【Pymongo进阶秘籍】:提升数据库操作效率的5大技巧
发布时间: 2024-10-01 12:28:51 阅读量: 3 订阅数: 9 

# 1. MongoDB与Pymongo基础概述
## MongoDB简介
MongoDB是一种面向文档的NoSQL数据库,具有高性能、高可用性和易扩展的特点。它支持丰富的查询语言,能处理各种形式的数据:结构化、半结构化或非结构化。使用MongoDB,开发者可以以文档为单位存储数据,这比传统的表格格式更加灵活。
## Pymongo入门
Pymongo是MongoDB的官方Python驱动,它允许Python程序直接操作MongoDB数据库。Pymongo提供了完整的方法集来执行常见数据库操作,包括插入、查询、更新、删除和聚合数据等。
## 数据模型与交互
在MongoDB中,数据模型使用JSON风格的文档,每个文档都是BSON格式,这是一种类JSON的二进制格式。Pymongo使得Python应用可以与MongoDB的集合和文档进行交互,像操作Python字典一样方便地处理数据。
随着大数据时代的到来,能够处理海量非结构化数据的NoSQL数据库越来越受到重视。MongoDB因其灵活性与高性能,在众多NoSQL数据库中脱颖而出,而Pymongo作为连接Python与MongoDB的桥梁,让Python开发者可以高效地进行数据的CRUD操作。在接下来的章节中,我们将深入了解Pymongo如何在不同场景下优化数据查询与管理,以及如何在实践中更好地应用这些知识。
# 2. Pymongo的数据查询优化
MongoDB作为一个高性能、开源且模式自由的文档导向数据库,被广泛使用于大数据量的存储和查询。而Pymongo是MongoDB官方提供的Python驱动,使得Python开发者能够通过Python脚本进行数据库的交互。查询优化作为数据库性能调整中的关键环节,对于保证系统的高效运行至关重要。本章将深入探讨Pymongo的数据查询优化策略。
## 2.1 理解查询性能关键点
### 2.1.1 查询计划和索引的优化
在进行MongoDB查询优化时,首先需要理解查询计划,它能够展示MongoDB是如何处理查询请求的。MongoDB提供了`explain()`方法,它允许开发者以不同的模式查看查询过程。这些模式包括:
- `queryPlanner`:提供一个基础的查询计划。
- `executionStats`:显示有关查询执行的统计信息,包括实际执行了哪些操作。
- `allPlansExecution`:在基础执行统计信息之上,显示了所有可能的查询计划。
索引优化对于提升查询性能至关重要。在MongoDB中,索引可以看作是数据的书签,它加快了查询和排序操作的速度。索引也遵循B-tree的数据结构,使得在大量数据中快速查找数据成为可能。
索引的优化可以从以下几个方面入手:
- 创建合理的索引:根据查询模式创建索引,并避免在低基数字段上创建索引。
- 使用复合索引:当需要针对多个字段进行查询时,可以创建复合索引。
- 定期维护索引:因为索引会随着数据的增删改变,所以定期对索引进行优化和重建是必要的。
### 2.1.2 查询速度的影响因素分析
查询速度可能受到多种因素的影响。理解这些因素有助于我们进行针对性的优化。
- 索引:不恰当的索引或者没有索引会导致全表扫描,这在大数据量的情况下会导致查询性能急剧下降。
- 查询语句:复杂的查询语句,如嵌套的查询,也会降低查询效率。
- 锁:数据库的锁机制在处理并发时会引入开销,如果设计不当可能会成为瓶颈。
- 硬件:服务器的CPU、内存、磁盘I/O速度都直接影响查询性能。
## 2.2 使用游标控制查询输出
### 2.2.1 限制结果数量和分页处理
使用Pymongo时,我们可以通过游标来限制查询结果的数量,这在实现分页功能时非常有用。例如,要获取查询结果的前10条记录,可以使用`limit()`方法:
```python
pipeline = [{"$match": {"name": "John Doe"}}]
results = db.collection.aggregate(pipeline)
cursor = results.limit(10)
```
在此基础上,实现分页功能,我们还需要使用`skip()`方法来跳过特定数量的文档:
```python
# 假设每页显示10条记录
for page_num in range(page, total_pages + 1):
offset = (page_num - 1) * 10
cursor = results.skip(offset).limit(10)
for doc in cursor:
# 处理每条文档数据...
```
### 2.2.2 控制数据加载和批处理
为了优化内存使用和提升性能,我们可以通过控制数据加载的批次来处理大量数据。Pymongo允许我们使用游标的`batch_size`参数来控制每个批次加载的文档数量:
```python
# 以每次50条文档为一批次进行处理
for doc in collection.find().batch_size(50):
# 处理文档...
```
这种方法可以帮助我们在处理大量数据时,避免一次性将所有数据加载到内存中。
## 2.3 索引的高级应用
### 2.3.1 复合索引的创建和优化
复合索引是一种可以包含多个字段的索引,当一个查询涉及到多个字段时,复合索引能大幅提升查询性能。创建复合索引时,通常要根据查询模式中字段的选择性和顺序来设计索引,以确保其效率。
在Pymongo中创建复合索引的代码如下:
```python
# 创建一个复合索引,首先按“age”字段升序,然后按“name”字段降序
db.collection.create_index([("age", 1), ("name", -1)])
```
### 2.3.2 索引维护和性能监控
索引维护涉及创建新索引、删除不必要的索引以及定期重新组织索引。Pymongo提供了多种工具和命令帮助开发者进行索引维护。性能监控则包括跟踪索引使用情况和调整索引策略。
MongoDB提供了`db.collection.totalIndexSize`命令来查看当前集合中所有索引的大小。这对于监控索引空间使用情况非常有用。
```python
# 查看集合索引的总大小
db.collection.totalIndexSize()
```
索引性能监控的一个重要方面是确保查询计划的有效性。经常检查查询计划可以帮助我们发现潜在的性能问题,并及时进行优化。
本章到此,我们了解了Pymongo数据查询优化的关键点,如何使用游标控制查询输出,以及索引的高级应用。接下来的章节将进一步探讨数据写入和更新技巧,帮助大家提升数据库的写入性能和数据一致性。
# 3. Pymongo的数据写入和更新技巧
## 3.1 写入操作的性能调优
### 3.1.1 批量插入和批量更新的方法
Pymongo提供了多种批量操作的方法,以优化写入操作的性能。使用批量写入可以显著减少网络往返次数,提高数据插入或更新的效率。
**批量插入:**
批量插入可以通过`bulk_write`方法实现,它允许用户一次性提交多个插入操作。这在数据迁移或初始数据导入时尤其有用。
```python
from pymongo import MongoClient
client = MongoClient('mongodb://localhost:27017/')
db = client['testdb']
collection = db['testcollection']
operations = [
{'insertOne': {'document': {'a': 1}}},
{'insertOne': {'document': {'a': 2}}},
{'insertOne': {'document': {'a': 3}}}
]
result = collection.bulk_write(operations)
print(result.bulk_api_result)
```
这段代码演示了如何使用`bulk_write`进行批量插入。`operations`是一个列表,其中每个元素是一个包含批量操作命令的字典。
**批量更新:**
批量更新操作同样可以使用`bulk_write`方法完成。这对于更新文档中的多个字段非常有效。
```python
operations = [
{'updateOne': {'filter': {'a': 1}, 'update': {'$set': {'a': 100}}}},
{'updateOne': {'filter': {'a': 2}, 'update': {'$inc': {'a': 10}}}},
]
result = collection.bulk_write(operations)
print(result.bulk_api_result)
```
在这里,每个操作指定了要更新的文档和更新操作本身。`updateOne`方法是`bulk_write`接受的多种操作类型之一。
### 3.1.2 写入操作的并发控制
在多用户环境下,写入操作的并发控制对于保证数据一致性和性能至关重要。Pymongo提供了一些工具来帮助控制并发写入。
**写入关注点(Write Concerns):**
MongoDB提供了不同的写入关注点,用以控制写入操作的确认级别。在Pymongo中,可以通过设置`write_concern`参数来指定。
```python
client = MongoClient('mongodb://localhost:27017/')
db = client['testdb']
collection = db['testcollection']
collection.insert_one({'a': 4}, write_concern={'w': 1, 'j': True})
```
在这里,`write_concern`被设置为确认写入到主节点并且日志被写入磁盘。`'w': 1`表示确认写入至少一个服务器,`'j': True`表示要求日志被写入磁盘。
**锁的使用:**
在写入操作中,锁的使用也是并发控制的一部分。MongoDB使用了读写锁来管理并发访问。虽然通常不建议在应用程序代码中直接操作锁,但是理解其工作原理对于优化写入性能也是有帮助的。
```python
from pymongo.lock import AdvisoryLock
from threading import Thread
lock = AdvisoryLock(client, db.name, "my_lock_key")
def thread_function():
with lock:
collection.insert_one({'a': 1})
threads = [Thread(target=thread_function) for _ in range(5)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
```
上述代码展示了如何使用Pymongo的`AdvisoryLock`类来在写入操作中实现简单的并发控制。这种方法在多线程应用程序中尤其有用。
通过这些批量操作和并发控制技术,开发者可以显著提高数据写入和更新的性能。在下一小节中,我们将进一步深入探讨Pymongo中的原子操作,了解它们是如何保持数据一致性的。
(未完待续,待下文继续展开剩余小节内容)
# 4. Pymongo的数据聚合与分析
## 4.1 数据聚合框架的效率提升
聚合管道是处理复杂数据查询和转换的强大工具,在Pymongo中扮演着至关重要的角色。本节内容将详细探讨如何优化聚合管道操作,提升其效率。
### 4.1.1 聚合管道优化技巧
聚合管道由多个阶段组成,每个阶段都会对数据进行处理,并将结果传递给下一个阶段。对于大数据集来说,高效的聚合管道至关重要。
```python
from pymongo import MongoClient
# 连接数据库
client = MongoClient('mongodb://localhost:27017/')
db = client['your_database']
collection = db['your_collection']
# 聚合管道示例
pipeline = [
{"$match": {"status": "active"}},
{"$group": {"_id": "$category", "total": {"$sum": "$amount"}}},
{"$sort": {"total": -1}}
]
# 执行聚合操作
results = list(collection.aggregate(pipeline))
```
在上面的代码中,`$match`阶段首先筛选出状态为“active”的文档,减少了传递到后续阶段的数据量;`$group`阶段将数据按类别分组并求和;`$sort`阶段对结果进行排序。
优化聚合管道的关键在于减少数据量和合理排序。在`$match`阶段尽可能地过滤掉不需要的文档,因为管道的早期阶段过滤比晚期阶段效率更高。另外,对于需要排序的字段,确保其上有索引,可以显著加快排序操作的速度。
### 4.1.2 高效的数据匹配和转换
在聚合管道中实现高效的数据匹配和转换,需要对数据进行合理的预处理和索引优化。合理的索引可以减少数据扫描量,提高查询速度。
```python
# 在匹配字段上创建索引
collection.create_index([("status", 1)])
```
对于转换操作,如`$project`或`$addFields`,应该尽可能避免在这些阶段进行复杂计算。在某些情况下,使用`$Facet`可以并行处理多个数据流,提高效率。
```python
# 使用$Facet进行并行处理
pipeline = [
{"$match": {"status": "active"}},
{"$facet": {
"top_categories": [
{"$group": {"_id": "$category", "total": {"$sum": "$amount"}}},
{"$sort": {"total": -1}}
],
"average_amount": [
{"$group": {"_id": null, "avg": {"$avg": "$amount"}}}
]
}}
]
# 执行聚合操作
results = list(collection.aggregate(pipeline))
```
在上面的代码中,我们利用`$Facet`并行处理了两个数据流:一个按类别分组并排序,另一个计算平均金额。这比顺序执行这两个操作要高效得多。
## 4.2 大数据集的聚合操作
处理大数据集时,聚合操作可能会变得非常缓慢和资源密集。本小节将介绍如何使用map-reduce和GridFS来处理大规模数据集。
### 4.2.1 使用map-reduce处理大数据
Map-reduce是一种将大型数据集分解为更小部分,并通过并行处理来实现高效数据处理的技术。MongoDB提供了与之对应的聚合操作。
```python
def map_function():
for doc in db.collection.find({"status": "active"}):
emit(doc["category"], doc["amount"])
def reduce_function(key, values):
return sum(values)
# 执行map-reduce操作
map_reduce_result = db.collection.map_reduce(
map_function, reduce_function, "map_reduce_example"
)
```
在上述代码中,`map_function`函数对每个符合条件的文档执行操作,并将类别和金额作为键值对发出。`reduce_function`函数则将所有发出的值合并,计算出每个类别的总金额。最终结果存储在指定的集合中。
使用map-reduce时应注意,它适合批处理,但不适用于实时查询。此外,如果数据集非常大,map-reduce操作本身可能需要优化和调整以适应集群环境。
### 4.2.2 使用GridFS处理文件存储
GridFS是一种用于存储大文件的文件存储规范,适用于在MongoDB中存储和检索文件。当需要对存储在GridFS中的文件进行聚合分析时,可以直接在文件数据上执行聚合操作。
```python
from pymongo.gridfs import GridFSBucket
# 创建GridFS Bucket
bucket = GridFSBucket(db, chunk_size=255*1024)
# 从GridFS读取文件并进行处理
with bucket.open_download_stream(gridfs_id) as ***
***
* 在此处处理数据块
```
在处理大量文件数据时,可以使用聚合管道对文件元数据进行聚合。例如,可以通过文件上传时间来聚合文件,并计算每个时间段的文件数量。
```python
pipeline = [
{"$match": {"uploadDate": {"$gte": start_date, "$lt": end_date}}},
{"$group": {"_id": {"year": {"$year": "$uploadDate"}, "month": {"$month": "$uploadDate"}}, "count": {"$sum": 1}}}
]
# 执行聚合操作
results = list(db.fs.files.aggregate(pipeline))
```
在上面的代码中,我们通过上传时间对文件进行了分组,并计算了每个月的文件数量。这样可以快速地对文件存储进行分析,而不需要加载整个文件内容。
## 4.3 聚合操作的性能监控与分析
聚合操作对于性能的影响很大,因此对其进行监控和分析是至关重要的。接下来,我们将探讨如何使用性能监控工具来诊断和优化聚合慢查询。
### 4.3.1 性能监控工具介绍
MongoDB提供了多种工具来监控数据库性能,其中`explain()`方法是最直接的工具之一。使用`explain()`方法可以详细了解查询或聚合操作的执行计划。
```python
# 使用explain()方法分析聚合操作
pipeline = [
{"$match": {"status": "active"}},
{"$group": {"_id": "$category", "total": {"$sum": "$amount"}}}
]
result = collection.aggregate(pipeline).explain("executionStats")
print(result["executionStats"]["executionTimeMillis"])
```
在上述代码中,`explain("executionStats")`提供了关于查询执行时间的详细统计信息,包括扫描的文档数量、返回的文档数量和执行时间等。
### 4.3.2 聚合慢查询的诊断与优化
识别慢查询后,我们需要对其进行分析和优化。慢查询通常由于以下原因造成:
- 遗漏索引导致的全表扫描
- 复杂的聚合逻辑或多个阶段
- 数据集过大导致的性能瓶颈
在对慢查询进行优化时,首先考虑索引优化。索引可以显著减少数据扫描量。其次,检查聚合管道是否有必要使用多个阶段,尝试合并一些阶段以减少数据传递次数。
```python
# 针对慢查询添加索引
collection.create_index([("status", 1), ("category", 1)])
# 优化聚合管道,避免不必要的中间阶段
```
最后,针对数据集过大带来的性能问题,可以考虑分片策略,将数据分散存储在多个服务器上。
总结来看,优化聚合操作不仅要求深入了解MongoDB的聚合框架,还需要合理的数据结构设计、适当的索引策略,以及对性能监控工具的熟练应用。通过这些方法,可以大幅度提升聚合操作的效率,有效处理大数据集,并确保数据库系统的稳定性。
# 5. Pymongo的高级应用技巧
MongoDB 作为一个面向文档的数据库,它提供了灵活的数据模型和强大的查询语言。Pymongo 作为 MongoDB 的官方 Python 驱动程序,允许 Python 程序直接与 MongoDB 数据库进行交互。本章节重点介绍 Pymongo 的高级应用技巧,旨在帮助开发者利用 Pymongo 实现更高效、可靠和安全的数据操作。
## 5.1 自定义对象映射
在开发应用时,我们常常希望将数据库中的文档直接映射到 Python 对象中,以便于操作和维护。对象关系映射(Object-Relational Mapping,简称 ORM)是一个可以实现这一目标的技术。
### 5.1.1 ORM的原理与实现
ORM 背后的原理是将数据库中的表映射为对象,将表中的列映射为对象的属性,并将数据库的操作转化为对这些对象的操作。这种方式可以让我们像操作对象一样操作数据库记录,代码更加直观且易于维护。
在 Pymongo 中,虽然没有直接提供类似 ORM 的框架,但我们可以通过定义类和使用 `pymongo.Collection` 对象来模拟这种行为。以下是一个简单的例子:
```python
from pymongo import MongoClient
from bson import ObjectId
class User:
def __init__(self, username, email):
self.username = username
self.email = email
def to_mongo(self):
return {
"username": self.username,
"email": self.email,
}
@classmethod
def from_mongo(cls, data):
return cls(data["username"], data["email"])
# 连接到 MongoDB
client = MongoClient('mongodb://localhost:27017/')
db = client['testdb']
users_collection = db['users']
# 创建一个用户对象
user = User("JohnDoe", "***")
# 插入到数据库
users_collection.insert_one(user.to_mongo())
# 从数据库检索并转换回对象
document = users_collection.find_one({"username": "JohnDoe"})
user_from_db = User.from_mongo(document)
```
在上面的例子中,我们定义了一个 `User` 类,该类可以将对象转换为 JSON 格式以存储到 MongoDB 中,并且可以将存储的 JSON 数据转换回 `User` 对象。
### 5.1.2 自定义类与文档的映射
在大型项目中,为了保持代码的清晰性和可维护性,通常需要自定义类与文档的映射。在 Python 中,我们可以通过类继承和属性装饰器来实现更为复杂的映射关系。
例如,以下是一个展示类继承和属性处理的例子:
```python
from pymongo import MongoClient
class Person(User):
def __init__(self, first_name, last_name, *args, **kwargs):
super().__init__(*args, **kwargs)
self.first_name = first_name
self.last_name = last_name
def to_mongo(self):
doc = super().to_mongo()
doc.update({
"first_name": self.first_name,
"last_name": self.last_name
})
return doc
# 创建 Person 对象并保存到数据库
person = Person("John", "Doe", username="johndoe", email="***")
users_collection.insert_one(person.to_mongo())
```
在这个例子中,`Person` 类继承自 `User` 类,并添加了额外的属性。它通过重写 `to_mongo` 方法来处理额外属性的映射。
## 5.2 高可用性和分片集群管理
MongoDB 支持多种部署架构,如单节点部署、副本集(Replica Sets)和分片集群(Sharding)。其中,分片集群是扩展性最强的部署方案,适用于大规模的数据存储和读写操作。
### 5.2.1 分片集群的原理和配置
分片集群允许我们将数据分散存储在多个服务器上,以此来分摊压力和增加数据吞吐量。一个分片集群包括以下组件:
- **Shards**:数据分片的存储单元,每个分片可以是单个服务器或复制集。
- **Mongos**:查询路由器,客户端通过它可以连接到分片集群。
- **Config Servers**:存储集群的元数据,记录分片信息。
配置分片集群通常涉及以下几个步骤:
1. 准备配置服务器和 Mongos 路由器。
2. 将每个分片加入集群。
3. 配置分片键(Shard Key),这是决定数据如何分布在不同分片上的字段。
以下是一个配置分片集群的简单示例:
```bash
# 初始化 config servers
mongo --port 27019 --eval 'rs.initiate()' --quiet
mongo --port 27019 --eval 'sh.addShard("localhost:27017")' --quiet
```
### 5.2.2 管理工具的使用与监控
MongoDB 提供了多种工具来监控和管理分片集群的健康状况和性能。其中,`mongos` 提供了一个接口用于查看集群状态:
```bash
# 查看集群状态
mongo --port 27017 --eval 'sh.status()'
```
另外,MongoDB 自带的 Web 界面 `mongostat` 和 `mongotop` 也可以用来监控集群状态。这些工具可以帮助管理员诊断问题和优化性能。
## 5.3 备份和恢复策略
数据的备份和恢复是数据库管理中非常重要的一环,尤其是在生产环境中。Pymongo 通过其 API 提供了备份和恢复数据库的能力。
### 5.3.1 备份的类型和方法
MongoDB 支持多种备份方法,包括:
- **冷备份(Cold Backup)**:停止数据库服务后进行的备份,适用于数据一致性要求非常高,但对服务可用性要求不高的场景。
- **热备份(Hot Backup)**:在数据库运行时进行的备份,适用于生产环境中的数据备份,需要保证数据的一致性和服务的可用性。
Pymongo 使用 `mongodump` 工具来执行热备份,示例如下:
```bash
mongodump --host ***.*.*.* --port 27017 --out /path/to/backup
```
### 5.3.2 恢复流程及故障排除
恢复数据通常涉及使用 `mongorestore` 工具将备份的数据文件恢复到数据库中。在执行恢复操作之前,应该确保数据库处于停机状态,除非进行热备份的热恢复。
```bash
mongorestore --host ***.*.*.* --port 27017 /path/to/backup
```
在恢复数据的过程中,可能会遇到各种错误和问题,比如备份文件损坏或者数据类型不匹配等。这时,可以通过查看日志文件和使用 `mongorestore` 的 `--verbose` 选项来获取更多的诊断信息,进而进行故障排除。
总结而言,Pymongo 提供了灵活的接口以实现与 MongoDB 数据库的高效交互,无论是通过自定义对象映射实现类似 ORM 的功能,还是通过分片集群实现高可用性和可扩展性,抑或是进行备份和恢复来保证数据的安全性。掌握这些高级技巧,可以更好地利用 Pymongo 提升应用性能,实现业务需求。
# 6. ```
# 第六章:Pymongo实践案例与最佳实践
## 6.1 实际项目中的性能优化案例
### 6.1.1 高流量网站的数据库操作优化
在处理高流量网站时,数据库操作的性能优化尤为关键。这涉及到对Pymongo的合理利用,以及对MongoDB配置的精细调整。
首先,要确保为频繁查询的字段建立了索引。例如,如果一个用户列表页面对用户名称进行搜索,那么可以创建一个以用户名称为键的索引:
```python
db.users.create_index([("username", 1)])
```
对于读取操作,可以通过连接池的方式减少连接的建立和关闭的开销:
```python
from pymongo import Connection
# 假设有一个连接池大小设置为5
connection_pool = Connection(maxPoolSize=5)
# 使用连接池获取连接
db = connection_pool.test
```
对于写操作,可以启用 WiredTiger 存储引擎的事务功能,以保证数据的一致性:
```python
from pymongo import MongoClient, WriteConcern
client = MongoClient('mongodb://user:pass@host:port/database',
write_concern=WriteConcern(w='majority', wtimeout=5000))
```
除了这些Pymongo级别的优化之外,MongoDB服务器端的配置也是提升性能的关键。如启用压缩来减少数据存储空间,启用缓存来提高读取效率等。
### 6.1.2 实时数据处理和分析
在实时数据处理和分析场景中,Pymongo的流式处理能力尤为关键。可以使用游标进行数据的实时查询和聚合,例如:
```python
pipeline = [
{'$match': {'status': 'new'}},
{'$group': {'_id': '$user_id', 'total': {'$sum': '$amount'}}}
]
cursor = db.transactions.aggregate(pipeline)
for record in cursor:
print(record)
```
对于极大规模的数据流,可以利用MongoDB的Change Streams功能来监听数据变化,实现实时数据处理。在Pymongo中,可以这样使用Change Streams:
```python
with client.test.get_database("mydatabase").get_collection("mycollection").watch() as stream:
for insert_change in stream:
print("Detected an insert event:", insert_change)
```
## 6.2 Pymongo最佳实践分享
### 6.2.1 代码复用和模块化
代码复用和模块化是保证代码可维护性的关键。使用Python的`import`和`from`语句可以方便地实现代码复用,而在大型项目中,合理地组织代码结构以模块化方式提供功能接口,是必须遵循的最佳实践。
一个典型的Python模块结构示例如下:
```
project/
__init__.py
connection.py
models.py
utils.py
```
其中`connection.py`负责建立数据库连接,`models.py`定义数据模型,`utils.py`包含通用的辅助函数。
### 6.2.2 代码审查和版本控制在项目中的应用
代码审查是提高代码质量的重要手段,而版本控制系统(如Git)则帮助团队高效协作。在Pymongo项目中,可以使用Git来管理代码版本,并利用GitHub、GitLab等平台进行代码审查。
代码审查可以是一个Pull Request,审查者应该检查代码的风格、结构、逻辑以及是否遵循了项目的开发规范。使用工具如`flake8`可以帮助自动化代码风格检查。
## 6.3 安全性与权限管理
### 6.3.1 用户认证和授权机制
MongoDB的用户认证和授权机制对于保护数据库至关重要。在Pymongo中,可以使用以下代码来创建用户,并赋予相应的角色:
```python
db.createUser({
"user": "app_user",
"pwd": passwordPrompt(), # or you can use a clear-text password here
"roles": [
{"role": "readWrite", "db": "mydatabase"}
]
})
```
授权是基于角色的,不同的角色有不同的权限集合。这要求开发者对权限的分配进行细致的规划,确保应用的安全性。
### 6.3.2 数据加密和安全审计
数据加密能够保护存储在数据库中的敏感信息。对于Pymongo来说,可以通过MongoDB服务器端的配置来启用加密存储。同时,在代码层面,可以使用加密库(如`cryptography`)来加密敏感数据。
安全审计则需要定期进行,确保所有的安全措施都是最新的,并且没有新的安全漏洞。审计可以包括数据库配置检查、代码库的漏洞扫描以及实际的安全测试等。
通过这些实践案例与最佳实践,Pymongo在实际项目中的性能优化和安全性管理得到了全面的展现,对IT专业人员提供了实践上的指导与帮助。
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Redis Python客户端进阶:自定义命令与扩展redis-py功能

# 1. Redis与Python的结合
在现代的软件开发中,Redis与Python的结合应用是构建高效、稳定的应用架构的一个重要方向。Redis,作为一个开源的内存数据结构存储系统,常被用作数据库、缓存和消息代理。Python,作为一种广泛应用于服务器端开发的编程语言,具有简洁易读的语法和丰富的库支持。
## 1.1 Redis与Python的结合
【Pytest与Selenium实战教程】:自动化Web UI测试框架搭建指南
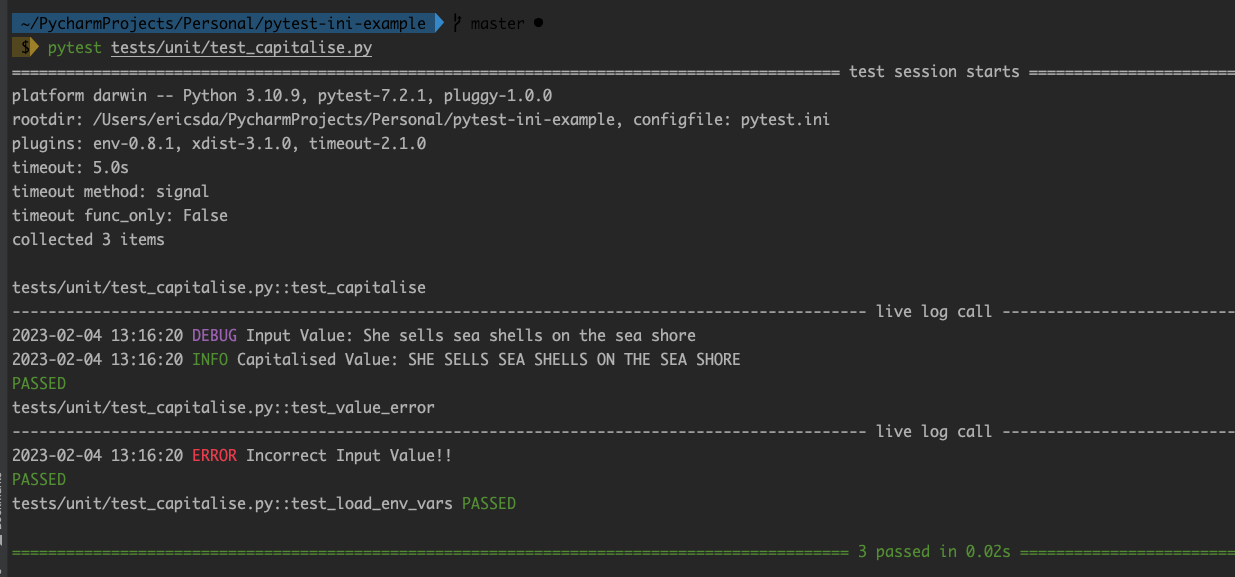
# 1. Pytest与Selenium基础介绍
## 1.1 Pytest介绍
Pytest是一个Python编写的开源测试框架,其特点在于易于上手、可扩展性强,它支持参数化测试用例、插件系统,以及与Selenium的无缝集成,非常适合进行Web自动化测试。它能够处理从简单的单元测试到复杂的集成测试用例,因其简洁的语法和丰富的功能而深受测试工程师的喜爱。
## 1.2 Selenium介绍
Selenium是一个用于Web应用程序测试的
Python开发者看过来:提升Web应用性能的Cookie存储策略

# 1. Web应用性能优化概述
## 1.1 性能优化的重要性
在数字化浪潮中,Web应用已成为企业与用户交互的重要渠道。性能优化不仅提升了用户体验,还直接关联到企业的市场竞争力和经济效益。一个响应速度快、运行流畅的Web应用,可以显著减少用户流失,提高用户满意度,从而增加转化率和收入。
## 1.2 性能优化的多维度
性能优化是一个多维度的过
【Django ORM数据校验守则】:保证数据准确性与合法性的黄金法则

# 1. Django ORM数据校验概论
## 引言
数据校验是构建健壮Web应用的重要环节。Django,作为全栈Web框架,提供了强大的ORM系统,其数据校验机制是保障数据安全性和完整性的基石。本章将对Django ORM数据校验进行概述,为后续深入探讨打下
【多租户架构】:django.core.paginator的应用案例
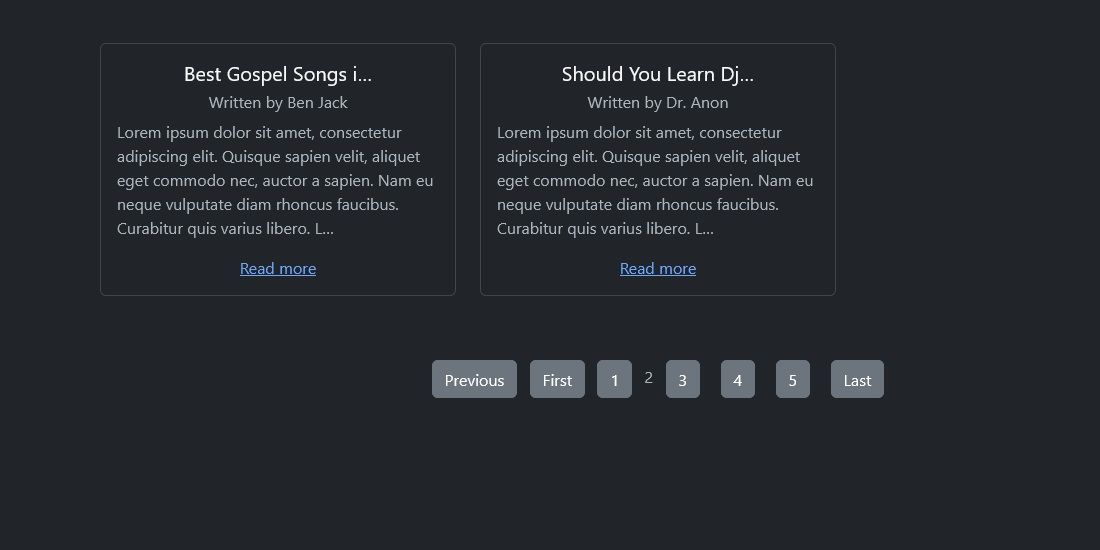
# 1. 多租户架构的基础知识
多租户架构是云计算服务的基石,它允许多个客户(租户)共享相同的应用实例,同时保持数据隔离。在深入了解django.core.paginator等具体技术实现之前,首先需要掌握多租户架构的核心理念和基础概念。
## 1.1 多租户架构的定义和优势
多租户架
GTK+3中的自定义控件:提升应用交互体验的3大策略

# 1. GTK+3自定义控件概述
## 1.1 GTK+3控件的基础
GTK+3作为一套丰富的GUI开发库,提供了大量预定义的控件供开发者使用。这些控件
Dev-C++ 5.11数据库集成术:在C++中轻松使用SQLite

# 1. SQLite数据库简介与Dev-C++ 5.11环境准备
在这一章节中,我们将首先介绍SQLite这一强大的轻量级数据库管理系统,它以文件形式存储数据,无需单独的服务器进程,非常适用于独立应用程序。接着,我们将讨论在Dev-C++ 5.11这一集成开发环境中准备和使用SQLite数据库所需的基本步骤。
## 1.1 SQLite简介
SQLite是实现了完整SQL数据库引擎的小型数据库,它作为一个库被
C++安全编程手册:防御缓冲区溢出与注入攻击的10大策略

# 1. C++安全编程概述
## 1.1 安全编程的必要性
在C++开发中,安全编程是维护系统稳定性和保障用户信息安全的重要环节。随着技术的发展,攻击者的手段越发高明,因此开发者必须对潜在的安全风险保持高度警惕,并在编写代码时采取相应的防御措施。安全编程涉及识别和解决程序中的安全隐患,防止恶意用户利用这些漏洞进行攻击。
## 1.2 C++中的安全挑战
由于C+
Python异常处理的边界案例:系统信号和中断的处理策略
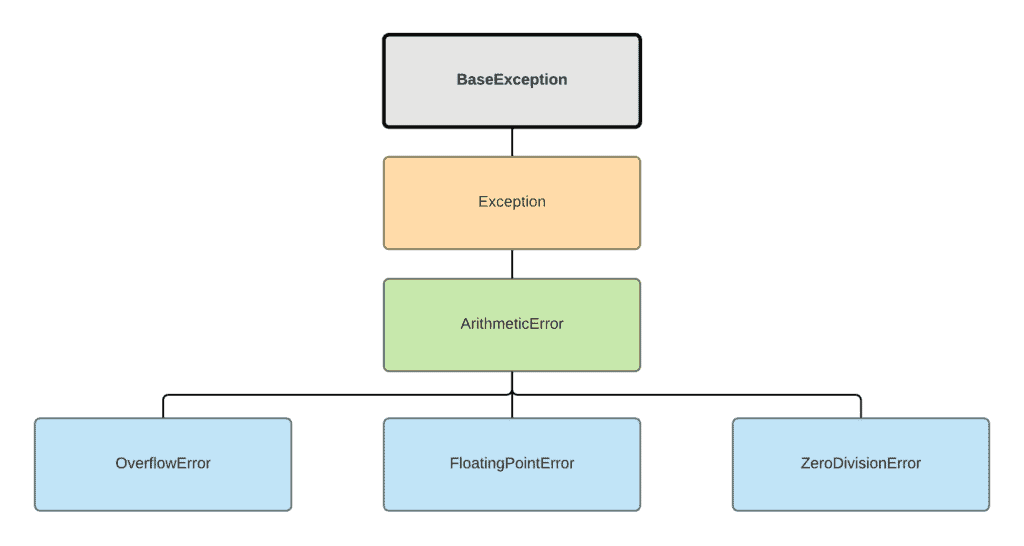
# 1. 异常处理基础知识概述
异常处理是软件开发中保障程序稳定运行的重要手段。本章将介绍异常处理的基础知识,并为读者建立一个扎实的理论基础。我们将从异常的概念入手,探讨其与错误的区别,以及在程序运行过程中异常是如何被引发、捕获和处理的。此外,本章还会简介异常的分类和处理方法,为进一步深入学习异常处理的高级技巧打下基础。
C语言内联函数深度探索:性能提升与注意事项
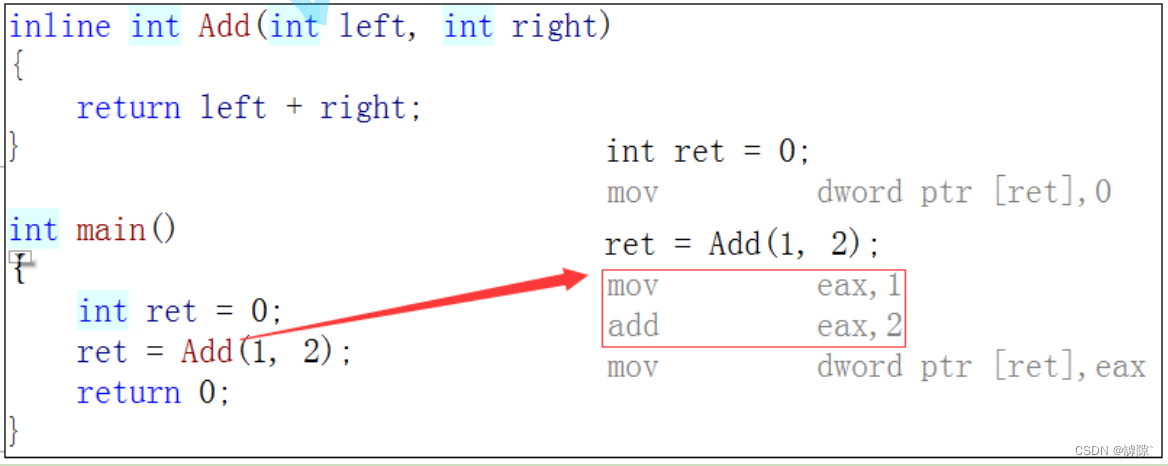
# 1. 内联函数的基础概念与作用
## 1.1 内联函数定义
内联函数是C++语言中一种特殊的函数,它的基本思想是在编译时期将函数的代码直接嵌入到调用它的地方。与常规的函数调用不同,内联函数可以减少函数调用的开销,从而提高程序运行的效率。
## 1.2 内联函数的作用
内联函数在编译后的目标代码中不存在一个单独的函数体,这意味着它可以减少程序运行时的上下文切换,提高执行效率。此外,内联函数的使用可以使得代
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )