Anaconda环境中Jupyter Notebook的配置和使用
发布时间: 2024-04-09 15:47:24 阅读量: 203 订阅数: 48 
# 1. 安装Anaconda
## 1.1 下载Anaconda安装包
- 访问[Aanconda官网](https://www.anaconda.com/products/distribution)下载适用于你操作系统的Anaconda安装包
- 选择合适的版本(推荐选择最新版本),点击下载并等待下载完成
- 下载完成后,双击下载的安装包,按照提示进行安装
## 1.2 安装Anaconda
- 打开下载好的Anaconda安装包,点击“Next”开始安装
- 阅读并接受许可协议,点击“Next”继续
- 选择安装路径和是否将Anaconda添加到系统环境变量中,点击“Next”继续
- 点击“Install”开始安装,等待安装完成
- 安装完成后,点击“Next”并点击“Finish”退出安装向导
## 1.3 配置Anaconda环境变量
- 打开Anaconda Navigator,在“Environments”选项卡中,点击“base (root)”下方的“Play”按钮启动Anaconda环境
- 在“Home”选项卡中,点击“Launch”下的Jupyter Notebook图标启动Jupyter Notebook
- 如果无法启动,需要手动配置环境变量:将Anaconda安装路径下的“Scripts”文件夹加入系统Path变量中
- 在命令行输入`jupyter notebook`来启动Jupyter Notebook,确保环境变量配置成功
通过以上步骤,你已经成功地安装并配置好了Anaconda环境,可以开始使用Jupyter Notebook进行编程和数据分析工作。
# 2. 启动Jupyter Notebook
在本章中,将介绍如何启动Jupyter Notebook,并对其界面进行详细介绍,同时演示如何创建一个新的Jupyter Notebook文件。
#### 2.1 启动Jupyter Notebook
启动Jupyter Notebook可以通过Anaconda Navigator来实现,也可以在命令行中直接输入`jupyter notebook`来启动。以下是一些常用的启动命令:
- 在命令行中输入`jupyter notebook`并回车启动Jupyter Notebook
- 在Anaconda Navigator中点击Jupyter Notebook图标启动
#### 2.2 Jupyter Notebook界面介绍
Jupyter Notebook的界面主要包括以下几个核心组件:
| 组件 | 描述 |
|--------------|-------------------------------------------|
| 文件浏览器 | 显示当前目录下的文件和文件夹 |
| 菜单栏 | 包含各种操作命令的菜单 |
| 工具栏 | 提供快捷操作按钮 |
| 代码单元格 | 编写和执行代码的区域 |
| Markdown单元格| 编写说明文档的区域 |
#### 2.3 创建一个新的Jupyter Notebook文件
要创建一个新的Jupyter Notebook文件,请按照以下步骤操作:
1. 点击界面上方的“New”按钮
2. 在下拉菜单中选择所需的编程语言(如Python 3)
3. 一个新的Notebook文件将被创建并显示在界面中,可以开始编写代码和文字内容
```python
# 示例代码:打印Hello World
print("Hello World")
```
```mermaid
graph TD;
A(启动Jupyter Notebook) --> B{选择语言};
B -->|选择Python| C(创建新文件);
B -->|选择R| D(创建新文件);
```
通过以上步骤,您已经学会了如何启动Jupyter Notebook,并创建一个新的文件进行编写和执行代码。在接下来的章节中,我们将继续探讨Jupyter Notebook的更多功能和用法。
# 3. Jupyter Notebook基本功能
### 3.1 Markdown和Code单元格
在Jupyter Notebook中,我们可以使用Markdown单元格来插入文本、标题、列表等内容,也可以使用Code单元格来编写和执行代码。
下面是一个简单的示例,演示如何在Markdown单元格中插入一个列表:
1. 第一项
2. 第二项
- 子项1
- 子项2
3. 第三项
接着,让我们来看一个简单的代码示例,在Code单元格中计算1加1的结果:
```python
# 计算1 + 1
1 + 1
```
### 3.2 执行代码和快捷键
在Jupyter Notebook中,我们可以使用快捷键来快速执行代码,例如在Code单元格中按下`Shift + Enter`即可执行该单元格的代码并切换到下一个单元格。此外,我们也可以使用菜单栏中的按钮来执行代码。
### 3.3 插入、移动和删除单元格
要在Jupyter Notebook中插入新的单元格,可以通

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Anaconda 环境管理和包管理的各个方面。从 Anaconda 的安装和配置到虚拟环境的创建和管理,再到包安装和卸载,本专栏提供了全面的指南。它还介绍了 Anaconda 环境变量的配置、Python 版本管理、Jupyter Notebook 的使用、数据科学和机器学习库的安装和优化,以及虚拟环境中不同 Python 版本的切换。此外,本专栏还提供了有关虚拟环境备份和恢复、环境优化、常见问题解决方案以及 Anaconda 中 conda 命令使用的深入信息。通过阅读本专栏,读者可以全面了解 Anaconda 环境管理,并提高其数据科学和机器学习工作流程的效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MS建模性能提升】:专家告诉你如何用5个技术提高模型处理速度
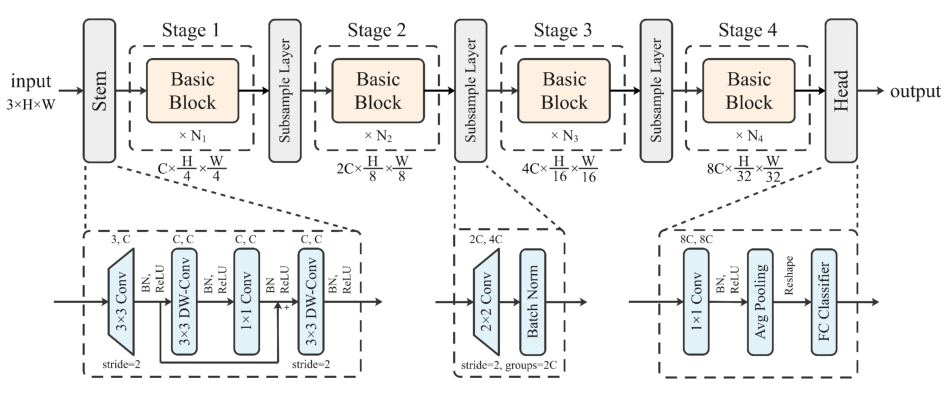
# 摘要
本文旨在提升MS建模的性能,涵盖了数据预处理、模型结构、并行计算、硬件选择和算法创新等多个关键技术。通过优化数据预处理步骤,提高了数据质量和效率;模型结构优化部分探讨了简化复杂度和性能评价指标;并行计算与分布式系统的章节讨论了高效的模型训练方法;硬件加速器的选择与配置章节分析了CPU、GPU及TPU等专用硬件对模型加速的影响;最后,算法优化与创新章节介绍了开源算法库和自
CAP理论实战解读:分布式数据库的可靠性、可用性与分区容忍性平衡术

# 摘要
CAP理论作为分布式系统设计的基础,对分布式数据库的发展起着至关重要的作用。本文首先概述了CAP理论的三要素——一致性、可用性和分区容忍性,并深入探讨了在实际分布式数据库系统中如何权衡这三个要素。通过案例分析,本文比较了不同数据库在CAP策略上的应用差异,并探讨了成功与失败的教训。其次
【DAC模块揭秘】:STM32F103数字模拟转换器的使用和优化技巧

# 摘要
本文详细介绍了DAC(数字到模拟转换器)模块的原理、硬件接口、编程基础、高级应用以及性能优化和故障排除方法。重点阐述STM32F103 DAC模块在各种应用中如何实现精确的模拟信号输出,包括音频信号的生成与控制、信号滤波、多通道应用等
【冠林AH1000系统升级指南】:10个实用技巧助您实现最佳性能
# 摘要
本论文全面介绍了冠林AH1000系统升级的全流程,重点阐述了升级前的准备工作、操作步骤以及性能提升的实用技巧。首先,进行了系统评估和需求分析,包括硬件兼容性检查和功能需求梳理,随后确立了系统备份策略并进行升级风险评估与应对。在系统升级操作步骤章节,详细描述了升级前检查、升级过程指南以及升级后的系统验证流程。此外,探
【逆变器功率管理】:PIC单片机在功率控制策略中的实战应用
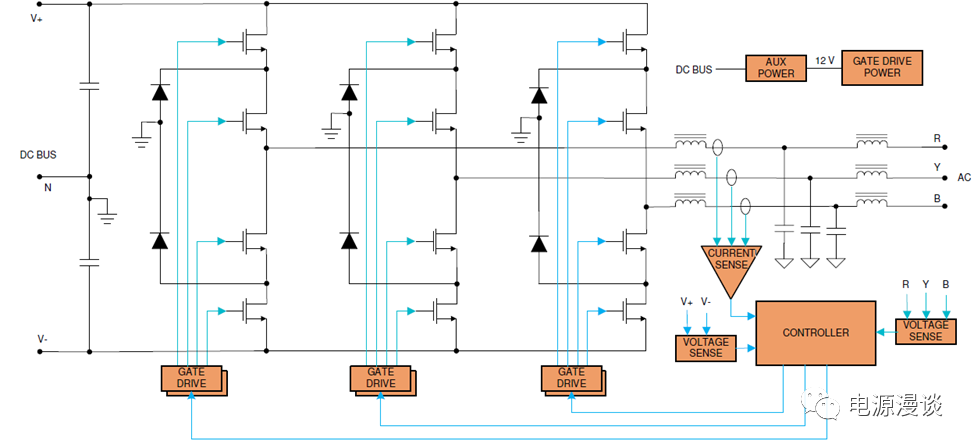
# 摘要
逆变器功率管理是电力电子领域中的关键技术,对于提高能效和优化电力系统性能至关重要。本文从逆变器功率管理的概述开始,详细介绍了PIC单片机在功率控制中的基础作用和编程实现。深入探讨了功率管理理论基础,包括功率管理的基本概念和控制理论模型,以及PIC单片机与功率控制策略的结合。此外,本文还讨论了逆变器功率管理系统
破解电力系统不对称故障:分析、处理与案例实战攻略

# 摘要
电力系统不对称故障是电网安全稳定运行中面临的重要问
【Groops网络优化】:实现无间断通信的关键设置

# 摘要
网络优化在现代通信系统中扮演着至关重要的角色,它确保了数据传输的高效与稳定。本文首先介绍了网络优化的基础概念和其重要性,随后详细探讨了网络协议与数据传输优化策略,包括TCP/IP协议栈的功能分析以及数据包传输优化的机制。文章接着转向无线网络性能的调优,涵盖了无线信号优化、网络安全设置和QoS实现。此外,有线网
从旧系统到现代IT基础设施:Sabre系统升级的关键里程碑
# 摘要
本文综述了Sabre系统的历史与现状,并探讨了现代IT基础设施的理论基础,包括云服务、虚拟化技术、分布式计算与存储。文中详细阐述了Sabre系统升级的实践操作,涉及硬件升级、软件架构转型以及安全性能的提升。升级后,通过对性能评估的方法与工具的研究,以及系统优化的实践案例分析,证实了优
深入探讨:PLC在现代能源管理系统中的关键角色与创新应用

# 摘要
可编程逻辑控制器(PLC)技术作为一种先进的自动化控制工具,在能源管理系统的应用中起着核心作用。本文首先概述了PLC的技术原理及其在能源管理中的基础应用,包括系统设计、监控与控制。随后,探讨了PLC在智能电网、可再生能源管理及高效能源存储中的创新应用技术。接着,文章分析了PLC系统集成与性能优化策略,强调了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )