YOLO数据集格式转换的秘密:深入剖析不同格式之间的差异和转换方法
发布时间: 2024-08-16 10:45:43 阅读量: 113 订阅数: 24 

python编写脚本实现voc数据集格式转换yolo数据集格式的工具
# 1. YOLO数据集格式概述**
YOLO(You Only Look Once)是一种实时目标检测算法,需要特定格式的数据集才能训练和评估。YOLO数据集遵循特定的结构和组织方式,包含图像和对应的标注信息,用于识别和定位图像中的目标。
YOLO数据集通常包含以下信息:
- 图像:数据集中的图像通常是JPEG或PNG格式,表示待检测的场景。
- 标注:标注信息以文本文件或XML文件形式提供,包含每个目标的边界框坐标和类别标签。边界框坐标指定目标在图像中的位置和大小,而类别标签指示目标的类型(例如,行人、汽车、动物)。
# 2. YOLO数据集转换的理论基础
### 2.1 数据格式转换的基本原理
**2.1.1 数据结构和组织方式**
数据格式转换涉及将数据从一种结构和组织方式转换为另一种。不同数据集格式具有不同的数据结构和组织方式。例如,VOC格式使用XML文件存储图像和标注信息,而COCO格式使用JSON文件存储图像和标注信息。
**2.1.2 数据编码和解码算法**
数据编码和解码算法用于将数据从一种格式转换为另一种。编码算法将数据转换为特定格式,而解码算法将数据从特定格式转换为原始格式。例如,Base64编码算法将二进制数据转换为ASCII字符,而JSON解码算法将JSON字符串转换为Python对象。
### 2.2 数据格式转换的常见挑战
**2.2.1 数据完整性和一致性**
在数据格式转换过程中,确保数据完整性和一致性至关重要。数据完整性是指数据没有丢失或损坏,而数据一致性是指数据在不同格式之间保持一致。例如,在从VOC格式转换为COCO格式时,确保图像和标注信息都完整且一致。
**2.2.2 数据类型和范围转换**
不同数据集格式可能使用不同的数据类型和范围。例如,VOC格式使用浮点数存储坐标,而COCO格式使用整数存储坐标。在转换数据时,需要考虑数据类型和范围的转换,以避免数据丢失或精度问题。
#### 代码块:
```python
import cv2
import numpy as np
# 从VOC格式转换为COCO格式
def voc_to_coco(voc_path, coco_path):
with open(voc_path, 'r') as f:
voc_data = f.read()
# 解析VOC XML文件
voc_root = ET.fromstring(voc_data)
coco_data = {'images': [], 'annotations': []}
# 遍历VOC图像
for image_node in voc_root.findall('image'):
image_id = image_node.find('id').text
image_width = int(image_node.find('width').text)
image_height = int(image_node.find('height').text)
# 创建COCO图像字典
image_dict = {'id': int(image_id), 'width': image_width, 'height': image_height}
coco_data['images'].append(image_dict)
# 遍历VOC标注
for object_node in image_node.findall('object'):
category_id = int(object_node.find('category').text)
bbox = object_node.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
# 创建COCO标注字典
annotation_dict = {'image_id': int(image_id), 'category_id': category_id, 'bbox': [xmin, ymin, xmax - xmin, ymax - ymin]}
coco_data['annotations'].append(annotation_dict)
# 将COCO数据写入JSON文件
with open(coco_path, 'w') as f:
json.dump(coco_data, f)
```
#### 代码逻辑分析:
该代码块实现了从VOC格式到COCO格式的数据转换。它首先解析VOC XML文件,然后遍历VOC图像和标注,并创建相应的COCO图像和标注字典。最后,将COCO数据写入JSON文件。
#### 参数说明:
* `voc_path`:VOC XML文件路径
* `coco_path`:COCO JSON文件路径
#### 数据类型和范围转换:
该代码块中,VOC格式的坐标使用浮点数存储,而COCO格式的坐标使用整数存储。在转换过程中,代码将VOC格式的浮点数坐标转换为COCO格式的整数坐标。
# 3. YOLO数据集转换的实践指南
### 3.1 常用YOLO数据集格式
YOLO算法对数据集格式有特定的要求,常用的YOLO数据集格式主要有两种:
- **VOC格式(Pascal VOC)**:VOC格式是Pascal VOC挑战赛中使用的数据集格式,其文件结构包括:
- **Annotations文件夹**:存储XML格式的标注文件,其中包含图像中目标的位置、类别和边界框信息。
- **ImageSets文件夹**:存储训练、验证和测试集的图像列表文件。
- **JPEGImages文件夹**:存储图像文件。
- **COCO格式(Microsoft COCO)**:COCO格式是Microsoft COCO数据集挑战赛中使用的数据集格式,其文件结构包括:
- **annotations文件夹**:存储JSON格式的标注文件,其中包含图像中目标的位置、类别、分割掩码和关键点信息。
- **images文件夹**:存储图像文件。
- **instances_train2017.json**:训练集标注文件。
- **instances_val2017.json**:验证集标注文件。
### 3.2 数据格式转换工具和库
为了方便不同数据集格式之间的转换,提供了多种工具和库:
- **OpenCV**:OpenCV是一个强大的计算机视觉库,提供了丰富的图像处理和数据转换功能。它支持多种数据集格式的读写,包括VOC和COCO格式。
```python
import cv2
# 读取VOC格式标注文件
annotations = cv2.imread('path/to/annotation.xml')
# 读取COCO格式标注文件
annotations = cv2.load('path/to/annotation.json')
```
- **Pillow**:Pillow是一个Python图像处理库,提供了图像加载、处理和保存功能。它支持多种图像格式,包括VOC和COCO格式。
```python
from PIL import Image
# 读取VOC格式图像
image = Image.open('path/to/image.jpg')
# 读取COCO格式图像
image = Image.open('path/to/image.jpg').convert('RGB')
```
# 4. YOLO数据集转换的进阶技巧
### 4.1 数据增强和预处理
#### 4.1.1 数据扩充技术
数据扩充是一种通过修改现有数据来创建新数据的方法,以增加数据集的大小和多样性。对于YOLO数据集,常用的数据扩充技术包括:
- **随机裁剪:**从原始图像中随机裁剪出不同大小和纵横比的区域。
- **随机翻转:**水平或垂直翻转图像,以增加图像的多样性。
- **随机旋转:**将图像旋转一定角度,以模拟相机运动或物体旋转。
- **颜色抖动:**改变图像的亮度、对比度、饱和度和色调,以增加图像的鲁棒性。
- **添加噪声:**向图像添加高斯噪声或椒盐噪声,以模拟真实世界中的噪声条件。
#### 4.1.2 数据归一化和标准化
数据归一化和标准化是将数据值缩放或转换到特定范围内的过程,以提高模型训练的效率和精度。对于YOLO数据集,常用的归一化和标准化技术包括:
- **归一化:**将数据值缩放至[0, 1]或[-1, 1]的范围内。
- **标准化:**将数据值减去均值并除以标准差,使其具有零均值和单位方差。
### 4.2 数据格式转换的性能优化
#### 4.2.1 并行化和多线程处理
并行化和多线程处理可以提高数据格式转换的性能,尤其是在处理大型数据集时。通过将转换任务分配给多个线程或进程,可以同时处理多个数据块,从而缩短转换时间。
#### 4.2.2 内存管理和数据缓存
内存管理和数据缓存对于优化数据格式转换的性能至关重要。通过有效管理内存,可以避免内存不足错误并提高转换速度。数据缓存可以将频繁访问的数据存储在内存中,以减少对硬盘的访问次数,从而提高性能。
```python
import numpy as np
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 将图像转换为 YOLO 格式
labels = np.array([
[0.5, 0.5, 0.2, 0.2], # 类别 0,边界框 [x, y, w, h]
[0.7, 0.7, 0.3, 0.3] # 类别 1,边界框 [x, y, w, h]
])
yolo_format = np.concatenate((image, labels), axis=2)
# 保存 YOLO 格式的图像
cv2.imwrite('image_yolo.jpg', yolo_format)
```
**代码逻辑分析:**
1. 读取图像并将其存储在 `image` 变量中。
2. 创建一个 `labels` 数组,其中包含边界框信息和类别标签。
3. 使用 `np.concatenate` 将图像和标签数组连接在一起,形成 YOLO 格式的数据。
4. 将 YOLO 格式的数据保存到文件 `image_yolo.jpg` 中。
**参数说明:**
- `cv2.imread(filename)`:读取图像文件并返回一个 NumPy 数组。
- `np.concatenate(arrays, axis)`:将多个数组连接在一起,`axis` 指定连接的轴。
- `cv2.imwrite(filename, image)`:将图像写入文件。
# 5. YOLO 数据集转换的特殊应用
### 5.1 YOLO 数据集格式转换在目标检测中的应用
#### 5.1.1 目标检测模型的训练和评估
YOLO 数据集格式转换在目标检测中发挥着至关重要的作用,因为它提供了将原始数据转换为目标检测模型所需格式的能力。目标检测模型需要训练和评估,而 YOLO 数据集格式转换可以确保数据以兼容的方式呈现,以便模型可以有效地处理和学习。
#### 5.1.2 目标检测数据集的创建和管理
YOLO 数据集格式转换还允许创建和管理目标检测数据集。通过将数据转换为 YOLO 格式,可以轻松地组织和标记数据,以便用于训练和评估目标检测模型。这对于创建高质量的数据集至关重要,该数据集可以提高模型的准确性和性能。
### 5.2 YOLO 数据集格式转换在图像分类中的应用
#### 5.2.1 图像分类模型的训练和评估
YOLO 数据集格式转换在图像分类中也有应用。图像分类模型需要训练和评估,而 YOLO 数据集格式转换可以确保数据以兼容的方式呈现,以便模型可以有效地处理和学习。
#### 5.2.2 图像分类数据集的创建和管理
YOLO 数据集格式转换还允许创建和管理图像分类数据集。通过将数据转换为 YOLO 格式,可以轻松地组织和标记数据,以便用于训练和评估图像分类模型。这对于创建高质量的数据集至关重要,该数据集可以提高模型的准确性和性能。
# 6. YOLO数据集格式转换的未来展望
### 6.1 新兴数据格式和转换技术
随着计算机视觉和机器学习领域的不断发展,新的数据格式和转换技术不断涌现,为YOLO数据集转换提供了更多选择和可能性。
**6.1.1 TFRecord格式**
TFRecord是一种由TensorFlow开发的二进制文件格式,用于存储结构化数据。它具有以下优点:
- 高效压缩:TFRecord可以有效地压缩数据,从而减少存储空间和传输时间。
- 并行读取:TFRecord支持并行读取,可以提高数据读取速度。
- 灵活的架构:TFRecord的架构灵活,可以存储各种类型的数据,包括图像、文本和数字。
**6.1.2 Parquet格式**
Parquet是一种列式存储格式,专为大数据分析而设计。它具有以下优点:
- 高性能:Parquet的列式存储结构可以提高数据查询和分析的性能。
- 可扩展性:Parquet支持大数据量,可以轻松扩展到TB级甚至PB级的数据集。
- 跨平台兼容性:Parquet是一种跨平台兼容的格式,可以在多种编程语言和工具中使用。
### 6.2 数据格式转换的自动化和标准化
为了简化和标准化YOLO数据集转换过程,正在开发各种框架和标准。
**6.2.1 数据格式转换框架**
数据格式转换框架提供了一个通用的平台,可以将不同格式的数据转换为YOLO格式。这些框架通常包含预定义的转换器和管道,可以自动执行转换过程。
**6.2.2 数据格式转换标准**
数据格式转换标准定义了YOLO数据集转换的通用规范,确保不同工具和框架之间的数据兼容性。这些标准有助于促进数据共享和协作。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“YOLO数据集格式转换”专栏,您的终极指南,从入门到精通。本专栏深入探讨了YOLO数据集格式转换的各个方面,涵盖从文件结构和数据格式到不同格式之间的转换方法。我们揭秘了转换背后的原理,并提供了实战手册,解决常见问题并优化转换效率。此外,我们还探讨了转换对数据增强、模型训练、部署和推理的影响。通过利用工具和脚本,我们提供了自动化转换的秘籍。最后,我们分享了最佳实践、案例研究以及转换在数据科学、机器学习、深度学习、计算机视觉、人工智能、大数据、云计算和边缘计算中的应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Windows系统性能升级】:一步到位的WinSXS清理操作手册
# 摘要
本文针对Windows系统性能升级提供了全面的分析与指导。首先概述了WinSXS技术的定义、作用及在系统中的重要性。其次,深入探讨了WinSXS的结构、组件及其对系统性能的影响,特别是在系统更新过程中WinSXS膨胀的挑战。在此基础上,本文详细介绍了WinSXS清理前的准备、实际清理过程中的方法、步骤及
Lego性能优化策略:提升接口测试速度与稳定性
# 摘要
随着软件系统复杂性的增加,Lego性能优化变得越来越重要。本文旨在探讨性能优化的必要性和基础概念,通过接口测试流程和性能瓶颈分析,识别和解决性能问题。文中提出多种提升接口测试速度和稳定性的策略,包括代码优化、测试环境调整、并发测试策略、测试数据管理、错误处理机制以及持续集成和部署(CI/CD)的实践。此外,本文介绍了性能优化工具和框架的选择与应用,并
UL1310中文版:掌握电源设计流程,实现从概念到成品

# 摘要
本文系统地探讨了电源设计的全过程,涵盖了基础知识、理论计算方法、设计流程、实践技巧、案例分析以及测试与优化等多个方面。文章首先介绍了电源设计的重要性、步骤和关键参数,然后深入讲解了直流变换原理、元件选型以及热设计等理论基础和计算方法。随后,文章详细阐述了电源设计的每一个阶段,包括需求分析、方案选择、详细设计、仿真
Redmine升级失败怎么办?10分钟内安全回滚的完整策略
# 摘要
本文针对Redmine升级失败的问题进行了深入分析,并详细介绍了安全回滚的准备工作、流程和最佳实践。首先,我们探讨了升级失败的潜在原因,并强调了回滚前准备工作的必要性,包括检查备份状态和设定环境。接着,文章详解了回滚流程,包括策略选择、数据库操作和系统配置调整。在回滚完成后,文章指导进行系统检查和优化,并分析失败原因以便预防未来的升级问题。最后,本文提出了基于案例的学习和未来升级策
频谱分析:常见问题解决大全

# 摘要
频谱分析作为一种核心技术,对现代电子通信、信号处理等领域至关重要。本文系统地介绍了频谱分析的基础知识、理论、实践操作以及常见问题和优化策略。首先,文章阐述了频谱分析的基本概念、数学模型以及频谱分析仪的使用和校准问题。接着,重点讨论了频谱分析的关键技术,包括傅里叶变换、窗函数选择和抽样定理。文章第三章提供了一系列频谱分析实践操作指南,包括噪声和谐波信号分析、无线信号频谱分析方法及实验室实践。第四章探讨了频谱分析中的常见问题和解决
SECS-II在半导体制造中的核心角色:现代工艺的通讯支柱
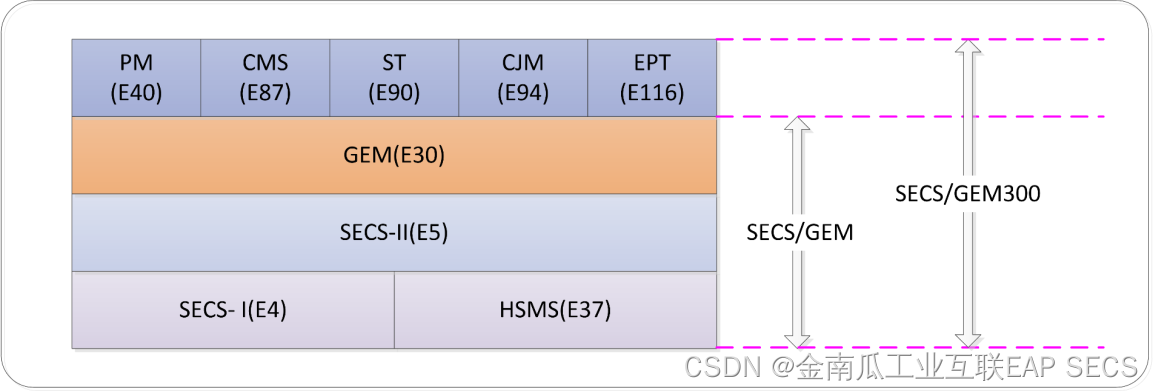
# 摘要
SECS-II标准作为半导体行业中设备通信的关键协议,对提升制造过程自动化和设备间通信效率起着至关重要的作用。本文首先概述了SECS-II标准及其历史背景,随后深入探讨了其通讯协议的理论基础,包括架构、组成、消息格式以及与GEM标准的关系。文章进一步分析了SECS-II在实践应用中的案例,涵盖设备通信实现、半导体生产应用以及软件开发与部署。同时,本文还讨论了SECS-II在现代半导体制造
深入探讨最小拍控制算法

# 摘要
最小拍控制算法是一种用于实现快速响应和高精度控制的算法,它在控制理论和系统建模中起着核心作用。本文首先概述了最小拍控制算法的基本概念、特点及应用场景,并深入探讨了控制理论的基础,包括系统稳定性的分析以及不同建模方法。接着,本文对最小拍控制算法的理论推导进行了详细阐述,包括其数学描述、稳定性分析以及计算方法。在实践应用方面,本文分析了最小拍控制在离散系统中的实现、
【Java内存优化大揭秘】:Eclipse内存分析工具MAT深度解读

# 摘要
本文深入探讨了Java内存模型及其优化技术,特别是通过Eclipse内存分析工具MAT的应用。文章首先概述了Java内存模型的基础知识,随后详细介绍MAT工具的核心功能、优势、安装和配置步骤。通过实战章节,本文展示了如何使用MAT进行堆转储文件分析、内存泄漏的检测和诊断以及解决方法。深度应用技巧章节深入讲解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )