【R语言学习路径】:从基础到高级,R语言与googleVis数据可视化的演变之旅
发布时间: 2024-11-07 13:18:12 阅读量: 25 订阅数: 28 
# 1. R语言基础知识概览
## 1.1 R语言的历史与优势
R语言自1993年由Ross Ihaka和Robert Gentleman发明以来,迅速成为数据科学领域的领导者。R语言的优势在于其开源性,庞大的社区支持,以及丰富的统计和图形功能库。它允许用户快速开发新的分析工具,同时能够处理大型数据集。
## 1.2 R语言的安装与配置
为了开始使用R语言,首先需要下载并安装R语言的官方发行版。可以从CRAN(Comprehensive R Archive Network)网站获取最新的安装包。安装完成后,可选择诸如RStudio等集成开发环境(IDE)来进一步优化开发效率。
## 1.3 R语言的入门操作
R语言中简单的入门级操作包括创建变量,执行基本的算术运算和函数调用。比如:
```r
x <- 10 # 创建一个变量x,并赋值为10
y <- x + 5 # 创建一个变量y,其值为x加上5
print(y) # 输出变量y的值
```
上述代码块演示了赋值操作符`<-`,以及`print()`函数的使用。这些是R语言初学者必须掌握的基本知识。
# 2. R语言数据分析实践
## 2.1 R语言数据结构与类型
### 2.1.1 向量、矩阵、数组的基础操作
在R语言中,向量、矩阵和数组是最基本的数据结构,它们的创建和操作是数据分析的基础。本节将详细介绍这些结构的创建、访问和基本操作。
向量是R语言中最基本的数据结构,它可以包含数值、字符或逻辑值。创建向量的方法很多,最常用的是`c()`函数,它可以将值连接成一个向量。
```R
# 创建一个数值向量
numeric_vector <- c(1, 2, 3, 4, 5)
# 创建一个字符向量
character_vector <- c("apple", "banana", "cherry")
# 创建一个逻辑向量
logical_vector <- c(TRUE, FALSE, TRUE, FALSE)
```
矩阵是一种二维数据结构,所有元素必须是相同的数据类型。可以使用`matrix()`函数创建矩阵,并指定行数和列数。
```R
# 创建一个3x3的矩阵
matrix_data <- matrix(1:9, nrow = 3, ncol = 3)
```
数组是多维的数据结构,至少有两维。可以使用`array()`函数创建数组,并通过`dim`参数定义数组的维度。
```R
# 创建一个3x3x2的数组
array_data <- array(1:18, dim = c(3, 3, 2))
```
### 2.1.2 数据框(DataFrame)与列表(List)
数据框(DataFrame)是R语言中用于存储表格数据的主要数据结构。它类似于数据库中的表格,可以包含不同类型的列。创建数据框可以使用`data.frame()`函数。
```R
# 创建一个数据框
df <- data.frame(
name = c("Alice", "Bob", "Charlie"),
age = c(24, 27, 22),
gender = c("Female", "Male", "Male")
)
```
列表(List)是R语言中最灵活的数据结构,它允许存储不同类型和长度的数据。列表可以包含向量、矩阵、数据框等,甚至可以嵌套其他列表。
```R
# 创建一个列表
my_list <- list(
vector = c(1, 2, 3),
matrix = matrix_data,
data_frame = df
)
```
### 2.2 R语言数据清洗技巧
数据清洗是数据分析中极为重要的一环。本节将探讨处理缺失值、数据合并与转换等常见的数据清洗技巧。
#### 2.2.1 缺失值处理方法
在数据分析中,处理缺失值是一个常见的问题。R语言提供了多种方法来处理这些缺失值。
- 删除含有缺失值的行或列
```R
# 删除含有缺失值的行
df_cleaned <- na.omit(df)
# 删除含有缺失值的列
df_cleaned <- df[ , colSums(is.na(df)) == 0]
```
- 填充缺失值
```R
# 使用均值填充数值型列的缺失值
df$age[is.na(df$age)] <- mean(df$age, na.rm = TRUE)
# 使用众数填充字符型列的缺失值
mode_value <- names(sort(-table(df$gender)))[1]
df$gender[is.na(df$gender)] <- mode_value
```
#### 2.2.2 数据合并与转换技术
数据合并和转换是清洗过程中必不可少的步骤。R语言中的`merge()`函数可以用来合并两个数据框,而`tidyr`包提供了`pivot_longer()`和`pivot_wider()`函数来转换数据格式。
```R
# 合并数据框
merged_df <- merge(df1, df2, by = "id_column")
```
```R
# 将宽格式数据转换为长格式
df_long <- pivot_longer(df, cols = c("var1", "var2"))
```
```R
# 将长格式数据转换为宽格式
df_wide <- pivot_wider(df_long, names_from = "name", values_from = "value")
```
### 2.3 R语言统计分析方法
R语言强大的统计分析能力使其在数据科学领域备受青睐。本节将介绍基本统计函数和一些高级统计分析方法。
#### 2.3.1 基本统计函数使用
R语言提供了许多用于计算基本统计量的函数,如均值、中位数、标准差等。
```R
# 计算均值
mean_value <- mean(df$age)
# 计算中位数
median_value <- median(df$age)
# 计算标准差
sd_value <- sd(df$age)
```
#### 2.3.2 假设检验与回归分析
R语言在进行假设检验和回归分析方面也提供了许多内置函数。例如,`t.test()`用于进行t检验,`lm()`用于线性回归分析。
```R
# 进行单样本t检验
t_test_result <- t.test(df$age, mu = 25)
```
```R
# 线性回归分析
lm_result <- lm(age ~ salary, data = df)
```
在接下来的文章中,我们将进一步深入探讨R语言在数据可视化、交互式可视化工具、高级数据分析方面的应用与实践。
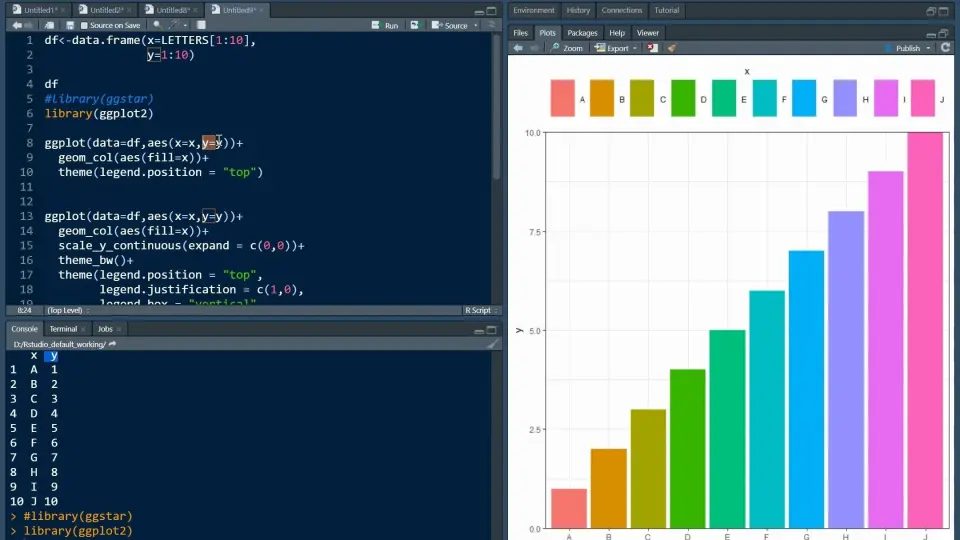
# 3. R语言数据可视化基础
数据可视化是数据分析的重要组成部分,它帮助我们将数据转化为直观的图表,以便更好地理解和传达数据背后的故事。在R语言中,数据可视化既可以通过图形用户界面(GUI)操作,也可以通过编程方式进行。本章节将深入探讨R语言在数据可视化方面的基础知识和进阶技巧。
## 3.1 图形用户界面(GUI)基础
RStudio是R语言中使用最广泛的集成开发环境(IDE),其内置的可视化工具可以让用户直观地操作和理解数据。与此同时,R语言还提供了强大的基础图形绘制能力。
### 3.1.1 RStudio

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
本专栏提供了一系列关于 R 语言 googleVis 数据包的详细教程,涵盖从入门到高级的各个方面。通过深入浅出的讲解和丰富的实战案例,专栏旨在帮助读者掌握 googleVis 的核心功能和高级技巧,从而有效地进行数据可视化和数据探索。从安装、更新到图表定制和性能优化,专栏提供了全面的指南,帮助读者充分利用 googleVis 的强大功能,打造专业级的数据可视化解决方案,让数据讲出引人入胜的故事。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
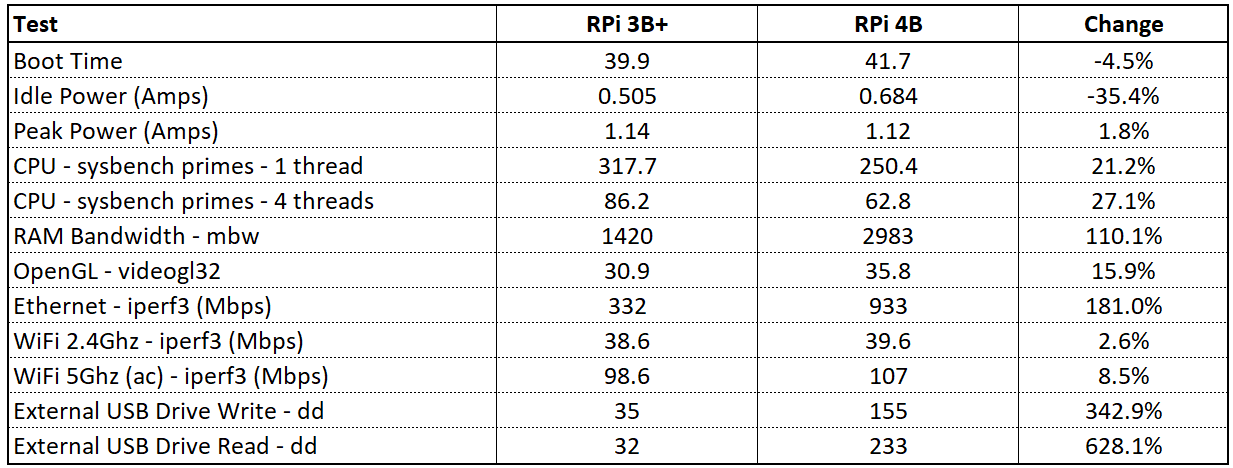
Odroid XU4与Raspberry Pi比较分析
# 摘要
本文详细比较了Odroid XU4与Raspberry Pi的硬件规格、操作系统兼容性、性能测试与应用场景分析,并进行了成本效益分析。通过对比处理器性能、内存存储能力、扩展性和连接性等多个维度,揭示了两款单板计算机的优劣。文章还探讨了它们在图形处理、视频播放、科学计算和IoT应用等方面的实际表现,并对初次购买成本与长期运营维护成本进行了
WinRAR CVE-2023-38831漏洞全生命周期管理:从漏洞到补丁

# 摘要
WinRAR CVE-2023-38831漏洞的发现引起了广泛关注,本文对这一漏洞进行了全面概述和分析。我们深入探讨了漏洞的技术细节、成因、利用途径以及受影响的系统和应用版本,评估了漏洞的潜在风险和影响等级。文章还提供了详尽的漏洞应急响应策略,包括初步的临时缓解措施、长期修复
【数据可视化个性定制】:用Origin打造属于你的独特图表风格

# 摘要
随着数据科学的发展,数据可视化已成为传达复杂信息的关键手段。本文详细介绍了Origin软件在数据可视化领域的应用,从基础图表定制到高级技巧,再到与其他工具的整合,最后探讨了最佳实践和未来趋势。通过Origin丰富的图表类型、强大的数据处理工具和定制化脚本功能,用户能够深入分析数据并创建直观的图表。此外,本文还探讨了如何利用Origin的自动化和网络功能实现高效的数据可视化协作和分享。通
【初学者到专家】:LAPD与LAPDm帧结构的学习路径与进阶策略
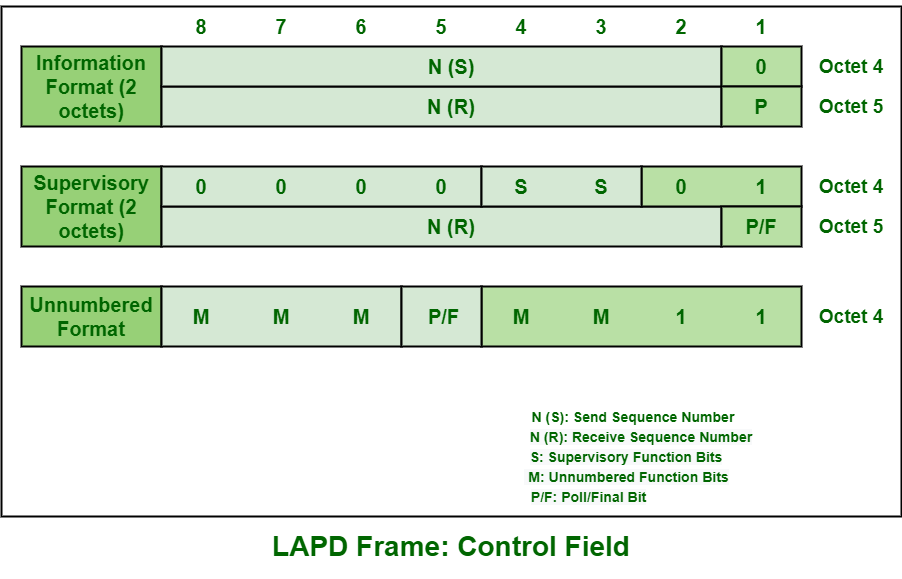
# 摘要
本文全面阐述了LAPD(Link Access Procedure on the D-channel)和LAPDm(LAPD modified)协议的帧结构及其相关理论,并深入探讨了这两种协议在现代通信网络中的应用和重要性。首先,对LAPD和LAPDm的帧结构进行概述,重点分析其组成部分与控制字段。接着,深入解析这两种协议的基础理论,包括历史发展、主要功能与特点
医学成像革新:IT技术如何重塑诊断流程

# 摘要
本文系统探讨了医学成像技术的历史演进、IT技术在其中的应用以及对诊断流程带来的革新。文章首先回顾了医学成像的历史与发展,随后深入分析了IT技术如何改进成像设备和数据管理,特别是数字化技术与PACS的应用。第三章着重讨论了IT技术如何提升诊断的精确性和效率,并阐述了远程医疗和增强现实技术在医学教育和手术规划中的应用。接着,文章探讨了数据安全与隐私保护的挑战,以及加密
TriCore工具链集成:构建跨平台应用的链接策略与兼容性解决

# 摘要
本文对TriCore工具链在跨平台应用构建中的集成进行了深入探讨。文章首先概述了跨平台开发的理论基础,包括架构差异、链接策略和兼容性问题的分析。随后,详细介绍了TriCore工具链的配置、优化以及链接策略的实践应用,并对链接过程中的兼容性
【ARM调试技巧大公开】:在ARMCompiler-506中快速定位问题

# 摘要
本文详述了ARM架构的调试基础,包括ARM Compiler-506的安装配置、程序的编译与优化、调试技术精进、异常处理与排错,以及调试案例分析与实战。文中不仅提供安装和配置ARM编译器的具体步骤,还深入探讨了代码优化、工具链使用、静态和动态调试、性能分析等技术细节。同时,本文还对ARM异常机制进行了解
【远程桌面工具稳定安全之路】:源码控制与版本管理策略
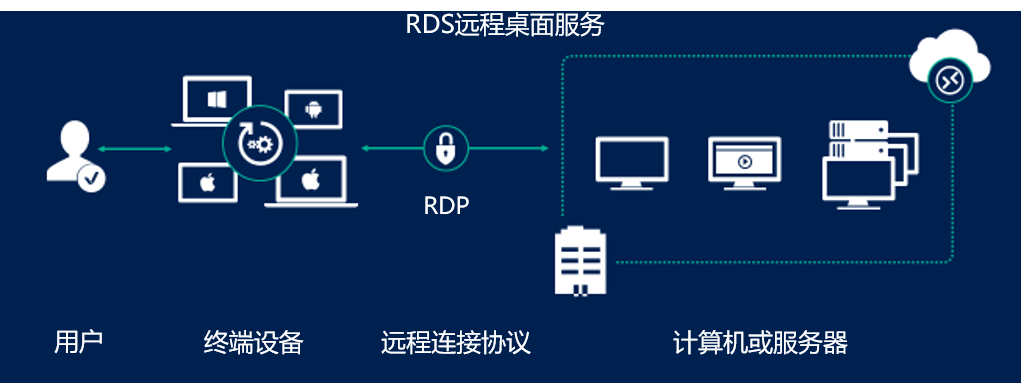
# 摘要
本文系统地介绍了远程桌面工具与源码控制系统的概念、基础和实战策略。文章首先概述了远程桌面工具的重要性,并详细介绍了源码控制系统的理论基础和工具分类,包括集中式与分布式源码控制工具以及它们的工作流程。接着,深入讨论了版本管理策略,包括版本号规范、分支模型选择和最佳实践。本文还探讨了远程桌面工具源码控制策略中的安全、权限管理、协作流程及持续集成。最后,文章展望了版本管理工具与
【网络连接优化】:用AT指令提升MC20芯片连接性能,效率翻倍(权威性、稀缺性、数字型)

# 摘要
随着物联网设备的日益普及,MC20芯片在移动网络通信中的作用愈发重要。本文首先概述了网络连接优化的重要性,接着深入探讨了AT指令与MC20芯片的通信原理,包括AT指令集的发展历史、结构和功能,以及MC20芯片的网络协议栈。基于理论分析,本文阐述了AT指令优化网络连接的理论基础,着重于网络延迟、吞吐量和连接质量的评估。实
【系统稳定性揭秘】:液态金属如何提高计算机物理稳定性
# 摘要
随着计算机硬件性能的不断提升,计算机物理稳定性面临着前所未有的挑战。本文综述了液态金属在增强计算机稳定性方面的潜力和应用。首先,文章介绍了液态金属的理论基础,包括其性质及其在计算机硬件中的应用。其次,通过案例分析,探讨了液态金属散热和连接技术的实践,以及液态金属在提升系统稳定性方面的实际效果。随后,对液态金属技术与传统散热材
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )