【C++效率秘籍】:提升编程速度的10个实用技巧与高级方法
发布时间: 2025-01-09 15:49:19 阅读量: 6 订阅数: 7 

036GraphTheory(图论) matlab代码.rar

# 摘要
C++作为高级编程语言,在编程效率和性能优化方面具有显著优势。本文着重探讨了C++编程效率的重要性,从基础优化技巧到中高级编程方法,深入讲解了多种提升代码质量与性能的技术手段。涵盖代码风格、内存管理、算法选择、模板编程、多线程实践、性能分析以及现代C++特性的应用。此外,文章还研究了C++项目实践中的案例分析,提供了针对性能瓶颈的解决方案,并对跨平台开发优化和未来C++效率提升的趋势进行了展望。
# 关键字
C++编程效率;代码优化;内存管理;多线程编程;性能分析;现代C++特性
参考资源链接:[C++编程学习:郑莉版《C++语言程序设计》课后习题解析](https://wenku.csdn.net/doc/4u9i7rnsi4?spm=1055.2635.3001.10343)
# 1. C++编程效率的重要性
## 1.1 效率在软件开发中的地位
在当今的软件开发环境中,编程效率是衡量一个项目是否成功的关键指标之一。提高效率不仅意味着缩短开发周期,降低成本,也代表着能够更快地响应市场变化,提供稳定且高性能的产品。
## 1.2 C++在效率提升中的角色
C++作为一种静态类型、编译式语言,以其高性能、可预测的运行时行为,在系统编程和性能敏感领域享有盛誉。然而,由于其复杂性,C++的效率提升既具有挑战性也拥有巨大潜力。
## 1.3 提升C++编程效率的方法
提升C++编程效率的方法多样,包括但不限于采用高效的设计模式、利用现代C++的新特性、性能分析与调优等。在后续章节中,我们将详细探讨这些方法,帮助读者提升在实际开发中的编程效率。
# 2. C++基础优化技巧
## 2.1 代码风格与规范
### 2.1.1 遵循C++编程规范
C++是一门具有强大表达能力和灵活性的编程语言,同时也因此在编码过程中容易出现各种问题。良好的代码风格和规范是保证项目质量和后续维护效率的基础。遵循C++编程规范可以:
- 提高代码的可读性和可维护性。
- 减少由于代码风格不一致带来的额外沟通成本。
- 帮助避免一些常见的编程错误。
例如,命名规范是其中一个重要方面,变量、函数、类等的命名都应该遵循一定的规则,这样可以在很大程度上提升代码的清晰度。C++标准库中的命名就是很好的范例。
```cpp
// 示例:合理命名
int countStudents(vector<string>& students) {
int count = 0;
for (auto const& student : students) {
if (isStudentActive(student)) {
++count;
}
}
return count;
}
```
在上述代码中,我们遵循了以下规范:
- 使用有意义的变量名。
- 函数命名采用动词开头,明确其功能。
### 2.1.2 命名约定和代码清晰度
在代码清晰度方面,除了命名之外,合理的代码结构和注释也非常重要。以下是一些推荐的实践方法:
- 将代码分解为小的、自包含的函数,每个函数实现一个简单的功能。
- 使用空行和缩进来清晰地区分代码块。
- 适时添加注释,解释复杂的逻辑或非显而易见的代码段。
```cpp
// 示例:代码清晰度的优化
// 计算数组中的正数和
int calculateSumOfPositiveNumbers(const vector<int>& data) {
int sum = 0;
for (int num : data) {
if (num > 0) { // 只累加正数
sum += num;
}
}
return sum;
}
```
在代码块中加入注释不仅能够解释当前的逻辑,还能帮助他人快速理解代码的作用,尤其在复杂的业务逻辑中这一点显得尤为重要。
## 2.2 内存管理优化
### 2.2.1 智能指针的使用
内存泄漏是C++程序中常见的问题,这通常是由于手动管理内存时忘记释放资源造成的。C++11引入了智能指针(如`std::unique_ptr`, `std::shared_ptr`),以自动管理资源,从而减少内存泄漏的风险。
使用智能指针可以自动释放资源,即使是异常发生时也能保证资源的正确释放。
```cpp
#include <memory>
void useSmartPointers() {
// 使用std::unique_ptr管理资源
std::unique_ptr<int[]> buffer(new int[1024]);
// ... 使用buffer进行操作 ...
// 当unique_ptr超出作用域时,自动释放资源
}
void useSharedPointers() {
// 使用std::shared_ptr管理资源
std::shared_ptr<vector<int>> data = std::make_shared<vector<int>>();
// ... 使用data进行操作 ...
// 当最后一个shared_ptr析构时,自动释放资源
}
```
智能指针通过引用计数(`std::shared_ptr`)或自定义删除器(`std::unique_ptr`)管理内存,消除了手动删除内存的需要。使用智能指针可以在不牺牲性能的情况下,有效提升代码的安全性和可维护性。
### 2.2.2 内存池的实现与应用
内存池是一种提高内存分配效率和减少内存碎片的技术。它预先从堆上分配一大块内存,然后将这个大块内存切割成固定大小的小块,按需分配给对象使用。
实现内存池的好处包括:
- 减少内存分配和释放的次数,提高性能。
- 减少内存碎片化。
内存池的实现相对复杂,这里只提供一个简化的例子:
```cpp
#include <iostream>
#include <vector>
class MemoryPool {
private:
const size_t m_chunkSize;
size_t m_startPos;
std::vector<char> m_buffer;
public:
MemoryPool(size_t chunkSize, size_t poolSize)
: m_chunkSize(chunkSize), m_startPos(0), m_buffer(poolSize) {}
void* alloc() {
if (m_startPos + m_chunkSize > m_buffer.size()) {
throw std::bad_alloc();
}
void* ret = &m_buffer[m_startPos];
m_startPos += m_chunkSize;
return ret;
}
void free(void*) {
// 不真正释放内存,仅回收内存池中对应部分
}
};
int main() {
MemoryPool pool(sizeof(int), 1024);
for (int i = 0; i < 10; ++i) {
int* p = static_cast<int*>(pool.alloc());
*p = i;
std::cout << *p << std::endl;
}
}
```
内存池的实现需要考虑对象的生命周期和内存的回收策略,但上述简化的内存池只负责分配,不负责释放内存,实际应用中需结合具体场景设计。
## 2.3 算法与数据结构的选择
### 2.3.1 算法复杂度的考量
在C++编程中,合理选择和实现算法对于性能至关重要。算法的复杂度分析,尤其是时间复杂度和空间复杂度,可以指导我们评估算法的效率。
- 时间复杂度描述了算法执行时间随输入大小增加的增长趋势。
- 空间复杂度描述了算法执行过程中所需的额外空间大小。
例如,对数组进行排序时,快速排序(平均时间复杂度`O(nlogn)`)比冒泡排序(时间复杂度`O(n^2)`)要高效得多。
```cpp
// 示例:不同排序算法的选择对性能的影响
#include <vector>
#include <algorithm> // 标准库中的排序算法
int main() {
std::vector<int> data(1000000);
// 快速排序
std::sort(data.begin(), data.end());
// ... 其他操作 ...
}
```
快速排序的`std::sort`作为C++标准库的一部分,是许多内置数据结构的默认排序方式,它经过高度优化,效率极高。
### 2.3.2 标准库容器的高效使用
C++标准库提供了丰富的容器,如`vector`, `list`, `map`, `set`等。这些容器在设计时已经考虑了性能优化,能够满足不同场景的需求。
- `vector`适合频繁随机访问的场景。
- `list`适用于频繁的插入和删除操作。
- `map`和`set`基于红黑树实现,适合有序存储和查找。
例如,当需要频繁插入和删除数据时,使用`list`通常比使用`vector`更为高效,因为`vector`在插入和删除时可能需要移动大量的元素。
```cpp
#include <list>
int main() {
std::list<int> numbers;
numbers.push_back(1);
numbers.push_back(2);
numbers.push_back(3);
// 直接在列表中间插入新元素
auto it = numbers.begin();
std::advance(it, 1);
numbers.insert(it, 25);
// 删除元素也很快,不需要移动大量元素
numbers.erase(it);
// ... 其他操作 ...
}
```
在使用标准库容器时,选择合适的容器类型以及了解其性能特点,可以帮助我们编写出更高效的代码。
在下一章节,我们将深入探讨C++的中高级编程技巧,包括模板编程、多线程编程,以及性能分析与调优。这将帮助读者更上一层楼,掌握更为高级的优化方法。
# 3. C++中高级编程技巧
## 3.1 模板编程与泛型设计
### 3.1.1 函数模板与类模板的应用
函数模板和类模板是C++泛型编程的基石,允许开发者编写与数据类型无关的代码,从而提高代码复用性和效率。泛型代码通过模板定义,使得同一套逻辑可以应用于不同的数据类型,这在标准库中尤为常见,如`std::vector`和`std::sort`函数。
```cpp
template <typename T>
T max(T a, T b) {
return a > b ? a : b;
}
template <typename T>
class Stack {
private:
std::vector<T> v;
public:
void push(T elem) {
v.push_back(elem);
}
T pop() {
if (v.empty()) throw std::out_of_range("Stack<>::pop(): empty stack");
T elem = v.back();
v.pop_back();
return elem;
}
};
```
通过`template`关键字,我们定义了一个模板函数`max`和一个模板类`Stack`,它们可以接受任意的数据类型。在使用时,编译器会根据传入的参数自动实例化相应的函数或类。
### 3.1.2 模板元编程的高级技巧
模板元编程是在编译时进行计算的一种技术,可以通过模板特化和递归模板实例化实现复杂的编译时计算。在C++11之前,模板元编程是C++中实现编译时计算的唯一方法。
```cpp
template <int N>
struct Factorial {
enum { value = N * Factorial<N-1>::value };
};
template <>
struct Factorial<0> {
enum { value = 1 };
};
int main() {
std::cout << "Factorial of 5 is " << Factorial<5>::value << std::endl;
}
```
在上面的例子中,我们定义了一个计算阶乘的模板结构体`Factorial`。当`N`大于0时,模板会被递归特化,直到`N`为0,这时特化版本会提供一个基础情况的返回值。模板元编程可以用于生成编译时的常量表达式、优化数据结构的内存布局等高级技巧。
## 3.2 多线程编程实践
### 3.2.1 标准库中的线程和互斥锁
C++11引入了新的线程库,提供了对多线程编程的原生支持。`<thread>`, `<mutex>`, `<condition_variable>`等头文件包含了创建和管理线程、同步线程执行的类和函数。
```cpp
#include <thread>
#include <mutex>
#include <iostream>
std::mutex mtx;
void print_block(int n, char c) {
mtx.lock();
for (int i = 0; i < n; ++i) {
std::cout.put(c);
}
std::cout << '\n';
mtx.unlock();
}
int main() {
std::thread threads[10];
for (int i = 0; i < 10; ++i) {
threads[i] = std::thread(print_block, 50, '*');
}
for (auto& th : threads) th.join();
}
```
上面的代码创建了多个线程,每个线程都会尝试获取一个互斥锁(`mtx`),并在获取锁后输出一段字符。`lock()`和`unlock()`确保了互斥锁的正确使用,防止了数据竞争和条件竞争。
### 3.2.2 并发算法的实现与优化
C++17对标准库进行了扩展,增加了一些并发算法,如`std::for_each`的并发版本,这些算法可以利用多核处理器来加速执行。
```cpp
#include <algorithm>
#include <execution>
#include <vector>
#include <iostream>
int main() {
std::vector<int> data(1000000);
std::iota(data.begin(), data.end(), 0);
std::for_each(std::execution::par, data.begin(), data.end(),
[](int& x) {
x *= x;
}
);
std::cout << "Final element is " << data.back() << '\n';
}
```
通过`std::execution::par`,算法并行执行,这要求编译器和标准库实现要支持并行执行策略。这种技术可以显著提高大数据集处理的效率。
## 3.3 性能分析与调优
### 3.3.1 利用性能分析工具
性能分析是优化程序性能的第一步。C++开发者可以使用一系列的工具来帮助分析程序性能,例如gprof、Valgrind、Intel VTune Amplifier以及Windows平台的性能分析工具。
```bash
g++ -O2 -pg -o my_program my_program.cpp
./my_program
gprof my_program gmon.out > report.txt
```
在上面的命令中,我们使用了`gprof`工具,通过编译时加上`-pg`标志来生成性能分析信息。在程序运行后,通过`gprof`分析生成的`gmon.out`文件来得到一个报告。
### 3.3.2 代码剖析与热点优化
代码剖析(profiling)是性能分析的一个关键步骤,它帮助开发者了解程序运行时每个函数调用的耗时情况。理解程序的热点(hot spots)是进行性能优化的首要条件。
```cpp
#include <chrono>
#include <iostream>
void compute(int n) {
long long int sum = 0;
for (int i = 0; i < n; ++i) {
sum += i;
}
}
int main() {
auto start = std::chrono::high_resolution_clock::now();
compute(1000000);
auto end = std::chrono::high_resolution_clock::now();
auto diff = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "Time taken by function: " << diff.count() << " milliseconds\n";
}
```
在上面的代码中,我们使用了`<chrono>`库来测量`compute`函数的执行时间。这是代码剖析的一个简单例子,实际应用中可能需要更复杂的分析来识别热点并进行优化。
在这一章节中,我们介绍了C++中高级编程技巧的几个关键部分,包括模板编程、多线程编程以及性能分析与调优。通过这些技术的应用和优化,C++开发者能够显著提升软件的性能和效率。在下一章节中,我们将进一步深入探讨C++高级特性和优化方法。
# 4. C++高级特性与优化方法
## 4.1 现代C++特性应用
### 4.1.1 C++11及以上版本的新特性
现代C++的发展历程中,C++11是具有里程碑意义的一个版本,它引入了大量的新特性,极大地丰富了C++的表达能力,并对性能优化提供了新的手段。以下是一些重要的C++11及后续版本的新特性,它们在现代C++编程中占有重要的地位:
- **自动类型推导(auto)**:允许编译器根据初始化表达式自动推导变量的类型。
- **统一初始化语法(uniform initialization)**:使用花括号初始化代替传统的列表初始化,增强初始化的灵活性和一致性。
- **智能指针(unique_ptr, shared_ptr)**:提供了自动内存管理的能力,减少内存泄漏的风险。
- **lambda表达式**:允许创建匿名函数对象,简化了函数式编程元素的使用。
- **线程库(<thread>)**:提供了标准的多线程支持。
- **右值引用与移动语义**:减少不必要的对象拷贝,优化性能。
- **类型推导函数(constexpr)**:允许在编译时进行计算,提升程序效率。
**代码示例:使用auto与lambda表达式**
```cpp
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
// 使用auto自动类型推导
for (auto &num : numbers) {
std::cout << num << ' ';
}
std::cout << std::endl;
// 使用lambda表达式进行排序
std::sort(numbers.begin(), numbers.end(), [](int a, int b) { return a > b; });
// 输出排序后的结果
for (const auto &num : numbers) {
std::cout << num << ' ';
}
std::cout << std::endl;
return 0;
}
```
在这个示例中,使用`auto`关键字使得变量`num`的类型在编译时被自动推导,免除了显式类型声明。另外,使用lambda表达式来定义排序的比较函数,使代码更加简洁。
### 4.1.2 利用lambda表达式和高阶函数
Lambda表达式是C++11引入的另一个重要特性,它允许程序员创建未命名的函数对象,可以捕获外部变量、定义参数列表、实现返回类型,并且可以在代码中任何需要的地方使用。Lambda表达式的出现,使得在C++中实现函数式编程变得更加容易和自然。
高阶函数是接受其他函数作为参数,或者返回一个函数的函数。在C++中,lambda表达式可以作为高阶函数使用,从而提高了代码的模块化和抽象能力。
**代码示例:使用lambda表达式作为高阶函数**
```cpp
#include <iostream>
#include <functional>
int main() {
// 定义一个函数,它接受一个函数作为参数
auto applyTwice = [](auto func, auto arg) {
return func(func(arg));
};
// 定义一个lambda函数
auto add = [](auto a, auto b) { return a + b; };
// 应用高阶函数
auto result = applyTwice(add, 3);
std::cout << "The result of applying 'add' twice on 3 is: " << result << std::endl;
return 0;
}
```
在这个代码块中,`applyTwice`函数是一个高阶函数,它接受一个函数`func`和一个参数`arg`,然后将`func`应用到`arg`上两次。这里用lambda表达式定义了一个简单的加法函数`add`,然后将其作为参数传递给`applyTwice`函数,实现了两次加法操作。
利用现代C++的这些新特性,程序员可以编写更简洁、更安全、更高效的代码。这不仅提升了开发效率,也有助于性能的提升。
## 4.2 编译器优化技术
### 4.2.1 编译器指令和优化开关
编译器优化是提升程序运行效率的一个重要手段,现代编译器提供了一系列的优化指令和优化级别开关,允许程序员根据不同的需求调整编译器的行为。以下是一些常用的编译器优化技术:
- **优化级别开关**:GCC编译器中使用`-O1`到`-O3`开关来控制优化级别,`-O3`通常提供最高的优化级别。
- **内联函数(inline)**:通过`inline`关键字,编译器可以将小的函数调用在编译时替换为函数体。
- **循环展开(loop unrolling)**:减少循环次数,通过减少循环控制的开销来提高性能。
- **死码消除(dead code elimination)**:移除程序中那些不会被执行到的代码段。
- **编译时计算(constexpr)**:在编译时进行的计算,减少程序运行时的计算负担。
**示例:优化级别的使用**
```bash
g++ -std=c++11 -O2 -o example example.cpp
```
在上面的编译指令中,`-O2`是GCC的一个优化开关,表示使用中等程度的优化。与`-O1`相比,`-O2`会开启更多的优化选项,但可能增加编译时间。
### 4.2.2 内联函数和循环展开
内联函数是编译时的一个优化手段,其主要目的是减少函数调用的开销。当函数非常短小且被频繁调用时,将函数声明为内联,编译器会将函数调用替换为函数的执行代码。
循环展开是一种减少循环开销的技术,它通过减少循环的迭代次数,直接在循环体中包含更多的计算步骤,从而减少循环控制的次数。
**代码示例:内联函数和循环展开**
```cpp
// 内联函数示例
inline int add(int a, int b) {
return a + b;
}
// 循环展开示例
void loopUnrolling() {
for (int i = 0; i < 10; i += 2) {
// 直接进行4次加法,减少循环次数
int sum = add(i, i+1) + add(i+2, i+3) + add(i+4, i+5) + add(i+6, i+7);
// ... 其他操作
}
}
```
在这个例子中,`add`函数被定义为内联,这意味着在编译时,每次调用`add`函数的地方都会被替换为相应的加法操作。`loopUnrolling`函数展示了循环展开的用法,通过合并多次迭代,减少了循环次数。
通过以上编译器优化技术,程序员可以大幅提升程序的性能。尽管现代编译器已经足够智能,能够自动应用许多优化策略,但是理解并掌握这些技术,可以让开发者更加有效地指导编译器进行优化。
## 4.3 构建自定义库与工具
### 4.3.1 第三方库的选择与集成
在开发过程中,尤其是大型项目中,很多时候会依赖第三方库来提供某些功能。正确选择和集成第三方库对于项目的成功至关重要。第三方库可以提供诸如网络通信、图形界面、数据处理等多种功能,帮助开发者快速构建应用。
选择第三方库时,以下是一些重要的考量因素:
- **许可证**:必须确保库的许可证符合你的项目需求。
- **活跃度**:检查库的维护者是否活跃,项目是否持续更新。
- **社区支持**:是否有活跃的社区和充足的文档。
- **性能**:库的性能是否满足项目的需要。
- **兼容性**:库是否与你的其他依赖项和目标平台兼容。
**示例:第三方库集成步骤**
1. **下载和配置**:通常第三方库会提供源码下载,配置编译环境是集成的第一步。
2. **依赖关系**:解决库的依赖关系,可能需要安装其他的依赖项。
3. **构建**:根据库提供的构建说明,使用合适的工具进行编译和安装。
4. **集成**:将构建好的库集成到你的项目中,正确设置链接器和编译器的路径。
### 4.3.2 创建与优化自定义工具链
自定义工具链是针对特定需求的软件开发工具组合。构建自定义工具链可以更好地控制开发流程,提高开发效率和产品质量。
构建自定义工具链通常包括以下几个步骤:
1. **确定需求**:根据项目需求确定工具链中需要哪些工具。
2. **选择工具**:选择适合的编译器、调试器、版本控制等。
3. **配置工具**:对选定的工具进行详细配置,确保它们能够协同工作。
4. **自动化**:通过脚本或专用工具实现工具链的自动化构建和测试。
5. **优化**:定期回顾工具链的性能和产出,进行必要的优化和升级。
**示例:创建自定义编译工具链**
假设我们需要为项目创建一个简单的自定义编译工具链,可以使用Makefile文件来自动化编译流程:
```makefile
CC=g++ # 定义编译器
CFLAGS=-std=c++11 # 编译器选项
LDFLAGS=-lm # 链接选项,这里链接数学库
app: main.o utility.o
$(CC) -o app main.o utility.o $(LDFLAGS)
main.o: main.cpp
$(CC) -c main.cpp $(CFLAGS)
utility.o: utility.cpp
$(CC) -c utility.cpp $(CFLAGS)
.PHONY: clean
clean:
rm -f app main.o utility.o
```
以上是一个简单的Makefile文件示例,定义了如何编译和链接程序。通过这个Makefile,你可以快速构建项目,并通过`make clean`清除构建产物。
在构建和集成自定义工具链时,需要特别注意工具链的一致性和兼容性,以及可能带来的性能提升。通过精心选择和配置工具链,可以为项目的长期成功打下坚实的基础。
# 5. C++项目中的实践与案例分析
在前几章中,我们已经深入探讨了C++编程效率的重要性、基础优化技巧以及中高级编程技巧和高级特性。现在,我们将焦点放在实际项目中的应用上,分析性能瓶颈,探讨跨平台开发的优化,并对未来C++效率提升的趋势进行展望。
## 5.1 实际项目中的性能瓶颈分析
在大型C++项目中,性能瓶颈是不可避免的。这些瓶颈可能源于算法效率低下、内存管理不当,或是系统资源的限制等多种因素。案例分析能帮助我们深入了解这些复杂问题。
### 5.1.1 大型项目中的性能问题案例
以一款3D游戏引擎为例,其中的性能瓶颈主要集中在图形渲染和物理模拟这两个模块。图形渲染模块在渲染大量多边形和粒子效果时,CPU和GPU资源争抢严重,导致帧率下降。物理模拟模块在处理复杂场景碰撞检测和刚体动力学计算时,同样耗时过长。
### 5.1.2 解决方案与调优策略
面对这类问题,解决方案和调优策略包括但不限于:
- **算法优化**:使用空间分割技术如四叉树或八叉树来减少碰撞检测的计算量。
- **并行计算**:利用多线程或GPU加速来分担CPU压力,例如使用OpenCL或CUDA进行物理模拟的并行化。
- **资源管理**:优化内存池的使用,减少动态内存分配的开销。
- **代码剖析**:通过性能分析工具定位热点代码,针对性地进行优化。
## 5.2 C++的跨平台开发优化
跨平台开发是现代软件开发的一个重要方向,而C++在这一领域同样表现突出。然而,不同的操作系统和硬件架构对性能有着各自的影响。
### 5.2.1 跨平台工具链的搭建
一个高效的跨平台工具链包括了编译器、链接器和构建系统。例如,使用CMake结合不同平台的生成器,可以构建出针对Windows、Linux和macOS的应用程序。此外,针对每个平台的特定库和API需要妥善封装和抽象,以保证代码的可移植性。
### 5.2.2 跨平台性能优化技巧
在不同平台上保持性能的一致性需要考虑以下技巧:
- **平台特定优化**:利用操作系统提供的特定API进行优化。例如,在Windows上使用DirectX,在Linux上使用OpenGL进行图形渲染。
- **编译器优化**:使用不同编译器针对平台优化的开关,例如GCC和Clang针对不同的平台提供了不同的优化选项。
- **算法和数据结构的适应性**:根据目标平台的硬件特性选择合适的算法和数据结构。
## 5.3 未来C++效率提升的趋势
随着技术的发展,C++持续进行着进化,以适应新的编程范式和硬件环境。
### 5.3.1 C++社区的最新动态
C++社区持续活跃,不断有新的提案和特性被引入。例如,C++20带来了概念(Concepts)、协程(Coroutines)等新的语言特性,为开发人员提供了更多的工具来编写高效代码。
### 5.3.2 未来技术方向和展望
未来,C++可能会进一步发展出更强大的工具和库,以支持并行计算、异步编程和更低级的硬件交互。此外,对AI和机器学习的集成,以及WebAssembly的优化支持,将是C++未来发展的关键方向。
在本章中,我们讨论了C++项目中的实际应用问题,包括性能瓶颈的分析与解决方案、跨平台开发的挑战与优化策略,以及未来C++技术的发展趋势。通过这些内容,我们可以更加深入地理解C++在现代软件开发中的地位和潜力。接下来,我们将进入下一章,进一步探索C++在专业领域中的应用案例。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《C++语言程序设计》郑莉清华大学出版社课后答案专栏是一个全面的C++编程资源,涵盖了从基础概念到高级技术的各个方面。它提供了深入的解析、实用技巧和代码示例,帮助初学者掌握C++,并帮助经验丰富的程序员提升技能。专栏内容包括:
* 关键概念:掌握C++编程的基础知识
* 实用应用:了解C++在实际项目中的应用
* 效率技巧:提高编程速度和代码质量
* 内存管理:深入理解C++的动态内存分配和释放机制
* 模板编程:掌握泛型编程的技巧
* 标准库:彻底理解STL容器、迭代器和算法
* 异常处理:正确使用异常和错误处理
* 并发编程:深入分析多线程和同步机制
* 性能优化:分析和优化C++代码的性能
* 底层技术:揭秘编译器和运行时的内部机制
* 跨平台开发:跨平台应用开发的方法和技巧
* 数据库交互:使用C++进行数据库编程
* 网络编程:构建客户端和服务器端网络应用
* GUI技术:基于C++的GUI开发技术
* 测试与调试:编写可靠C++代码的技巧
* 数据结构:掌握和实现高效的数据结构算法
* 游戏开发:使用C++进行游戏编程的高级技术
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【网络中心度计算全攻略】:从理论到实践,揭秘图论中的核心算法

# 摘要
本文从网络中心度计算的角度出发,系统地回顾了图论基础理论,并详细介绍了中心度的基本概念、类型及其在实际网络中的计算方法。
揭秘STM32单线半双工:2小时掌握高效通信的秘诀

# 摘要
本文全面介绍STM32单线半双工通信技术,涵盖其基本原理、软硬件实现方法、调试与优化技巧,以及实际应用案例。首先概述了单线半双工通信,并与多线通信进行对比,阐述了其工作机制。接着深入解析了STM32在此通信模式下的协议标准和帧结构,同时强调了硬件设计中的关键要点。本文第三章和第四章重点介绍了软件架构、编程实践,以及调试策略和性能优化技巧。通过两个
【大数据时代必备:Hadoop框架深度解析】:掌握核心组件,开启数据科学之旅
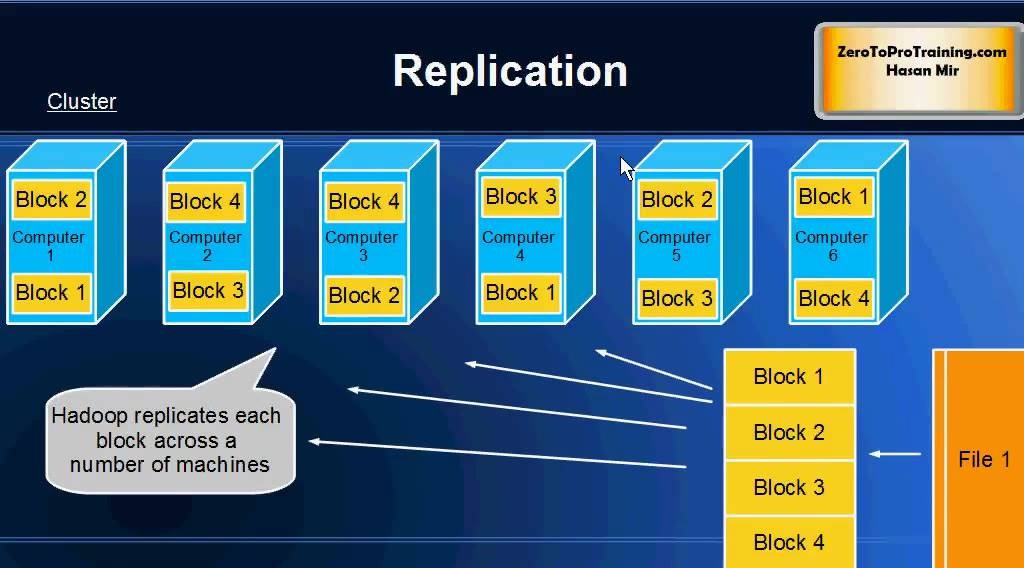
# 摘要
Hadoop作为一个开源的分布式存储和计算框架,在大数据处理领域发挥着举足轻重的作用。本文首先对Hadoop进行了概述,并介绍了其生态系统中的核心组件。深入分
Compaq Visual Fortran 6.6安装与使用大全:Fortran开发者的宝贵经验分享
# 摘要
本文详细介绍了Compaq Visual Fortran 6.6(CVF)的安装、基础使用、核心概念、项目管理和高级应用。第一章和第二章提供了一个全面的CVF简介及安装流程,包括系统要求、兼容性检查、安装步骤和验证测试。第三章关注CVF的基本使用方法,涵盖开发环境操作、代码编写技巧及程序的编译、链接和运行。第四章深入探讨Fortran语言的基础语法、控制结构、函数、面向对象编程和模块。
【Linux多系统管理大揭秘】:专家级技巧助你轻松驾驭
# 摘要
本文全面介绍了Linux多系统管理的关键技术和最佳实践。首先概述了多系统管理的基本概念,随后详细探讨了多系统的安装与启动流程,包括系统安装前的准备工作、各主流Linux发行版的安装方法以及启动管理器GRUB2的配置。接下来,文章深入分析了Linux多系统间文件共享与数据迁移的策略,特别是NTFS与Linux文件系统的互操作性和网络文件系统(NFS)的应用。此外,本
【CodeBlocks精通指南】:一步到位安装wxWidgets库(新手必备)

# 摘要
本文旨在为使用CodeBlocks和wxWidgets库的开发者提供详细的安装、配置、实践操作指南和性能优化建议。文章首先介绍了CodeBlocks和wxWidgets库的基本概念和安装流程,然后深入探讨了CodeBlocks的高级功能定制和wxWidgets的架构特性。随后,通过实践操作章节,指导读者如何创建和运行一个wxWidgets项目,包括界面设计、事件
Visual C++ 6.0 LNK1104错误:终结文件无法打开的挑战

# 摘要
Visual C++ 6.0中的LNK1104错误是一个常见的链接问题,可能导致开发者在编译和部署应用程序时遇到障碍。本文旨在全面解析LNK1104错误的成因,包括链接过程的介绍、常见触发条件以及错误信息的解读。通过分析各种可能的原因,如缺少库文件或
iOS通用链接与深度链接结合秘籍:打造无缝用户体验

# 摘要
本文详细探讨了iOS平台上的通用链接和深度链接技术,包括它们的概念、实现、配置以及与安全与隐私相关的考量。通过深
Xilinx Polar IP核初学者必读:快速入门指南

# 摘要
Xilinx Polar IP核作为一款高性能且可重用的IP核,为FPGA项目提供了灵活的解决方案。本文首先介绍了Polar IP核的基础概念,包括其定义、分类以及在系统设计中的角色。随后,详细阐述了其设计、实现、验证和测试的开发流程,并通过案例分析展示了IP核在不同应用中的集成与优化。文章还探讨了IP核的高级应用,如硬件加速和并行处理,并讨论了Polar IP核的生
【嵌入式系统开发速成指南】:掌握Windriver的10个关键技巧

# 摘要
本文旨在全面介绍嵌入式系统开发流程,特别是在使用Windriver工具进行开发的实践中。首先,文章从搭建开发环境入手,详细说明了安装Windriver工具、配置嵌入式硬件与软件以及优化开发环境的过程。接着,深入探讨了Windriver框架,包括架构组件解析、驱动程序开发基础以及高级编程接口的应用。第四章着重于系统集成与测试
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )