




【Python字典内存管理】:避免内存泄漏,提升性能的高级技巧

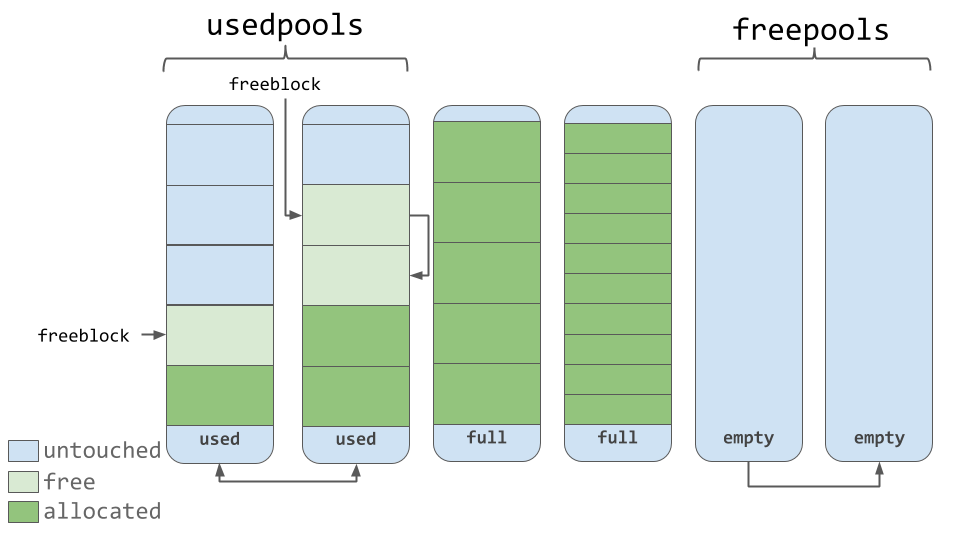
1. Python字典基础与内存机制
Python字典是构建于哈希表之上的高级数据结构,用于存储键值对(key-value pairs)。在本章中,我们将从基础开始,逐步深入探讨Python字典背后的内存机制。
1.1 字典对象的内存布局
在内存层面,Python字典主要由两个部分组成:键(keys)和值(values)。字典会根据键的哈希值来存储数据,保证数据的快速检索。
- my_dict = {'a': 1, 'b': 2, 'c': 3}
1.2 字典的内存分配
Python字典通过动态数组实现,当字典中元素数量超过数组容量时,会自动进行扩容。在Python 3.6之前的版本,字典在内存中不保证顺序,但自Python 3.7开始,字典保持插入顺序。
1.3 字典内存的动态扩展
随着字典中元素的增加,Python会根据预设的策略对字典进行扩容以维持操作效率。这涉及到重新哈希现有元素和重新分配内存空间,进而影响内存使用效率。
- for i in range(1000):
- my_dict[i] = i ** 2
以上代码将导致字典my_dict动态扩展其内存空间,以适应不断增长的元素数量。通过了解这一过程,我们可以更好地掌握Python字典的内存使用,从而优化我们的程序设计。
2. 深入理解Python字典的内存管理
2.1 字典对象在内存中的表现
2.1.1 字典的内部结构分析
Python字典在内存中的表现与其内部结构紧密相关。字典是通过一种称为哈希表的结构实现的,这种结构允许我们以非常快的方式检索和存储键值对。当创建一个新的字典时,Python会在内存中初始化一个大小固定的数组,并准备一些用于处理哈希冲突的额外空间。
每个键值对在哈希表中由一个元素表示,这些元素通常称为条目或记录。每个条目都包含两部分:一个指向键的指针和一个指向值的指针。在哈希表的初始化阶段,所有的条目都指向一个特定的哨兵值,通常是Py.None,表示该位置当前没有存储有效的键值对。
- # 示例:初始化一个空字典
- empty_dict = {}
哈希函数是实现快速检索的关键。它将键转换为数组索引,这个索引指向数组中存储键值对的位置。如果两个键通过哈希函数得到相同的索引,则称为哈希冲突。Python通过一种称为开放寻址的技术解决冲突。在开放寻址中,如果计算出的索引位置已被占用,会寻找下一个可用位置来存储键值对。
2.1.2 字典键值对的内存分配
当一个键值对被添加到字典中时,Python会在内存中为键和值分配空间。键的内存分配相对简单,因为它通常是一个不可变对象,如字符串或元组。值的内存分配则依赖于值的数据类型和大小。
- # 示例:向字典中添加键值对
- dict["key"] = "value"
键必须是不可变的,以便哈希函数能够产生一致的结果。这意味着字典中存储的键不能是列表或其他可变类型,因为它们的内容可以改变,导致哈希值不一致。
值的内存分配取决于其类型。如果值是一个不可变类型(如整数或字符串),则其内存直接分配。如果值是一个可变类型(如列表或另一个字典),则仅分配一个指针,指向实际数据的存储位置。这种分配方式使得Python字典在存储大型数据结构时非常高效,但也可能导致循环引用和内存泄漏的问题。
2.2 字典内存管理的关键技术
2.2.1 字典的内存分配策略
Python字典的内存分配策略是动态的。随着字典的使用,数组会根据需要进行重新分配,以保持哈希表的效率。当字典中的元素数量达到一定比例(负载因子)时,哈希表会增长,即创建一个新的更大的数组,并将旧数组中的所有键值对重新哈希并插入到新数组中。
- # 伪代码:哈希表增长过程
- def resize_hash_table():
- old_table = current_hash_table
- new_table = allocate_larger_table()
- for entry in old_table:
- if entry.is_occupied():
- key, value = entry.get_key_value()
- hash_key = hash_function(key)
- new_table.insert_at(hash_key, key, value)
- current_hash_table = new_table
通过这种方式,Python保持了字典操作的平均时间复杂度接近O(1),即使在字典大小变化时也是如此。然而,这个过程是资源密集型的,因为需要复制所有现有的键值对到新的哈希表中。因此,在设计程序时,应当尽量避免频繁的哈希表扩容操作。
2.2.2 字典的垃圾回收机制
Python使用引用计数和标记-清除(mark-sweep)算法来管理内存。引用计数跟踪每个对象的引用次数,当引用次数降为零时,对象占用的内存可以立即回收。但是,引用计数无法处理循环引用的情况,这时就需要使用标记-清除算法。
在标记-清除算法中,垃圾回收器会从一组根对象开始,标记所有可达的对象。那些未被标记的对象意味着它们无法通过任何引用链访问,因此它们占用的内存可以安全地回收。字典可以参与循环引用,特别是当值包含对字典自身的引用时。
- # 示例:循环引用导致的内存问题
- d1 = {}
- d2 = {}
- d1['key'] = d2
- d2['key'] = d1
为了避免这种问题,开发者需要在设计数据结构时注意避免循环引用,或者使用弱引用(weakref模块)来打破强引用循环。
2.3 Python字典内存泄漏的原因
2.3.1 循环引用与内存泄漏
内存泄漏在Python程序中通常是由循环引用引起的。循环引用发生在多个对象相互引用,形成一个闭环,导致即使程序中没有其他引用指向这些对象,它们也不会被垃圾回收器回收。在字典中,循环引用可能发生在值是可变对象,并且该对象包含了对字典自身的引用时。
- # 循环引用示例
- a = {}
- b = {}
- a['b'] = b
- b['a'] = a
在这种情况下,即使删除了a和b的外部引用,这两个字典仍然不会被回收,因为它们通过相互引用彼此保持活跃状态。要避免这种内存泄漏,开发者应该尽量使用不可变类型的值,或者使用弱引用。
2.3.2 字典使用不当引发的问题
除了循环引用,不当的字典使用方式也可能导致内存泄漏。例如,如果字典持续增长且不进行任何清理,它可能会消耗越来越多的内存。此外,如果字典用于存储大量大型数据结构而不进行定期清理,也可能造成内存使用效率低下。
- # 示例:大量存储大型对象的字典
- large_objects_dict = {}
- for _ in range(1000000):
- large_objects_dict[_] = generate_large_object()
为了解决这些问题,开发者应当在程序中实现适当的内存管理策略,比如定期清理不再需要的字典条目,或者使用更合适的数据结构来存储大量数据。另一个可行的方法是使用弱引用字典(weakref.WeakValueDictionary),它不会阻止其值被垃圾回收,从而避免内存泄漏。
3. 性能优化与内存泄漏预防
3.1 优化字典操作提升性能
字典作为Python中最常用的复合数据类型之一,其操作的效率直接影响程序的性能。在进行性能优化时,我们主要关注如何减少不必要的内存分配和提高字典操作的速度。
3.1.1 使用字典推导式简化代码
字典推导式是一种在Python中创建字典的简洁方式。它不仅使代码更加简洁,还能提高执行效率。字典推导式的基本语法如下:
- {key_expr: value_expr for item in iterable}
举个例子,如果我们需要从一组数据中提取出唯一的键,并将这些键与它们出现的次数形成一个字典:
- data = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']
- counts = {item: data.count(item) for item in set(data)}
- print(counts)
这段代码执行完毕后,会输出字典,其中包含每种水果的出现次数。字典推导式的好处在于它避免了显式的循环结构,并且在内部实现上比传统的循环更加高效。
3.1.2 字典的解包与合并技巧
在处理多个字典时,Python允许你使用解包操作符(**)来合并它们。这是在处理配置信息或在函数中使用默认参数时非常有用的技巧。
假设有两个字典:
- dict1 = {'a': 1, 'b': 2}
- dict2 = {'c': 3, 'd': 4}
使用解包操作符,可以合并为一个新的字典:
- combined_dict = {**dict1, **dict2}
这会得到:
- {'a': 1, 'b': 2, 'c': 3, 'd': 4}
通过这种方式,可以更

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
DM9162_DM9162I底层架构揭秘:底层逻辑与工作原理详解
智能工厂资讯整合成功秘诀:案例研究揭露关键因素
相机标定工具对比:开源与商业解决方案优劣分析
黄芩素晶体结构测定:粉末X射线衍射法的高级技巧与案例研究
【硬件专家推荐】:如何为波形发生器选择最佳单片机
驱动开发攻略:AW-CM256(CYW43xx)Wi-Fi芯片调试与故障排除技巧
团队开发捷径:Pycharm与GitLab连接常见问题的权威解答
MATLAB脚本调试大揭秘:三角形单元分析问题解决技巧
动量轮自行车的能源管理:STM32与电源优化的革命性策略
【2SK3018可靠性测试】:确保长期稳定运行的测试与验证策略


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















