Kubernetes中Pod的创建与管理
发布时间: 2024-01-18 17:51:37 阅读量: 49 订阅数: 36 

Kubernetes集群搭建及其资源管理操作手册
# 1. 理解Pod
## 1.1 什么是Pod
在Kubernetes中,Pod是最小的部署单元,它由一个或多个容器组成,这些容器共享存储、网络和其他资源。每个Pod都有一个唯一的IP地址,并且它们可以相互通信。
## 1.2 Pod的特点和优势
Pod具有以下特点和优势:
- **共享网络和存储**:Pod中的多个容器可以共享网络和存储空间,方便它们之间进行通信和数据共享。
- **松耦合**:不同容器可以被设计成相对独立的功能单元,便于开发、部署和维护。
- **资源共享**:Pod中的容器可以共享资源,提高资源利用率和性能。
## 1.3 Pod在Kubernetes中的角色和作用
Pod在Kubernetes中扮演着重要的角色,主要作用包括:
- **部署单元**:Pod是Kubernetes中的最小部署单元,用于封装应用程序、存储资源、服务代理和一个独立的IP地址。
- **资源调度**:Kubernetes的调度器通过Pod的调度来决定在哪个节点上运行Pod中的容器。
- **服务发现**:Pod可以通过Kubernetes的service进行暴露和发现,使得不同Pod中的容器可以相互通信和协作。
以上是对第一章节内容的详细展示,请问接下来需要添加或修改什么内容呢?
# 2. 创建Pod
在Kubernetes中,Pod是最小的可调度和可管理的单元。一个Pod可以包含一个或多个容器,并且它们共享网络和存储资源。在本章节中,我们将讨论如何创建Pod以及常见的创建方式。
### 2.1 使用YAML文件创建Pod
创建Pod的常见方式是使用YAML文件描述Pod的配置信息,并通过kubectl命令将该YAML文件提交给Kubernetes集群。
下面是一个示例的Pod的YAML文件:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: container1
image: nginx:1.16
ports:
- containerPort: 80
- name: container2
image: busybox
command: ["/bin/sh", "-c", "while true; do echo Hello; sleep 10; done"]
```
上述YAML文件描述了一个包含两个容器的Pod。其中,`container1`使用`nginx:1.16`镜像,并将容器的80端口映射到宿主机。`container2`使用`busybox`镜像,并运行一个简单的循环命令。
要创建该Pod,可以执行以下命令:
```bash
$ kubectl create -f pod.yaml
```
执行完上述命令后,Kubernetes将会在集群中创建名为`my-pod`的Pod,并根据配置启动其中的容器。
### 2.2 使用命令行工具创建Pod
除了使用YAML文件外,还可以使用kubectl命令行工具直接创建Pod。
以下是一个示例的命令行创建Pod的命令:
```bash
$ kubectl run my-pod --image=nginx:1.16 --port=80
```
上述命令将在集群中创建一个名为`my-pod`的Pod,并使用`nginx:1.16`镜像启动该Pod的容器。容器的80端口将会被映射到该Pod的宿主机上。
### 2.3 创建包含多个容器的Pod
在某些情况下,我们可能需要创建一个包含多个容器的Pod,让它们能够共享网络和存储资源。
以下是一个示例的Pod的YAML文件,其中包含了两个容器:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: web
image: nginx:1.16
ports:
- containerPort: 80
- name: sidecar
image: busybox
command: ["/bin/sh", "-c", "while true; do echo Sidecar; sleep 5; done"]
```
上述YAML文件描述了一个名为`my-pod`的Pod,其中包含了`web`和`sidecar`两个容器。`web`容器使用`nginx:1.16`镜像启动一个Web服务器,而`sidecar`容器则运行一个简单的循环命令。
通过类似的命令行方式或者使用`kubectl create -f`命令,我们可以将上述YAML文件提交给Kubernetes集群,从而创建该Pod。
总结:
本章介绍了在Kubernetes中创建Pod的常见方式。我们可以使用YAML文件定义Pod的配置信息,也可以使用kubectl命令行工具直接创建Pod。此外,我们还看到了如何创建包含多个容器的Pod,以实现更复杂的应用部署。
下一章节将讨论如何管理已创建的Pod,包括健康检查、扩展缩容和存储网络管理等内容。
# 3. 管理Pod
Pod的管理是Kubernetes中非常重要的一部分,包括了对Pod的健康检查、故障恢复、扩展收缩以及对存储和网络的管理等。接下来我们将深入探讨Pod的管理相关知识。
#### 3.1 Pod的健康检查和故障恢复
在Kubernetes中,Pod的健康状态非常关键,Kubernetes通过三种方式来检查Pod的健康状况:livenessProbe、readinessProbe和startupProbe。
##### 3.1.1 livenessProbe
livenessProbe用于检测容器是否存活,如果容器存活,则Pod会继续运行;如果容器不健康,Kubernetes会根据容器的重启策略进行处理。下面是一个使用livenessProbe的Pod示例:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-probe
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
```
在上面的示例中,livenessProbe会每5秒执行一次命令"cat /tmp/healthy"来检测容器是否存活。
##### 3.1.2 readinessProbe
readinessProbe用于检测容器是否准备好接受流量,如果容器准备好,则可以接收流量;如果容器尚未准备好,Kubernetes会暂停流量的转发。下面是一个使用readinessProbe的Pod示例:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: readiness-probe
spec:
containers:
- name: readiness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- sleep 5; exit 1
readinessProbe:
exec:
command:
- ls
- /tmp/healthy
initialDelaySeconds: 3
periodSeconds: 3
```
在上面的示例中,readinessProbe会每3秒执行一次命令"ls /tmp/healthy"来检测容器是否准备好接受流量。
##### 3.1.3 startupProbe
startupProbe用于检测容器是否已经启动成功,如果容器启动成功,则Pod可以继续运行;如果容器启动失败,Kubernetes会根据容器的重启策略进行处理。需要注意的是,startupProbe是在Pod的初始启动阶段执行的,只会执行一次。下面是一个使用startupProbe的Pod示例:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: startup-probe
spec:
containers:
- name: startup
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- sleep 60
startupProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10
```
在上面的示例中,startupProbe会在容器启动后延迟10秒执行一次命令"cat /tmp/healthy"来检测容器是否启动成功。
#### 3.2 对Pod进行扩展和收缩
在Kubernetes中,可以通过控制器(如Deployment、ReplicaSet等)来对Pod进行扩展和收缩。通过修改副本数量的方式可以实现Pod的扩展和收缩。
```shell
# 扩展Pod
kubectl scale deployment/my-deployment --replicas=5
# 收缩Pod
kubectl scale deployment/my-deployment --replicas=3
```
通过上述命令可以轻松地对Deployment中的Pod数量进行扩展和收缩。
#### 3.3 管理Pod的存储和网络
对于Pod的存储管理,可以使用PersistentVolume(PV)和PersistentVolumeClaim(PVC)来实现Pod的持久化存储。而网络管理方面,可以通过Service、Ingress等资源来实现Pod的网络管理和流量控制。
以上就是关于Pod的管理的相关内容,包括了健康检查和故障恢复、扩展收缩以及存储和网络的管理。希望这些内容能够帮助你更好地理解和管理Kubernetes中的Pod。
# 4. Pod的调度与亲和性
在Kubernetes中,Pod的调度是指将Pod分配到合适的节点上运行的过程。调度器根据节点的资源情况和Pod的需求来选择一个节点,并将Pod绑定到该节点上。除了基本的调度机制外,Kubernetes还提供了亲和性策略,帮助用户更精确地控制Pod的调度行为。
#### 4.1 Pod调度过程解析
Pod的调度过程主要包括以下几个步骤:
1. 节点选择:调度器会根据节点的资源情况和Pod的需求,选择一个合适的节点。
2. 节点评分:调度器会为每个节点计算一个评分,评估节点是否适合运行该Pod。
3. 优选调度:调度器会根据节点评分选择最合适的节点作为目标节点。
4. 绑定Pod:调度器将Pod与目标节点进行绑定,并将Pod信息存储在etcd中。
#### 4.2 标签选择器和节点亲和性
在Kubernetes中,标签选择器和节点亲和性是用来控制Pod调度的重要手段。
- 标签选择器:用户可以为Pod和节点添加标签,然后使用标签选择器来定义Pod应该被调度到哪些节点上。标签选择器可以使用等式选择器、集合选择器、存在性选择器等多种方式。
- 节点亲和性:用户可以在Pod的亲和性策略中指定节点亲和性规则,以控制Pod被调度到具有特定标签的节点上。节点亲和性规则可以使用等式、集合、存在性等多种方式,并且可以定义多个规则。
#### 4.3 Pod亲和性和反亲和性的使用
Pod的亲和性和反亲和性是节点亲和性的一种表现形式。通过使用亲和性和反亲和性规则,用户可以将Pod调度到特定的节点上,或者将Pod与某些节点隔离开来。
Pod的亲和性规则可以采用以下方式之一:
```yaml
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: label-key
operator: In
values:
- label-value
```
Pod的反亲和性规则可以采用以下方式之一:
```yaml
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: label-key
operator: In
values:
- label-value
topologyKey: kubernetes.io/hostname
```
使用亲和性和反亲和性规则,可以精确控制Pod在集群中的调度行为,实现更好的资源管理和服务质量。
本章节对Pod的调度与亲和性进行了介绍,其中包括了Pod调度过程的解析,以及如何使用标签选择器和节点亲和性来控制Pod的调度行为。希望读者能够深入理解Pod的调度机制,并在实际场景中灵活运用。
# 5. 监控与日志
在Kubernetes中,监控Pod的健康状态以及收集和分析Pod的日志是非常重要的任务。本章将介绍一些常用的监控和日志相关的工具和技术。
### 5.1 监控Pod的健康状态
在Kubernetes中,我们可以使用以下方式来监控Pod的健康状态:
#### 5.1.1 使用Kubernetes自带的健康检查机制
Kubernetes提供了一套健康检查机制,可以检测容器的健康状态。具体包括:
- Liveness Probe: 用于检测容器是否存活,如果检测失败,则会重启容器。
- Readiness Probe: 用于检测容器是否准备好接收流量,如果检测失败,则不会将流量转发到该容器。
下面是一个使用Liveness Probe的示例:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
```
在上述示例中,Liveness Probe会每10秒钟发送一个HTTP GET请求到容器的`/health`路径,并在容器启动5秒钟之后开始进行检查。
#### 5.1.2 使用Prometheus进行监控
Prometheus是一个开源的监控系统,可以帮助我们收集和存储时间序列数据,并支持灵活的查询和可视化。可以使用Prometheus来监控Kubernetes集群中的Pod,具体步骤如下:
1. 部署Prometheus Server到Kubernetes集群中。
2. 配置Prometheus的监控规则,以收集Pod的指标数据。
3. 使用Grafana等工具进行数据可视化。
### 5.2 收集和分析Pod的日志
在Kubernetes中,我们可以使用以下方式来收集和分析Pod的日志:
#### 5.2.1 使用Kubernetes原生日志收集器
Kubernetes提供了一个原生的日志收集器,它会将Pod的日志输出到标准输出流(stdout)和标准错误流(stderr)。我们可以通过kubectl命令来查看Pod的日志:
```bash
kubectl logs <pod-name>
```
#### 5.2.2 使用ELK Stack进行日志收集和分析
ELK Stack是一个开源的日志管理平台,由Elasticsearch、Logstash和Kibana组成。可以使用ELK Stack来收集、存储和分析Kubernetes集群中的Pod日志:
1. 部署Elasticsearch和Kibana到Kubernetes集群中。
2. 配置Logstash来收集Pod的日志并将其发送到Elasticsearch中。
3. 在Kibana中进行日志的搜索、过滤和可视化。
### 5.3 使用Prometheus等工具进行监控
除了用于监控Pod健康状态的Prometheus之外,还有一些其他常用的监控工具和技术可以用于监控Kubernetes集群和Pod,包括:
- Grafana: 一个开源的可视化工具,可以与Prometheus等监控系统集成,用于创建仪表盘并可视化监控指标。
- cAdvisor: 一个用于监控容器的开源工具,可以提供容器的资源使用情况、性能指标等信息。
- Heapster: 一个开源的集群监控工具,用于收集并存储Kubernetes集群和Pod的监控数据。
以上是一些常用的监控和日志相关的工具和技术,可以根据需求选择合适的工具来监控和分析Kubernetes中的Pod。
# 6. 安全与最佳实践
在使用Kubernetes中的Pod时,安全性和最佳实践非常重要。本章节将介绍一些安全性最佳实践和指南,以确保您的Pod和集群的安全性。
#### 6.1 安全最佳实践
在创建和管理Pod时,以下是一些安全最佳实践的建议:
1. **使用最小化的特权**: 在创建Pod时,应尽量使用最小化的特权进行设置。仅授予所需的权限和能力,并且避免在容器中运行具有root权限的进程。
2. **限制资源使用**: 根据需要限制Pod的资源使用,这可以防止恶意行为或资源耗尽。
3. **容器镜像安全**: 使用受信任的容器镜像,并定期进行更新和扫描以确保没有已知的漏洞。
4. **网络隔离**: 对Pod进行网络隔离,限制其与其他Pod或集群外部通信的能力。这可以帮助防止未经授权的访问和网络攻击。
5. **访问控制**: 使用Kubernetes的访问控制机制,如RBAC(Role-Based Access Control),限制对Pod和集群资源的访问权限。
#### 6.2 Pod的安全策略
Kubernetes提供了一些安全策略的特性,可以用来加强对Pod的安全控制,例如:
1. **Pod Security Policies**: Pod Security Policies允许集群管理员定义和强制执行安全策略,确保只有满足特定要求的Pod才能够运行。
```yaml
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: restricted
spec:
privileged: false
seLinux:
rule: RunAsAny
runAsUser:
rule: MustRunAsNonRoot
fsGroup:
rule: RunAsAny
volumes:
- '*'
```
2. **网络策略**: 使用网络策略可以限制Pod之间的网络通信,以提供更加细粒度的安全控制。例如,可以定义只允许特定IP或标签的Pod进行通信。
```yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-specific-pods
spec:
podSelector:
matchLabels:
app: my-app
ingress:
- from:
- podSelector:
matchLabels:
app: allowed-app
- ipBlock:
cidr: 10.0.0.0/24
```
#### 6.3 最佳实践指南与建议
除了一些基本的安全最佳实践外,以下是一些使用Pod的最佳实践指南和建议:
1. **定期备份**: 定期备份您的Pod和集群数据,以防止数据丢失或意外的故障。
2. **日志监控**: 设置日志监控和集中式日志管理,以便追踪和分析Pod中的日志信息。
3. **定期更新**: 定期更新Pod中使用的容器镜像和Kubernetes版本,以获得最新的功能和安全补丁。
4. **异常处理**: 设置适当的异常处理和故障恢复机制,以确保Pod的健壮性和可用性。
这些安全性最佳实践和最佳实践指南将帮助您保护您的Pod和集群免受潜在的安全威胁,并确保它们以可靠和安全的方式运行。
希望这些安全与最佳实践的建议对您有所帮助,并能提升您在使用Kubernetes中的Pod时的安全性和效率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《K8S/Linux-kubernetes控制器-Statefulset详解》是一本全面介绍Kubernetes控制器Statefulset的专栏。该专栏将从Kubernetes的基础概念解析开始,逐步深入探索Kubernetes中的各个核心模块和功能。读者将了解到Kubernetes中Pod的创建与管理、容器调度算法、Service和Ingress、资源调度与亲和性规则、安全与认证机制等方面的详细解析。此外,专栏还讨论了监控与日志管理、存储管理与卷配置、配置管理与自动化部署、网络原理与解析、高可用与故障恢复、扩展性与自动伸缩、灰度发布与滚动升级等关键主题。而专栏的重点则是探讨Statefulset中的有状态应用管理与数据持久化、有序部署与服务发现、数据一致性与容错机制、自动扩展与水平伸缩等方面的知识。无论是初学者还是有经验的Kubernetes用户,都可以从本专栏中获取实用的技术知识和架构设计思路。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
无线通信的黄金法则:CSMA_CA与CSMA_CD的比较及实战应用

# 摘要
本文系统地探讨了无线通信中两种重要的载波侦听与冲突解决机制:CSMA/CA(载波侦听多路访问/碰撞避免)和CSMA/CD(载波侦听多路访问/碰撞检测)。文中首先介绍了CSMA的基本原理及这两种协议的工作流程和优劣势,并通过对比分析,深入探讨了它们在不同网络类型中的适用性。文章进一步通
Go语言实战提升秘籍:Web开发入门到精通

# 摘要
Go语言因其简洁、高效以及强大的并发处理能力,在Web开发领域得到了广泛应用。本文从基础概念到高级技巧,全面介绍了Go语言Web开发的核心技术和实践方法。文章首先回顾了Go语言的基础知识,然后深入解析了Go语言的Web开发框架和并发模型。接下来,文章探讨了Go语言Web开发实践基础,包括RES
【监控与维护】:确保CentOS 7 NTP服务的时钟同步稳定性
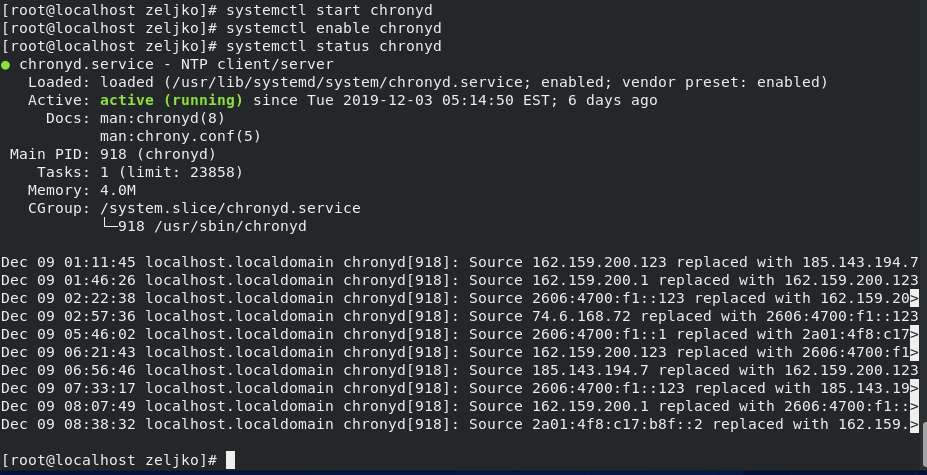
# 摘要
本文详细介绍了NTP(Network Time Protocol)服务的基本概念、作用以及在CentOS 7系统上的安装、配置和高级管理方法。文章首先概述了NTP服务的重要性及其对时间同步的作用,随后深入介绍了在CentOS 7上NTP服务的安装步骤、配置指南、启动验证,以及如何选择合适的时间服务器和进行性能优化。同时,本文还探讨了NTP服务在大规模环境中的应用,包括集
【5G网络故障诊断】:SCG辅站变更成功率优化案例全解析
# 摘要
随着5G网络的广泛应用,SCG辅站作为重要组成部分,其变更成功率直接影响网络性能和用户体验。本文首先概述了5G网络及SCG辅站的理论基础,探讨了SCG辅站变更的技术原理、触发条件、流程以及影响成功率的因素,包括无线环境、核心网设备性能、用户设备兼容性等。随后,文章着重分析了SCG辅站变更成功率优化实践,包括数据分析评估、策略制定实施以及效果验证。此外,本文还介绍了5
PWSCF环境变量设置秘籍:系统识别PWSCF的关键配置

# 摘要
本文全面阐述了PWSCF环境变量的基础概念、设置方法、高级配置技巧以及实践应用案例。首先介绍了PWSCF环境变量的基本作用和配置的重要性。随后,详细讲解了用户级与系统级环境变量的配置方法,包括命令行和配置文件的使用,以及环境变量的验证和故障排查。接着,探讨了环境变量的高级配
掌握STM32:JTAG与SWD调试接口深度对比与选择指南

# 摘要
随着嵌入式系统的发展,调试接口作为硬件与软件沟通的重要桥梁,其重要性日益凸显。本文首先概述了调试接口的定义及其在开发过程中的关键作用。随后,分别详细分析了JTAG与SWD两种常见调试接口的工作原理、硬件实现以及软件调试流程。在此基础上,本文对比了JTAG与SWD接口在性能、硬件资源消耗和应用场景上的差异,并提出了针对STM32微控制器的调试接口选型建议。最后,本文探讨
ACARS社区交流:打造爱好者网络

# 摘要
ACARS社区作为一个专注于ACARS技术的交流平台,旨在促进相关技术的传播和应用。本文首先介绍了ACARS社区的概述与理念,阐述了其存在的意义和目标。随后,详细解析了ACARS的技术基础,包括系统架构、通信协议、消息格式、数据传输机制以及系统的安全性和认证流程。接着,本文具体说明了ACARS社区的搭
Paho MQTT消息传递机制详解:保证消息送达的关键因素
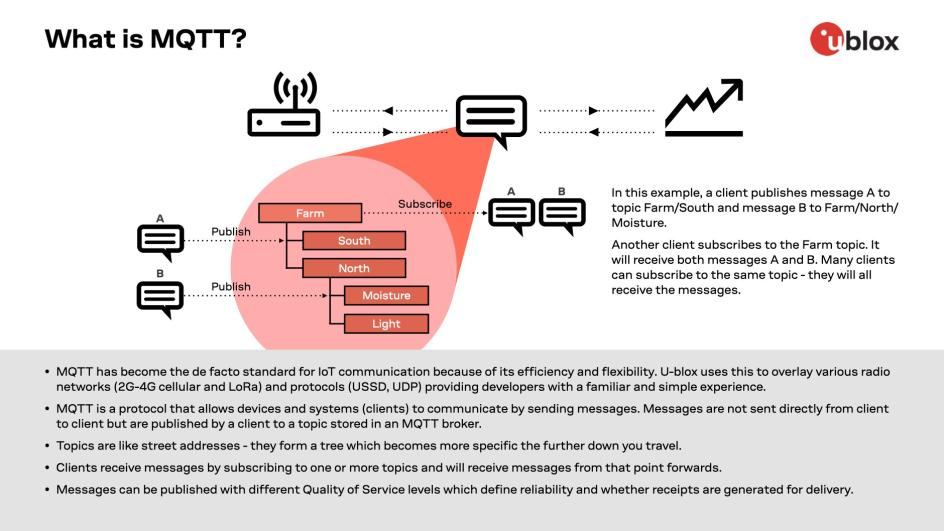
# 摘要
本文深入探讨了MQTT消息传递协议的核心概念、基础机制以及保证消息送达的关键因素。通过对MQTT的工作模式、QoS等级、连接和会话管理的解析,阐述了MQTT协议的高效消息传递能力。进一步分析了Paho MQTT客户端的性能优化、安全机制、故障排查和监控策略,并结合实践案例,如物联网应用和企业级集成,详细介绍了P
保护你的数据:揭秘微软文件共享协议的安全隐患及防护措施{安全篇

# 摘要
本文对微软文件共享协议进行了全面的探讨,从理论基础到安全漏洞,再到防御措施和实战演练,揭示了协议的工作原理、存在的安全威胁以及有效的防御技术。通过对安全漏洞实例的深入分析和对具体防御措施的讨论,本文提出了一个系统化的框架,旨在帮助IT专业人士理解和保护文件共享环境,确保网络数据的安全和完整性。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )