际化和本地化以及新特性,但Python的字符串处理仍然在不断演进,满足日益复杂的软件开发需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python字符串处理全攻略》专栏深入探讨了Python中字符串处理的各个方面。从基础的分割、格式化和匹配技巧,到高级的切片优化、国际化和正则表达式应用,该专栏提供了全面的指南。它还涵盖了编码和解码的细微差别、性能优化策略、安全考虑因素和实战应用。通过深入了解Python字符串处理的方方面面,开发人员可以提高他们的编码效率,编写更简洁、健壮和高效的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
datasheet解读速成课:关键信息提炼技巧,提升采购效率

# 摘要
本文全面探讨了datasheet在电子组件采购过程中的作用及其重要性。通过详细介绍datasheet的结构并解析其关键信息,本文揭示了如何通过合理分析和利用datasheet来提升采购效率和产品质量。文中还探讨了如何在实际应用中通过标准采购清单、成本分析以及数据整合来有效使用datasheet信息,并通过案例分析展示了datasheet在采购决策中的具体应用。最后,本文预测了datasheet智能化处
【光电传感器应用详解】:如何用传感器引导小车精准路径

# 摘要
光电传感器在现代智能小车路径引导系统中扮演着核心角色,涉及从基础的数据采集到复杂的路径决策。本文首先介绍了光电传感器的基础知识及其工作原理,然后分析了其在小车路径引导中的理论应用,包括传感器布局、导航定位、信号处理等关键技术。接着,文章探讨了光电传感器与小车硬件的集成过程,包含硬件连接、软件编程及传感器校准。在实践部分,通过基
新手必看:ZXR10 2809交换机管理与配置实用教程
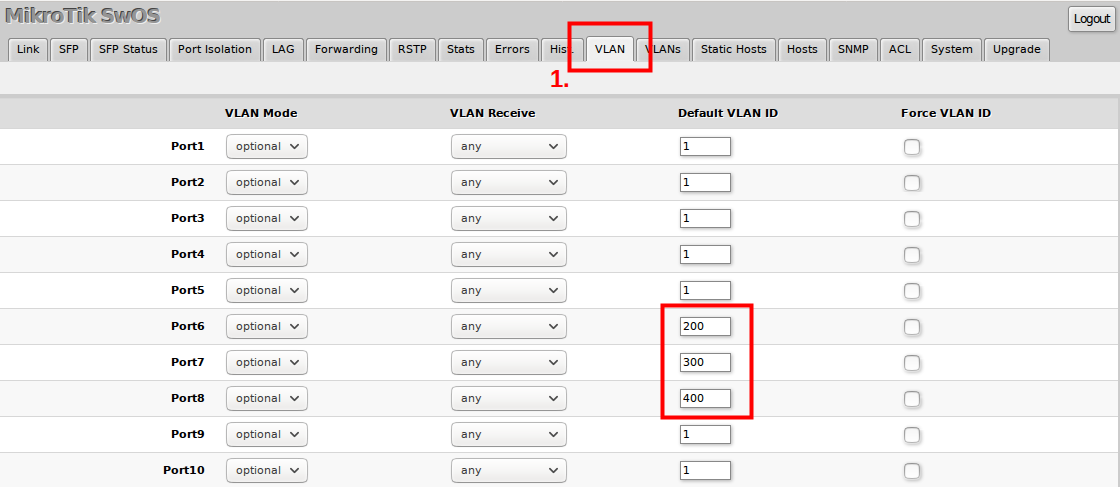
# 摘要
ZXR10 2809交换机作为网络基础设施的关键设备,其配置与管理是确保网络稳定运行的基础。本文首先对ZXR10 2809交换机进行概述,并介绍了基础管理知识。接着,详细阐述了交换机的基本配置,包括物理连接、初始化配置、登录方式以及接口的配置与管理。第三章深入探讨了网络参数的配置,VLAN的创建与应用,以及交换机的安全设置,如ACL配置和端口安全。第四章涉及高级网络功能,如路由配置、性能监控、故障排除和网络优
加密技术详解:专家级指南保护你的敏感数据
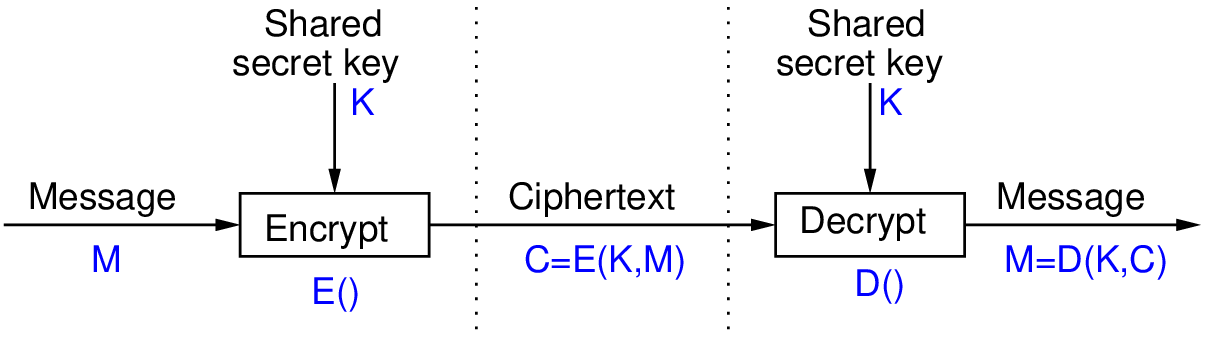
# 摘要
本文系统介绍了加密技术的基础知识,深入探讨了对称加密与非对称加密的理论和实践应用。分析了散列函数和数字签名在保证数据完整性与认证中的关键作用。进一步,本文探讨了加密技术在传输层安全协议TLS和安全套接字层SSL中的应用,以及在用户身份验证和加密策略制定中的实践。通过对企业级应用加密技术案例的分析,本文指出了实际应用中的挑战与解决方案,并讨论了相关法律和合规问题。最后,本文展望了加密技术的未来发展趋势,特别关注了量
【16串电池监测AFE选型秘籍】:关键参数一文读懂

# 摘要
本文全面介绍了电池监测AFE(模拟前端)的原理和应用,着重于其关键参数的解析和选型实践。电池监测AFE是电池管理系统中不可或缺的一部分,负责对电池的关键性能参数如电压、电流和温度进行精确测量。通过对AFE基本功能、性能指标以及电源和通信接口的分析,文章为读者提供了选择合适AFE的实用指导。在电池监测AFE的集成和应用章节中
VASPKIT全攻略:从安装到参数设置的完整流程解析

# 摘要
VASPKIT是用于材料计算的多功能软件包,它基于密度泛函理论(DFT)提供了一系列计算功能,包括能带计算、动力学性质模拟和光学性质分析等。本文系统介绍了VASPKIT的安装过程、基本功能和理论基础,同时提供了实践操作的详细指南。通过分析特定材料领域的应用案例,比如光催化、
【Exynos 4412内存管理剖析】:高速缓存策略与性能提升秘籍
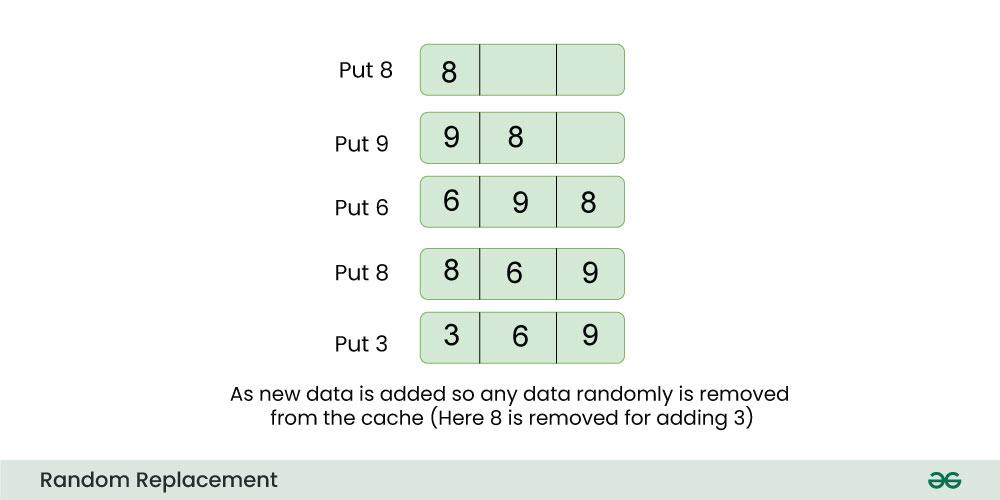
# 摘要
本文对Exynos 4412处理器的内存管理进行了全面概述,深入探讨了内存管理的基础理论、高速缓存策略、内存性能优化技巧、系统级内存管理优化以及新兴内存技术的发展趋势。文章详细分析了Exynos 4412的内存架构和内存管理单元(MMU)的功能,探讨了高速缓存架构及其对性能的影响,并提供了一系列内存管理实践技巧和性能提升秘籍。此外,
慧鱼数据备份与恢复秘籍:确保业务连续性的终极策略(权威指南)
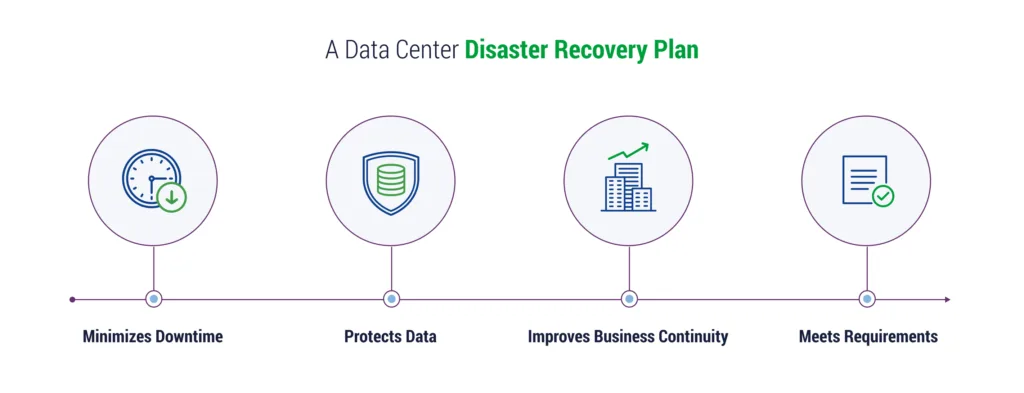
# 摘要
本文全面探讨了数据备份与恢复的基础概念,备份策略的设计与实践,以及慧鱼备份技术的应用。通过分析备份类型、存储介质选择、备份工具以及备份与恢复策略的制定,文章提供了深入的技术见解和配置指导。同时,强调了数据恢复的重要性,探讨了数据恢复流程、策略以及慧鱼数据恢复工具的应用。此
【频谱分析与Time Gen:建立波形关系的新视角】:解锁频率世界的秘密
# 摘要
本文旨在探讨频谱分析的基础理论及Time Gen工具在该领域的应用。首先介绍频谱分析的基本概念和重要性,然后详细介绍Time Gen工具的功能和应用场景。文章进一步阐述频谱分析与Time Gen工具的理论结合,分析其在信号处理和时间序列分析中的作用。通过多个实践案例,本文展示了频谱分析与Time Gen工具相结合的高效性和实用性,并探讨了其在高级应用中的潜在方向和优势。本文为相关领域的研究人员和工程师
【微控制器编程】:零基础入门到编写你的首个AT89C516RD+程序
# 摘要
本文深入探讨了微控制器编程的基础知识和AT89C516RD+微控制器的高级应用。首先介绍了微控制器的基本概念、组成架构及其应用领域。随后,文章详细阐述了AT89C516RD+微控制器的硬件特性、引脚功能、电源和时钟管理。在软件开发环境方面,本文讲述了Keil uVision开发工具的安装和配置,以及编程语言的使用。接着,文章引导读者通过实例学习编写和调试AT89C516RD+的第一个程序,并探讨了微控制器在实践应用中的接口编程和中断驱动设计。最后,本文提供了高级编程技巧,包括实时操作系统的应用、模块集成、代码优化及安全性提升方法。整篇文章旨在为读者提供一个全面的微控制器编程学习路径,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )