Kubernetes中Pod生命周期管理的最佳实践
发布时间: 2024-02-26 14:17:08 阅读量: 31 订阅数: 16 
# 1. 理解Pod生命周期
## 1.1 什么是Pod?
在Kubernetes中,Pod是最小的可部署单元,它可以包含一个或多个紧密关联的容器。Pod封装了应用程序的一个或多个容器、存储资源、独立的网络IP以及管理这些容器的策略。
## 1.2 Pod生命周期的各个阶段介绍
Pod的生命周期包括以下几个阶段:
- Pending(挂起):Pod被创建,但容器镜像尚未下载或Pod处于调度中。
- Running(运行中):Pod中的容器已被创建并正在运行。
- Succeeded(成功):Pod中的所有容器已成功完成任务。
- Failed(失败):Pod中的所有容器都即将失败或已经失败。
- Unknown(未知):无法获取Pod当前状态。
## 1.3 为什么Pod生命周期管理很重要?
Pod生命周期管理对于确保应用程序的可靠性、稳定性和高可用性至关重要。优化Pod的生命周期可以最大程度地提高系统的效率和资源利用率,同时可以更好地应对各种故障和异常情况。
接下来,我们将深入探讨如何最佳实践Pod的创建、调度、运行、监控、更新、扩展、终止和清理。
# 2. Pod的创建和调度
在Kubernetes中,Pod的创建和调度是非常重要的环节,它直接影响着应用程序的运行效果和性能。在本章中,我们将介绍一些关于Pod的创建和调度的最佳实践,以帮助您更好地管理Pod的生命周期。
### 2.1 创建Pod的最佳实践
在创建Pod时,需要考虑以下几点最佳实践:
#### a) 使用声明式Pod描述
使用YAML文件来描述Pod的规格是最佳实践之一。这样可以确保Pod的配置被版本控制并易于维护。
```yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx
image: nginx:latest
```
#### b) 避免在Pod中运行多个容器
尽量保持Pod中只运行一个容器,这样可以更好地管理容器的生命周期和资源。
#### c) 使用Init容器进行初始化
如果有初始化任务需要在启动容器之前完成,可以使用Init容器来实现。这有助于提高应用程序的可靠性和稳定性。
```yaml
spec:
initContainers:
- name: init-container
image: busybox
command: ['sh', '-c', 'echo "Initialization completed."']
```
### 2.2 优化Pod调度的策略
Pod的调度是指将Pod分配到集群的不同节点上以实现负载均衡和资源最大化利用。以下是一些优化Pod调度的策略:
#### a) 使用节点亲和性和反亲和性
通过节点亲和性和反亲和性来控制Pod被调度到特定节点的条件,以满足业务需求和资源限制。
```yaml
apiVersion: v1
kind: Pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
```
#### b) 设置Pod的优先级和预留资源
通过设置Pod的优先级和请求/限制资源来优化Pod的调度和资源分配,以确保关键应用程序能够获得足够的资源支持。
```yaml
apiVersion: v1
kind: Pod
spec:
priorityClassName: high-priority
containers:
- name: nginx
resources:
requests:
memory: "64Mi"
cpu: "250m"
```
### 2.3 使用资源限制来提高Pod的创建和调度效率
为Pod设置资源请求和限制是优化Pod创建和调度效率的重要手段。资源请求可以让调度器知道Pod所需的资源量,而资源限制可以避免Pod占用过多资源导致节点过载。
```yaml
apiVersion: v1
kind: Pod
spec:
containers:
- name: nginx
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
```
通过以上最佳实践和策略,您可以更好地管理和优化Pod的创建和调度过程,提高应用程序的运行效率和稳定性。
# 3. Pod的运行和监控
在Kubernetes中,Pod的运行和监控是保证应用程序正常运行的关键环节。本章将介绍如何监控和管理Pod的运行状态,以及处理可能出现的异常情况。
#### 3.1 Pod的运行状态和监控指标
首先,我们需要了解Pod可能处于的几种状态,以及如何通过Kubernetes提供的监控指标来查看Pod的健康状况。
常见的Pod状态包括:
- **Running**: 表示Pod正在正常运行。
- **Pending**: 表示Pod已经被创建,但容器尚未启动。
- **Succeeded**: 表示Pod中的所有容器已成功终止运行。
- **Failed**: 表示Pod中的某个容器运行失败。
监控指标通常包括:
- **CPU利用率**
- **内存利用率**
- **网络流量**
- **磁盘IO**
- **容器日志**
#### 3.2 如何监控和调整运行中的Pod
Kubernetes提供了多种方式来监控和调整运行中的Pod,例如:
- **kubectl describe pod <pod_name>**: 查看特定Pod的详细信息,包括事件和状态。
- **kubectl logs <pod_name>**: 查看Pod中容器的日志输出。
- **kubectl exec -it <pod_name> -- /bin/bash**: 进入Pod容器内部进行调试和查看状态。
- **Horizontal Pod Autoscaler (HPA)**: 根据实际负载情况自动调整Pod数量。
#### 3.3 日志管理和事件追踪技巧
在处理Pod的运行日志时,可以考虑以下技巧:
- **集中日志管理**: 使用日志聚合工具(如Elasticsearch、Fluentd、Kibana)集中管理Pod的日志。
- **日志轮转和压缩**: 配置Pod中容器的日志轮转和压缩策略,避免占用过多磁盘空间。
- **事件追踪**: 使用Kubernetes Events来追踪Pod的创建、更新和终止事件,及时发现潜在问题。
通过有效的监控和日志管理,可以更好地管理和维护Kubernetes集群中的Pod,确保应用程序稳定运行。
# 4. Pod的更新和扩展
更新和扩展是Pod生命周期管理中非常重要的环节,能够保证应用程序的持续可用性和扩展性。在Kubernetes中,可以通过滚动更新和水平扩展来实现Pod的更新和扩展。
#### 4.1 实现Pod的滚动更新
在Kubernetes中,通过更新Pod的定义或镜像版本来实现滚动更新。我们可以使用Deployment来管理Pod的更新过程,Deployment可以保证在进行更新时,始终保持指定数量的Pod处于可用状态,以确保应用程序的稳定性。
下面是一个基于Python Flask应用的Deployment示例:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v1
ports:
- containerPort: 5000
```
当我们需要更新Pod时,只需修改Deployment的定义中的镜像版本,Kubernetes将自动进行滚动更新,确保在更新过程中应用程序保持可用。
#### 4.2 使用水平扩展自动调整Pod数量
Kubernetes提供了水平扩展的能力,可以根据Pod的资源使用情况来自动调整Pod的数量,以适应流量的变化。我们可以通过Horizontal Pod Autoscaler(HPA)来实现自动扩展。
下面是一个基于CPU利用率来自动扩展Pod数量的HPA示例:
```yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 80
```
以上示例中,我们设置了在CPU利用率达到80%时,最大扩展到10个Pod,并保证至少有1个Pod可用。Kubernetes将根据实际的CPU利用率来自动调整Pod的数量,以满足应用程序的需求。
#### 4.3 考虑Pod伸缩和自动缩容的最佳实践
在实际应用中,需要考虑Pod的伸缩和自动缩容的最佳实践,包括设置合理的扩展触发条件、监控指标和扩展策略,以及避免因扩展过程中带来的不必要的成本增长或资源浪费。
综上所述,通过滚动更新和水平扩展,我们能够灵活管理Pod的更新和扩展,在保证应用程序稳定运行的同时,有效利用集群资源,提高应用程序的可用性和可扩展性。
# 5. Pod的终止和清理
在Kubernetes中,Pod的终止和清理是非常重要的,正确的操作可以保证系统的稳定性和资源利用率。本章将介绍如何安全地终止Pod、清理终止的Pod和避免因Pod终止而带来的影响和风险。
#### 5.1 安全地终止Pod的流程
在终止Pod之前,需要确保Pod中的应用程序能够优雅地关闭,释放资源以及处理未完成的请求。以下是安全地终止Pod的步骤示例:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-app
image: my-image
lifecycle:
preStop:
exec:
command: ["sh", "-c", "echo 'Shutting down gracefully'"]
```
- 代码解析:
- 在Pod的spec中定义了容器的声明周期(lifecycle)。
- 使用preStop钩子实现在容器停止之前执行特定的命令,这里是输出"Shutting down gracefully"。
- 通过preStop钩子可以让应用程序有机会进行清理工作,确保数据的完整性和稳定性。
#### 5.2 清理终止的Pod和资源残留
当Pod终止后,可能会留下一些残留的资源,如Pod的持久存储、网络连接等。为了避免资源的浪费和影响集群的正常运行,需要对这些残留资源进行清理。
```bash
kubectl delete pod my-pod --grace-period=0 --force
```
- 命令解析:
- 使用kubectl delete pod <pod-name> --grace-period=0 --force 命令可以立即删除Pod,不经过graceful shutdown阶段。
- 通过force参数强制删除Pod,确保Pod能够及时释放资源。
#### 5.3 避免Pod终止带来的影响和风险
在实际运维中,Pod的终止可能会对系统造成影响,如网络中断、服务不可用等。为了降低这些风险,可以采取以下策略:
- 使用ReplicaSet或Deployment来管理Pod,确保总是有指定数量的Pod运行。
- 设置合适的Pod的重启策略,如Never、OnFailure等。
- 定期检查Pod的状态,确保Pod正常运行,并及时处理异常情况。
通过以上方法,可以有效避免Pod终止带来的影响和风险,保障系统的稳定性和可靠性。
在Kubernetes中,Pod的终止和清理是一个重要的环节,合理的终止策略和资源清理可以提高系统的稳定性和资源利用效率。希望本章的内容能帮助您更好地管理Pod的生命周期。
# 6. 实例分析和案例分享
在本节中,我们将分享一些关于Kubernetes中Pod生命周期管理的成功案例,以及实例分析中的常见错误和解决方案。同时,我们会根据不同场景提出一些经验分享,帮助读者更好地理解和应用Pod生命周期管理的最佳实践。
#### 6.1 Kubernetes中Pod生命周期管理的成功案例
在实际的生产环境中,有许多公司和团队通过精细的Pod生命周期管理取得了良好的效果。以某互联网公司为例,他们在生产环境中实现了高可用性和灵活性的Pod管理,通过以下方式实现:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
```
这个成功案例中,该公司采用了Deployment控制器来管理Pod的生命周期,保证了Pod的高可用性和扩展性。同时,他们设置了3个副本,确保了服务的稳定性和负载均衡。这样的设计非常适合需要大规模部署和负载均衡的场景。
#### 6.2 实例分析:常见错误和解决方案
在实际应用中,有一些常见的错误可能会影响Pod的生命周期管理效果,比如资源配置不当、网络配置错误、镜像拉取问题等。针对这些问题,我们可以采取以下解决方案:
- 资源配置不当:及时调整Pod的资源请求和限制,避免资源不足或浪费的情况发生。
- 网络配置错误:检查Pod的网络策略和服务配置,确保网络通信正常,避免影响Pod的正常运行。
- 镜像拉取问题:优化镜像的构建和拉取流程,提高Pod的启动速度,避免因镜像问题导致Pod无法正常运行。
#### 6.3 不同场景下Pod生命周期管理的经验分享
针对不同场景下的Pod生命周期管理,我们需要考虑的因素也会有所不同。比如在高并发场景下,需要关注Pod的负载均衡和资源调度;在节假日流量波动大时,需要考虑Pod的自动扩展和收缩等。
因此,在实际应用中,我们需要根据具体场景灵活运用Pod生命周期管理的最佳实践,不断优化和调整,以实现更高效的运维管理和服务稳定性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Kubernetes中Pod的生命周期管理和健康检测,从理论到实战,从标签标识到最佳实践,涵盖了丰富的内容。通过介绍Pod的启动和终止最佳实践、节点选择器的部署管理、健康保证的方法和技巧,以及调度和自动修复策略等方面,帮助读者全面了解如何有效地管理和监控Pod的健康状态。此外,文章还探讨了监控和日志管理对Pod健康的影响,为读者提供了在微服务架构中实践的指引。无论是初学者还是经验丰富的架构师,都可以从中获益,加深对Kubernetes中Pod生命周期和健康检测的理解,提升在DevOps中的实战能力。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Standard.jar资源优化:压缩与性能提升的黄金法则

# 1. Standard.jar资源优化概述
在现代软件开发中,资源优化是提升应用性能和用户体验的重要手段之一。特别是在处理大型的Java应用程序包(如Standard.jar)时,合理的资源优化策略可以显著减少应用程序的启动时间、运行内存消耗,并增强其整体性能。本章旨在为读者提供一个关于Standard.jar资源优化的概览,并介绍后续章节中将详细讨论
MATLAB图像特征提取中的光流法与运动分析:深入理解与应用
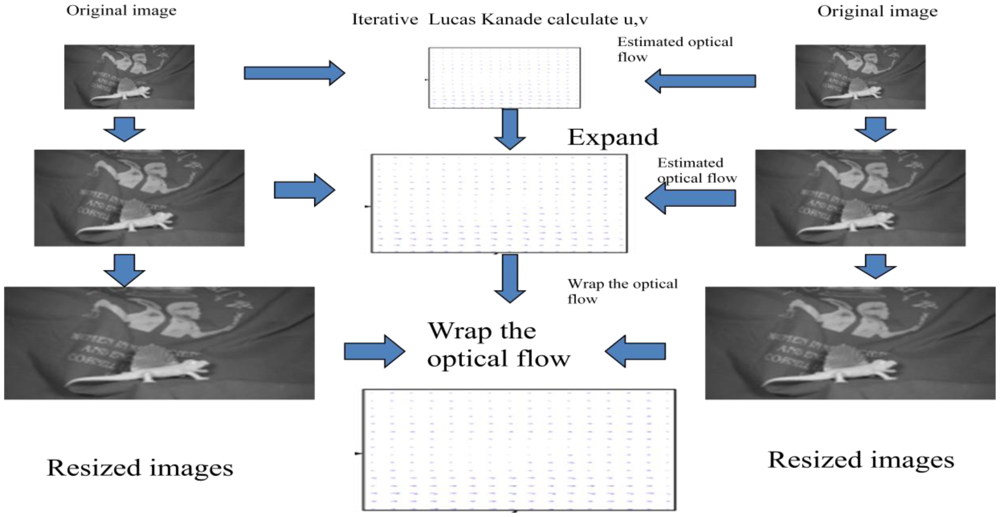
# 1. 光流法与运动分析概述
## 1.1 光流法与运动分析的重要性
在计算机视觉领域,光流法与运动分析是核心的技术之一,它们帮助我们理解和解释动态世界中的视觉信息。光流法是分析和解释动态图像序列中像素运动的基础,广泛应用于自动驾驶、视频监控、机器人导航等多个领域。运动分析则是从更宏观的角度,对视频中物体的运动模式进行解读
Python遗传算法的并行计算:提高性能的最新技术与实现指南
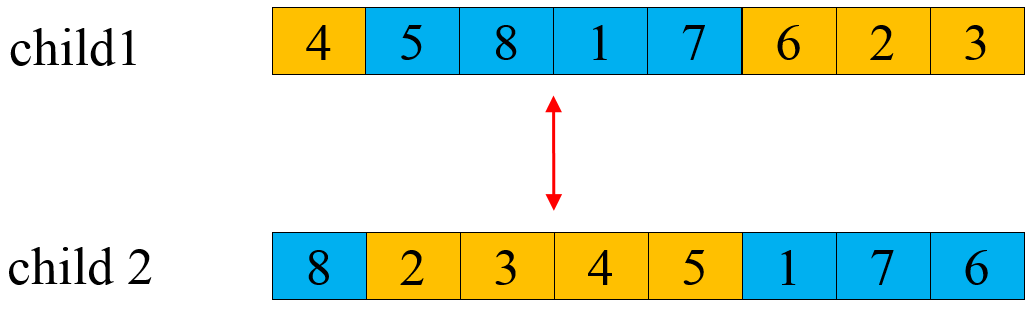
# 1. 遗传算法基础与并行计算概念
遗传算法是一种启发式搜索算法,模拟自然选择和遗传学原理,在计算机科学和优化领域中被广泛应用。这种算法在搜索空间中进行迭代,通过选择、交叉(杂交)和变异操作,逐步引导种群进化出适应环境的最优解。并行计算则是指使用多个计算资源同时解决计算问题的技术,它能显著缩短问题求解时间,提高计算效率。当遗传算法与并行计算结合时,可以处理更为复杂和大规模的优化问题,其并行化的核心是减少计算过程中的冗余和依赖,使得多个种群或子种群可以独
【MATLAB应用诊断与修复】:快速定位问题,轻松解决问题的终极工具
# 1. MATLAB的基本概念和使用环境
MATLAB,作为数学计算与仿真领域的一种高级语言,为用户提供了一个集数据分析、算法开发、绘图和数值计算等功能于一体的开发平台。本章将介绍MATLAB的基本概念、使用环境及其在工程应用中的地位。
## 1.1 MATLAB的起源与发展
MATLAB,全称为“Matrix Laboratory”,由美国MathWorks公司于1984年首次推出。它是一种面向科学和工程计算的高性能语言,支持矩阵运算、数据可视化、算法设计、用户界面构建等多方面任务。
## 1.2 MATLAB的安装与配置
安装MATLAB通常包括下载安装包、安装必要的工具箱以及环境
【数据并行技术详解】:Horovod的高效应用策略

# 1. 数据并行技术概述
在当今快速发展的数据时代,深度学习模型的规模和复杂性不断增长,使得单机训练变得不再可行。为了应对这一挑战,数据并行技术应运而生,它通过在多个计算节点之间分布数据,以加速模型的训练过程。数据并行不仅有助于缩短训练时间,还提高了计算资源的利用率,允许研究者和工程师处理更大规模的数据集和更复杂的模型。
## 2.
JSTL响应式Web设计实战:适配各种设备的网页构建秘籍
# 1. 响应式Web设计的理论基础
响应式Web设计是创建能够适应多种设备屏幕尺寸和分辨率的网站的方法。这不仅提升了用户体验,也为网站拥有者节省了维护多个版本网站的成本。理论基础部分首先将介绍Web设计中常用的术语和概念,例如:像素密度、视口(Viewport)、流式布局和媒体查询。紧接着,本章将探讨响应式设计的三个基本组成部分:弹性网格、灵活的图片以及媒体查询。最后,本章会对如何构建一个响应式网页进行初步的概述,为后续章节使用JSTL进行实践
MATLAB噪声过滤技术:条形码识别的清晰之道

# 1. MATLAB噪声过滤技术概述
在现代计算机视觉与图像处理领域中,噪声过滤是基础且至关重要的一个环节。图像噪声可能来源于多种因素,如传感器缺陷、传输干扰、或环境光照不均等,这些都可能对图像质量产生负面影响。MATLAB,作为一种广泛使用的数值计算和可视化平台,提供了丰富的工具箱和函数来处理这些噪声问题。在本章中,我们将概述MATLAB中噪声过滤技术的重要性,以及它在数字图像处理中
算法优化:MATLAB高级编程在热晕相位屏仿真中的应用(专家指南)

# 1. 热晕相位屏仿真基础与MATLAB入门
热晕相位屏仿真作为一种重要的光波前误差模拟方法,在光学设计与分析中发挥着关键作用。本章将介绍热晕相位屏仿真的基础概念,并引导读者入门MATLAB,为后续章节的深入学习打下坚实的基础。
## 1.1 热晕效应概述
热晕效应是指在高功率激光系统中,由于温度变化导致的介质折射率分
Git协作宝典:代码版本控制在团队中的高效应用
# 1. Git版本控制基础
## Git的基本概念与安装配置
Git是目前最流行的版本控制系统,它的核心思想是记录快照而非差异变化。在理解如何使用Git之前,我们需要熟悉一些基本概念,如仓库(repository)、提交(commit)、分支(branch)和合并(merge)。Git可以通过安装包或者通过包管理器进行安装,例如在Ubuntu系统上可以使用`sudo apt-get install git`
【异步任务处理方案】:手机端众筹网站后台任务高效管理
# 1. 异步任务处理概念与重要性
在当今的软件开发中,异步任务处理已经成为一项关键的技术实践,它不仅影响着应用的性能和可扩展性,还直接关联到用户体验的优化。理解异步任务处理的基本概念和它的重要性,对于开发者来说是必不可少的。
## 1.1 异步任务处理的基本概念
异步任务处理是指在不阻塞主线程的情况下执行任务的能力。这意味着,当一个长时间运行的操作发生时,系统不会暂停响应用户输入,而是让程序在后台处理这些任务
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )