利用 Elasticsearch 进行实时数据分析的方法探究
发布时间: 2024-05-01 11:12:52 阅读量: 67 订阅数: 48 

# 1. Elasticsearch概述**
Elasticsearch是一个开源、分布式、基于Lucene构建的搜索引擎。它以其高扩展性、高可用性和实时搜索能力而著称。Elasticsearch主要用于存储和检索大量结构化和非结构化数据,并提供强大的搜索和分析功能。
Elasticsearch采用倒排索引结构,可以快速高效地检索数据。它还支持多种数据类型,包括文本、数字、日期和地理位置,并提供丰富的查询语言,允许用户灵活地查询和过滤数据。此外,Elasticsearch具有强大的分析功能,可以对数据进行聚合、分组和相关性排序,帮助用户从数据中提取有价值的见解。
# 2. Elasticsearch数据建模与索引
### 2.1 数据建模原则
Elasticsearch中的数据建模遵循以下原则:
- **非关系型:**Elasticsearch是一个非关系型数据库,这意味着数据不是存储在表中,而是存储在文档中。
- **扁平化:**Elasticsearch文档是扁平化的,这意味着它们不包含嵌套结构。
- **动态类型:**Elasticsearch字段可以具有动态类型,这意味着它们可以存储不同类型的数据,例如字符串、数字和日期。
- **可扩展性:**Elasticsearch文档可以随着时间的推移而扩展,这意味着可以添加新字段而无需重新索引数据。
### 2.2 索引设计与优化
索引是Elasticsearch中用于快速查找和检索数据的结构。索引设计对于Elasticsearch的性能至关重要。
**索引设计原则:**
- **选择正确的字段:**索引字段应包含经常用于查询和过滤的数据。
- **使用分词器:**分词器将文本字段分解为单独的词条,以提高全文搜索的效率。
- **优化字段类型:**选择与数据类型相匹配的字段类型,例如字符串、数字和日期。
- **使用索引模板:**索引模板允许您为具有类似结构的索引定义通用的索引设置。
**索引优化技术:**
- **合并索引:**合并多个小索引以提高性能。
- **刷新和刷新间隔:**控制索引更新的频率以优化性能。
- **副本和分片:**创建索引副本和分片以提高可用性和可伸缩性。
### 2.3 文档类型与映射
文档类型用于定义文档的结构和字段。映射定义每个字段的属性,例如类型、分词器和默认值。
**文档类型:**
- **用于逻辑分组:**文档类型可用于将具有相似结构的文档分组。
- **支持多类型索引:**一个索引可以包含多个文档类型。
**映射:**
- **定义字段属性:**映射定义每个字段的类型、分词器和默认值。
- **动态映射:**Elasticsearch可以自动为新字段创建映射,但可以禁用此功能以提高性能。
- **类型转换:**映射可以定义类型转换规则,例如将字符串转换为数字。
**代码示例:**
```json
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "standard"
},
"author": {
"type": "keyword"
},
"publish_date": {
"type": "date"
}
}
}
}
```
**代码逻辑分析:**
此映射定义了一个名为"books"的文档类型,其中包含三个字段:"title"、"author"和"publish_date"。
- "title"字段是一个文本字段,使用标准分词器进行分词。
- "author"字段是一个关键字字段,表示精确匹配。
- "publish_date"字段是一个日期字段,用于存储日期值。
# 3. Elasticsearch查询与分析
### 3.1 基本查询语法
Elasticsearch查询语法基于JSON,提供了一种灵活且强大的方式来检索数据。基本查询语法包括:
- **term查询:**精确匹配指定字段的值,语法为:`{ "field_name": "value" }`
- **range查询:**匹配指定字段值范围内的文档,语法为:`{ "field_name": { "gte": start, "lte": end } }`
- **prefix查询:**匹配指定字段值前缀的文档,语法为:`{ "field_name": { "prefix": "prefix_value" } }`
- **wildcard查询:**匹配指定字段值中包含通配符(* 或 ?)的文档,语法为:`{ "field_name": { "wildcard": "wildcard_pattern" } }`
- **bool查询:**组合多个查询,使用AND、OR、NOT等操作符,语法为:`{ "bool": { "must": [query1, query2], "should": [query3, query4], "must_not": [query5] } }`
### 3.2 聚合与分组分析
Elasticsearch聚合允许对搜索结果进行分组、统计和汇总。常见的聚合类型包括:
- **count聚合:**计算匹配文档的数量
- **sum聚合:**计算指定字段值的总和
- **avg聚合:**计算指定字段值的平均值
- **max聚合:**计算指定字段值的最高值
- **min聚合:**计算指定字段值的最低值
聚合还可以与分组结合使用,将文档分组到不同的桶中,并在每个桶上执行聚合。
### 3.3 全文搜索与相关性排序
Elasticsearch提供全文搜索功能,可以搜索文档中的文本字段。相关性排序用于根据文档与查询的相关性对搜索结果进行排序。
全文搜索使用倒排索引,将每个单词映射到包含该单词的文档列表。相关性排序算法考虑因素包括:
- **词频(TF):**单词在文档中出现的次数
- **逆文档频率(IDF):**单词在整个索引中出现的文档数量
- **文档长度:**文档的长度
- **查询长度:**查询的长度
通过调整这些因素的权重,可以优化相关性排序算法以满足特定需求。
# 4. Elasticsearch实时数据分析
### 4.1 流式数据摄取与处理
实时数据分析需要实时摄取和处理数据流。Elasticsearch提供了多种流式数据摄取机制,包括:
- **Logstash:** 一种流行的日志解析和管道工具,可以将数据从各种来源(如日志文件、消息队列)摄取到Elasticsearch。
- **Beats:** 轻量级的代理,用于从系统、应用程序和云服务收集指标和事件数据。
- **Kafka Connect:** 一个连接器框架,允许将数据从Kafka主题流式传输到Elasticsearch。
数据摄取后,需要进行处理以使其适合分析。Elasticsearch提供了以下处理管道:
- **Ingest Node Pipeline:** 在索引文档之前应用转换和丰富操作。
- **Painless Scripting:** 一种脚本语言,用于在索引时动态修改文档。
- **GeoIP Enrichment:** 使用GeoIP数据丰富文档,以提供地理位置信息。
### 4.2 实时分析管道
Elasticsearch提供了强大的实时分析管道,允许在数据摄取后立即执行分析。这些管道包括:
- **Transform:** 允许将数据从一个索引转换到另一个索引,并应用转换和聚合。
- **Rollup:** 创建汇总索引,以提供按时间或其他维度分组的数据的汇总视图。
- **Machine Learning:** 使用机器学习算法检测异常、预测趋势和识别模式。
### 4.3 实时仪表板与可视化
为了监控和可视化实时数据分析的结果,Elasticsearch提供了以下工具:
- **Kibana:** 一个开源的可视化平台,用于创建仪表板、图表和地图。
- **Dashboards:** 可定制的仪表板,显示来自不同来源的数据。
- **Timelion:** 一个交互式可视化工具,用于探索和分析时间序列数据。
**代码块:**
```
# 使用 Logstash 将日志数据摄取到 Elasticsearch
input {
file {
path => "/var/log/nginx/access.log"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "nginx-access-logs"
}
}
```
**逻辑分析:**
此Logstash配置将从`/var/log/nginx/access.log`文件中摄取Nginx访问日志。它使用Grok过滤器将日志消息解析为结构化字段,然后将数据输出到Elasticsearch中的“nginx-access-logs”索引。
**Mermaid流程图:**
```mermaid
sequenceDiagram
participant User
participant Logstash
participant Elasticsearch
User ->> Logstash: Send log data
Logstash ->> Elasticsearch: Parse and index data
```
**表格:**
| 工具 | 功能 |
|---|---|
| Logstash | 日志解析和管道 |
| Beats | 系统和应用程序监控 |
| Ingest Node Pipeline | 索引前转换和丰富 |
| Transform | 索引间转换和聚合 |
| Kibana | 可视化平台 |
| Dashboards | 可定制仪表板 |
# 5.1 日志分析与监控
日志分析是Elasticsearch最常见的应用之一。通过将日志数据索引到Elasticsearch中,可以方便地进行实时搜索、过滤和分析,从而快速发现问题、进行故障排除和提高系统性能。
### 日志数据采集
日志数据采集可以通过多种方式进行,例如:
- 使用Logstash等日志收集工具
- 直接通过Elasticsearch API或客户端写入日志
- 使用Beats等轻量级数据采集代理
### 日志数据建模
日志数据通常包含大量非结构化文本,需要进行建模才能有效分析。Elasticsearch提供了强大的数据建模功能,可以将日志数据映射到特定的字段和数据类型。
### 日志数据分析
日志分析可以帮助解决以下问题:
- **错误和异常检测:**搜索特定错误消息或异常代码,快速识别系统问题。
- **性能监控:**分析响应时间、请求数等指标,监控系统性能。
- **安全审计:**跟踪用户活动、登录和注销事件,进行安全审计和合规性检查。
### 实例:故障排除
假设一个Web服务器出现500错误,可以通过Elasticsearch进行以下故障排除:
```bash
# 搜索所有500错误日志
GET /logs/_search
{
"query": {
"match": {
"status_code": 500
}
}
}
```
```bash
# 聚合错误消息,找出最常见的错误
GET /logs/_search
{
"size": 0,
"aggs": {
"top_errors": {
"terms": {
"field": "error_message"
}
}
}
}
```
通过分析聚合结果,可以快速找出导致500错误的最常见原因。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏简介
《Elasticsearch深入解析与实战》专栏全面深入地剖析了Elasticsearch的各个方面,从基本概念到高级应用。专栏包含一系列文章,涵盖了索引创建和管理、全文搜索、分词器、查询DSL语法、排序和聚合、文档更新和删除、高可用集群、性能调优、备份和恢复、与Kibana协同使用、数据管道处理、地理空间搜索、安全机制、与Logstash集成、索引优化、实时数据分析、故障诊断、监控和警报、数据备份和灾难恢复、近实时分析、索引模板和映射配置、多字段联合搜索、文档版本管理、升级和版本迁移、自定义聚合分析、机器学习应用、监控和日志记录管理、高级性能调优和集群扩展、与其他大数据平台集成等主题。本专栏旨在为读者提供全面深入的Elasticsearch知识和实践指导,帮助他们充分利用Elasticsearch的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【系统恢复101】:黑屏后的应急操作,基础指令的权威指南

# 摘要
系统恢复是确保计算环境连续性和数据安全性的关键环节。本文从系统恢复的基本概念出发,详细探讨了操作系统的启动原理,包括BIOS/UEFI阶段和引导加载阶段的解析以及启动故障的诊断与恢复选项。进一步,本文深入到应急模式下的系统修复技术,涵盖了命令行工具的使用、系统配置文件的编辑以及驱动和
【电子元件检验案例分析】:揭秘成功检验的关键因素与常见失误

# 摘要
电子元件检验是确保电子产品质量与性能的基础环节,涉及对元件分类、特性分析、检验技术与标准的应用。本文从理论和实践两个维度详细介绍了电子元件检验的基础知识,重点阐述了不同检验技术的应用、质量控制与风险管理策略,以及如何从检验数据中持续改进与创新。文章还展望了未来电子元件检验技术的发展趋势,强调了智能化、自动化和跨学科合作的重
【PX4性能优化】:ECL EKF2滤波器设计与调试
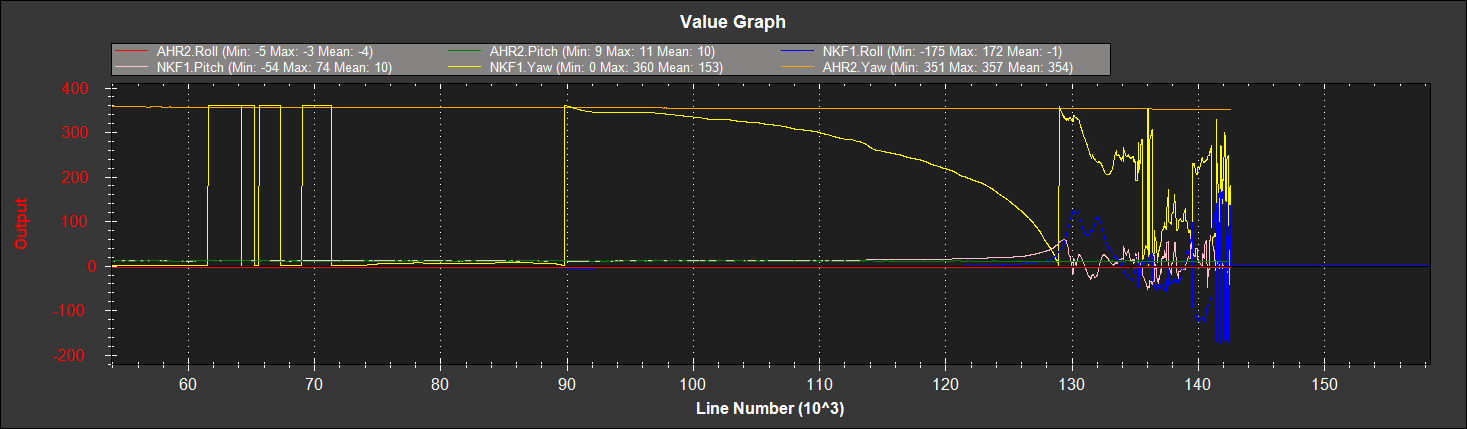
# 摘要
本文综述了PX4性能优化的关键技术,特别是在滤波器性能优化方面。首先介绍了ECL EKF2滤波器的基础知识,包括其工作原理和在PX4中的角色。接着,深入探讨了ECL EKF2的配置参数及其优化方法,并通过性能评估指标分析了该滤波器的实际应用效果。文章还提供了详细的滤波器调优实践,包括环境准备、系统校准以及参数调整技
【802.3BS-2017物理层详解】:如何应对高速以太网的新要求

# 摘要
随着互联网技术的快速发展,高速以太网成为现代网络通信的重要基础。本文对IEEE 802.3BS-2017标准进行了全面的概述,探讨了高速以太网物理层的理论基础、技术要求、硬件实现以及测试与验证。通过对物理层关键技术的解析,包括信号编码技术、传输介质、通道模型等,本文进一步分析了新标准下高速以太网的速率和距离要求,信号完整性与链路稳定性,并讨论了功耗和环境适应性问题。文章还介绍了802.3
Linux用户管理与文件权限:笔试题全解析,确保数据安全
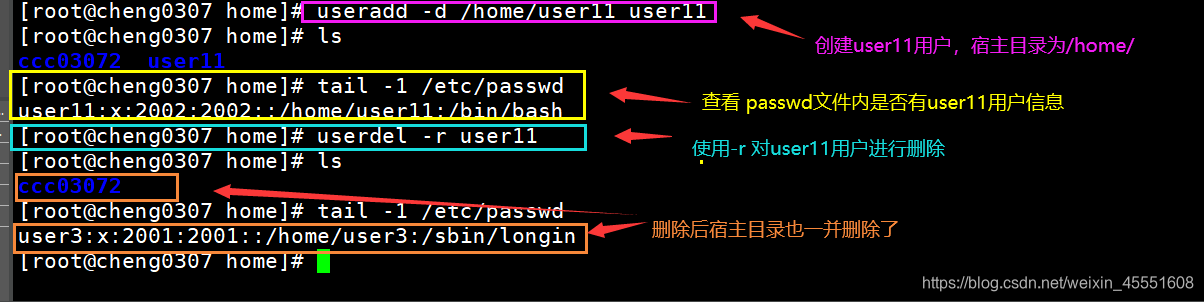
# 摘要
本论文详细介绍了Linux系统中用户管理和文件权限的管理与配置。从基础的用户管理概念和文件权限设置方法开始,深入探讨了文件权
Next.js数据策略:API与SSG融合的高效之道

# 摘要
Next.js是一个流行且功能强大的React框架,支持服务器端渲染(SSR)和静态站点生成(SSG)。本文详细介绍了Next.js的基础概念,包括SSG的工作原理及其优势,并探讨了如何高效构建静态页面,以及如何将API集成到Next.js项目中实现数据的动态交互和页面性能优化。此外,本文还展示了在复杂应用场景中处理数据的案例,并探讨了Next.js数据策略的
STM32F767IGT6无线通信宝典:Wi-Fi与蓝牙整合解决方案
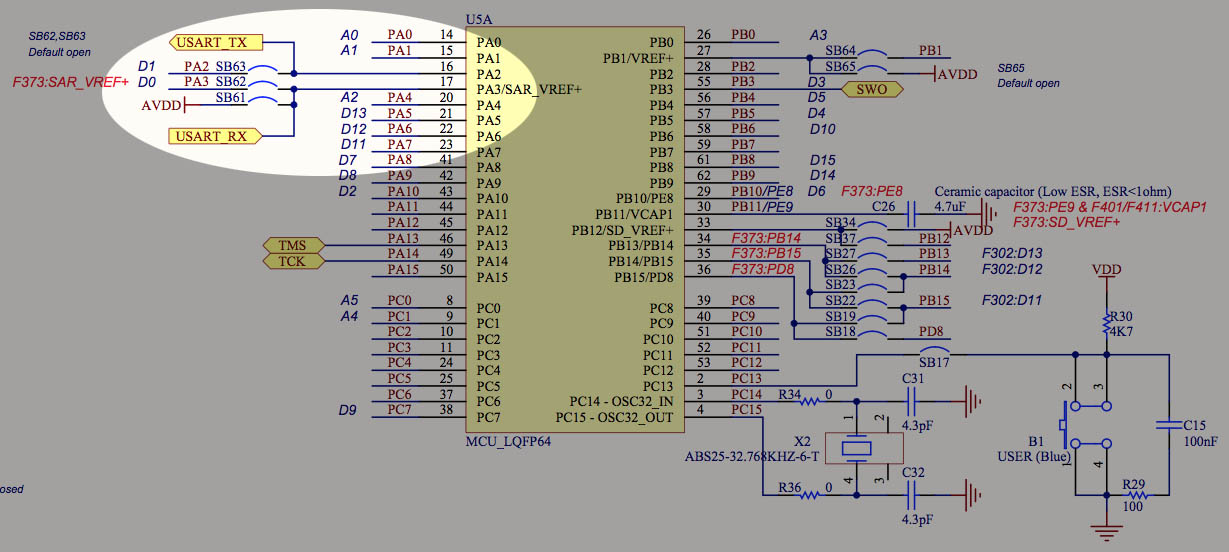
# 摘要
本论文系统地探讨了STM32F767IGT6微控制器在无线通信领域中的应用,重点介绍了Wi-Fi和蓝牙模块的集成与配置。首先,从硬件和软件两个层面讲解了Wi-Fi和蓝牙模块的集成过程,涵盖了连接方式、供电电路设计以及网络协议的配置和固件管理。接着,深入讨论了蓝牙技术和Wi-Fi通信的理论基础,及其在实际编程中的应用。此外,本论文还提
【CD4046精确计算】:90度移相电路的设计方法(工程师必备)

# 摘要
本文全面介绍了90度移相电路的基础知识、CD4046芯片的工作原理及特性,并详细探讨了如何利用CD4046设计和实践90度移相电路。文章首先阐述了90度移相电路的基本概念和设计要点,然后深入解析了CD4046芯片的内部结构和相位锁环(PLL)工作机制,重点讲述了基于CD4046实现精确移相的理论和实践案例。此外,本文还提供了电路设计过程中的仿真分析、故障排除技巧,以及如何应对常见问题。文章最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )