【正则表达式与字符串】:打造复杂匹配模式的十大技巧
发布时间: 2024-09-20 10:10:27 阅读量: 119 订阅数: 55 

python使用正则表达式匹配字符串开头并打印示例

# 1. 正则表达式基础和字符串处理
正则表达式是处理字符串的强大工具,它通过定义一系列的字符和模式来匹配特定的文本片段。本章将介绍正则表达式的基础知识,包括其在字符串处理中的基本应用。
## 1.1 正则表达式的定义和用途
正则表达式(Regular Expression)是一种文本模式,包含普通字符(例如字母和数字)和特殊字符(称为“元字符”)。它用于检查一个字符串是否符合预定的格式,或者将字符串中符合模式的部分进行提取、替换等操作。
## 1.2 字符串处理的基本概念
字符串处理涉及许多操作,如搜索、替换、分割和连接等。正则表达式通过一套完整的规则和语法,使这些操作更加灵活和强大。它能够识别复杂的文本模式,是许多编程语言和文本处理工具的核心功能。
本章为正则表达式之旅奠定了基础,下一章将深入了解正则表达式的元素构成。
# 2. 掌握正则表达式的基本元素
### 2.1 字符类和特殊字符
#### 2.1.1 普通字符和特殊字符的使用
在正则表达式中,普通字符指的是任何未被定义为特殊意义的字符,它们通常代表字面意义上的字符。例如,在正则表达式中输入 "cat" 会匹配到含有 "cat" 这三个连续字符的文本。相较之下,特殊字符则具有特殊的功能和意义,例如点号(`.`)、星号(`*`)、加号(`+`)、问号(`?`)、方括号(`[]`)、花括号(`{}`)、圆括号(`()`)、竖线(`|`)等。
当我们需要匹配特殊字符本身时,必须对其进行转义。在大多数编程语言中,对特殊字符进行转义通常通过在其前面加上反斜杠(`\`)来实现。例如,要匹配文本中的点号,我们需要使用正则表达式 `\.`。
使用特殊字符时,应理解其语义和应用上下文,下面是一个表格,简述了一些常见特殊字符及其功能:
| 特殊字符 | 功能描述 |
|----------|---------|
| `.` | 匹配除换行符之外的任何单个字符 |
| `*` | 匹配前面的子表达式零次或多次 |
| `+` | 匹配前面的子表达式一次或多次 |
| `?` | 匹配前面的子表达式零次或一次 |
| `[]` | 字符集,匹配括号内任意单个字符 |
| `{}` | 量词,匹配前面的子表达式指定次数 |
| `()` | 分组,组合多个原子规则为一个整体 |
| `|` | 分支,匹配任一子表达式 |
#### 2.1.2 字符类的定义与应用
字符类是正则表达式中用于匹配一组字符集合的语法结构。它通过方括号 `[]` 来定义,可以匹配方括号内的任意单个字符。例如,正则表达式 `[aeiou]` 可以匹配任何一个英文元音字母。字符类可以包含范围,如 `[a-z]` 匹配从 'a' 到 'z' 的任意一个小写字母。
字符类还支持否定,即不匹配括号内任何字符。这通过在方括号的开头放置一个脱字符 `^` 来实现。比如,`[^0-9]` 将匹配任何非数字的字符。
这里有一个简单的例子,展示如何使用字符类来匹配电子邮件地址中的用户名部分(假设用户名只包含字母、数字、下划线和点号):
```regex
^[a-zA-Z0-9_.]+$
```
解释:
- `^`:匹配输入字符串的开始位置。
- `[a-zA-Z0-9_.]+`:匹配字母、数字、下划线和点号一次或多次。
- `$`:匹配输入字符串的结束位置。
字符类的灵活性在于我们可以根据需要组合不同的字符集,从而构建出复杂而精确的模式来匹配目标字符串。
### 2.2 量词和限定符
#### 2.2.1 量词的概念与类型
量词用来指定一个模式重复出现的次数,它是正则表达式中强大的组件之一。常见的量词包括 `*`、`+`、`?`、`{n}`、`{n,}` 和 `{n,m}`,其中 `n` 和 `m` 是非负整数。
- `*`:表示前一个元素可以出现零次或多次。
- `+`:表示前一个元素可以出现一次或多次。
- `?`:表示前一个元素可以出现零次或一次。
- `{n}`:表示恰好出现 `n` 次。
- `{n,}`:表示至少出现 `n` 次。
- `{n,m}`:表示至少出现 `n` 次,但不超过 `m` 次。
在使用量词时,可以对复杂结构进行简化。例如,假设我们要匹配一系列由连字符连接的数字,如 `1-2-3-4-5`,我们可以使用以下正则表达式:
```regex
\d+(?:-\d+)*
```
解释:
- `\d+`:匹配一个或多个数字。
- `(?:-\d+)*`:一个非捕获组,匹配零次或多次以连字符开始的数字序列。这里的括号是正则表达式中用来标记分组的,而 `?:` 是一个非捕获分组的开始,表示我们不希望将这部分匹配结果单独保存为一个组。
#### 2.2.2 限定符在字符串中的应用实例
限定符能够让我们更精确地控制模式匹配的数量,这在处理具有重复结构的数据时尤为有用。假设我们需要从日志文件中提取所有以 "ERROR:" 开头,后接任意数量的数字和冒号结束的行,我们可以使用如下正则表达式:
```regex
^ERROR:(\d+:+)*
```
解释:
- `^`:匹配行的开始。
- `ERROR:`:匹配 "ERROR:" 文本。
- `(\d+:+)*`:一个捕获组,匹配一个或多个数字后跟一个冒号,这个组可以重复零次或多次。
这样的表达式可以有效地匹配类似 "ERROR:123:456:789:" 或 "ERROR:" 的模式。量词与分组结合使用,可以帮助我们更细致地控制数据的结构和内容。
### 2.3 分组和捕获
#### 2.3.1 分组的作用和用法
分组允许我们在一个正则表达式中将多个元素组合在一起,并对它们进行重复、选择等操作。分组用圆括号 `()` 表示,并且可以包含任何可以放在正则表达式中的字符。分组是构建复杂正则表达式的基础。
使用分组的一个实际例子是,在处理具有相似结构但不同内容的字符串时,我们希望提取某些共通的部分。例如,在处理一系列网页链接时,我们可能想要提取每个链接的协议部分:
```regex
^((https?|ftp)://)
```
解释:
- `^`:匹配行的开始。
- `((https?|ftp)://)`:这是一个分组,其中包含另一个分组,用于匹配以 "http"、"https"、"ftp" 开头,后跟冒号和双斜杠的模式。
#### 2.3.2 捕获组的创建和引用技巧
捕获组不仅可以用于组合复杂的表达式,还可以用于提取和保存匹配的结果。通过在分组的开头添加括号 `()`,即可创建一个捕获组。在匹配过程中,捕获组所匹配到的内容会被保存,并且可以被后续引用。
例如,如果我们需要匹配一个日期格式,如 "YYYY-MM-DD" 并从中提取年、月、日,可以使用如下正则表达式:
```regex
(\d{4})-(\d{2})-(\d{2})
```
解释:
- `(\d{4})`:捕获组,匹配四个数字。
- `-`:匹配字面上的连字符。
- `(\d{2})`:捕获组,匹配两个数字。
在程序代码中,我们通常可以使用这些捕获组的引用(在某些语言中使用 `$1`、`$2` 等)来访问和操作这些匹配的内容。这样做不仅可以使代码更加简洁,还可以提高执行效率。
分组的一个

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python字符串处理全攻略》专栏深入探讨了Python中字符串处理的各个方面。从基础的分割、格式化和匹配技巧,到高级的切片优化、国际化和正则表达式应用,该专栏提供了全面的指南。它还涵盖了编码和解码的细微差别、性能优化策略、安全考虑因素和实战应用。通过深入了解Python字符串处理的方方面面,开发人员可以提高他们的编码效率,编写更简洁、健壮和高效的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
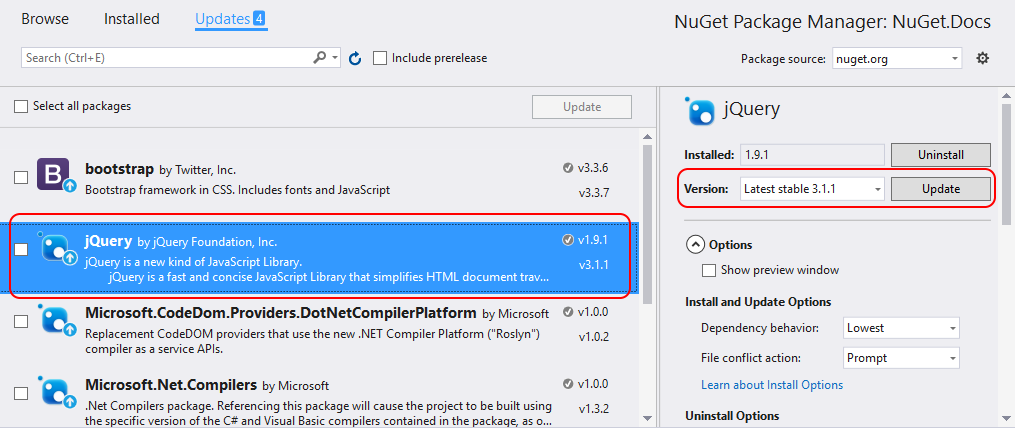
【VS2022升级全攻略】:全面破解.NET 4.0包依赖难题
# 摘要
本文对.NET 4.0包依赖问题进行了全面概述,并探讨了.NET框架升级的核心要素,包括框架的历史发展和包依赖问题的影响。文章详细分析了升级到VS2022的必要性,并提供了详细的升级步骤和注意事项。在升级后,本文着重讨论了VS2022中的包依赖管理新工具和方法,以及如何解决升级中遇到的问题,并对升级效果进行了评估。最后,本文展望了.NET框架的未来发
【ALU设计实战】:32位算术逻辑单元构建与优化技巧

# 摘要
算术逻辑单元(ALU)作为中央处理单元(CPU)的核心组成部分,在数字电路设计中起着至关重要的作用。本文首先概述了ALU的基本原理与功能,接着详细介绍32位ALU的设计基础,包括逻辑运算与算术运算单元的设计考量及其实现。文中还深入探讨了32位ALU的设计实践,如硬件描述语言(HDL)的实现、仿真验证、综合与优化等关
【网络效率提升实战】:TST性能优化实用指南

# 摘要
本文全面综述了TST性能优化的理论与实践,首先介绍了性能优化的重要性及基础理论,随后深入探讨了TST技术的工作原理和核心性能影响因素,包括数据传输速率、网络延迟、带宽限制和数据包处理流程。接着,文章重点讲解了TST性能优化的实际技巧,如流量管理、编码与压缩技术应用,以及TST配置与调优指南。通过案例分析,本文展示了TST在企业级网络效率优化中的实际应用和性能提升措施,并针对实战
【智能电网中的秘密武器】:揭秘输电线路模型的高级应用

# 摘要
本文详细介绍了智能电网中输电线路模型的重要性和基础理论,以及如何通过高级计算和实战演练来提升输电线路的性能和可靠性。文章首先概述了智能电网的基本概念,并强调了输电线路模型的重要性。接着,深入探讨了输电线路的物理构成、电气特性、数学表达和模拟仿真技术。文章进一步阐述了稳态和动态分析的计算方法,以及优化算法在输电线路模型中的应用。在实际应用方面,本文分析了实时监控、预测模型构建和维护管理策略。此外,探讨了当前技术面临的挑战和未来发展趋势,包括人
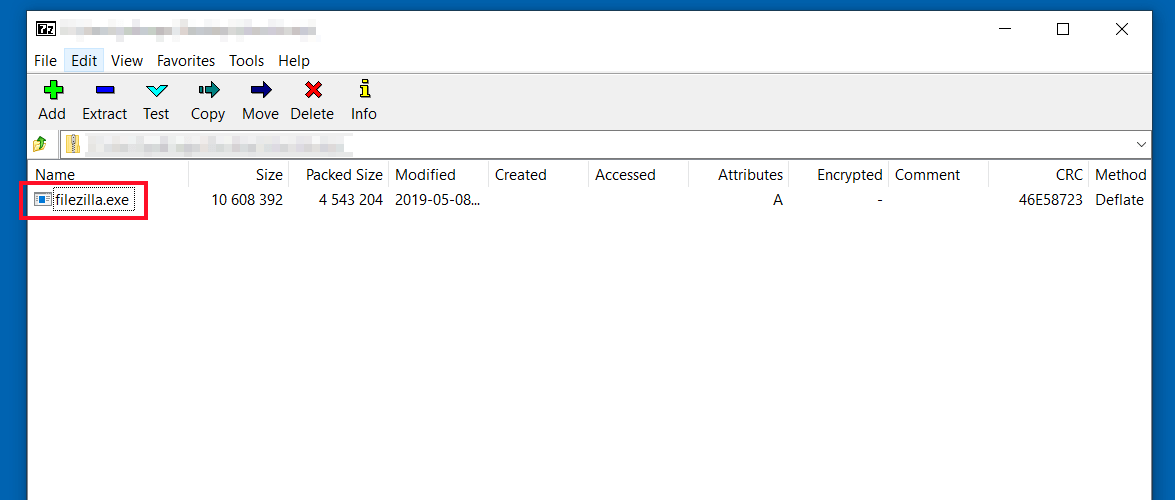
【扩展开发实战】:无名杀Windows版素材压缩包分析
# 摘要
本论文对无名杀Windows版素材压缩包进行了全面的概述和分析,涵盖了素材压缩包的结构、格式、数据提取技术、资源管理优化、安全性版权问题以及拓展开发与应用实例。研究指出,素材压缩包是游戏运行不可或缺的组件,其结构和格式的合理性直接影响到游戏性能和用户体验。文中详细分析了压缩算法的类型、标准规范以及文件编码的兼容性。此外,本文还探讨了高效的数据提取技
【软件测试终极指南】:10个上机练习题揭秘测试技术精髓
# 摘要
软件测试作为确保软件质量和性能的重要环节,在现代软件工程中占有核心地位。本文旨在探讨软件测试的基础知识、不同类型和方法论,以及测试用例的设计、执行和管理策略。文章从静态测试、动态测试、黑盒测试、白盒测试、自动化测试和手动测试等多个维度深入分析,强调了测试用例设计原则和测试数据准备的重要性。同时,本文也关注了软件测试的高级技术,如性能测试、安全测试以及移动
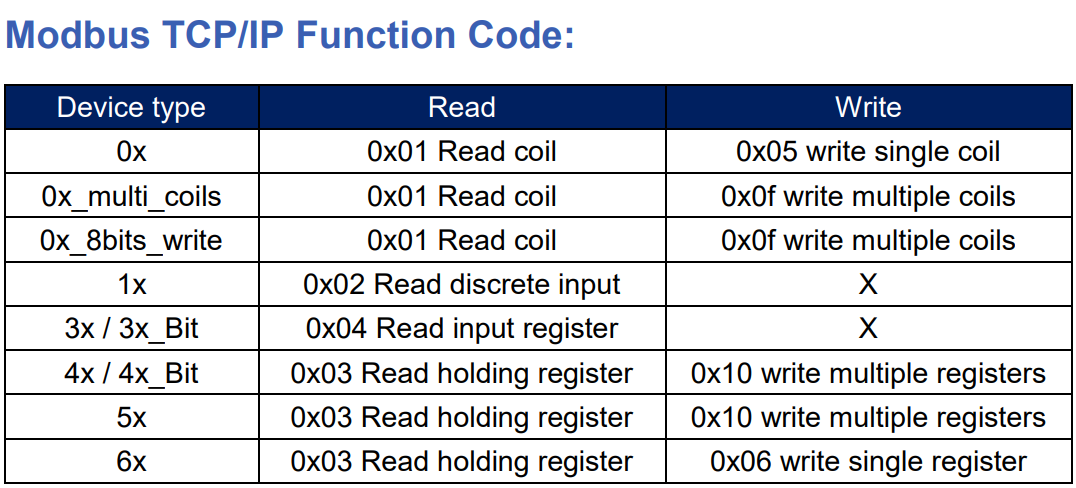
【NModbus库快速入门】:掌握基础通信与数据交换
# 摘要
本文全面介绍了NModbus库的特性和应用,旨在为开发者提供一个功能强大且易于使用的Modbus通信解决方案。首先,概述了NModbus库的基本概念及安装配置方法,接着详细解释了Modbus协议的基础知识以及如何利用NModbus库进行基础的读写操作。文章还深入探讨了在多设备环境中的通信管理,特殊数据类型处理以及如何定
单片机C51深度解读:10个案例深入理解程序设计
# 摘要
本文系统地介绍了基于C51单片机的编程及外围设备控制技术。首先概述了C51单片机的基础知识,然后详细阐述了C51编程的基础理论,包括语言基础、高级编程特性和内存管理。随后,文章深入探讨了单片机硬件接口操作,涵盖输入/输出端口编程、定时器/计数器编程和中断系统设计。在单片机外围设备控制方面,本文讲解了串行通信、ADC/DAC接口控制及显示设备与键盘接口的实现。最后,通过综合案例分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )