PyTorch中的自然语言处理技术
发布时间: 2024-04-02 19:20:10 阅读量: 44 订阅数: 21 

PyTorch 自然语言处理
# 1. 简介
- PyTorch简介
- 自然语言处理简介
# 2. PyTorch基础
PyTorch是一个基于Python的科学计算库,在深度学习领域广受欢迎。它提供了强大的张量操作和自动求导功能,使深度学习模型的实现和训练变得更加简单和高效。在自然语言处理领域,PyTorch也被广泛应用于文本数据处理和文本分类等任务。
### 张量(Tensors)操作
在PyTorch中,张量是存储和处理数据的主要数据结构。张量类似于Numpy中的数组,但可以在GPU上运行加速计算。以下是一个简单的张量操作示例:
```python
import torch
# 创建一个大小为3x3的随机张量
x = torch.rand(3, 3)
print(x)
# 在GPU上进行张量运算
if torch.cuda.is_available():
device = torch.device("cuda")
x = x.to(device)
print(x)
```
### 自动求导(Automatic Differentiation)
PyTorch通过自动求导功能,能够自动计算张量的梯度,这对于训练深度学习模型至关重要。以下是一个简单的自动求导示例:
```python
import torch
# 创建一个张量并设置requires_grad=True,表示需要对其求导
x = torch.tensor([2.0], requires_grad=True)
# 定义一个函数 y = x^2
y = x**2
# 自动计算y关于x的梯度
y.backward()
# 打印出导数 dy/dx
print(x.grad)
```
### 模型定义和训练流程
在PyTorch中,可以通过继承`torch.nn.Module`类来定义自定义模型。同时,PyTorch提供了优化器(如SGD、Adam等)和损失函数(如交叉熵损失函数)来训练模型。以下是一个简单的线性回归模型定义和训练示例:
```python
import torch
import torch.nn as nn
# 定义一个线性回归模型
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
# 定义数据和标签
x = torch.tensor([[1.0], [2.0], [3.0]])
y = torch.tensor([[2.0], [4.0], [6.0]])
# 实例化模型、损失函数和优化器
model = LinearRegression()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(100):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/100], Loss: {loss.item()}')
```
通过以上代码示例,可以看到PyTorch在深度学习模型的定义和训练过程中的灵活性和便利性。在接下来的章节中,我们将会更深入地探讨PyTorch在自然语言处理中的应用。
# 3. 自然语言处理基础
在本章节中,我们将介绍自然语言处理(Natural Language Processing,NLP)的基础知识,包括文本数据预处理、词嵌入以及文本分类的实现方法。
#### 文本数据预处理
文本数据预处理是NLP任务中的第一步,它包括去除特殊字符、标点符号,分词、建立词汇表等操作。下面是一个简单的文本数据预处理的示例:
```python
import re
import nltk
nltk.download('punkt')
def preprocess_text(text):
text = text.lower()
text = re.sub(r'[^a-zA-Z0-9\s]', '', text)
tokens = nltk.word_tokenize(text)
return tokens
text = "Hello, this is a sample sentence for text processing!"
tokens = preprocess_text(text)
print(tokens)
```
**代码总结:** 上述代码使用Python中的re模块和nltk库进行文本数据预处理,包括将文本转换为小写、去除特殊字符、分词等。
**结果说明:** 经过预处理后,文本被分割成了单词的列表:['hello', 'this', 'is', 'a', 'sample', 'sentence', 'f

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 PyTorch MAML 元学习专栏!本专栏将带你踏上 PyTorch MAML 元学习的旅程,深入了解其核心概念、实践和应用。从变量声明和数据加载的基础知识到梯度下降优化、模型构建和训练的复杂性,我们将逐步探索 PyTorch MAML 的各个方面。我们将深入研究梯度反向传播、损失函数和评估指标,并探讨神经网络结构和优化技巧。此外,我们还将介绍自定义数据集、模型存储和加载,以及模型微调和迁移学习。对于图像处理和序列建模,我们将深入研究卷积神经网络和循环神经网络。我们还将探讨自然语言处理技术、强化学习算法和超参数优化。最后,我们将关注模型部署、性能优化、多 GPU 并行训练、分布式计算和模型解释。通过这个专栏,你将掌握 PyTorch MAML 元学习的知识和技能,并能够将其应用于实际项目中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SSPRT测试模式:案例驱动的性能优化关键要素解析

# 摘要
本文系统地阐述了SSPRT测试模式及其在性能测试和优化中的应用。首先概述了SSPRT测试模式,随后详细介绍了性能测试的理论基础,包括性能测试的重要性和分类,以及性能测
【Android项目构建加速秘籍】:使用Gradle提升速度的10个技巧
# 摘要
本文深入探讨了Gradle构建工具的基础知识、优化理论和提速技巧。首先,概述了Gradle的项目构建过程,包括其生命周期的三个主要阶
国大牛VMP脱壳脚本进阶教程:自动化与优化并行策略

# 摘要
本文深入探讨了VMP脱壳技术与自动化脚本开发,提供了自动化脚本开发的基础知识,并详细阐述了VMP脱壳脚本的实践应用、优化与性能提升策略。通过具体案例,本文展示了如何实现自动化扫描、脱壳操作及测试,并针对代码优化、内存管理和并行处理等方面提出了实用的改进措施。本文还展望了脚本技术的进阶应用与未来发展趋势,包括机器学习技术的集成和开
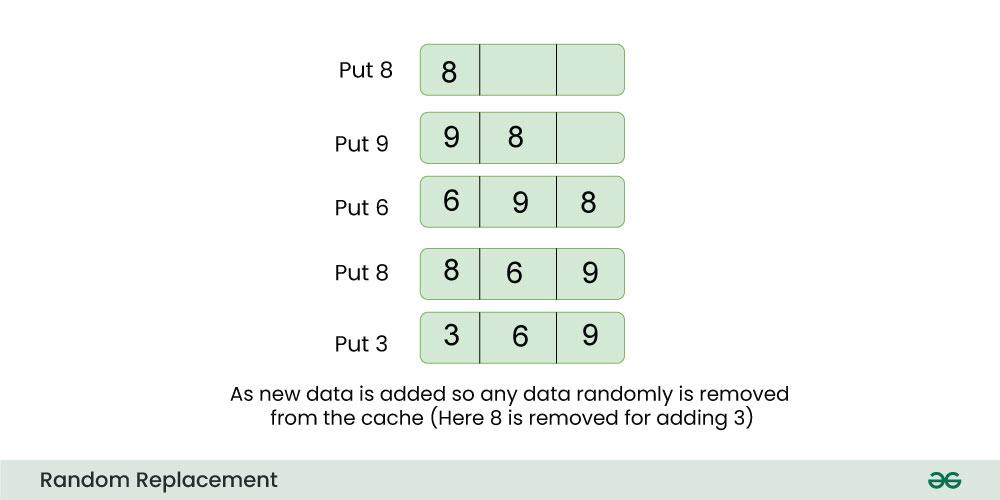
内存管理秘籍:2路组相联Cache设计最佳实践
# 摘要
本文深入探讨了内存管理与Cache技术,特别是2路组相联Cache的设计、优化和性能评估。首先介绍了内存管理与Cache技术的基础知识,然后重点分析了2路组相联Cache的设计理论,包括其工作机制、替换算法以及优化策略。接着,通过实际场景下的性能测试与案例研究,评估了Cache性能,并探讨了优化方法。最后,本文展望了2路组相联Cache在AI、大数据、
【MQTT消息管理】:移远4G模组EC200A的高级消息队列优化技术
# 摘要
本文首先介绍了MQTT协议与消息队列的基础知识,随后对移远4G模组EC200A进行了技术概述。在消息队列优化理论与实践方面,本文详细探讨了优化目标、性能评估指标、排队策略、持久化与缓存机制以及消息过滤和路由技术。文章重点分析了MQTT在移远4G模组中的高级应用,包括服务质量(QoS)、连接管理、主题与订阅管理的优化策略。最后,通过案例分析,展示了消息队列优化在实际应用中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )