基于opencv的疲劳驾驶检测在远程监控中的应用,打造智慧交通新模式
发布时间: 2024-08-12 05:44:45 阅读量: 18 订阅数: 27 

# 1. 基于 OpenCV 的疲劳驾驶检测概述**
疲劳驾驶是一种严重的交通安全隐患,它会显著降低驾驶员的反应能力和判断力,从而增加事故发生的风险。基于 OpenCV 的疲劳驾驶检测是一种通过计算机视觉技术识别和分析驾驶员生理特征来判断其疲劳状态的方法。
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,它提供了丰富的图像处理和分析功能。利用 OpenCV,我们可以从驾驶员的面部图像中提取瞳孔变化、眼睑下垂和点头动作等生理特征,并通过机器学习算法对其进行分类,从而判断驾驶员是否处于疲劳状态。
# 2.1 疲劳驾驶的生理特征
疲劳驾驶是一种由于驾驶员持续驾驶时间过长或睡眠不足导致的生理和心理状态,会严重影响驾驶员的驾驶能力,增加交通事故的风险。疲劳驾驶的生理特征主要表现在以下几个方面:
### 2.1.1 瞳孔变化
瞳孔是虹膜中央的孔洞,瞳孔的大小受交感神经和副交感神经的支配。当驾驶员处于疲劳状态时,交感神经活性降低,副交感神经活性增强,导致瞳孔直径增大。瞳孔直径的变化可以通过图像处理技术进行检测,从而判断驾驶员的疲劳程度。
### 2.1.2 眼睑下垂
眼睑下垂是指上眼睑下垂遮挡瞳孔,是疲劳驾驶的典型生理特征。当驾驶员处于疲劳状态时,眼部肌肉无力,导致上眼睑下垂。眼睑下垂可以通过图像处理技术进行检测,从而判断驾驶员的疲劳程度。
### 2.1.3 点头动作
点头动作是指头部前后摆动的动作,是疲劳驾驶的另一个典型生理特征。当驾驶员处于疲劳状态时,头部肌肉无力,容易出现点头动作。点头动作可以通过图像处理技术进行检测,从而判断驾驶员的疲劳程度。
**代码块:**
```python
import cv2
# 读取视频
video = cv2.VideoCapture('fatigue_driving.mp4')
# 初始化瞳孔检测器
pupil_detector = cv2.CascadeClassifier('pupil_detector.xml')
# 初始化眼睑下垂检测器
eyelid_detector = cv2.CascadeClassifier('eyelid_detector.xml')
# 初始化点头动作检测器
head_nodding_detector = cv2.CascadeClassifier('head_nodding_detector.xml')
while True:
# 读取帧
ret, frame = video.read()
if not ret:
break
# 瞳孔检测
pupils = pupil_detector.detectMultiScale(frame, 1.1, 5)
for (x, y, w, h) in pupils:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 眼睑下垂检测
eyelids = eyelid_detector.detectMultiScale(frame, 1.1, 5)
for (x, y, w, h) in eyelids:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 0, 255), 2)
# 点头动作检测
head_nodding = head_nodding_detector.detectMultiScale(frame, 1.1, 5)
for (x, y, w, h) in head_nodding:
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 显示帧
cv2.imshow('Fatigue Driving Detection', frame)
# 按下 q 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放视频
video.release()
# 销毁所有窗口
cv2.destroyAllWindows()
```
**代码逻辑分析:**
该代码使用 OpenCV 读取视频帧并进行疲劳驾驶检测。它使用级联分类器检测瞳孔、眼睑下垂和点头动作。检测到的特征用矩形框标记在帧上。
**参数说明:**
* `pupil_detector`:瞳孔检测器
* `eyelid_detector`:眼睑下垂检测器
* `head_nodding_detector`:点头动作检测器
* `frame`:视频帧
* `x`、`y`、`w`、`h`:矩形框的坐标和尺寸
# 3. 基于 OpenCV 的疲劳驾驶检测实践**
**3.1 数据采集与预处理**
**3.1.1 数据集介绍**
疲劳驾驶检测模型的训练和评估需要大量的标注数据。通常,可以使用现有的公开数据集,例如:
- [Kaggle 疲劳驾驶数据集](https://www.kaggle.com/datasets/andrewmvd/driver-drowsiness-detection)
- [NTHU 疲劳驾驶数据集](https://www.csie.nthu.edu.tw/~cjlin/drowsy_driver/)
这些数据集包含了大量驾驶员在不同疲劳程度下的图像或视频,并提供了相应的标注信息。
**3.1.2 数据增强技术**
为了提高模型的泛化能力,防止过拟合,可以使用数据增强技术来扩充数据集。常用的数据增强技术包括:
- **随机旋转:**对图像进行随机旋转,以模拟驾驶员头部在不同角度下的姿态。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了基于 OpenCV 图像处理技术的疲劳驾驶检测。通过涵盖人脸检测、特征提取、眼部特征分析、瞳孔检测、打哈欠检测、机器学习、系统设计、系统实现、模型部署、商业应用、远程监控、性能优化、故障排除和稳定性提升等各个方面,专栏全面介绍了疲劳驾驶检测的原理、技术和应用。旨在为读者提供全面的知识和见解,以了解如何利用 OpenCV 技术开发有效的疲劳驾驶检测系统,保障行车安全和提升驾驶体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据访问速度优化】:分片大小与数据局部性策略揭秘
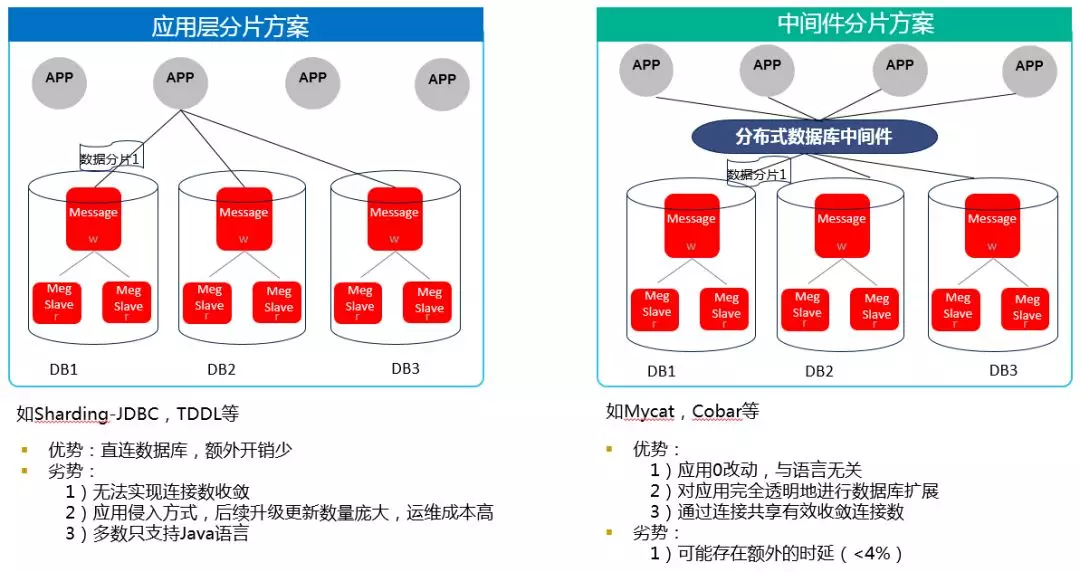
# 1. 数据访问速度优化概论
在当今信息化高速发展的时代,数据访问速度在IT行业中扮演着至关重要的角色。数据访问速度的优化,不仅仅是提升系统性能,它还可以直接影响用户体验和企业的经济效益。本章将带你初步了解数据访问速度优化的重要性,并从宏观角度对优化技术进行概括性介绍。
## 1.1 为什么要优化数据访问速度?
优化数据访问速度是确保高效系统性能的关键因素之一
【大数据精细化管理】:掌握ReduceTask与分区数量的精准调优技巧

# 1. 大数据精细化管理概述
在当今的信息时代,企业与组织面临着数据量激增的挑战,这要求我们对大数据进行精细化管理。大数据精细化管理不仅关系到数据的存储、处理和分析的效率,还直接关联到数据价值的最大化。本章节将概述大数据精细化管理的概念、重要性及其在业务中的应用。
大数据精细化管理涵盖从数据
【优化策略】:MapReduce编程模型下表连接算法的极致提升
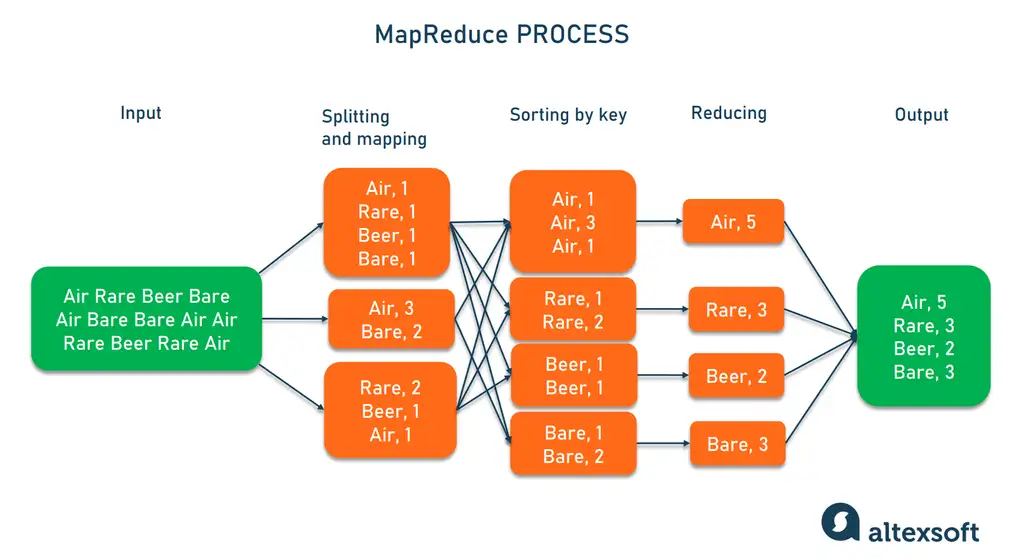
# 1. MapReduce编程模型概述
MapReduce是Hadoop生态系统中的核心组件,它通过将复杂的任务分解为两个关键操作—Map和Reduce,极大地简化了大规模数据处理的过程。在本章中,我们将探索MapReduce的基础概念、工作原理,以及它如何应对大数据分析的需求。
## 1.1 MapReduce的起源与发展
Map
MapReduce小文件处理:数据预处理与批处理的最佳实践

# 1. MapReduce小文件处理概述
## 1.1 MapReduce小文件问题的普遍性
在大规模数据处理领域,MapReduce小文件问题普遍存在,严重影响
MapReduce中的Combiner与Reducer选择策略:如何判断何时使用Combiner
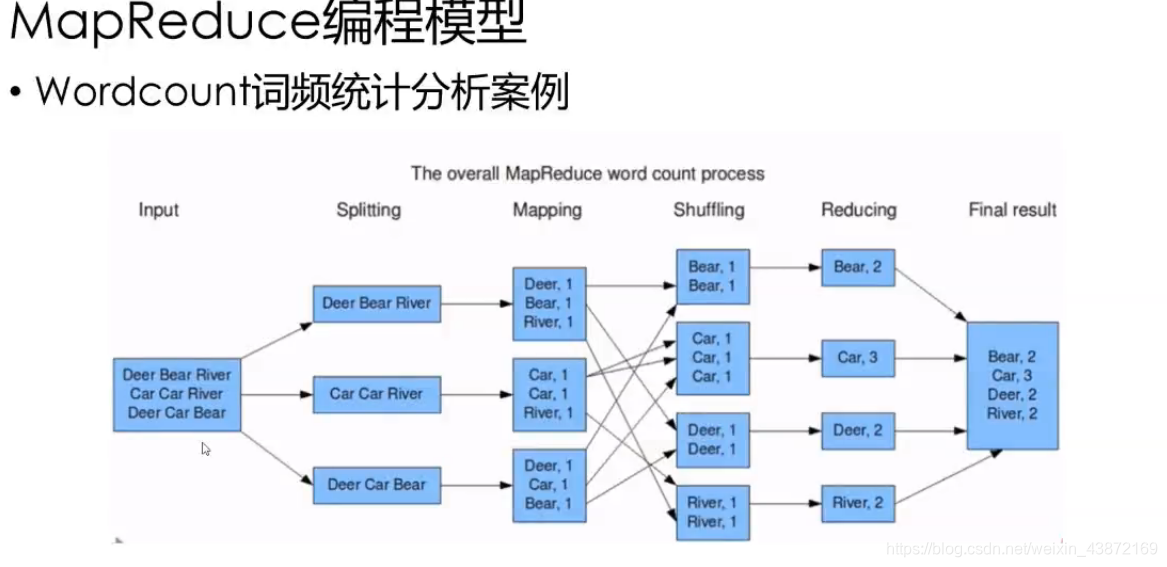
# 1. MapReduce框架基础
MapReduce 是一种编程模型,用于处理大规模数据集
项目中的Map Join策略选择
# 1. Map Join策略概述
Map Join策略是现代大数据处理和数据仓库设计中经常使用的一种技术,用于提高Join操作的效率。它主要依赖于MapReduce模型,特别是当一个较小的数据集需要与一个较大的数据集进行Join时。本章将介绍Map Join策略的基本概念,以及它在数据处理中的重要性。
Map Join背后的核心思想是预先将小数据集加载到每个Map任
MapReduce自定义分区:规避陷阱与错误的终极指导

# 1. MapReduce自定义分区的理论基础
MapReduce作为一种广泛应用于大数据处理的编程模型,其核心思想在于将计算任务拆分为Map(映射)和Reduce(归约)两个阶段。在MapReduce中,数据通过键值对(Key-Value Pair)的方式被处理,分区器(Partitioner)的角色是决定哪些键值对应该发送到哪一个Reducer。这种机制至关
【数据仓库Join优化】:构建高效数据处理流程的策略

# 1. 数据仓库Join操作的基础理解
## 数据库中的Join操作简介
在数据仓库中,Join操作是连接不同表之间数据的核心机制。它允许我们根据特定的字段,合并两个或多个表中的数据,为数据分析和决策支持提供整合后的视图。Join的类型决定了数据如何组合,常用的SQL Join类型包括INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN等。
## SQL Joi
MapReduce与大数据:挑战PB级别数据的处理策略

# 1. MapReduce简介与大数据背景
## 1.1 大数据的定义与特性
大数据(Big Data)是指传统数据处理应用软件难以处
跨集群数据Shuffle:MapReduce Shuffle实现高效数据流动

# 1. MapReduce Shuffle基础概念解析
## 1.1 Shuffle的定义与目的
MapReduce Shuffle是Hadoop框架中的关键过程,用于在Map和Reduce任务之间传递数据。它确保每个Reduce任务可以收到其处理所需的正确数据片段。Shuffle过程主要涉及数据的排序、分组和转移,目的是保证数据的有序性和局部性,以便于后续处理。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )