【Python代码运行秘籍】:一键启动Python代码,告别繁琐调试
发布时间: 2024-06-18 10:28:16 阅读量: 83 订阅数: 37 

Python编程快速上手+让繁琐工作自动化_python_
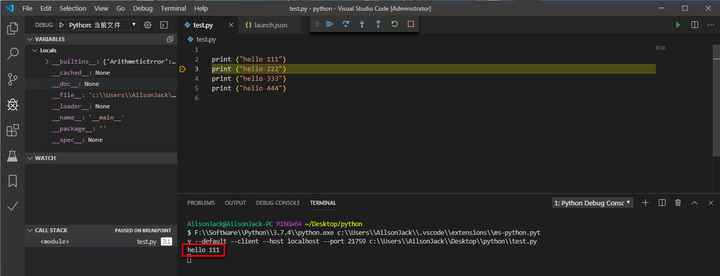
# 1. Python代码运行基础
Python代码运行基础是理解Python编程的关键。本章将介绍Python解释器的基本原理、代码执行流程以及常见的运行时错误。
### 1.1 Python解释器
Python解释器是一个程序,它将Python代码转换为机器可执行的字节码。字节码是一种中间语言,它由Python虚拟机(PVM)执行。PVM负责管理内存、执行指令和处理异常。
### 1.2 代码执行流程
Python代码的执行流程如下:
1. **词法分析:**解释器将源代码分解为称为标记的更小单元。
2. **语法分析:**解释器检查标记并将其解析为语法树,它表示代码的结构。
3. **字节码生成:**语法树被编译成字节码,它是一种针对PVM优化的中间语言。
4. **字节码执行:**PVM执行字节码,将Python代码转换为机器指令。
# 2. Python代码调试技巧
### 2.1 调试工具和方法
#### 2.1.1 Python调试器(pdb)
Python调试器(pdb)是一个交互式调试工具,允许开发者在代码执行过程中设置断点、检查变量、执行命令。
**使用pdb调试代码:**
1. 在要调试的代码行前添加`import pdb; pdb.set_trace()`。
2. 运行代码。
3. 当代码执行到断点时,将进入pdb交互式提示符。
4. 在提示符下,可以使用以下命令:
- `n`:继续执行代码,直到下一个断点或代码结束。
- `l`:列出当前代码行周围的代码。
- `p`:打印变量的值。
- `c`:继续执行代码,忽略所有断点。
**示例:**
```python
import pdb; pdb.set_trace()
def divide(a, b):
return a / b
result = divide(10, 0)
```
运行代码后,将进入pdb交互式提示符。使用`l`命令列出当前代码行周围的代码:
```
> l
4 import pdb; pdb.set_trace()
5
6 def divide(a, b):
7 return a / b
8
9 result = divide(10, 0)
10
```
使用`p`命令打印变量`a`和`b`的值:
```
> p a
10
> p b
0
```
使用`n`命令继续执行代码,将触发`ZeroDivisionError`异常。
#### 2.1.2 日志和跟踪
日志和跟踪是调试代码的另一种有用方法。它们允许开发者记录代码执行期间发生的事件和错误。
**使用日志记录调试代码:**
1. 导入`logging`模块。
2. 创建一个日志器并设置其级别。
3. 使用`logger.info()`、`logger.warning()`和`logger.error()`等方法记录消息。
**示例:**
```python
import logging
# 创建一个日志器并设置其级别为DEBUG
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
# 记录一条信息消息
logger.info("程序启动")
# 记录一条警告消息
logger.warning("内存不足")
# 记录一条错误消息
logger.error("程序崩溃")
```
**使用跟踪调试代码:**
1. 导入`traceback`模块。
2. 使用`traceback.print_exc()`函数打印异常的堆栈跟踪。
**示例:**
```python
import traceback
try:
# 尝试执行可能引发异常的代码
raise Exception("错误消息")
except Exception:
# 打印异常的堆栈跟踪
traceback.print_exc()
```
### 2.2 常见错误和解决方案
#### 2.2.1 语法错误
语法错误是代码中不符合Python语法规则的错误。这些错误通常很容易识别和修复。
**示例:**
```python
# 语法错误:缺少冒号
if x > 0
print("x是正数")
```
**解决方案:**
```python
# 修复后的代码:
if x > 0:
print("x是正数")
```
#### 2.2.2 运行时错误
运行时错误是在代码执行期间发生的错误。这些错误通常由无效的输入、内存问题或其他外部因素引起。
**示例:**
```python
# 运行时错误:除数为零
result = 10 / 0
```
**解决方案:**
```python
# 修复后的代码:
try:
result = 10 / 0
except ZeroDivisionError:
print("不能除以零")
```
#### 2.2.3 逻辑错误
逻辑错误是代码中导致不正确结果的错误。这些错误可能更难识别和修复。
**示例:**
```python
# 逻辑错误:使用错误的比较运算符
if x >= 0:
print("x是正数或零")
```
**解决方案:**
```python
# 修复后的代码:
if x > 0:
print("x是正数")
elif x == 0:
print("x是零")
```
# 3. Python代码优化实践
### 3.1 代码性能分析
#### 3.1.1 性能瓶颈识别
**代码分析工具:**
- **cProfile:**用于分析代码运行时间和函数调用次数。
- **line_profiler:**用于分析代码中每一行的执行时间。
- **memory_profiler:**用于分析代码的内存使用情况。
**代码分析步骤:**
1. 使用性能分析工具运行代码。
2. 识别性能瓶颈,即执行时间过长或内存占用过多的部分。
3. 分析代码逻辑,找出导致性能问题的根源。
**示例:**
```python
import cProfile
def fibonacci(n):
if n < 2:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
cProfile.run('fibonacci(30)')
```
**分析:**
cProfile输出显示fibonacci函数的执行时间过长。分析代码逻辑发现,该函数存在大量的重复计算,导致性能瓶颈。
#### 3.1.2 代码优化策略
**优化技术:**
- **缓存:**存储重复计算的结果,避免多次计算。
- **并行化:**将代码分解成多个并行执行的任务。
- **数据结构选择:**选择合适的的数据结构,如字典或集合,以提高查找效率。
- **算法优化:**使用更优的算法,如二分查找或动态规划。
**示例:**
```python
# 使用缓存优化fibonacci函数
fibonacci_cache = {}
def fibonacci(n):
if n < 2:
return n
elif n in fibonacci_cache:
return fibonacci_cache[n]
else:
result = fibonacci(n-1) + fibonacci(n-2)
fibonacci_cache[n] = result
return result
```
**分析:**
通过使用缓存,fibonacci函数可以避免重复计算,从而显著提高性能。
### 3.2 代码可读性和可维护性
#### 3.2.1 代码风格指南
**代码风格指南:**
- **PEP 8:**Python官方的代码风格指南,规定了缩进、命名约定、行长等规范。
- **公司内部指南:**一些公司制定了自己的代码风格指南,以确保代码的一致性。
**代码风格规范:**
- 使用4个空格缩进,避免使用制表符。
- 函数和类名使用驼峰式命名法,变量名使用下划线分隔单词。
- 行长限制在80个字符以内。
- 使用注释解释复杂代码逻辑。
**示例:**
```python
# 遵循PEP 8代码风格
def calculate_average(numbers):
"""计算一组数字的平均值。
Args:
numbers (list): 数字列表。
Returns:
float: 数字的平均值。
"""
total = sum(numbers)
count = len(numbers)
return total / count
```
**分析:**
该代码遵循PEP 8代码风格,使用正确的缩进、命名约定和注释,提高了代码的可读性和可维护性。
#### 3.2.2 单元测试和文档
**单元测试:**
- 单元测试用于测试代码的单个函数或类。
- 确保代码在各种输入和条件下都能正常工作。
**文档:**
- 文档解释代码的目的、用法和限制。
- 帮助其他开发者理解和维护代码。
**示例:**
```python
# 单元测试示例
import unittest
class TestAverage(unittest.TestCase):
def test_average(self):
self.assertEqual(calculate_average([1, 2, 3]), 2.0)
self.assertEqual(calculate_average([4, 5, 6]), 5.0)
```
**分析:**
单元测试验证了calculate_average函数在不同输入下的正确性。文档清楚地解释了函数的目的和用法,提高了代码的可维护性。
# 4. Python代码自动化部署
### 4.1 容器化和云部署
#### 4.1.1 Docker容器
Docker是一种容器化技术,它允许将应用程序及其依赖项打包到一个轻量级的、可移植的容器中。使用Docker,可以轻松地在不同的环境中部署和运行应用程序,而无需担心依赖关系或配置问题。
**Docker容器的优势:**
- **隔离性:**容器提供了一个隔离的环境,应用程序可以在其中运行,而不会影响主机或其他容器。
- **可移植性:**容器可以在不同的平台和环境中轻松部署,而无需修改应用程序代码。
- **一致性:**容器确保应用程序在所有环境中以相同的方式运行,从而提高了可靠性和可预测性。
**创建和使用Docker容器:**
1. **创建Dockerfile:**Dockerfile是一个文本文件,它指定了如何构建容器镜像。
2. **构建容器镜像:**使用`docker build`命令构建容器镜像,它将根据Dockerfile创建容器镜像。
3. **运行容器:**使用`docker run`命令运行容器,它将从容器镜像中创建并运行容器实例。
#### 4.1.2 云平台部署
云平台提供了一系列服务,可以简化Python代码的部署和管理。这些服务包括:
- **虚拟机(VM):**虚拟机是运行在云平台上的虚拟计算机,可以用来部署Python应用程序。
- **容器编排:**容器编排服务(如Kubernetes)可以管理和编排Docker容器,实现自动部署、扩展和故障恢复。
- **无服务器计算:**无服务器计算服务(如AWS Lambda)允许在无需管理基础设施的情况下运行代码。
**云平台部署的优势:**
- **可扩展性:**云平台可以轻松地扩展或缩减资源,以满足应用程序的需求。
- **可靠性:**云平台提供高可用性和冗余,以确保应用程序的正常运行时间。
- **成本效益:**云平台按需付费,只为使用的资源付费,从而降低了成本。
### 4.2 自动化构建和测试
#### 4.2.1 持续集成(CI)
持续集成(CI)是一种实践,它涉及到频繁地将代码更改集成到共享存储库中,并自动构建和测试代码。CI有助于及早发现错误,并确保代码始终处于可部署状态。
**CI工具:**
- **Jenkins:**一个流行的开源CI工具,提供广泛的插件和集成。
- **Travis CI:**一个托管的CI服务,支持多种语言和平台。
- **CircleCI:**另一个托管的CI服务,专注于速度和可扩展性。
**CI流程:**
1. **代码提交:**当开发人员将代码提交到存储库时,CI工具会触发构建和测试过程。
2. **构建:**CI工具使用Docker或其他容器化技术构建代码。
3. **测试:**CI工具运行单元测试和其他测试,以验证代码的正确性。
4. **报告:**CI工具生成报告,总结构建和测试结果。
#### 4.2.2 持续交付(CD)
持续交付(CD)是一种实践,它涉及到自动将代码更改部署到生产环境中。CD有助于缩短部署周期,并提高部署的可靠性。
**CD工具:**
- **Jenkins:**Jenkins也可以用于CD,它提供管道插件来定义和管理部署过程。
- **Spinnaker:**一个开源CD工具,专注于多云和混合云部署。
- **AWS CodeDeploy:**一个托管的CD服务,用于在AWS云平台上部署应用程序。
**CD流程:**
1. **触发部署:**当CI构建和测试成功后,CD工具会触发部署过程。
2. **部署准备:**CD工具准备部署环境,例如创建容器镜像或虚拟机。
3. **部署:**CD工具将代码更改部署到生产环境中。
4. **监控:**CD工具监控部署过程,并生成报告以总结部署结果。
# 5. Python代码实战应用**
**5.1 数据科学和机器学习**
Python在数据科学和机器学习领域扮演着至关重要的角色。其丰富的库和工具,如NumPy、Pandas和Scikit-learn,使得数据处理、模型训练和评估变得更加高效。
**5.1.1 数据预处理和特征工程**
数据预处理是机器学习过程中的关键步骤,它涉及到数据清洗、转换和标准化。Python中的Pandas库提供了强大的数据操作和处理功能。
```python
import pandas as pd
# 从CSV文件读取数据
df = pd.read_csv('data.csv')
# 缺失值处理
df.fillna(df.mean(), inplace=True)
# 特征缩放
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)
```
**5.1.2 机器学习模型训练和评估**
Python中的Scikit-learn库提供了广泛的机器学习算法,用于分类、回归和聚类等任务。
```python
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# 数据集分割
X_train, X_test, y_train, y_test = train_test_split(df_scaled, df['target'], test_size=0.2)
# 模型训练
model = LogisticRegression()
model.fit(X_train, y_train)
# 模型评估
score = model.score(X_test, y_test)
print(f'模型准确率:{score}')
```
**5.2 Web开发和后端服务**
Python在Web开发中也广泛应用,Flask和Django是两个流行的Web框架。
**5.2.1 Flask和Django框架**
Flask是一个轻量级的微框架,适合快速开发简单的Web应用程序。
```python
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/api/v1/users', methods=['GET'])
def get_users():
users = [{'id': 1, 'name': 'John Doe'}, {'id': 2, 'name': 'Jane Doe'}]
return jsonify(users)
```
Django是一个全栈Web框架,提供更全面的功能,包括模型、视图和模板。
```python
from django.db import models
class User(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=255)
def __str__(self):
return self.name
```
**5.2.2 RESTful API设计**
RESTful API遵循代表性状态转移(REST)架构风格,提供统一的接口和资源表示。
```python
from rest_framework import serializers, viewsets, routers
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ['id', 'name']
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
# 路由器
router = routers.DefaultRouter()
router.register('users', UserViewSet)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 专栏,您的 Python 编程知识库!本专栏涵盖了从初学者到高级用户的广泛主题,旨在帮助您掌握 Python 的方方面面。
从解决常见错误和内存泄漏到优化代码性能和故障排除,我们为您提供全面的指南。您还将深入了解 Python 的数据处理和分析功能,以及机器学习、云计算和分布式系统等高级概念。
此外,本专栏还提供了有关 Web 开发框架、RESTful API 设计、DevOps 实践和人工智能应用的实用见解。无论您是初学者还是经验丰富的开发人员,您都可以在此处找到提升 Python 技能所需的知识和技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【TLV3501电路性能优化攻略】:提升效率的5大实战策略
# 摘要
本文对TLV3501电路进行了详尽的探讨,包括其概述、性能指标、设计理论基础、调试技巧以及优化策略。首先介绍了TLV3501电路的基本结构和主要功能,接着从电路设计理论基础出发,详细分析了性能优化的关键理论依据,如信号完整性、电源管理和高频电路设计要点。随后,文章针对电源优化、信号链路优化、热管理和电磁
tc234故障诊断与排除:专业级故障处理速成课

# 摘要
本文旨在为技术人员提供关于tc234故障的全面诊断与排除指南。首先,概述了故障诊断的理论基础,包括根本原因分析与故障排除流程。随后,深入探讨了实时监控、日志分析、网络及性能工具在故障诊断中的实践应用。文章进一步阐述了自动化故障诊断工具的高级应用,如脚本编写和AI技术的运用。重点讨论了灾难恢复与备份策略的重要性,并提出了故障处理流程优化的策略。最后,展望了新兴技术在故障诊断中的应用前景,强调了人员技能
【Cortex-A启动过程全解析】:固件到操作系统的深层探索

# 摘要
本文全面探讨了Cortex-A处理器的启动序列,包括引导加载器的解析、操作系统的加载以及启动过程中的安全机制。首先概述了引导加载器的角色、功能和执行流程,并探讨了其自定义和安全性问题。接着介绍了操作系统加载前的准备、启动过程及调试优化方法。此外,本文详细分析了Cortex-A启动阶段的安全挑战和安全特性的实现,以及安全配置和管理。最后,本文提供了启动性能的优化
Matlab数据类型深入解析:矩阵和数组操作的终极指南
# 摘要
Matlab作为一种广泛使用的数值计算环境和编程语言,其数据类型是支持各种计算和工程应用的基础。本文全面介绍了Matlab的数据类型系统,包括基础的矩阵和数组操作,以及进阶的结构体、类、对象和多维数组处理。特别强调了数据类型转换与优化的策略,以及不同类型在数值计算、工程仿真、科研可视化以及机器学习和深度学习中的实际应用。通过对Matlab数据类型深入的
【ANSYS自动化脚本编写】:打造自动化流程的策略与实践

# 摘要
随着计算机辅助工程(CAE)的普及,ANSYS作为一款功能强大的仿真工具,在工程设计和分析中扮演着重要角色。本文旨在为读者提供一个关于ANSYS自动化脚本编写的全面指南。首先,文章简要概述了ANSYS自动化脚本的重要性及其基本概念。随后,详细介绍ANSYS脚本编写的基础知识
FEKO5.5教程进阶篇

# 摘要
FEKO5.5作为一种先进的电磁仿真软件,在工程实践中得到了广泛的应用。本文首先回顾了FEKO5.5的基础知识,然后深入探讨了其高级建模技术,包括复杂结构的建模方法、高级材料属性设置以及源和激励的高级配置。文章接着对FEKO5.5的后处理与分析技术进行了说明,重点介绍了数据后处理、优化与参数研究以及高级结果分析技术。之后,本文着重分析了FEKO5.5的并
效率倍增:安国量产工具多盘操作高级技巧
# 摘要
本文旨在详细介绍安国量产工具的基础操作和高级应用,探讨了多盘操作的理论基础和硬件接口兼容性,以及批量处理与自动化操作的最佳实践。文章深入分析了多盘复制、同步技术、读写速度提升方法和故障排除技巧,同时强调了数据安全、定期维护和安全漏洞修复的重要性。此外,本文还预测了安国量产工具的技术发展趋势,并讨论了行业趋势和社区合作对操作方法的潜在影响。通过这些内容,本文为相关领域专业人士提供了一份全面的技术指导和操
Matrix Maker 自定义脚本编写:中文版编程手册的精粹

# 摘要
Matrix Maker是一款功能强大的自定义脚本工具,提供了丰富的脚本语言基础和语法解析功能,支持面向对象编程,并包含高级功能如错误处理、模块化和性能优化等。本文详细介绍了Matrix Ma
安川 PLC CP-317安全功能详解

# 摘要
本论文详尽介绍了安川PLC CP-317的安全功能,首先概述了其安全功能的特点及意义。随后深入探讨了CP-317的基本安全机制,包括安全输入/输出的配置与应用、安全控制原理及其实施步骤,以及如何管理和配置不同安全区域和安全级别。第三章着重于安全编程实践,包括编程规则、安全问题的常见对策、安全功能的集成与测试以及案例分析。第四章讨论了CP-317安全功能的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )