【Pymongo实践技巧】:优化数据模型与数据库管理实战
发布时间: 2024-10-01 12:41:07 阅读量: 19 订阅数: 21 
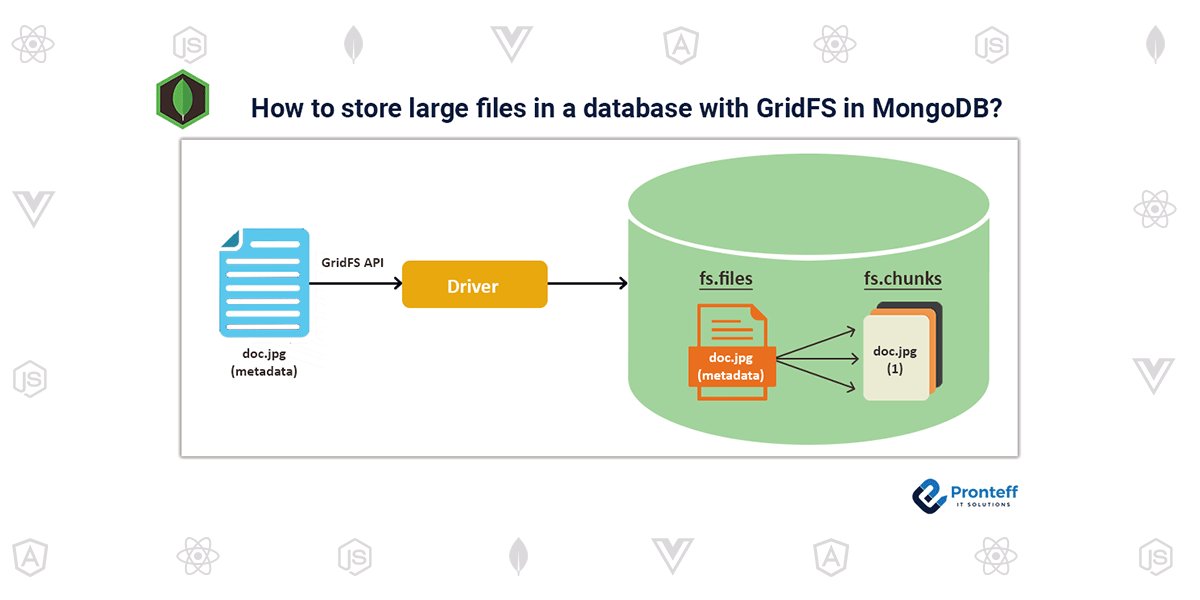
# 1. MongoDB与Pymongo基础介绍
## 1.1 MongoDB简介
MongoDB是一款面向文档的NoSQL数据库,它以其灵活性、水平扩展能力和高性能而闻名。文档存储在MongoDB中是一个JSON风格的格式,称为BSON(类似于JSON的一个二进制编码格式),支持嵌套结构和多种数据类型。
## 1.2 Pymongo简介
Pymongo是MongoDB官方提供的Python接口,它允许开发者通过Python程序与MongoDB数据库进行交互。它支持所有MongoDB的核心特性,包括数据的增删改查、索引创建和管理等。
## 1.3 MongoDB与Pymongo的关系
Pymongo作为MongoDB在Python语言的客户端,使用它可以在Python脚本中编写数据库操作逻辑,实现数据的快速访问与维护。这一章将介绍如何使用Pymongo连接MongoDB数据库,以及执行基本的CRUD(创建、读取、更新和删除)操作。
```python
# 示例代码 - 使用Pymongo连接到MongoDB并执行基本操作
from pymongo import MongoClient
# 创建连接
client = MongoClient('mongodb://localhost:27017/')
# 连接到数据库
db = client['mydatabase']
# 连接到集合
collection = db['mycollection']
# 插入一个文档
collection.insert_one({"name": "John", "age": 27})
# 查询文档
for doc in collection.find({"age": {"$gt": 25}}):
print(doc)
```
通过本章内容,读者将理解MongoDB的基本概念,并掌握使用Pymongo进行基础数据库操作的方法。
# 2. Pymongo数据模型优化
### 2.1 数据模型设计原则
#### 2.1.1 理解MongoDB的文档结构
MongoDB是一种非关系型文档数据库,它以BSON格式(类似于JSON)存储数据。这意味着它的数据模型与传统的关系型数据库模型有本质的不同。在MongoDB中,数据存储在“文档”中,每个文档都是一个键值对的集合。文档可以嵌套,这就允许一个文档内包含其它文档或数组。这种灵活的数据模型对数据结构的动态变化提供了很大的便利。
在设计文档结构时,关键是要理解数据之间的关系。比如,一对多的关系可以通过数组来实现,而一对一的关系可以通过嵌入式文档来实现。通过这样的结构,可以减少对JOIN操作的需求,从而提高查询效率。
#### 2.1.2 设计高效的数据模型
高效的数据模型设计对于提升MongoDB性能至关重要。在设计数据模型时,应该遵循以下原则:
1. **数据冗余最小化**:避免不必要的数据重复,但同时要注意对于经常一起查询的数据,可以适当冗余以减少查询次数。
2. **预聚合数据**:对于常常需要进行复杂查询或统计的数据,可以预先聚合存储,以减少实时计算的压力。
3. **使用内嵌文档**:在需要保证数据一致性时,使用内嵌文档可以避免多表连接操作,提升查询性能。
4. **适当使用引用**:对于那些经常需要独立更新或者不常一起查询的数据,使用文档引用可以提高数据的灵活性和维护性。
5. **模型的可扩展性**:在设计数据模型时,要考虑到未来应用可能的扩展需求,避免过于紧密耦合的设计。
### 2.2 Pymongo中的数据类型和索引
#### 2.2.1 各种数据类型的存储与使用
Pymongo通过其API支持MongoDB的多种数据类型。比如:
- **基本数据类型**:包括字符串、数字、布尔值、数组、对象和null。
- **日期类型**:MongoDB支持日期类型,通常用于记录操作时间等。
- **文档类型**:文档即为键值对集合,支持嵌套文档。
- **二进制数据**:用于存储二进制数据,如图片、视频等。
在Pymongo中使用这些数据类型,可以利用Python的原生类型,如字符串和字典等。例如,创建一个文档并插入到集合中,可以使用以下代码:
```python
import pymongo
client = pymongo.MongoClient('mongodb://localhost:27017/')
db = client.testdb
collection = db.testcollection
# 创建文档
document = {
"name": "Alice",
"age": 25,
"signup_date": datetime.datetime.now(),
"interests": ["reading", "traveling"],
"profile_picture": b'\x89PNG\r\n\x1a\n\x00\x00' # 示例二进制数据
}
# 插入文档
collection.insert_one(document)
```
在上面的示例中,我们创建了一个包含不同类型数据的文档,并将其插入到数据库中。
#### 2.2.2 创建和管理索引提升性能
索引是提高数据库查询性能的重要手段。在MongoDB中,可以创建多种类型的索引,如单字段索引、复合索引、文本索引和地理空间索引等。
Pymongo提供了`create_index`方法用于创建索引。对于性能优化而言,选择合适的字段和创建复合索引是关键。例如,对常用于查询和排序的字段创建索引可以显著提升查询速度。
```python
# 创建单字段索引
collection.create_index([("name", pymongo.ASCENDING)])
# 创建复合索引
collection.create_index([("age", pymongo.ASCENDING), ("signup_date", pymongo.DESCENDING)])
```
上述代码创建了一个基于`name`字段的单字段索引和一个基于`age`和`signup_date`字段的复合索引。
### 2.3 数据模型实践技巧
#### 2.3.1 嵌入式文档与引用文档的选择
在数据模型设计中,经常需要在嵌入式文档和引用文档之间做出选择。嵌入式文档适合于数据项之间关联性较强的情况,而引用文档适合于数据项之间关联性较弱的情况。
以用户和订单的关系为例,如果一个用户通常会有多个订单,订单数据与用户数据紧密关联,可以将订单嵌入到用户文档中。如果用户与订单之间的关系不那么密切,或者订单数据经常单独查询,那么应使用引用的方式。
```python
# 嵌入式文档示例
user_document = {
"name": "Bob",
"address": "123 Main Street",
"orders": [
{"order_id": "o1", "item": "book"},
{"order_id": "o2", "item": "pen"}
]
}
# 插入用户文档
collection.insert_one(user_document)
# 引用文档示例
user_document = {
"name": "Alice",
"address": "456 Elm Street"
}
collection.insert_one(user_document)
order_document = {
"user_id": "123",
"order_id": "o1",
"item": "laptop"
}
order_collection = db.orders
order_collection.insert_one(order_document)
```
在上述代码中,用户文档直接嵌入了订单数据,而另一个用户文档则仅存储了用户的标识,订单数据则在另一个集合中引用该标识。
#### 2.3.2 高级查询优化方法
在MongoDB中,可以利用聚合框架来执行高级查询。聚合框架允许用户执行一系列操作以转换数据集,并执行复杂的数据分析。Pymongo提供了`aggregate`方法,它支持各种聚合操作,如`$match`、`$group`、`$sort`等。
例如,如果我们需要按用户年龄分组统计订单数量,可以使用以下聚合管道:
```
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python库文件学习之PyMongo》专栏深入探讨了PyMongo库,为MongoDB和Python开发人员提供了全面的指南。从快速入门指南到高级教程,该专栏涵盖了从数据库连接到复杂查询、聚合管道、数据建模、安全性和性能调优等各个方面。它还提供了实用技巧、错误管理策略、并发操作最佳实践、数据迁移和备份技巧,以及异步编程和监控方面的深入见解。无论您是PyMongo新手还是经验丰富的开发人员,该专栏都将为您提供宝贵的知识和见解,帮助您构建高效、健壮的MongoDB应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
R语言YieldCurve包优化教程:债券投资组合策略与风险管理
# 1. R语言YieldCurve包概览
## 1.1 R语言与YieldCurve包简介
R语言作为数据分析和统计计算的首选工具,以其强大的社区支持和丰富的包资源,为金融分析提供了强大的后盾。YieldCurve包专注于债券市场分析,它提供了一套丰富的工具来构建和分析收益率曲线,这对于投资者和分析师来说是不可或缺的。
## 1.2 YieldCurve包的安装与加载
在开始使用YieldCurve包之前,首先确保R环境已经配置好,接着使用`install.packages("YieldCurve")`命令安装包,安装完成后,使用`library(YieldCurve)`加载它。
``
【extRemes包深度应用】:构建自定义模型,掌握极端值分析的核心

# 1. extRemes包概览与极端值理论基础
## 1.1 极端值理论简介
极端值理论(EVT)是概率论的一个分支,专注于研究独立同分布随机变量的极端值的统计特性。这一理论在许多领域中都至关重要,如金融风险评估、气候科学和工程安全等。EVT的核心是确定在给定时间段内,数据集中的极端值发生的可能性,并且能够预测未来极端事件的
【R语言极端值计算】:掌握isnev包算法原理与优化

# 1. R语言极端值计算的基础知识
极端值的计算是数据科学中重要的一个环节,尤其在风险管理、金融分析、环境科学等领域。R语言作为数据分析
【R语言编程实践手册】:evir包解决实际问题的有效策略

# 1. R语言与evir包概述
在现代数据分析领域,R语言作为一种高级统计和图形编程语言,广泛应用于各类数据挖掘和科学计算场景中。本章节旨在为读者提供R语言及其生态中一个专门用于极端值分析的包——evir——的基础知识。我们从R语言的简介开始,逐步深入到evir包的核心功能,并展望它在统计分析中的重要地位和应用潜力。
首先,我们将探讨R语言作为一种开源工具的优势,以及它如何在金融
【R语言parma包案例分析】:经济学数据处理与分析,把握经济脉动

# 1. 经济学数据处理与分析的重要性
经济数据是现代经济学研究和实践的基石。准确和高效的数据处理不仅关系到经济模型的构建质量,而且直接影响到经济预测和决策的准确性。本章将概述为什么在经济学领域中,数据处理与分析至关重要,以及它们是如何帮助我们更好地理解复杂经济现象和趋势。
经济学数据处理涉及数据的采集、清洗、转换、整合和分析等一系列步骤,这不仅是为了保证数据质量,也是为了准备适合于特
【R语言极值事件预测】:评估和预测极端事件的影响,evd包的全面指南

# 1. R语言极值事件预测概览
R语言,作为一门功能强大的统计分析语言,在极值事件预测领域展现出了其独特的魅力。极值事件,即那些在统计学上出现概率极低,但影响巨大的事件,是许多行业风险评估的核心。本章节,我们将对R语言在极值事件预测中的应用进行一个全面的概览。
首先,我们将探究极值事
【R语言时间序列预测大师】:利用evdbayes包制胜未来

# 1. R语言与时间序列分析基础
在数据分析的广阔天地中,时间序列分析是一个重要的分支,尤其是在经济学、金融学和气象学等领域中占据
TTR数据包在R中的实证分析:金融指标计算与解读的艺术

# 1. TTR数据包的介绍与安装
## 1.1 TTR数据包概述
TTR(Technical Trading Rules)是R语言中的一个强大的金融技术分析包,它提供了许多函数和方法用于分析金融市场数据。它主要包含对金融时间序列的处理和分析,可以用来计算各种技术指标,如移动平均、相对强弱指数(RSI)、布林带(Bollinger
【R语言社交媒体分析全攻略】:从数据获取到情感分析,一网打尽!

# 1. 社交媒体分析概览与R语言介绍
社交媒体已成为现代社会信息传播的重要平台,其数据量庞大且包含丰富的用户行为和观点信息。本章将对社交媒体分析进行一个概览,并引入R语言,这是一种在数据分析领域广泛使用的编程语言,尤其擅长于统计分析、图形表示和数据挖掘。
## 1.1
【自定义数据包】:R语言创建自定义函数满足特定需求的终极指南
# 1. R语言基础与自定义函数简介
## 1.1 R语言概述
R语言是一种用于统计计算和图形表示的编程语言,它在数据挖掘和数据分析领域广受欢迎。作为一种开源工具,R具有庞大的社区支持和丰富的扩展包,使其能够轻松应对各种统计和机器学习任务。
## 1.2 自定义函数的重要性
在R语言中,函数是代码重用和模块化的基石。通过定义自定义函数,我们可以将重复的任务封装成可调用的代码
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )