深入理解Anaconda环境管理和包管理
发布时间: 2024-04-09 15:40:26 阅读量: 68 订阅数: 47 

如何安装并使用conda指令管理python环境
# 1. 深入理解Anaconda环境管理和包管理
1. **Anaconda简介**
Anaconda是一个用于科学计算的Python发行版,包含了conda、Python和许多科学计算相关的库和工具。它能够简化包的安装和管理,使得数据科学家更加专注于解决问题,而不是配置环境。
Anaconda的不同版本针对不同用户需求提供了多个版本,其中包含了丰富的数据科学工具。用户可以根据实际需求选择适合自己的版本,从而提高工作效率和数据科学实验的质量。
| Anaconda版本 | 主要特点 |
| -------------- | -------------------------- |
| Individual Edition | 适合个人用户的免费版本 |
| Team Edition | 针对团队协作和生产环境的版本 |
| Enterprise Edition | 针对企业级部署的版本 |
Anaconda的优势主要体现在以下几个方面:
- **环境管理:** Anaconda能够方便地创建、管理和切换不同的Python环境,避免了不同项目之间的依赖冲突。
- **包管理:** Anaconda提供了强大的包管理工具conda,可以方便地安装、更新和卸载Python包。
- **数据科学工具:** Anaconda预装了许多用于数据分析、机器学习和深度学习的库和工具,大大简化了数据科学家的工作流程。
- **跨平台支持:** Anaconda支持多个操作系统,包括Windows、macOS和Linux,使得在不同平台上的工作无缝切换。
# 2. Anaconda环境管理
Anaconda环境管理是Anaconda提供的功能之一,可以帮助用户创建、管理和删除不同的Python环境,以便在不同的项目中使用特定的Python版本和包。下面将介绍Anaconda环境管理的具体操作。
#### 创建新环境
通过以下步骤可以创建一个名为`myenv`的新环境:
```bash
conda create --name myenv
```
创建环境时可以指定Python版本:
```bash
conda create --name myenv python=3.8
```
#### 管理环境变量
可以使用以下命令在环境中安装软件包:
```bash
conda install -n myenv package_name
```
可以激活环境并设置环境变量:
```bash
conda activate myenv
```
#### 删除环境
如果需要删除环境`myenv`,可以运行以下命令:
```bash
conda remove --name myenv --all
```
另一种删除环境的方法是:
```bash
conda env remove --name myenv
```
#### 流程图示例
下面是一个简单的mermaid流程图,展示了创建新环境的过程:
```mermaid
graph TD
A[开始] --> B[创建环境 myenv]
B --> C{环境成功创建?}
C -->|是| D[激活环境]
C -->|否| E[结束]
```
通过以上操作,可以有效地管理Anaconda环境,确保不同项目之间的隔离和独立,提高开发效率。
# 3. **Anaconda包管理**
Anaconda不仅提供了强大的环境管理功能,还提供了便捷的包管理工具,让用户可以轻松安装、更新和卸载各种Python包。
1. **安装包**
- 使用conda安装包非常简单,只需在命令行中输入`conda install package_name`即可。例如,安装numpy包可以使用`conda install numpy`。
2. **更新包**
- 通过conda也可以轻松更新已安装的包,只需要运行`conda update package_name`命令即可。比如,更新numpy包可以使用`conda update numpy`。
3. **卸载包**
- 如果需要卸载某个包,只需在命令行中执行`conda remove package_name`即可完成包的卸载。例如,卸载numpy包可以使用`conda remove numpy`。
下面是一个示例代码,在Anaconda环境中使用conda来安装、更新和卸载包:
```bash
# 安装numpy包
conda install numpy
# 更新numpy包
conda update numpy
# 卸载numpy包
conda remove numpy
```
通过以上操作,用户可以轻松管理Anaconda环境中的各种Python包,确保环境中的包始终保持最新版本,以便开展数据科学相关的工作。
针对Anaconda包管理的流程,下面使用mermaid格式流程图展示操作步骤:
```mermaid
graph LR
A[开始] --> B(安装包)
B --> C(更新包)
C --> D(卸载包)
D --> E[结束]
```
在这个流程中,用户可以根据需求选择安装、更新或卸载包,从而灵活管理Anaconda环境中的包。
# 4. **Anaconda包管理与虚拟环境**
在Anaconda中,包管理和虚拟环境是非常重要的概念,可以帮助我们更好地管理和组织项目所需的依赖包和环境。下面将详细介绍Anaconda包管理与虚拟环境的相关内容。
#### 4.1 什么是虚拟环境
虚拟环境是一种机制,允许在同一台计算机上同时管理多个独立的Python环境。每个虚拟环境都有自己的安装目录,可以安装不同版本的Python解释器和包,从而隔离项目之间的依赖关系。通过虚拟环境,我们可以更好地管理项目的依赖关系,避免因为不同项目所需的包版本冲突而导致问题。
#### 4.2 在虚拟环境中使用包管理功能
在Anaconda中,我们可以使用 `conda` 命令在虚拟环境中进行包管理。以下是在虚拟环境中使用 `conda` 进行包管理的一些常用操作:
1. 列出当前虚拟环境中已安装的包:
```bash
conda list
```
2. 在虚拟环境中安装新的包,例如安装 pandas:
```bash
conda install pandas
```
3. 更新虚拟环境中的某个包,例如更新 numpy:
```bash
conda update numpy
```
4. 卸载虚拟环境中的某个包,例如卸载 matplotlib:
```bash
conda remove matplotlib
```
通过以上操作,我们可以在不同的虚拟环境中灵活管理各自项目的依赖关系,确保项目之间的独立性和稳定性。
#### 虚拟环境包管理操作示例表格
下表展示了在虚拟环境中使用 `conda` 进行包管理的示例操作和对应的结果:
| 操作 | 命令 | 结果 |
|--------------|----------------------|--------------------------------------------------------------|
| 列出已安装包 | conda list | pandas, numpy, scikit-learn |
| 安装新包 | conda install matplotlib | 安装 matplotlib 包到虚拟环境中 |
| 更新包 | conda update pandas | 更新 pandas 到最新版本 |
| 卸载包 | conda remove numpy | 卸载虚拟环境中的 numpy 包 |
#### 虚拟环境包管理流程图
```mermaid
graph LR
A[开始] --> B{选择操作}
B -->|安装新包| C[conda install package]
B -->|更新包| D[conda update package]
B -->|卸载包| E[conda remove package]
C --> F[安装成功]
D --> G[更新成功]
E --> H[卸载成功]
F --> I[结束]
G --> I
H --> I
I --> J[结束]
```
# 5. **Anaconda环境共享与导出**
在Anaconda中,环境的共享与导出是非常重要的功能,可以方便地在不同的机器之间共享环境配置和包依赖。下面将介绍如何进行环境的导出、共享和导入操作。
1. **导出环境**
使用以下命令可以将当前环境导出为一个`environment.yml`文件:
```bash
conda env export > environment.yml
```
这样就会生成一个包含当前环境中所有包信息的`environment.yml`文件,其中包括包名、版本号等信息。
2. **共享环境**
将导出的`environment.yml`文件分享给他人后,对方可以使用该文件来创建相同的环境,只需运行以下命令:
```bash
conda env create -f environment.yml
```
这将根据`environment.yml`文件中的包信息重新创建一个与原环境相同的环境。
3. **导入环境**
若要在新的机器上使用已有的环境配置,可以将`environment.yml`文件复制到新机器上,然后运行如下命令:
```bash
conda env create -f environment.yml
```
这样便能在新机器上重新创建与原环境相同的环境配置。
| 包名 | 版本 |
|-----------|--------|
| numpy | 1.19.2 |
| pandas | 1.1.3 |
| scikit-learn | 0.23.2 |
**导出环境示例代码:**
```bash
conda env export > environment.yml
```
**共享环境示例代码:**
```bash
conda env create -f environment.yml
```
```mermaid
graph LR
A(导出环境) --> B(共享环境)
B --> C(导入环境)
```
通过上述操作,我们可以方便地在不同的机器之间共享和导入Anaconda环境,以确保开发环境的一致性。
# 6. **Anaconda环境与Jupyter Notebook集成**
Anaconda环境与Jupyter Notebook的集成是在数据科学工作流中非常常见的一种方式,能够有效地管理环境和Python包。
1. **在Jupyter Notebook中使用Anaconda环境**
- 在Jupyter Notebook中可以选择不同的内核,也即不同的Anaconda环境,以便使用该环境中安装的Python版本和包。
- 下面是在Jupyter Notebook中更改内核的代码示例:
```python
# 安装 jupyter 和 ipykernel
!pip install jupyter ipykernel
# 将conda环境添加到Jupyter Notebook中
!python -m ipykernel install --user --name=myenv --display-name "Python (myenv)"
```
- 通过上述代码,可以将名为"myenv"的Anaconda环境添加到Jupyter Notebook中,以便在Notebook中选择该环境作为内核运行代码。
2. **安装Jupyter Notebook扩展**
- Jupyter Notebook提供了许多有用的扩展功能,可以进一步增强编辑、展示和操作Notebook的功能。
- 下表列出了一些常用的Jupyter Notebook扩展及其作用:
| 扩展名 | 功能 |
|---------------------|------------------------|
| jupyter_contrib_nbextensions | 添加额外的Notebook功能和工具 |
| jupyter_nbextensions_configurator | 可视化配置Notebook的扩展 |
| variableInspector | 在Notebook中查看变量和其值 |
| autopep8 | 自动格式化Python代码 |
| toc2 | 生成Notebook的目录 |
- 通过安装这些扩展,可以提升Jupyter Notebook的编写和展示效率,使得数据科学工作流更加流畅。
3. **总结**
- 通过以上操作,可以将Anaconda环境与Jupyter Notebook完美集成,实现在不同环境中管理Python包和版本、快速切换内核、使用丰富的Notebook扩展功能等,为数据科学工作提供了便利和灵活性。
以上是关于Anaconda环境与Jupyter Notebook集成的内容,通过这些方法可以更好地利用Anaconda环境进行数据科学和机器学习工作。
# 7. **Anaconda环境与数据科学应用**
Anaconda作为一个集成的数据科学环境,提供了丰富的工具和库,支持数据处理、分析和机器学习等任务。下面将介绍Anaconda在数据科学领域的应用和相关示例。
1. **Anaconda在数据科学中的应用**
- Anaconda提供了包括NumPy、Pandas、Matplotlib在内的数据科学工具库,方便数据处理和可视化。
- 通过Anaconda的虚拟环境管理,可以为不同项目创建独立的环境,确保项目间的依赖隔离。
2. **数据处理、分析和机器学习示例**
- 示例代码如下:
```python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 创建一个DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'Salary': [50000, 60000, 70000, 80000]}
df = pd.DataFrame(data)
# 打印DataFrame的前几行数据
print(df.head())
# 绘制年龄和工资的散点图
plt.scatter(df['Age'], df['Salary'])
plt.xlabel('Age')
plt.ylabel('Salary')
plt.title('Age vs. Salary')
plt.show()
```
- 代码总结:以上代码示例使用了NumPy进行数据处理,Pandas创建并操作DataFrame,Matplotlib绘制了散点图。
3. **深度学习框架与Anaconda集成**
- Anaconda可以很好地集成深度学习框架,如TensorFlow、PyTorch等,方便进行神经网络模型的开发和训练。
- 通过Anaconda的包管理功能,可以方便地安装和更新各种深度学习库和工具。
下面是一个展示使用Anaconda环境进行数据处理、分析和可视化的流程图(Mermaid格式):
```mermaid
graph TD;
A[数据采集] --> B[数据清洗]
B --> C[数据分析]
C --> D[数据可视化]
```
通过以上章节的讲解,读者可以了解Anaconda在数据科学中的重要作用,以及如何利用Anaconda环境进行数据处理、分析和机器学习任务。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Anaconda 环境管理和包管理的各个方面。从 Anaconda 的安装和配置到虚拟环境的创建和管理,再到包安装和卸载,本专栏提供了全面的指南。它还介绍了 Anaconda 环境变量的配置、Python 版本管理、Jupyter Notebook 的使用、数据科学和机器学习库的安装和优化,以及虚拟环境中不同 Python 版本的切换。此外,本专栏还提供了有关虚拟环境备份和恢复、环境优化、常见问题解决方案以及 Anaconda 中 conda 命令使用的深入信息。通过阅读本专栏,读者可以全面了解 Anaconda 环境管理,并提高其数据科学和机器学习工作流程的效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【IBM Power AIX系统安装新手指南】:0基础到英雄的完美升级之路

# 摘要
本文详细介绍了IBM Power AIX系统的安装、基础管理操作以及高级管理技巧。首先概述了AIX系统的特点及安装前的准备工作,随后深入解析了系统的安装步骤和初始化配置流程。文章进一步探讨了文件系统管理、用户权限管理、进程监控等基础管理任务,并介绍了性能监控、
【H3C-CAS-Converter深度剖析】:核心组件与功能的专家解析

# 摘要
本文详细介绍了H3C-CAS-Converter的设计和功能,重点解析了其核心组件,包括架构总览、功能定位和交互关系,以及关键组件如数据转换引擎、格式解析器和数据验证模块的实现。进一步探讨了 Converter 的功能,例如支持的转换格式、高级特性、用户交互和配置管理。通过实际部署案例分析,阐述了 Converter 在数据迁移、同步备
风险管理高级应用:德勤智能地图案例深度剖析,提升风险管理效能

# 摘要
本文旨在探讨智能地图技术在企业风险管理中的应用与效能。首先,概述了风险管理的理论基础及智能地图技术的发展,然后重点分析了智能地图在风险识别、评估、应对与监控中的具体作用,结合德勤智能地图的案例,详细说明了其在理论与实践
【环境优化】Lumion 12 Pro场景环境调整与优化最佳实践
# 摘要
本文详细介绍了Lumion 12 Pro软件的基础设置与高级技巧,着重探讨了场景环境构建、渲染与动画调整、以及性能优化与系统管理等方面。通过具体操作技巧的阐述,如场景元素的导入与编辑、环境效果的精细控制、渲染质量的提升和粒子系统的优化应用,本文意在为用户提供高效创建真实感场景和动画的方法。同时,针对硬件资源分配、文件管理和稳定性提升的讨论,为Lumion使用
图像恢复技术精讲:期末复习噪声与失真处理术(噪声失真解决速成)

# 摘要
图像恢复技术是数字图像处理中的一个关键领域,它致力于从噪声和失真中恢复原始图像的清晰度和完整性。本文首先概述了图像恢复技术的基本概念,随后深入探讨了图像噪声和失真的分类、特性、以及其对图像质量的影响。紧接着,文章详细介绍了图像去噪和复原技术的原理和实践,包括空间域和频域去噪方法、图像复原的策略和高级技术。此外,本文还审视了当前常用的图像处理工具,并通过案
【Excel公式高级运用】:揭秘如何自动从身份证号码提取年龄
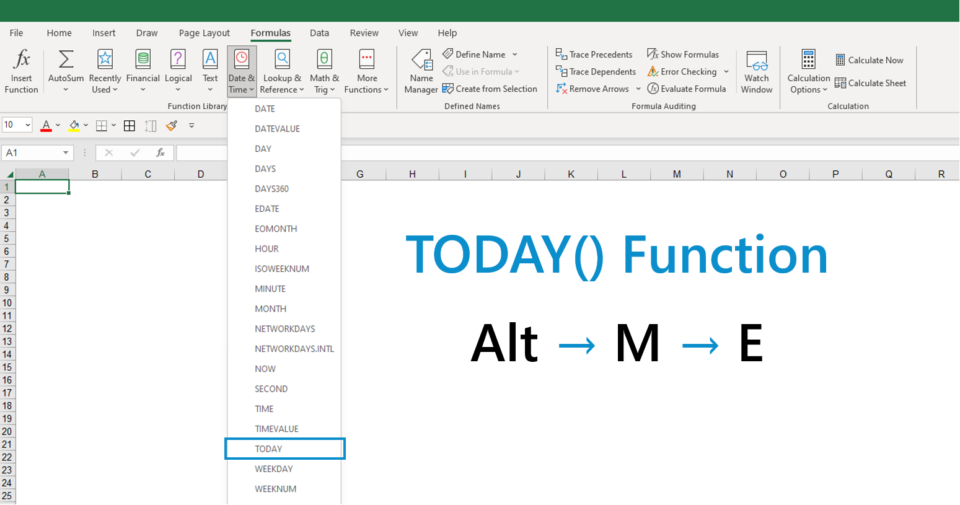
# 摘要
本文系统回顾了Excel公式的基础知识,并深入探讨了如何从身份证号码中提取和解读关键信息。通过详细分析身份证号码的结构及关键信息的定位方法,本文进一步介绍了提取关键信息的常用Excel函数,如LEFT、RIGHT和MID函数,以及文本与数字转换的技巧。接着,文章集中于构建基于身份证号码提取出生年份和计算年龄的公式,同时提供了逻辑实现和实例应用场
iSecure Center深度解读:掌握这5大新趋势,企业安全升级立见成效

# 摘要
随着数字化转型的加速,企业安全面临前所未有的挑战和新的技术趋势。iSecure Center作为一个全面的安全解决方案,扮演着帮助企业应对信息安全威胁、提升安
【单片机编程必备】:掌握10个关键函数,提升你的编程效率

# 摘要
单片机编程作为嵌入式系统开发的重要组成部分,对提升硬件控制能力有着举足轻重的作用。本文首先介绍了单片机编程的基础知识与关键函数的理论基础,详细探讨了函数定义、参数传递机制、返回值以及函数的分类和选择标准。随后,文章深入实践技巧部分,讨论了输入输出、定时器及中断处理函数的使用和优化。在关键函数的应用章节中,本文解释了
CRC校验故障排除手册:Modbus_RTU协议下的常见问题深度解析
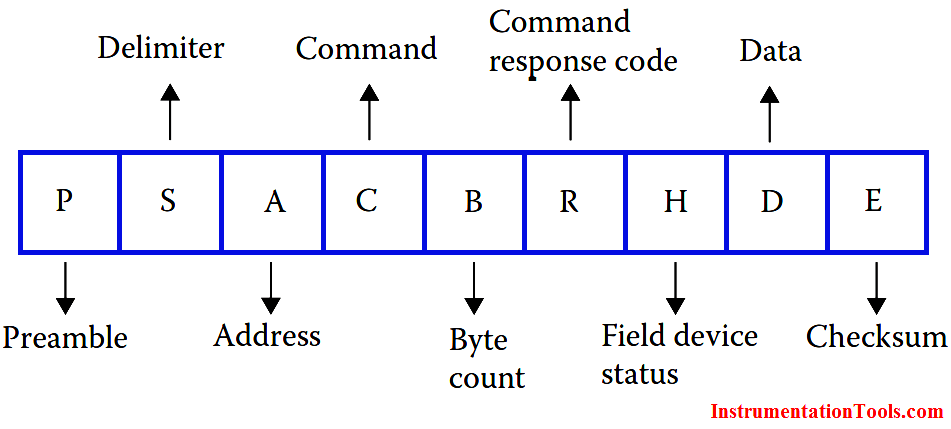
# 摘要
本文对CRC校验和Modbus_RTU协议进行了全面的介绍和分析,探讨了CRC校验的基本原理及其在Modbus_RTU协议中的应用,以确保数据传输的完整性。同时,本文详细分析了CRC校验可能出现的常见故障,并提供了故障诊断和解决的方法。此外,文章通过实践案例深入
【FPGA时序分析】:input延迟影响及输出延迟调优策略

# 摘要
本文深入探讨了FPGA时序分析的基础知识、输入输出延迟的理论与实践、以及时序分析工具与方法。通过对输入延迟的概念解析,分析了时钟域交叉与时钟偏斜对系统性能的影响,并探讨了输入延迟的测量方法及优化实例。输出延迟调优章节介绍了输出延迟的理论基础、技术手段及其在高速
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )