Elasticsearch 与 Kibana 的协同使用技巧
发布时间: 2024-05-01 11:04:12 阅读量: 72 订阅数: 48 

kibana-4.6.1 搭配elasticsearch2.4.4使用
# 2.1 Elasticsearch数据模型和索引结构
Elasticsearch采用了一种基于JSON的文档导向数据模型,将数据存储为一系列文档,每个文档都包含一个唯一的ID和一个或多个字段。字段可以是各种类型,包括字符串、数字、日期和布尔值。
文档被组织成索引,索引又进一步细分为分片。分片是索引的水平分区,允许在多个服务器上分布数据,从而提高可扩展性和性能。每个分片都包含索引中所有文档的副本,确保数据冗余和高可用性。
# 2. Elasticsearch数据索引与查询
### 2.1 Elasticsearch数据模型和索引结构
#### 2.1.1 文档、字段和类型
Elasticsearch中的数据以文档的形式存储,每个文档由一组字段组成,字段是文档中特定信息的键值对。字段可以是不同的数据类型,如字符串、数字、布尔值或日期。
类型是文档的逻辑分组,可以将具有相似结构和目的的文档组织在一起。类型在Elasticsearch 7.0版本中已弃用,但仍然可以用于较旧的版本。
#### 2.1.2 索引和分片
索引是Elasticsearch中存储和检索文档的逻辑容器。索引可以包含多个分片,分片是索引的水平分区,可以分布在不同的服务器上。分片可以提高查询和索引性能,因为它们允许并行处理请求。
### 2.2 Elasticsearch查询语言(ESQL)
#### 2.2.1 基本查询语法
ESQL(Elasticsearch查询语言)是一种基于JSON的查询语言,用于从Elasticsearch中检索数据。基本查询语法包括:
- `match`:匹配特定字段中的文本或值
- `term`:匹配特定字段中的确切值
- `range`:匹配指定范围内的值
- `bool`:组合多个查询条件
#### 2.2.2 高级查询特性
ESQL还支持高级查询特性,如:
- `nested`:查询嵌套文档
- `script`:使用脚本自定义查询条件
- `geo_distance`:根据地理距离进行查询
- `aggregations`:聚合查询结果以获取统计信息
### 代码示例
```
GET /my-index/_search
{
"query": {
"match": {
"title": "Elasticsearch"
}
}
}
```
**代码逻辑分析:**
此查询使用`match`查询条件来查找`my-index`索引中标题字段包含`"Elasticsearch"`的文档。
**参数说明:**
- `GET`:HTTP请求方法,用于检索数据
- `my-index`:要查询的索引名称
- `_search`:搜索端点
- `query`:查询条件,用于指定要匹配的字段和值
# 3. Kibana数据可视化与分析
### 3.1 Kibana仪表盘和图表
#### 3.1.1 创建仪表盘和图表
Kibana提供了直观的界面,用于创建自定义仪表盘和图表,以可视化和分析Elasticsearch中的数据。
1. **创建仪表盘:**在Kibana主菜单中,单击“仪表盘”选项卡,然后单击“创建仪表盘”按钮。
2. **添加图表:**在仪表盘画布上,单击“添加”按钮,然后选择要创建的图表类型。
3. **配置图表:**为图表选择数据源、指标和可视化设置。
4. **布局和定制:**使用拖放功能安排图表,并使用颜色、字体和布局选项自定义仪表盘的外观。
#### 3.1.2 定制化可视化效果
Kibana允许对图表进行高度定制,以满足特定需求。
1. **数据转换:**使用转换管道操作数据,例如过滤、聚合和排序。
2. **图表类型:**从各种图表类型中进行选择,包括条形图、折线图、饼图和散点图。
3. **视觉效果:**使用颜色、形状和大小来增强图表的可读性和可理解性。
4. **交互性:**添加交互式元素,例如工具提示、钻取和筛选,以提供更深入的数据探索。
### 3.2 Kibana数据探索和分析
#### 3.2.1 数据过滤和聚合
Kibana提供强大的数据过滤和聚合功能,用于识别趋势、模式和异常。
1. **过滤:**使用查询语言(如Lucene查询语法)过滤数据,以专注于特定子集。
2. **聚合:**使用聚合函数(如求和、求平均值和求计数)将数据分组并汇总。
3. **数据探索:**通过交互式可视化界面探索数据,并使用工具提示和钻取功能获取更详细的信息。
#### 3.2.2 异常检测和趋势分析
Kibana包含高级分析功能,用于检测异常值和识别趋势。
1. **异常检测:**使用机器学习算法检测数据中的异常值,例如异常峰值或异常模式。
2. **趋势分析:**使用时间序列可视化和预测模型分析数据中的趋势,并预测未来值。
3. **预测建模:**使用统计模型和机器学习技术对数据进行建模,并预测未来的结果。
# 4. Elasticsearch与Kibana集成
### 4.1 Elasticsearch与Kibana的通信机制
#### 4.1.1 REST API和JSON格式
Elasticsearch与Kibana之间的通信主要通过REST API进行,使用JSON格式传输数据。REST API提供了对Elasticsearch集群的统一访问接口,允许Kibana执行各种操作,如索引文档、执行查询和检索数据。
**代码块:使用REST API创建索引**
```
curl -X PUT "http://localhost:9200/my-index" -H 'Content-Type: application/json' -d '{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"title": { "type": "text" },
"body": { "type": "text" }
}
}
}'
```
**逻辑分析:**
此代码使用REST API创建名为“my-index”的索引。它指定了分片和副本的数量,并定义了两个字段(“title”和“body”)的映射。
**参数说明:**
* **-X PUT:**指定HTTP请求方法为PUT,用于创建索引。
* **-H 'Content-Type: application/json':**指定请求内容类型为JSON。
* **-d '...':**指定要发送到Elasticsearch的JSON数据。
#### 4.1.2 插件和扩展
除了REST API,Kibana还支持插件和扩展,以增强其功能。插件可以添加新的可视化类型、数据源和分析功能。扩展允许用户自定义Kibana的界面和行为。
**代码块:安装Kibana插件**
```
bin/kibana-plugin install x-pack
```
**逻辑分析:**
此代码安装了x-pack插件,它提供了安全、监控和报告等高级功能。
**参数说明:**
* **bin/kibana-plugin:**Kibana插件命令。
* **install:**指定要执行的操作(安装)。
* **x-pack:**要安装的插件名称。
### 4.2 Kibana对Elasticsearch数据的实时监控
#### 4.2.1 仪表盘和图表配置
Kibana提供了一个仪表盘和图表界面,允许用户实时监控Elasticsearch集群的性能和健康状况。这些可视化可以显示集群指标,如索引大小、查询延迟和节点状态。
**代码块:创建Elasticsearch集群健康仪表盘**
```
GET /_cluster/health
{
"cluster_name": "my-cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 3,
"number_of_data_nodes": 3,
"active_primary_shards": 10,
"active_shards": 10,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}
```
**逻辑分析:**
此代码获取Elasticsearch集群的健康状态。它显示了集群名称、状态、节点数量和分片信息。
**参数说明:**
* **GET /_cluster/health:**获取集群健康状态的REST API端点。
#### 4.2.2 警报和通知
Kibana还提供警报和通知功能,允许用户在发生特定事件(如索引大小超过阈值或查询延迟过高)时收到通知。这些警报可以通过电子邮件、Slack或其他通知渠道发送。
**代码块:创建警报以监控索引大小**
```
POST /api/alerts/alert
{
"name": "Index size alert",
"type": "index_size",
"enabled": true,
"schedule": {
"interval": "1h"
},
"conditions": [
{
"query": {
"bool": {
"must": [
{
"range": {
"index.size_in_bytes": {
"gte": "100gb"
}
}
}
]
}
},
"name": "Index size condition"
}
],
"actions": [
{
"email": {
"to": "admin@example.com",
"subject": "Index size alert: {{ctx.metadata.index}}",
"body": "The index {{ctx.metadata.index}} has exceeded the size threshold of 100GB."
},
"name": "Email action"
}
]
}
```
**逻辑分析:**
此代码创建了一个警报,当索引大小超过100GB时,它会向admin@example.com发送电子邮件通知。
**参数说明:**
* **POST /api/alerts/alert:**创建警报的REST API端点。
* **name:**警报名称。
* **type:**警报类型(在本例中为“index_size”)。
* **enabled:**是否启用警报。
* **schedule:**警报执行时间表。
* **conditions:**触发警报的条件。
* **actions:**当条件满足时执行的操作。
# 5.1 日志分析和故障排除
Elasticsearch 和 Kibana 在日志分析和故障排除方面发挥着至关重要的作用。通过将日志数据索引到 Elasticsearch 中,我们可以利用其强大的搜索和分析功能快速识别和解决问题。
### 5.1.1 索引日志数据
将日志数据索引到 Elasticsearch 的过程涉及以下步骤:
1. **定义索引模板:**创建索引模板以定义日志数据的映射和设置,例如字段类型、分词器和分片数量。
2. **配置日志收集器:**使用 Filebeat 或 Logstash 等工具将日志从源系统收集到 Elasticsearch。
3. **索引日志数据:**日志收集器将日志数据发送到 Elasticsearch,并根据索引模板进行索引。
```yaml
# Filebeat 配置示例
filebeat.inputs:
- type: log
paths:
- /var/log/syslog
fields:
type: syslog
```
### 5.1.2 查询和分析日志
一旦日志数据被索引,我们可以使用 Kibana 查询和分析它们。Kibana 提供了直观的界面,用于创建仪表盘、图表和过滤器,以便快速识别模式和趋势。
```
# Kibana 查询示例
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "error"
}
}
]
}
}
}
```
通过结合 Elasticsearch 的搜索能力和 Kibana 的可视化功能,我们可以轻松地:
- 查找特定错误或警告消息
- 分析日志模式以识别潜在问题
- 跟踪日志事件的时间线以进行故障排除
- 创建仪表盘以监控关键日志指标

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏简介
《Elasticsearch深入解析与实战》专栏全面深入地剖析了Elasticsearch的各个方面,从基本概念到高级应用。专栏包含一系列文章,涵盖了索引创建和管理、全文搜索、分词器、查询DSL语法、排序和聚合、文档更新和删除、高可用集群、性能调优、备份和恢复、与Kibana协同使用、数据管道处理、地理空间搜索、安全机制、与Logstash集成、索引优化、实时数据分析、故障诊断、监控和警报、数据备份和灾难恢复、近实时分析、索引模板和映射配置、多字段联合搜索、文档版本管理、升级和版本迁移、自定义聚合分析、机器学习应用、监控和日志记录管理、高级性能调优和集群扩展、与其他大数据平台集成等主题。本专栏旨在为读者提供全面深入的Elasticsearch知识和实践指导,帮助他们充分利用Elasticsearch的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【系统恢复101】:黑屏后的应急操作,基础指令的权威指南

# 摘要
系统恢复是确保计算环境连续性和数据安全性的关键环节。本文从系统恢复的基本概念出发,详细探讨了操作系统的启动原理,包括BIOS/UEFI阶段和引导加载阶段的解析以及启动故障的诊断与恢复选项。进一步,本文深入到应急模式下的系统修复技术,涵盖了命令行工具的使用、系统配置文件的编辑以及驱动和
【电子元件检验案例分析】:揭秘成功检验的关键因素与常见失误

# 摘要
电子元件检验是确保电子产品质量与性能的基础环节,涉及对元件分类、特性分析、检验技术与标准的应用。本文从理论和实践两个维度详细介绍了电子元件检验的基础知识,重点阐述了不同检验技术的应用、质量控制与风险管理策略,以及如何从检验数据中持续改进与创新。文章还展望了未来电子元件检验技术的发展趋势,强调了智能化、自动化和跨学科合作的重
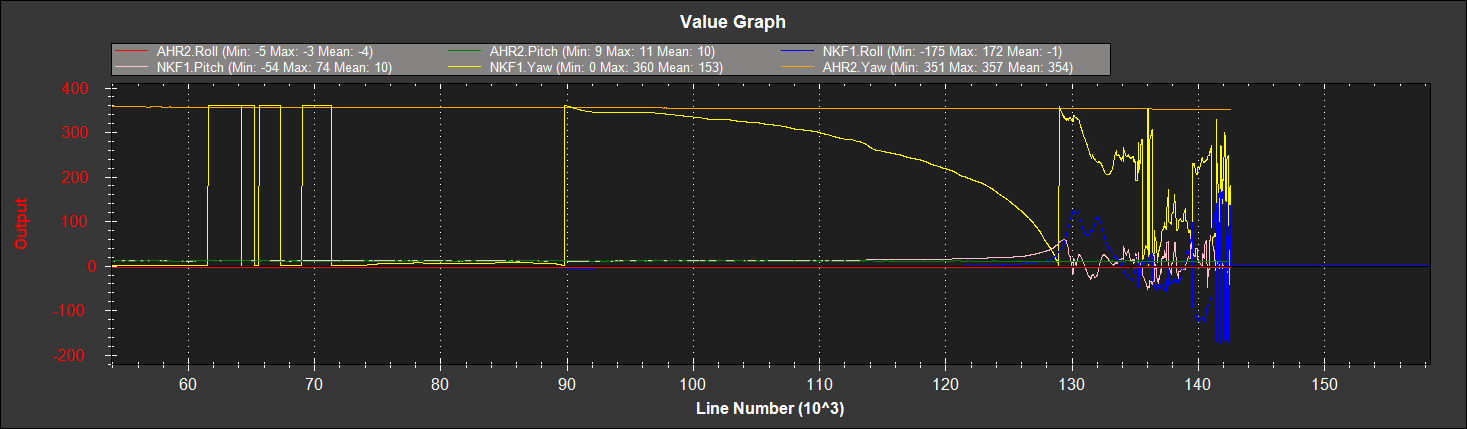
【PX4性能优化】:ECL EKF2滤波器设计与调试
# 摘要
本文综述了PX4性能优化的关键技术,特别是在滤波器性能优化方面。首先介绍了ECL EKF2滤波器的基础知识,包括其工作原理和在PX4中的角色。接着,深入探讨了ECL EKF2的配置参数及其优化方法,并通过性能评估指标分析了该滤波器的实际应用效果。文章还提供了详细的滤波器调优实践,包括环境准备、系统校准以及参数调整技
【802.3BS-2017物理层详解】:如何应对高速以太网的新要求

# 摘要
随着互联网技术的快速发展,高速以太网成为现代网络通信的重要基础。本文对IEEE 802.3BS-2017标准进行了全面的概述,探讨了高速以太网物理层的理论基础、技术要求、硬件实现以及测试与验证。通过对物理层关键技术的解析,包括信号编码技术、传输介质、通道模型等,本文进一步分析了新标准下高速以太网的速率和距离要求,信号完整性与链路稳定性,并讨论了功耗和环境适应性问题。文章还介绍了802.3
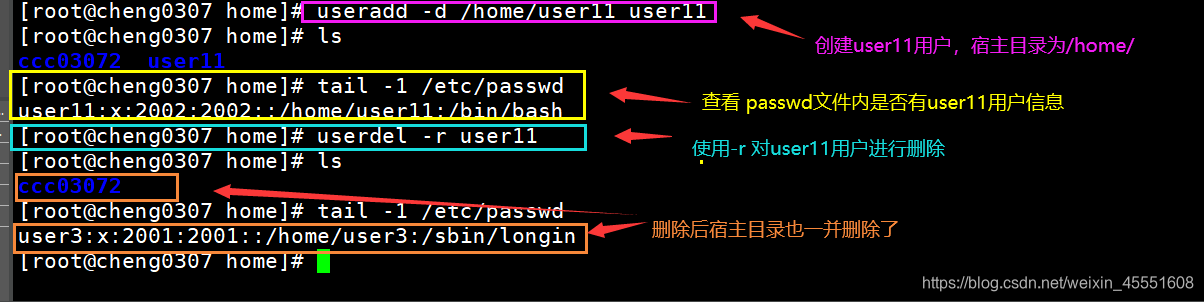
Linux用户管理与文件权限:笔试题全解析,确保数据安全
# 摘要
本论文详细介绍了Linux系统中用户管理和文件权限的管理与配置。从基础的用户管理概念和文件权限设置方法开始,深入探讨了文件权
Next.js数据策略:API与SSG融合的高效之道

# 摘要
Next.js是一个流行且功能强大的React框架,支持服务器端渲染(SSR)和静态站点生成(SSG)。本文详细介绍了Next.js的基础概念,包括SSG的工作原理及其优势,并探讨了如何高效构建静态页面,以及如何将API集成到Next.js项目中实现数据的动态交互和页面性能优化。此外,本文还展示了在复杂应用场景中处理数据的案例,并探讨了Next.js数据策略的
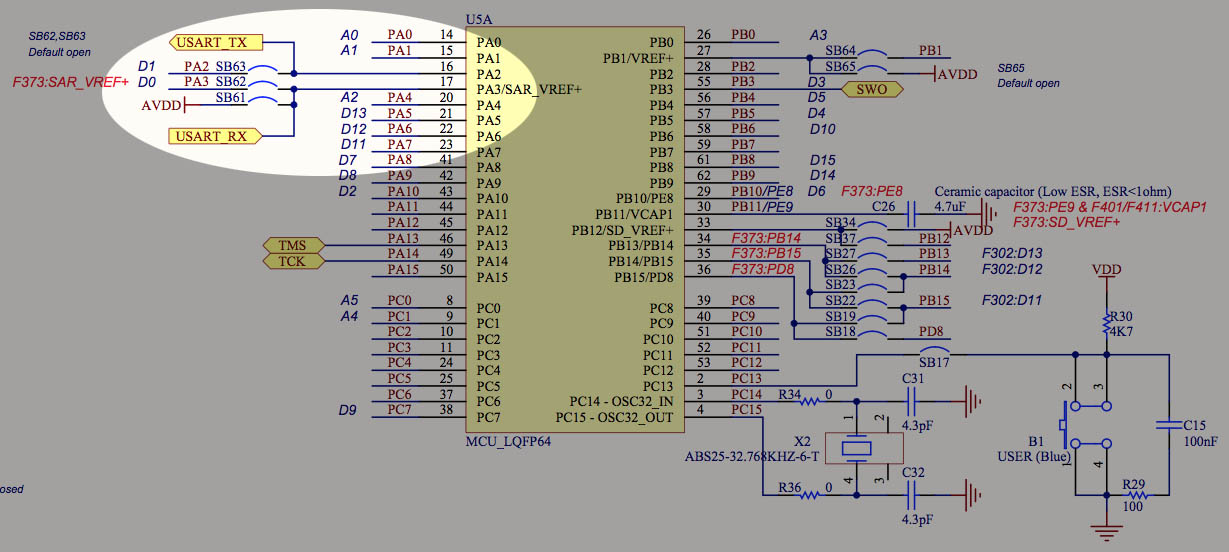
STM32F767IGT6无线通信宝典:Wi-Fi与蓝牙整合解决方案
# 摘要
本论文系统地探讨了STM32F767IGT6微控制器在无线通信领域中的应用,重点介绍了Wi-Fi和蓝牙模块的集成与配置。首先,从硬件和软件两个层面讲解了Wi-Fi和蓝牙模块的集成过程,涵盖了连接方式、供电电路设计以及网络协议的配置和固件管理。接着,深入讨论了蓝牙技术和Wi-Fi通信的理论基础,及其在实际编程中的应用。此外,本论文还提
【CD4046精确计算】:90度移相电路的设计方法(工程师必备)

# 摘要
本文全面介绍了90度移相电路的基础知识、CD4046芯片的工作原理及特性,并详细探讨了如何利用CD4046设计和实践90度移相电路。文章首先阐述了90度移相电路的基本概念和设计要点,然后深入解析了CD4046芯片的内部结构和相位锁环(PLL)工作机制,重点讲述了基于CD4046实现精确移相的理论和实践案例。此外,本文还提供了电路设计过程中的仿真分析、故障排除技巧,以及如何应对常见问题。文章最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )