实战技巧:如何使用MAE作为模型评估标准


基于万能逼近原理的自适应模糊控制算法在多自由度AUV运动控制中的应用与抗干扰补偿Simulink仿真研究,自适应模糊控制算法的万能逼近原理与多自由度AUV运动控制的抗干扰补偿技术-基于Simulin
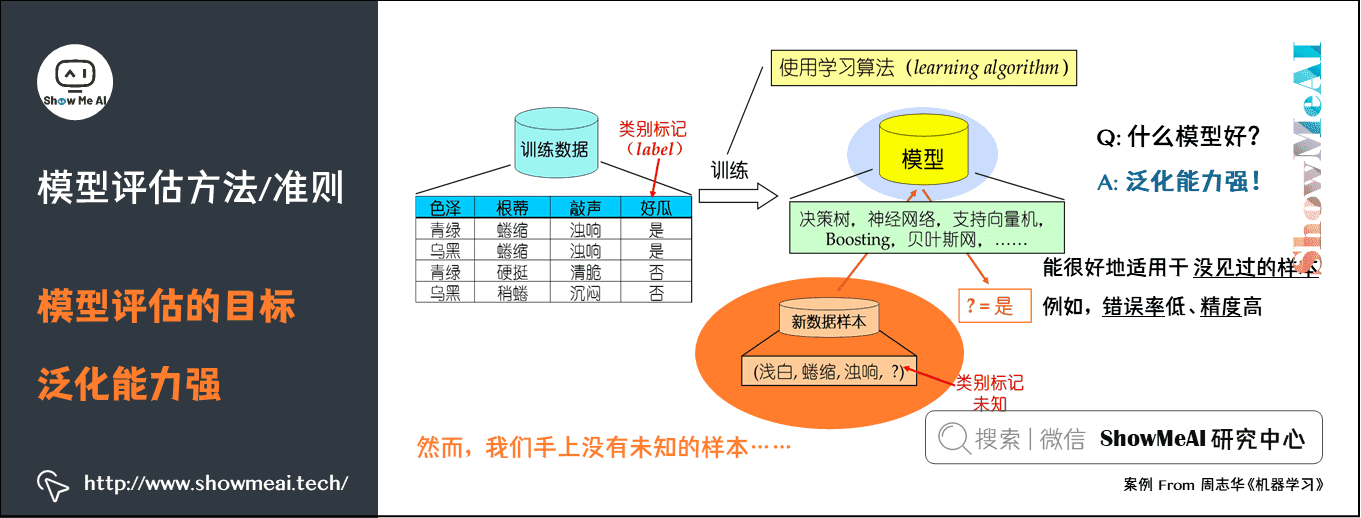
1. 模型评估标准MAE概述
在机器学习与数据分析的实践中,模型的评估标准是确保模型质量和可靠性的关键。MAE(Mean Absolute Error,平均绝对误差)作为一种常用的评估指标,其核心在于衡量模型预测值与真实值之间差异的绝对值的平均数。相比其他指标,MAE因其直观、易于理解和计算的特点,在不同的应用场景中广受欢迎。在本章中,我们将对MAE的基本概念进行介绍,并探讨其在模型评估中的重要性。通过了解MAE的基本原理,我们能够为接下来更深入的探讨MAE在理论基础、实际应用及优化策略等方面打下坚实的基础。
2. MAE的理论基础
2.1 误差度量方法综述
误差度量方法是评估模型预测准确性的关键手段,它们帮助我们了解模型与实际数据之间的差异。在构建机器学习模型时,使用适当的误差度量方法能够帮助我们更好地理解模型性能,并指导模型的优化。
2.1.1 误差度量的定义和重要性
误差度量可以理解为预测值和实际值之间差异的量化表达。它对模型的性能评价至关重要,因为:
- 目标明确:误差度量定义了模型优化的具体目标,使得模型训练有了明确的方向。
- 性能评估:通过计算误差度量值,可以对不同模型或模型在不同参数下的性能进行比较。
- 问题诊断:误差的分析可以帮助我们发现模型可能存在的问题,例如过拟合或欠拟合。
2.1.2 常见的误差度量方法对比
常见的误差度量方法包括均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)等。下面通过一个表格对比这些方法的优缺点:
| 方法 | 定义 | 优点 | 缺点 |
|---|---|---|---|
| MSE | $\frac{1}{N} \sum_{i=1}^{N}(y_i - \hat{y}_i)^2$ | 对大误差惩罚更大,反映了模型对异常值的敏感性 | 不易解释,对异常值敏感 |
| RMSE | $\sqrt{MSE}$ | 对误差进行开方,与预测值和实际值的量级相同,易解释 | 对异常值仍然敏感 |
| MAE | $\frac{1}{N} \sum_{i=1}^{N} | y_i - \hat{y}_i | $ |
2.2 MAE的定义和计算方式
2.2.1 MAE的数学表达式
MAE,即平均绝对误差,是真实值和预测值之间差的绝对值的平均数。其数学表达式为:
$$ MAE = \frac{1}{N} \sum_{i=1}^{N}|y_i - \hat{y}_i| $$
其中,$N$是样本数量,$y_i$是第$i$个样本的真实值,而$\hat{y}_i$是对应的预测值。
2.2.2 MAE与其他误差度量方法的比较
MAE与MSE和RMSE相比,对数据的异常值更为鲁棒,不会因为个别极端值的存在而产生较大的影响。这是因为MAE仅计算绝对值,而不进行平方运算。这一特点使得MAE在许多实际应用中更加适用,特别是在那些数据分布中存在异常值的场景。
2.3 MAE的优势与局限性
2.3.1 MAE的优势分析
MAE的主要优势在于其直观性和鲁棒性。由于MAE仅涉及绝对值运算,因此在解释模型的平均误差方面更加直观。同时,MAE对异常值的鲁棒性使得它在处理含有异常值的数据集时,能更好地反映模型的整体表现。
2.3.2 MAE在不同应用场景的局限性
尽管MAE具有许多优点,但在某些情况下也有局限性。例如,在需要对误差进行更细致划分的场景中,MAE可能不够敏感,不能反映误差的程度差异。此外,在时间序列预测中,由于MAE忽略了误差的方向性,它可能不足以捕捉到预测值与真实值之间可能出现的系统性偏差。
MAE在实际应用中可能需要结合其他指标来更全面地评估模型性能。接下来,我们将深入探讨MAE在不同模型中的应用,以及在实际案例中的实战技巧。
3. MAE在不同模型中的应用
3.1 线性回归中的MAE应用
3.1.1 线性回归的MAE计算实例
线性回归是一种基本的统计学方法,用于建立因变量(目标变量)和一个或多个自变量(解释变量)之间的关系模型。在评估线性回归模型的性能时,平均绝对误差(MAE)是一个直接而实用的指标。MAE计算的是模型预测值与实际观测值之间差值的绝对值的平均数。
以一个简单的线性回归模型为例,我们有一组房屋销售数据,其中包含房屋面积(平方米)和相应的价格(万元)。我们可以用线性回归来预测给定面积的房子的价格。接下来,我们将计算MAE来评估模型的预测准确性。
以下是使用Python的scikit-learn库来实现线性回归并计算MAE的过程:
- from sklearn.linear_model import LinearRegression
- from sklearn.metrics import mean_absolute_error
- import numpy as np
- # 假设X_train是训练数据中的房屋面积特征,y_train是对应的价格标签
- X_train = np.array([[20], [25], [30], [35], [40]])
- y_train = np.array([180, 230, 320, 380, 450])
- # 创建线性回归模型实例并训练
- model = LinearRegression()
- model.fit(X_train, y_train)
- # 使用模型进行预测
- predictions = model.predict(X_train)
- # 假设y_true是真实的房屋价格
- y_true = np.array([175, 240, 310, 365, 420])
- # 计算MAE
- mae = mean_absolute_error(y_true, predictions)
- print(f"The Mean Absolute Error of the model is: {mae}")
在这个例子中,我们首先导入了LinearRegression和mean_absolute_error函数,接着定义了训练数据和真实标签。之后我们训练了线性回归模型并用它进行了预测。最后,我们使用mean_absolute_error函数计算了MAE。
3.1.2 MAE在优化线性回归模型中的作用
MAE不仅用于评估模型的性能,而且在模型优化中起到了关键的作用。通过最小化MAE,我们可以对线性回归模型的参数进行调整,以提升预测的准确性。在实际应用中,我们通常会使用梯度下降或其他优化算法来找到最小化MAE的模型参数。
在scikit-learn中,我们可以通过设置SGDRegressor(随机梯度下降回归器)的损失函数为'huber'或'epsilon_insensitive',来实现MAE的优化。
例如:
- from sklearn.linear_model import SGDRegressor
- # 创建一个SGD回归器实例,使用MAE作为损失函数
- sgd_regressor = SGDRegressor(loss='epsilon_insensitive', max_iter=1000, tol=1e-3)
- # 训练模型
- sgd_regressor.fit(X_train, y_train)
- # 再次进行预测
- sgd_predictions = sgd_regressor.predict(X_train)
- # 计算优化后的MAE
- optimized_mae = mean_absolute_error(y_true, sgd_predictions)
- print(f"The Optimized Mean Absolute Error of the model is: {optimized_mae}")
在这个例子中,我们使用SGDReg

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【DCS系统霍尼韦尔PKS基础入门】:快速掌握操作界面与基本功能
【BIOS优化的艺术】:提升曙光服务器硬件性能的终极指南
【Qt信号与槽机制详解】:深入理解万年历功能逻辑处理
大数据智能应用
【华为OD机考编码实战攻略】:一小时内掌握真题编程技巧
【KUKA机器人通讯故障快速诊断】:5分钟内找出问题根源
【启动代码优化】:从STARTUp.A51开始,优化你的C51项目
MSRP协议深度讲解:多媒体通信的性能与安全并重策略
STM32F1xx HAL库高级技巧揭秘:掌握GPIO中断处理机制


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )