




内存管理秘籍:2路组相联Cache设计最佳实践


数据结构_C语言_链表多项式相加_教学示例_1741871959.zip
摘要
本文深入探讨了内存管理与Cache技术,特别是2路组相联Cache的设计、优化和性能评估。首先介绍了内存管理与Cache技术的基础知识,然后重点分析了2路组相联Cache的设计理论,包括其工作机制、替换算法以及优化策略。接着,通过实际场景下的性能测试与案例研究,评估了Cache性能,并探讨了优化方法。最后,本文展望了2路组相联Cache在AI、大数据、物联网及边缘计算等新兴技术领域的应用前景,并讨论了技术创新带来的挑战与机遇。
关键字
内存管理;Cache技术;2路组相联;性能评估;优化策略;技术创新
参考资源链接:头歌计算机组成原理:2路组相联Cache设计详解
1. 内存管理与Cache技术概述
内存管理是现代计算机系统中至关重要的一环,而Cache作为内存与处理器之间快速的缓存存储层,极大地提高了数据的存取速度。本章首先介绍内存管理的基本概念,随后深入探讨Cache技术的基本原理,为后续章节中更专业的2路组相联Cache设计和优化打下坚实的基础。
内存管理的重要性
内存管理的核心任务是确保程序能够高效且稳定地使用物理内存资源。在多任务操作系统中,内存管理负责地址转换、内存分配、回收以及页面置换等操作,它通过分页和分段等机制来优化内存的利用率。
Cache技术的基本原理
Cache技术是计算机体系结构中的一个关键优化手段,它利用处理器与主存之间速度的差距,临时存储频繁访问的数据。这样,当处理器再次需要这些数据时,可以从速度更快的Cache中读取,从而提高整体性能。Cache通常包括以下几个层次:
- 一级Cache(L1):紧靠CPU核心,访问速度快,但容量较小。
- 二级Cache(L2):容量较L1大,速度稍慢,位于CPU核心内或紧邻核心。
- 三级Cache(L3):更大容量的缓存,可用于多个核心共享,位于CPU芯片内。
这些缓存层次通过专门的硬件算法管理数据,确保最频繁被访问的数据被存储在速度最快的缓存中。
Cache与内存管理的结合
在内存管理中,虚拟内存技术与Cache的配合使用,使得系统能够运行比物理内存更大的程序。虚拟内存使用页表来维护虚拟地址到物理地址的映射关系,而Cache则处理那些常访问的虚拟内存页数据。当发生内存访问时,内存管理单元(MMU)先将虚拟地址转换为物理地址,然后Cache控制器尝试从Cache中检索数据。
Cache技术不仅提高了数据存取速度,而且它与内存管理的无缝对接,是现代计算机系统性能提升的关键所在。通过本章的介绍,读者应该对内存管理和Cache技术有了初步了解,为学习更复杂的2路组相联Cache技术打下基础。
2. 2路组相联Cache的设计理论基础
2.1 Cache的基本工作原理
2.1.1 Cache的结构和组成
Cache(缓存)是位于处理器和主存储器之间的一种高速存储器,它的主要目的是减少处理器访问主存储器时的延迟,从而提高整个系统的性能。Cache的基本工作原理涉及以下几个关键组成部分:
- 缓存存储器(Cache Memory):用于临时存放频繁访问的数据副本。
- 标签存储器(Tag Memory):记录缓存存储器中的数据块(Block)与主存地址之间的映射关系。
- 控制逻辑(Control Logic):管理Cache的读写过程,并决定数据是否命中以及在不命中时从主存中加载数据。
一个典型的2路组相联Cache的工作原理图示如下:
在2路组相联Cache中,缓存存储器被分为大小相等的缓存行(Cache Line),每个缓存行可以存放一个或多个数据块。而标签存储器则记录了这些数据块的地址信息。
2.1.2 Cache的映射方式
Cache的映射方式定义了主存中的数据如何映射到Cache中。对于2路组相联Cache来说,主要映射方式有两种:直接映射和组相联映射。
- 直接映射(Direct Mapped):每个主存块只能映射到特定的缓存行。
- 组相联映射(Set Associative):每个主存块可以映射到一组特定的缓存行中的任意一行。
由于2路组相联Cache属于组相联映射的一种,这里主要讲解组相联映射。在2路组相联映射中,每个主存块可映射到两个不同的缓存行,这种方式允许更多的数据块在缓存中竞争同一位置,相对于直接映射,它在一定程度上降低了冲突不命中的概率,提高了Cache的利用效率。
2.2 2路组相联Cache的工作机制
2.2.1 2路组相联的特点与优势
2路组相联Cache结合了直接映射的快速和全相联映射的高命中率的优点,通过为每个主存块提供两个可能的缓存行位置,显著降低了冲突不命中的机会。这种设计允许缓存行之间共享相同的数据块,避免了多行数据只能存储在固定位置的限制。
2.2.2 数据存储与检索过程
数据的存储和检索过程可以通过以下步骤来描述:
- 地址分解(Address Decomposition):处理器发出的地址首先被分解为标记(Tag)、索引(Index)和块内偏移(Block Offset)。
- 缓存行匹配(Cache Line Matching):根据索引和组相联的规则,从Cache中读取多个标记与请求地址的标记进行比较。
- 缓存命中判定(Cache Hit Determination):若缓存行中的任一标记与请求地址的标记匹配,则发生缓存命中,将对应缓存行的数据返回给处理器。
- 缓存未命中处理(Cache Miss Handling):若没有匹配的标记,则缓存未命中,需要从主存储器中获取数据并替换Cache中的数据块。
2.3 Cache替换算法的分析与选择
2.3.1 常见的Cache替换算法
在2路组相联Cache中,若一个缓存行被选中但为空,或在替换时需要决定替换哪个缓存行,就需要使用替换算法。常见的替换算法包括:
- 最近最少使用(LRU):替换最长时间未被访问的缓存行。
- 先进先出(FIFO):替换最早进入Cache的缓存行。
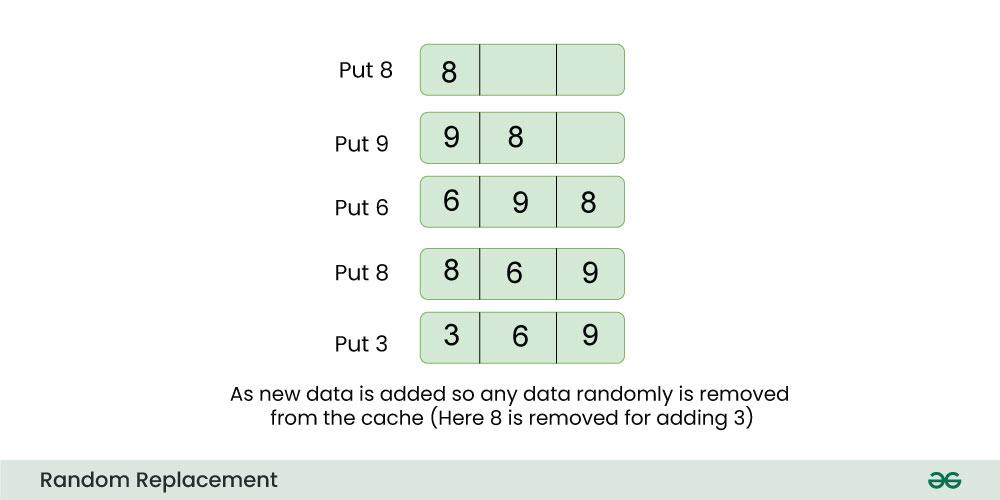
- 随机替换(Random Replacement):随机选择一个缓存行进行替换。
2.3.2 替换算法性能对比
以LRU、FIFO和随机替换三种算法为例进行性能对比,通常:
- LRU提供了较好的性能,尤其是在访问模式具有局部性时,但它需要额外的硬件支持来记录访问时间信息。
- FIFO实现简单,但是它可能无法适应复杂的访问模式,导致"异常现象",如"Belady异常"。
- 随机替换算法在实现上最为简单,且不会出现Belady异常,但性能上一般不如LRU。
具体在性能评估中,这些算法的选择取决于硬件成本和应用需求之间的平衡。在某些特定的硬件实现中,可以结合多种替换策略,以优化性能。
3. 2路组相联Cache的优化策略
3.1 缓存行的设计与优化
缓存行是缓存管理的基本单位,其设计对性能有着显著的影响。在2路组相联Cache中,缓存行的设计与优化是提升Cache性能的重要手段。
3.1.1 缓存行的大小选择
缓存行大小的选择是一个需要权衡的问题。如果缓存行过大,可能会导致缓存资源的浪费,因为较大的缓存行可能会包含未被访问的数据;若缓存行过小,则可能会增加缓存行替换的频率,导致性能下降。
在实践中,通常需要通过实验来确定最合适的缓存行大小。可以通过对比不同大小缓存行下的命中率和性能表现来作出决策。
3.1.2 缓存行合并策略
缓存行合并策略是指将多个连续的内存访问请求合并到一起,以减少对内存的访问次数。这对于减少内存延迟和提高Cache效率非常有效。在2路组相联Cache中,合适的缓存行合并策略可以显著提升缓存的利用率。
当检测到连续的内存访问模式时,合并策略会将这些请求打包发送,这可以减少内存访问的总次数,同时减轻内存带宽的压力。
3.2 数据预取技术的应用
数据预取是一种在Cache未被命中之前,提前将数据从主存预取到Cache中的技术。它能够在一定程度上减少因Cache未命中带来的延迟。
3.2.1 预取技术的原理
预取技术的原理是基于访问局部性原理。通过预测接下来将要访问的数据,预先将这些数据加载到Cache中,从而提高Cache命中率。
- // 示例代码块:数据预取策略
- // 伪代码示例,具体实现依据硬件和系统架构有所不同
- // 初始化预取模块
- initialize_prefetch_unit();
- // 在Cache加载之前,启动预取
- prefetch(address) {
- next_addresses = address_predictor(address);
- for (addr in next_addresses) {
- if (is_cache_line_missing(addr)) {
- fetch_data_to_cache(addr);
- }
- }
- }
在上述代码中,initialize_prefetch_unit() 函数负责初始化预取模块,prefetch() 函数根据当前地址以及地址预测器的预测结果来预取数据。
3.2.2 预取策略的实现与效果
预取策略的实现通常需要硬件支持,并且要对访问模式有一定的预测能力。常见的预取策略有时间预取和空间预取。时间预取是基于时间序列的访问预测,而空间预取则是基于数据空间位置的连续性进行预测。
- | 预取策略 | 原理

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
IMS流量管理:中国联通Mw_Mg_Mi_Mj_Mk_Gm接口的负载均衡技巧
成功转型案例揭秘:企业如何利用212国标协议2017版实现升级
行车记录仪夜视功能深度解析:夜间挑战的对策,让黑暗无所遁形
总线系统:连接计算机各个部件的枢纽
MPLABX+Pickit3烧写案例分析:真实世界挑战的解决方案
VMware vCenter Server 5.5性能提升秘籍:高效管理虚拟化环境
DevOps实践大揭秘:如何打造极致高效的IT运维流程
NPDP真题题库构建:打造个人专属题库的10大技巧
【性能大比拼】:哪种Turbo码译码算法更胜一筹?
【云端数据守护者】:OceanStor Ultrapath在云环境下的应用实践


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















