【字典在数据处理中的应用】:利用字典进行高效数据清洗,提升数据质量
发布时间: 2024-09-18 23:43:46 阅读量: 104 订阅数: 37 

NCC1909数据字典

# 1. 字典数据结构概述
数据结构是计算机存储、组织数据的方式,它决定了数据处理的效率和便捷性。在众多数据结构中,字典(Dictionary)是一种以键值对(key-value pairs)形式存储数据的结构,在多种编程语言中都有对应实现,如Python中的dict。字典允许用户通过键快速访问、插入、修改和删除数据元素,它在内存中通过散列表(hash table)技术实现,以实现高速的查找。
与数组或链表相比,字典的主要优势在于其对元素的快速访问能力。它没有顺序的概念,不需要像数组那样通过索引顺序访问,也不需要像链表那样遍历整个集合来查找一个元素。这种高效的数据访问机制使得字典成为实现映射关系的理想选择。
在本章中,我们将介绍字典的基本概念、操作以及在实际编程中的应用。我们还会探讨字典与其他数据结构(如列表和元组)的比较,以及它在数据处理中的潜在用途和优势。通过理解字典的这些特性,我们可以更好地掌握如何在不同的场景中利用字典来解决问题。
# 2. 字典在数据清洗中的理论基础
## 2.1 数据清洗的重要性与目的
### 2.1.1 数据质量对分析的影响
数据清洗是数据预处理的一个关键步骤,对后续的数据分析、数据挖掘和机器学习模型的建立都有着至关重要的影响。在数据质量低下的情况下,数据分析的结果可能会有偏差,导致错误的决策或模型训练的不准确。在数据科学领域,数据质量主要取决于数据的完整性、一致性、准确性和时效性。
为了更直观地理解数据质量的影响,我们可以考虑以下情况:在一张包含客户购买记录的数据表中,如果存在大量的缺失值或不一致的数据格式(例如日期格式不统一、货币单位不一致等),那么在进行销售趋势分析或客户细分时,这些错误和不一致的数据点会扭曲分析结果,导致市场分析或销售策略的误判。因此,确保数据质量是数据清洗的首要任务。
### 2.1.2 清洗数据的原则和方法
数据清洗的核心原则是确保数据的准确性和一致性,并尽可能地保留有用信息。进行数据清洗时,常用的方法包括但不限于以下几点:
1. **处理缺失值**:可以采用删除、填充或预测缺失值的方式进行处理。
2. **纠正数据错误**:识别并修正数据录入错误、拼写错误或逻辑错误。
3. **数据格式化**:统一数据格式,确保日期、时间、货币等数据类型的标准化。
4. **数据标准化**:将数据转换为具有统一范围或分布的形式,如归一化或标准化。
5. **数据去重**:识别并删除重复记录,以避免数据的冗余。
6. **检测异常值**:识别数据集中的异常值,并决定是删除还是修正这些值。
## 2.2 字典数据结构的特点
### 2.2.1 键值对存储机制
在Python中,字典是一种内置的数据结构,它通过键值对的方式存储数据,其中每个键都是唯一的,而每个键都映射到一个特定的值。这种数据结构允许我们快速地访问、插入和删除元素。键可以是任何不可变类型,如字符串、数字或元组,而值可以是任何数据类型,包括数字、字符串、列表、字典甚至是其他字典。
字典的键值对存储机制在数据清洗中有其独特的优势。例如,当处理缺失值时,我们可以使用字典来存储每个字段的缺失数据计数,或者使用字典的键值对来创建查找表,以便快速映射和替换缺失值。
### 2.2.2 字典与列表、元组的比较
与列表和元组相比,字典在访问元素时具有更高的效率,尤其是当数据集很大时。列表和元组都是顺序存储的数据结构,元素的访问时间复杂度为O(n),而字典的访问时间复杂度为O(1)。这是因为字典使用了哈希表的内部实现机制,通过计算键的哈希值来快速定位元素。
不过,列表和元组在某些情况下也有其优势。例如,如果数据需要保持特定的顺序,或者需要对元素进行切片操作时,列表或元组可能是更好的选择。而在数据清洗过程中,由于经常需要查找和替换数据,字典的优势更为明显。
## 2.3 字典在数据处理中的优势
### 2.3.1 快速访问与修改数据
字典的快速访问和修改特性在数据清洗中尤为突出。例如,当需要统计某个字段中各个值出现的频率时,我们可以直接使用字典的键来存储值,以值出现的次数作为字典的值。这样做不仅方便地统计出频率,还可以快速更新频率统计,而无需遍历整个数据集。
### 2.3.2 灵活的数据结构适用场景
字典的灵活性使其在许多数据处理场景中都非常有用。例如,在进行数据转换时,我们可以使用字典来映射原始值到新的编码值,从而实现数据的分类和编码。此外,字典也经常用于构建复杂的查找表,比如在地理信息系统中用于匹配城市名称到其经纬度。
此外,在数据聚合和分组时,字典可以作为累加器,通过键来对数据进行分组,并对每组数据进行计算和汇总。这种方式不仅简化了代码,还提高了数据处理的效率。
# 3. 字典数据清洗实践操作
字典数据结构因其灵活性和高效性,在数据清洗操作中扮演着重要的角色。本章将深入探讨字典在实际数据清洗任务中的具体应用,包括处理缺失值、异常值检测以及数据转换等场景。
## 3.1 利用字典进行缺失值处理
在数据分析中,缺失值处理是一个重要的步骤,缺失值的存在可能会严重影响分析结果的准确性。字典数据结构因其灵活的键值对特性,被广泛应用于缺失值的检测和处理。
### 3.1.1 检测缺失数据的方法
要处理缺失数据,首先需要能够准确地识别它们。通常,我们可以使用字典来存储数据集的列名作为键,以对应列的值作为值。通过遍历字典,我们可以快速检测到键值为`None`或者特定标记(如`NaN`)的情况。
例如,以下代码展示了如何使用字典检测数据中的缺失值:
```python
import pandas as pd
import numpy as np
# 创建一个包含缺失值的DataFrame
data = {'A': [1, None, 3, 4], 'B': [5, 6, None, 8], 'C': [9, 10, 11, 12]}
df = pd.DataFrame(data)
# 将DataFrame转换为字典
data_dict = df.to_dict()
# 检测字典中的缺失值
missing_values = {key: [index for index, value in enumerate(value_list) if pd.isnull(value)] for key, value_list in data_dict.items()}
print(missing_values)
```
输出结果中会列出每个键(列名)和对应的缺失值索引位置,从而便于进行下一步的缺失值处理。
### 3.1.2 填补缺失值的策略
填补缺失值的常用策略包括使用固定值、列的平均值、中位数或者基于模型的预测值。在字典中,我们可以根据键值对的具体内容,灵活地应用这些策略。
例如,以下代码展示了如何使用字典填充缺失值:
```python
# 使用列的平均值填补缺失值
for key, value_list in data_dict.items():
if key != 'C': # 假设第三列不需要填补缺失值
mean_value = np.mean([v for v in value_list if v is not None])
data_dict[key] = [mean_value if pd.isnull(v) else v for v in value_list]
# 将处理后的字典转换回DataFrame
filled_df = pd.DataFrame(data_dict)
print(filled_df)
```
在这个例子中,我们选择了使用平均值来填充缺失值。这种方法简单且常用于初步分析,但在更复杂的场景下,可能需要更精细化的处理策略。
## 3.2 字典在异常值检测中的应用
异常值是指那些不符合数据分布规律的观测值,它们可能是数据错误或者真实变异的表现。字典数据结构可以通过存储统计数据和阈值来检测和处理异常值。
### 3.2.1 异常值的识别技术
异常值检测通常基于统计学原理,例如,利用标准差、四分位距(IQR)等统计量来定义异常值。字典可以存储这些统计量,使异常值检测过程更加高效。
例如,以下代码展示了如何使用字典和标准差来识别异常值:
```python
# 计算每列的均值和标准差,并存储到字典中
stats_dict = {key: {'mean': np.mean(value_list), 'std': np.std(value_list)} for key, value_list in data_dict.items()}
# 定义异常值的阈值
threshold = 3
outliers = {}
# 检测异常值
for key, stats in stats_dict.items():
mean, std = stats['mean'], stats['std']
outliers[key] = [index for index, value in enumerate(data_dict[key]) if (value < mean - threshold * std or value > mean + threshold * std)]
print(outliers)
```
这段代码会返回一个字典,其中包含了每列数据中超出阈值范围的索引位置,从而识别出潜在的异常值。
### 3.2.2 利用字典进行异常值处理
检测到异常值后,需要根据具体情况进行处理。字典提供了快速访问和修改数据的能力,可以根据是否为异常值来决定数据的保留或替换。
例如,以下代码展示了如何利用字典替换异常值:
```python
# 替换异常值为列的均值
for key, stats in stats_dict.items():
mean = stats['mean']
for index in outliers[key]:
data_dict[key][index] = mean
# 将处理后的字典转换回DataFrame
cleaned_df = pd.DataFrame(data_
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"dictionary python"为主题,深入探讨了Python字典的方方面面。从基础使用到高级技巧,涵盖了字典复制、性能优化、常见问题、内存管理、高级用法、排序技巧、JSON数据处理、集合关系、线程安全操作、数据处理应用、自定义排序和Web开发应用等方面。通过循序渐进的讲解和实战策略,帮助读者从入门到精通,掌握字典的各种用法和技巧,提升Python编程能力,优化代码性能,避免数据混乱,提高开发效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
爱普生R230打印机:废墨清零的终极指南,优化打印效果与性能

# 摘要
本文全面介绍了爱普生R230打印机的功能特性,重点阐述了废墨清零的技术理论基础及其操作流程。通过对废墨系统的深入探讨,文章揭示了废墨垫的作用限制和废墨计数器的工作逻辑,并强调了废墨清零对防止系统溢出和提升打印机性能的重要性。此外,本文还分享了提高打印效果的实践技巧,包括打印头校准、色彩管理以及高级打印设置的调整方法。文章最后讨论了打印机的维护策略和性能优化手段,以及在遇到打印问题时的故障排除
【Twig在Web开发中的革新应用】:不仅仅是模板

# 摘要
本文旨在全面介绍Twig模板引擎,包括其基础理论、高级功能、实战应用以及进阶开发技巧。首先,本文简要介绍了Twig的背景及其基础理论,包括核心概念如标签、过滤器和函数,以及数据结构和变量处理方式。接着,文章深入探讨了Twig的高级
如何评估K-means聚类效果:专家解读轮廓系数等关键指标
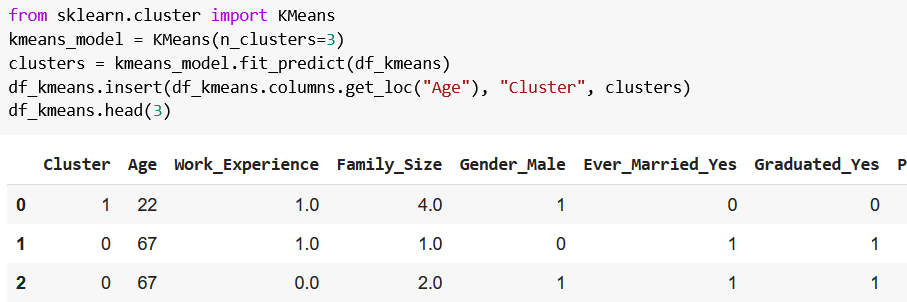
# 摘要
K-means聚类算法是一种广泛应用的数据分析方法,本文详细探讨了K-means的基础知识及其聚类效果的评估方法。在分析了内部和外部指标的基础上,本文重点介绍了轮廓系数的计算方法和应用技巧,并通过案例研究展示了K-means算法在不同领域的实际应用效果。文章还对聚类效果的深度评估方法进行了探讨,包括簇间距离测量、稳定性测试以及高维数据聚类评估。最后,本
STM32 CAN寄存器深度解析:实现功能最大化与案例应用
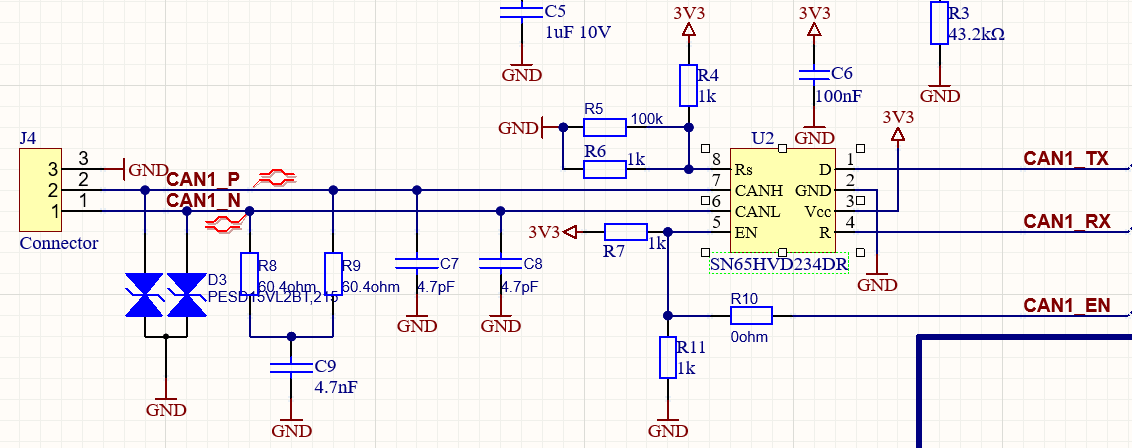
# 摘要
本文对STM32 CAN总线技术进行了全面的探讨和分析,从基础的CAN控制器寄存器到复杂的通信功能实现及优化,并深入研究了其高级特性。首先介绍了STM32 CAN总线的基本概念和寄存器结构,随后详细讲解了CAN通信功能的配置、消息发送接收机制以及错误处理和性能优化策略。进一步,本文通过具体的案例分析,探讨了STM32在实时数据监控系统、智能车载网络通信以
【GP错误处理宝典】:GP Systems Scripting Language常见问题与解决之道
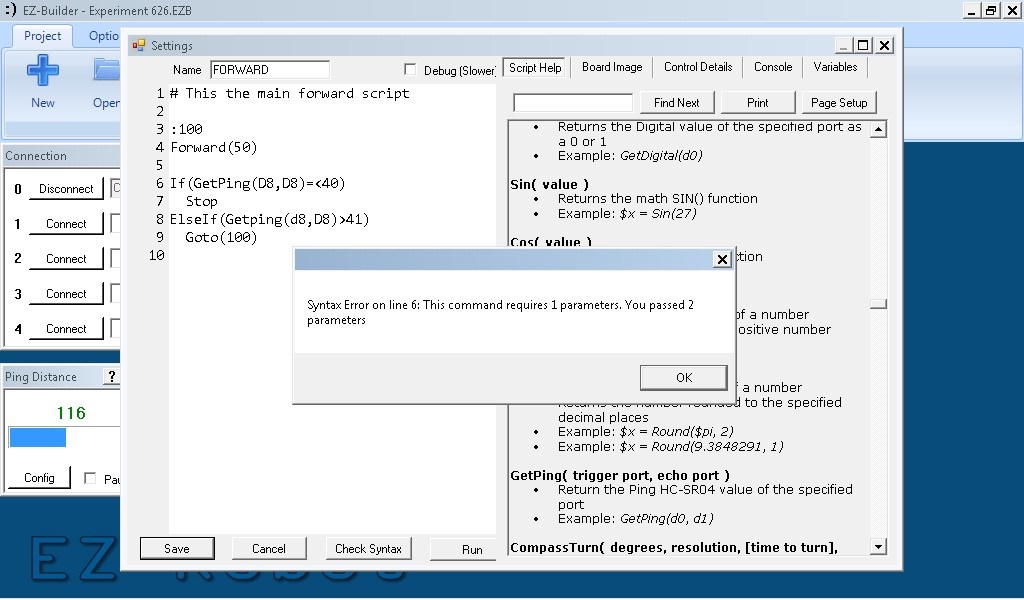
# 摘要
GP Systems Scripting Language是一种为特定应用场景设计的脚本语言,它提供了一系列基础语法、数据结构以及内置函数和运算符,支持高效的数据处理和系统管理。本文全面介绍了GP脚本的基本概念、基础语法和数据结构,包括变量声明、数组与字典的操作和标准函数库。同时,详细探讨了流程控制与错误处理机制,如条件语句、循环结构和异常处
【电子元件精挑细选】:专业指南助你为降噪耳机挑选合适零件

# 摘要
随着个人音频设备技术的迅速发展,降噪耳机因其能够提供高质量的听觉体验而受到市场的广泛欢迎。本文从电子元件的角度出发,全面分析了降噪耳机的设计和应用。首先,我们探讨了影响降噪耳机性能的电子元件基础,包括声学元件、电源管理元件以及连接性与控制元
ARCGIS高手进阶:只需三步,高效创建1:10000分幅图!
# 摘要
本文深入探讨了ARCGIS环境下1:10000分幅图的创建与管理流程。首先,我们回顾了ARCGIS的基础知识和分幅图的理论基础,强调了1:10000比例尺的重要性以及地理信息处理中的坐标系统和转换方法。接着,详细阐述了分幅图的创建流程,包括数据的准备与导入、创建和编辑过程,以及输出格式和版本管理。文中还介绍了一些高级技巧,如自动化脚本的使用和空间分析,以
【数据质量保障】:Talend确保数据精准无误的六大秘诀
# 摘要
数据质量对于确保数据分析与决策的可靠性至关重要。本文探讨了Talend这一强大数据集成工具的基础和在数据质量管理中的高级应用。通过介绍Talend的核心概念、架构、以及它在数据治理、监控和报告中的功能,本文强调了Talend在数据清洗、转换、匹配、合并以及验证和校验等方面的实践应用。进一步地,文章分析了Talend在数据审计和自动化改进方面的高级功能,包括与机器学习技术的结合。最后,通过金融服务和医疗保健行业的案
【install4j跨平台部署秘籍】:一次编写,处处运行的终极指南

# 摘要
本文深入探讨了使用install4j工具进行跨平台应用程序部署的全过程。首先介绍了install4j的基本概念和跨平台部署的基础知识,接着详细阐述了其安装步骤、用户界面布局以及系统要求。在此基础上,文章进一步阐述了如何使用install4j创建具有高度定制性的安装程序,包括定义应用程序属性、配置行为和屏幕以及管理安装文件和目录。此外,本文还
【Quectel-CM AT命令集】:模块控制与状态监控的终极指南

# 摘要
本论文旨在全面介绍Quectel-CM模块及其AT命令集,为开发者提供深入的理解与实用指导。首先,概述Quectel-CM模块的基础知识与AT命令基础,接着详细解析基本通信、网络功能及模块配置命令。第三章专注于AT命令的实践应用,包括数据传输、状态监控
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )