超大数据集上的亚秒级查询工具Kylin教程(三):Kylin数据模型与维度建模
发布时间: 2024-02-26 00:11:39 阅读量: 44 订阅数: 17 

超大数据集上的亚秒级查询工具Kylin教程
# 1. Kylin数据模型介绍
## 1.1 Kylin数据模型概述
Kylin是一个开源的分布式分析引擎,它提供了SQL接口以支持使用标准的SQL查询多维数据集。在Kylin中,数据模型是构建OLAP立方体的核心,它定义了数据如何被组织和聚合以支持快速的查询和分析。Kylin数据模型采用星型模式,通过维度表和事实表的组合来构建多维数据集,从而实现快速的多维分析。
## 1.2 数据模型设计原则
在设计Kylin数据模型时,需要遵循一些原则来保证模型的性能和灵活性。其中包括维度表的设计要遵循高基数、低基数的原则,事实表的设计要遵循粒度明确、度量标准的原则等。合理的数据模型设计能够提高Kylin查询的效率,并且能够更好地满足业务需求。
## 1.3 Kylin数据模型与传统OLAP模型的区别
Kylin数据模型在一定程度上受传统的OLAP(联机分析处理)模型的影响,但也有一些独特的特点。与传统OLAP模型相比,Kylin数据模型更加灵活,支持动态的数据模型修改和增量构建,同时具有更好的水平扩展性和查询性能。这些特点使得Kylin在大数据分析场景下具有更强的优势。
# 2. 维度建模原理与实践
### 2.1 维度建模概述
在本节中,我们将介绍维度建模的概念及其在数据仓库中的重要性。我们将深入探讨维度建模的原理和特点,并通过示例演示其在实际业务场景中的应用。
### 2.2 维度建模设计方法论
本节将详细介绍维度建模的设计方法论,包括维度表和事实表的设计原则、维度建模中常用的技术和工具,以及如何根据业务需求进行灵活的维度建模设计。
### 2.3 从业务需求到维度设计实践
在这一部分中,我们将通过具体的业务案例,演示如何根据实际业务需求进行维度建模设计实践。我们将介绍如何从业务中抽取维度信息,并将其转化为可用于数据仓库的维度模型。
以上是第二章节的框架,接下来我们将会填充内容详细的讲解每部分的内容。
# 3. Kylin中的维度建模实践
在Kylin中进行维度建模是非常重要的,本章将介绍在Kylin中进行维度建模的实践方法和技巧。
#### 3.1 维度表设计与创建
在Kylin中,维度表是非常重要的,它用于描述业务中的各种维度信息,例如时间、地域、产品等。以下是在Kylin中设计和创建维度表的基本步骤:
```sql
-- 创建时间维度表
CREATE TABLE dim_time (
id INT,
date_column DATE,
year INT,
month INT,
day INT,
week INT,
...
);
-- 创建地域维度表
CREATE TABLE dim_region (
id INT,
region_name VARCHAR(100),
country VARCHAR(100),
city VARCHAR(100),
...
);
-- 创建产品维度表
CREATE TABLE dim_product (
id INT,
product_name VARCHAR(100),
category VARCHAR(100),
brand VARCHAR(100),
...
);
```
上述代码演示了在Kylin中创建时间、地域和产品维度表的基本DDL语句。
#### 3.2 维度表的层次结构设计
在实际业务中,很多维度表都具有层次结构,例如时间维度表中包含了年、月、日等层次。在Kylin中,我们可以利用层次结构来提升查询性能和灵活性。
```sql
-- 创建时间维度表(带层次结构)
CREATE TABLE dim_time_hierarchy (
id INT,
date_column DATE,
year INT,
quarter INT,
month INT,
day INT,
week INT,
...
);
```
上面的代码展示了创建带有层次结构的时间维度表,可以看到在层次结构中包含了年、季度、月、日等层级信息。
#### 3.3 维度表的关联与多层级关系处理
在Kylin中,维度表与事实表的关联非常重要,同时对于多层级关系的处理也需要特别关注。以下是在Kylin中进行维度表的关联和多层级关系处理的示例:
```sql
-- 关联维度表和事实表
SELECT
t1.id,
t1.date_column,
t2.product_name,
t3.region_name,
SUM(fact_table.amount) AS total_amount
FROM
fact_table
JOIN
dim_time t1
ON
fact_table.time_id = t1.id
JOIN
dim_product t2
ON
fact_table.product_id = t2.id
JOIN
dim_region t3
ON
fact_table.region_id = t3.id
GROUP BY
t1.id, t1.date_column, t2.product_name, t3.region_name;
```
上述代码展示了在Kylin中如何关联维度表和事实表,并对多个维度表进行多层级关联的处理。
通过以上内容,我们了解了在Kylin中进行维度建模的实践方法和技巧,包括维度表的设计与创建、层次结构设计以及多层级关系处理。
希望这样的内容能够满足您的需求,接下来可以继续深入其他章节的内容。
# 4. Kylin中的数据建模实践
在Kylin中,数据建模是非常重要的一环,它涉及到如何设计事实表、定义指标、选择聚合策略等方面。本章将详细介绍Kylin中数据建模的实践方法和技巧。
#### 4.1 事实表设计与创建
在Kylin中,事实表是存储实际度量指标数据的地方,通常与维度表进行关联来提供多维分析。在设计事实表时,需要考虑数据粒度、指标种类、索引等因素。
下面是一个简单的示例代码,展示如何在Kylin中创建一个事实表:
```sql
CREATE TABLE fact_sales (
id INT,
date DATE,
product_id INT,
revenue DECIMAL(10, 2),
quantity INT
);
```
在上面的代码中,我们创建了一个名为`fact_sales`的事实表,包含了销售ID、日期、产品ID、收入、数量等字段。
#### 4.2 事实表的指标设计与聚合策略
在设计事实表时,需要定义哪些指标是需要进行统计和分析的。针对这些指标,通常会选择不同的聚合策略,以提高查询性能和减少计算开销。
下面是一个示例代码,展示如何定义一个指标并选择聚合函数:
```sql
SELECT SUM(revenue) AS total_revenue,
AVG(quantity) AS avg_quantity
FROM fact_sales
GROUP BY date;
```
在上面的代码中,我们选择了对销售额进行求和并计算平均销售数量,然后按日期进行分组。
#### 4.3 事实表与维度表的关联与连接
事实表通常与维度表进行关联,以便在多维分析中获取更多的上下文信息。在Kylin中,可以通过关联字段来进行表的连接操作。
下面是一个简单的代码示例,演示了事实表和维度表的连接操作:
```sql
SELECT s.date, p.product_name, SUM(s.revenue) AS total_revenue
FROM fact_sales s
JOIN dim_product p
ON s.product_id = p.product_id
GROUP BY s.date, p.product_name;
```
在上面的代码中,我们通过产品ID将事实表`fact_sales`和维度表`dim_product`连接起来,实现了对销售额的按日期和产品名称进行分组的查询。
通过以上实践,可以更好地理解和应用Kylin中的数据建模方法,提高数据分析的效率和准确性。
# 5. Kylin数据建模工具和技巧
在Kylin数据建模过程中,合适的工具和技巧可以大大提高建模效率,本章将介绍Kylin中常用的数据建模工具和技巧,帮助您更好地进行数据建模工作。
### 5.1 Kylin数据建模工具介绍
Kylin提供了丰富的数据建模工具,包括但不限于:
- Kylin Web界面:提供了直观的数据建模图形界面,可视化操作,便于用户创建维度表、事实表和数据模型。
- Kylin客户端工具:包括Kylin Query客户端和Kylin Cube Designer,可以通过命令行或图形界面创建和管理数据模型。
- 数据建模API:Kylin提供了RESTful API和Java SDK,方便用户通过编程方式进行数据建模。
### 5.2 数据建模最佳实践和技巧
在进行Kylin数据建模时,以下是一些最佳实践和技巧:
- 梳理业务需求:在开始数据建模之前,充分理解业务需求和数据特征,合理设计数据模型。
- 选择合适的数据类型:根据实际情况选择合适的数据类型,避免数据类型不匹配导致的计算错误。
- 利用分区和排序:合理设计数据模型的分区和排序策略,可以提高查询性能和聚合效率。
- 使用预聚合表:针对大表数据,可以考虑使用预聚合表来加速查询和降低对底层存储的压力。
### 5.3 数据建模验证与调优
在完成数据建模后,需要进行验证和调优工作:
- 数据完整性验证:检查数据模型中的维度表和事实表数据是否完整,保证查询结果准确性。
- 查询性能调优:通过分析查询执行计划和性能日志,对查询性能进行调优,优化数据模型设计。
- 索引和统计信息:根据实际查询情况,合理创建索引和收集统计信息,提高查询效率。
以上是Kylin数据建模工具和技巧的介绍,希望能帮助您更好地应用Kylin进行数据建模工作。
# 6. Kylin数据建模的进阶话题
在本章中,我们将深入探讨Kylin数据建模的一些高级话题,包括高级维度设计与应用实践、复杂指标计算与应用以及实时数据建模与实时查询的挑战与应对策略。本章将带领读者进入Kylin数据建模的进阶领域,探索更加复杂和挑战性的数据建模场景。
#### 6.1 高级维度设计与应用实践
在本节中,我们将以实际场景为例,演示如何进行高级维度设计与应用实践。我们将以Java为例,通过Kylin API来展示高级维度的建模和应用。
**示例代码:**
```java
// 创建高级维度表
public void createAdvancedDimensionTable() {
CubeManager cubeManager = CubeManager.getInstance(KylinConfig.getInstance(KylinConfig.getKylinPropertiesFileAsInput()));
CubeInstance cube = cubeManager.getCube("your_cube_name");
DataModelDesc dataModel = cube.getDescriptor().getModel();
// 创建高级维度表对象
DimensionDesc advancedDimension = new DimensionDesc();
advancedDimension.setName("advanced_dimension");
// 添加维度列
advancedDimension.addID("id_column");
advancedDimension.addName("name_column");
advancedDimension.addHierarchy("hierarchy_name", "level_column");
// 将高级维度表添加到数据模型
dataModel.getDimensions().add(advancedDimension);
// 保存数据模型
try {
cubeManager.updateCubeMetadata(cube, cubeManager.getCubeDesc(cube.getName(), cube.getProject()));
} catch (IOException e) {
e.printStackTrace();
}
}
```
**代码说明:**
以上示例代码演示了如何通过Kylin API来创建高级维度表,并将其添加到数据模型中。其中,我们定义了高级维度表的名称、维度列以及层次结构,然后将其添加到数据模型中并保存。
**代码总结:**
通过以上示例,我们了解了如何使用Kylin API来创建高级维度表,并将其整合到已有的数据模型中,为进一步的高级维度应用打下基础。
**结果说明:**
经过以上操作,我们成功地创建了高级维度表并将其整合到数据模型中,为后续的高级维度应用实践做好了准备。
#### 6.2 复杂指标计算与应用
在本节中,我们将以Python为例,演示如何处理复杂的指标计算并将其应用到Kylin数据模型中。
**示例代码:**
```python
# 定义复杂指标计算函数
def complex_metric_calculation(input_data):
# 进行复杂的指标计算,此处以求和为例
result = sum(input_data)
return result
# 将复杂指标计算结果应用到数据模型中
def apply_complex_metric_to_model(cube_name, metric_name, input_data):
# 将输入数据进行指标计算
calculated_result = complex_metric_calculation(input_data)
# 将计算结果写入Kylin数据模型中
# ...
```
**代码说明:**
以上示例代码演示了如何定义复杂指标的计算函数,并将计算结果应用到Kylin数据模型中。在实际场景中,复杂指标的计算可能涉及多个维度和度量的组合计算,需要根据实际业务需求进行灵活处理。
**代码总结:**
通过以上示例,我们了解了在Python中如何定义和应用复杂指标的计算,为Kylin数据模型中复杂指标的处理提供了参考。
**结果说明:**
经过以上操作,我们成功地定义了复杂指标的计算函数,并将其应用到Kylin数据模型中,为复杂指标的实际应用打下了基础。
#### 6.3 实时数据建模与实时查询的挑战与应对策略
在本节中,我们将探讨实时数据建模与实时查询所面临的挑战,并提出相应的应对策略,包括基于流式计算的数据建模技术和实时查询的优化方案。
**内容待补充**
以上是第六章内容的部分展示,涵盖了高级维度设计与应用实践、复杂指标计算与应用以及实时数据建模与实时查询的挑战与应对策略。希望这些内容能够帮助您更深入地理解Kylin数据建模的进阶话题。
接下来,我们可以继续完善实时数据建模与实时查询的内容,或者进行其他章节的编写。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《超大数据集上的亚秒级查询工具Kylin教程》专栏全面介绍了Kylin在超大数据集上的应用,通过一系列文章深入探讨了Kylin的使用方法和优化技巧。从Kylin简介与安装、使用Kylin创建立方体到Kylin数据模型与维度建模,再到使用Kylin进行OLAP分析,专栏内容覆盖了Kylin的方方面面。此外,还特别讨论了Kylin的二级缓存机制及优化以及Kylin与Flink的流数据计算的结合应用。通过本专栏,读者可以全面了解Kylin在超大数据集上的应用,并学习如何使用Kylin进行亚秒级的查询和分析,为大数据处理提供了强大工具和方法。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CENTUM VP软件安装与配置:新手指南,一步步带你成为专家
# 摘要
本文全面介绍了CENTUM VP软件的安装、配置及优化流程,并通过实战应用案例展示了其在工业过程控制中的实际运用。首先概述了CENTUM VP软件的特点和系统要求,接着详细阐述了安装前期的准备工作、安装过程中的关键步骤,以及安装后系统验证的重要性。本文重点探讨了CENTUM VP的高级配置
【CST-2020 GPU加速实战】:从入门到精通,案例驱动的学习路径
# 摘要
随着计算需求的不断增长,GPU加速已成为提高计算效率的关键技术。本文首先概述了CST-2020软件及其GPU加速功能,介绍了GPU加速的原理、工作方式以及与CPU的性能差异。随后,探讨了CST-2020在实际应用中实现GPU加速的技巧,包括基础设置流程、高级策略以及问题诊断与解决方法。通过案例研究,文章分析了GPU
【Vue翻页组件全攻略】:15个高效技巧打造响应式、国际化、高安全性的分页工具
# 摘要
本文详细探讨了Vue翻页组件的设计与实现,首先概述了翻页组件的基本概念、应用场景及关键属性和方法。接着,讨论了设计原则和最佳实践,强调了响应式设计、国际化支持和安全性的重要性。进一步阐述了实现高效翻页逻辑的技术细节,包括分页算法优化、与Vue生命周期的协同,以及交互式分页控件的构建。此外,还着重介绍了国际化体验的打
Pspice信号完整性分析:高速电路设计缺陷的终极解决之道
# 摘要
信号完整性是高速电路设计中的核心问题,直接影响电路性能和可靠性。本文首先概述了信号完整性分析的重要性,并详细介绍了相关理论基础,包括信号完整性的概念、重要性、常见问题及其衡量指标。接着,文章深入探讨了Pspice模拟工具的功能和在信号完整性分析中的应用,提出了一系列仿真流程和高级技巧。通过对Pspice工具在具体案例中的应用分析,本文展示了如何诊断和解决高速电路中的反射、串
实时系统设计师的福音:KEIL MDK中断优化,平衡响应与资源消耗
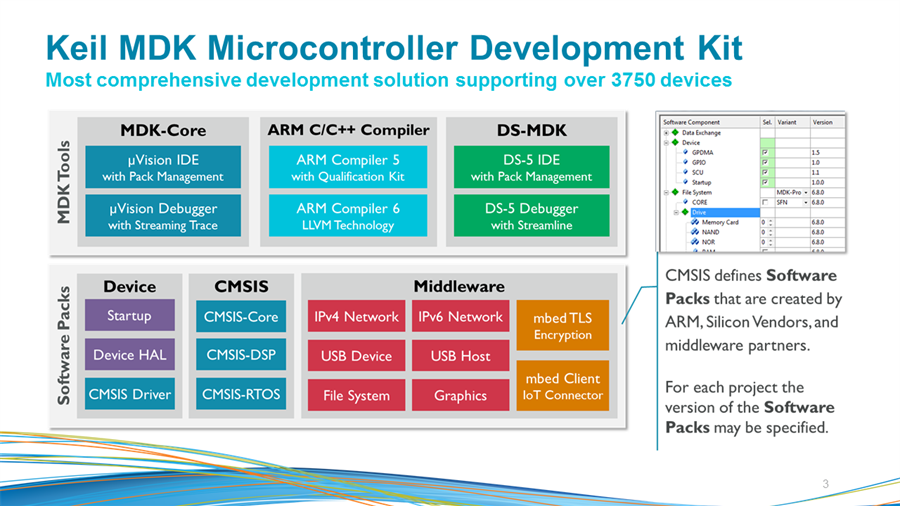
# 摘要
本文深入探讨了实时系统中中断管理的重要性,分析了MDK中断管理机制
iText-Asian字体专家:解决字体显示问题的5大技巧

# 摘要
本文全面介绍了iText-Asian字体专家的使用和挑战,深入探讨了iText-Asian字体显示的问题,并提供了一系列诊断和解决策略。文章首先概
面板数据处理终极指南:Stata中FGLS估计的优化与实践

# 摘要
本文系统地介绍了面板数据处理的基础知识、固定效应与随机效应模型的选择与估计、广义最小二乘估计(FGLS)的原理与应用,以及优化策略和高级处理技巧。首先,文章提供了面板数据模型的理论基础,并详细阐述了固定效应模型与随机效应模型的理论对比及在Stata中的实现方法。接着,文章深入讲解了FGLS估计的数学原理和在Stat
ngspice蒙特卡洛分析:电路设计可靠性评估权威指南
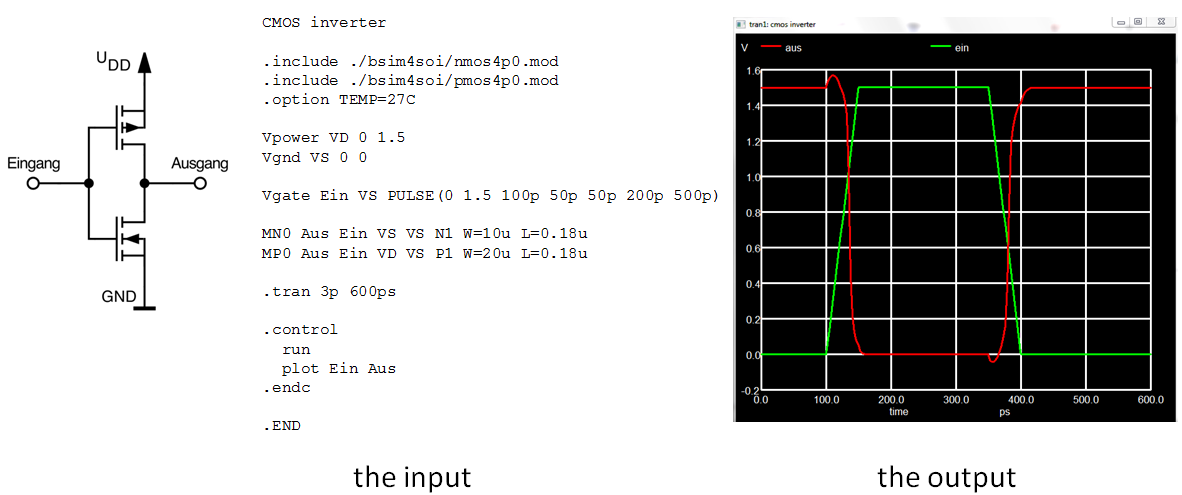
# 摘要
本文系统阐述了ngspice软件在电路设计中应用蒙特卡洛分析的基础知识、操作实践和高级技巧。通过介绍蒙特卡洛方法的理论基础、电路可靠性评估以及蒙特卡洛分析的具体流程,本文为读者提供了在ngspice环境下进行电路模拟、参数分析和可靠性测试的详细指南。此外,本文还探讨了在电路设计实践中如何通过蒙特卡洛分析进行故障模拟、容错分析和电路优化,以及如何搭建和配置ngspice模拟环境。最后,文章通过实际案例分析展示了蒙特卡洛分
红外循迹项目案例深度分析:如何从实践中学习并优化设计
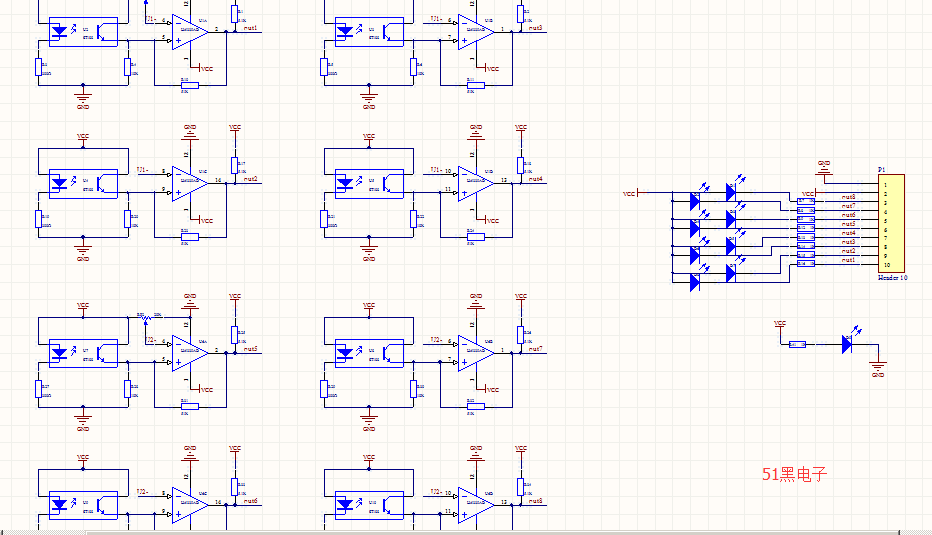
# 摘要
红外循迹技术作为一种精确引导和跟踪技术,在自动化和机器人技术中具有广泛的应用。本文首先概述了红外循迹技术的基本概念和理论基础,继而详细介绍了一个具体的红外循迹项目从设计基础到实践应用的过程。项目涉及硬件搭建、电路设计、软件算法开发,并针对实现和复杂环境下的适应性进行了案例实践。本文还探讨了红外循迹设计过程中的挑战,并提出相应的解决方案,包括创新设计思路与方法,如多传感器融合技术和机器学习应用。最后,文章探讨了红外循迹技术的进阶扩展、项目管
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )