SIMD与MIMD并行计算的比较与应用
发布时间: 2024-02-28 12:16:08 阅读量: 61 订阅数: 22 
# 1. 数据结构与算法在IT行业中的重要性
在IT行业中,数据结构与算法一直都是程序员需要掌握的重要知识。良好的数据结构与算法能够帮助程序员更高效地解决问题,提高代码的性能,并且在面试和项目实践中也扮演着至关重要的角色。
## 为什么数据结构与算法对程序员如此重要?
数据结构是一种组织和存储数据的方式,而算法则是解决特定问题的一系列步骤。在实际开发中,选择合适的数据结构和算法能够帮助我们更加高效地处理数据、提高代码的执行效率,并在一定程度上节省存储空间。因此,数据结构与算法对于程序员而言是至关重要的。
## 哪些场景下需要用到数据结构与算法?
- 数据处理:在实际项目中,经常需要对大量数据进行处理和分析,而选择合适的数据结构和算法能够提高数据处理的效率。
- 性能优化:对于需要频繁执行的代码,选择合适的算法能够提高代码的执行效率,从而减少资源的消耗。
- 工程实践:在面试和项目实践中,对数据结构与算法的掌握程度也是衡量程序员能力的重要指标。
## 结语
数据结构与算法不仅是编程领域的基础知识,更是解决实际问题的利器。在日常的开发工作中,我们需要不断地学习、理解和应用各种数据结构与算法,以提升自身的编程能力和解决问题的能力。在接下来的章节中,我们将深入探讨数据结构与算法在不同编程语言中的应用及实现。
# 2. 数据准备与预处理
在进行任何数据分析或机器学习任务之前,数据准备与预处理是至关重要的一步。本章节将介绍如何进行数据准备与预处理,包括数据清洗、特征选择、特征缩放、数据转换等方面。
#### 2.1 数据清洗
数据清洗是指对原始数据进行筛查、处理和转换,以便使数据更适合进行分析。常见的数据清洗操作包括处理缺失值、处理异常值、去除重复数据等。下面是一个示例Python代码演示如何处理缺失值:
```python
import pandas as pd
# 创建包含缺失值的DataFrame
data = {'A': [1, 2, None, 4], 'B': [5, None, 7, 8]}
df = pd.DataFrame(data)
# 处理缺失值,这里使用平均值填充
df.fillna(df.mean(), inplace=True)
```
代码解释:
- 首先导入pandas库
- 创建包含缺失值的DataFrame
- 使用`fillna`方法填充缺失值,这里使用每列的均值进行填充
#### 2.2 特征选择
特征选择是指从所有特征中选择最相关或最具代表性的特征,以用于模型训练。常见的特征选择方法包括过滤式特征选择、包裹式特征选择和嵌入式特征选择。下面是一个示例Python代码演示如何使用随机森林进行特征选择:
```python
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
# 生成随机分类数据集
X, y = make_classification(n_samples=1000, n_features=10, random_state=42)
# 使用随机森林进行特征选择
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X, y)
importances = clf.feature_importances_
```
代码解释:
- 导入随机森林分类器和数据生成函数
- 生成随机分类数据集
- 使用随机森林分类器拟合数据,并获取特征重要性
以上是数据准备与预处理的部分内容,下一节将继续介绍特征缩放和数据转换的相关内容。
# 3. 数据分析与建模
在进行IT项目开发的过程中,数据分析与建模是至关重要的一环。通过对数据的深入分析和建模,我们可以更好地理解业务需求,并为系统设计和实现提供有力支持。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
三菱PLC MODBUS TCP通讯基础入门:掌握这5个技巧,让你成为通讯高手

参考资源链接:[三菱Q系列PLC MODBUS TCP通讯配置指南](https://wenku.csdn.net/doc/38xacpyrs6?spm=1055.2635.3001.10343)
# 1. MODBUS TCP通讯协议概述
MODBUS TCP通讯协议是工业自动化领域广泛使用的标准协议之一。作为一种开放式的协议,它提供了一种机制,允许设备之间通过
活动图在敏捷开发中的杀手锏:网上购物系统案例研究
参考资源链接:[UML网上购物活动图和状态图](https://wenku.csdn.net/doc/6401abc3cce7214c316e96ac?spm=1055.2635.3001.10343)
# 1. 活动图在敏捷开发中的重要性
敏捷开发模式近年来在软件行业受到了广泛的欢迎,其迅速迭代和灵活应对变化的特性,使得它成为许多团队的首选开发方式。活动图作为一种可视化的流程图工具,在敏捷开
视频导出插件兼容性全解决:处理各种兼容性问题的黄金法则

参考资源链接:[VideoExport V1.1.0:恋活工作室高效录屏插件教程](https://wenku.csdn.net/doc/2mu2r53zh2?spm=1055.2635.3001.10343)
# 1. 视频导出插件兼容性问题概述
在当今数字化时代,视频编辑软件成为了内容创作者不可或缺的工具。视频导出插件作为软件的重要组成部分,其兼容性问题往
自由能计算在GROMACS模拟中的方法与技巧:专家分享
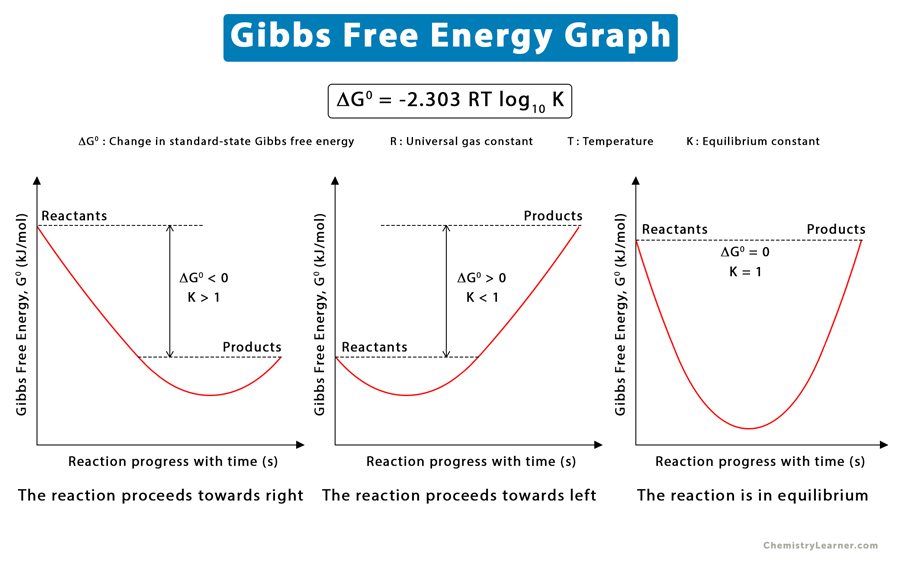
参考资源链接:[Gromacs模拟教程:从pdb到gro,top文件生成及初步模拟](https://wenku.csdn.net/doc/2d8k99rejq?spm=1055.2635.3001.10343)
# 1. GROMACS模拟简介与安装配置
## 1.1 GROMACS模拟简介
GROMACS(GROningen MAchine for
【高效电力变换技术】PLECS建模与仿真:揭秘变换器的秘密
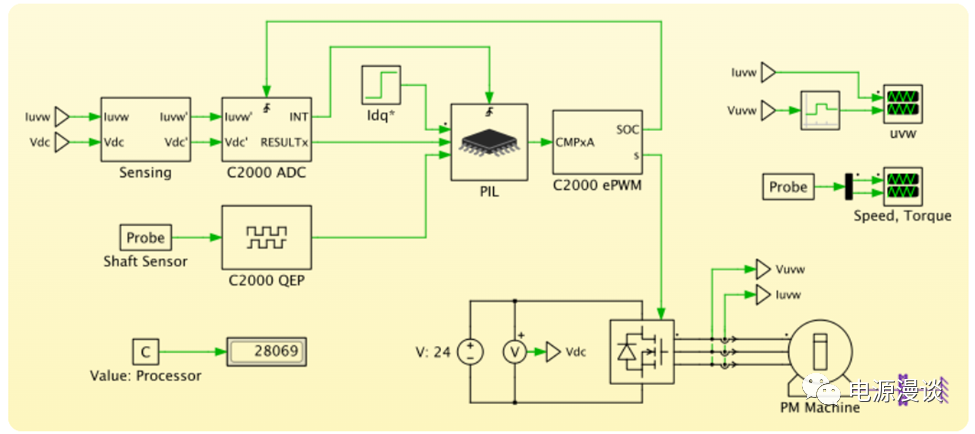
参考资源链接:[PLECS中文使用手册:电力电子系统建模与仿真指南](https://wenku.csdn.net/doc/6401abd1cce7214c316e99bb?spm=1055.2635.3001.10343)
# 1. 高效电力变换技术基础
在现代电力系统中,电力变换技术扮演着核心角色,它涉及到电能的高效转换,以适应不同电力系统和负载的需求。随着科技
【大数据处理】:清华Virtuoso大数据处理应用,挑战极限性能

参考资源链接:[清华微电子所Cadence Virtuoso教程:从入门到精通](https://wenku.csdn.net/doc/6401abcfcce7214c316e9947?spm=1055.2635.3001.10343)
# 1. 大数据处理的概念与挑战
## 1.1 大数据的定义和特征
大数据(Big Data)是一
三星K2200打印机乱码问题终结者:维修模式下的精准解决方案(清晰输出)

参考资源链接:[三星K2200打印机进入维修模式并且清除传输卷寿命的方法.docx](https://wenku.csdn.net/doc/6412b6d0be7fbd1778d48144?spm=1055.2635.3001.10343)
# 1. 三星K2200打印机乱码现象概述
在现代办公环境中,打印机是不可或缺的设备之一。然而,当打印机输出
【最新进展】Romax CAD-Fusion模型导入功能更新:如何跟进?

参考资源链接:[Romax软件教程:CAD Fusion几何模型的导入与导出](https://wenku.csdn.net/doc/54igq1bm01?spm=1055.2635.3001.10343)
# 1. Romax CAD-Fusion模型导入功能概述
SM25QH256MX物联网应用教程:连接、互操作性与通信协议的深入解析
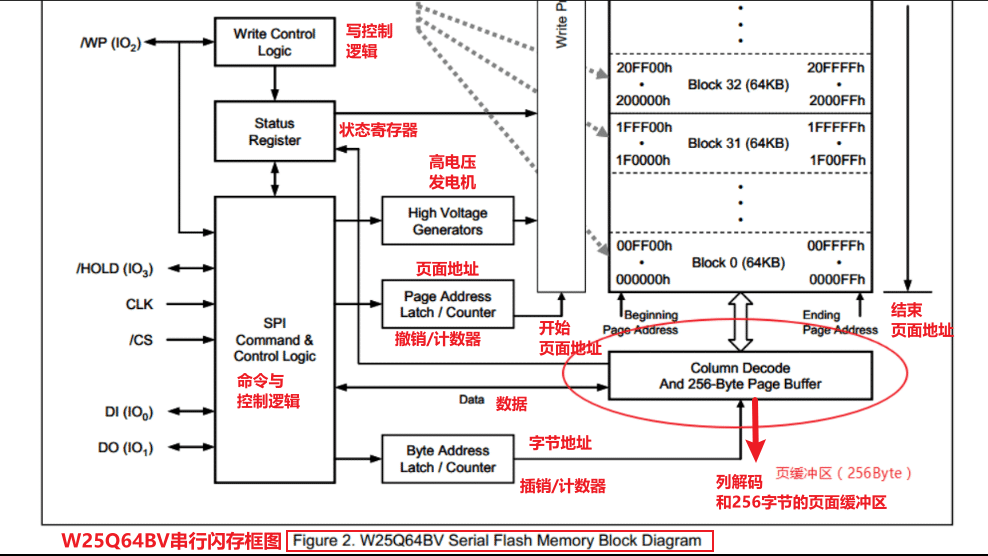
参考资源链接:[国微SM25QH256MX:256Mb SPI Flash 存储器规格说明书](https://wenku.csdn.net/doc/1s6cz8fsd9?spm=1055.2635.3001.10343)
# 1. SM25QH256MX简介与物联网应用概述
## 1.1 SM25QH256MX简介
SM25QH256MX是SMIC生产的一款高性能串行NOR Flash芯片。它支持
【5G网络与物联网】:物联网在5G中的新机遇,把握未来脉搏

参考资源链接:[NR5G网络拒绝码-5gsm_cause = 36 (0x24) (Regular deactivation).docx](https://wenku.csdn.net/doc/644b82f1fcc5391368e5ef6a?spm=1055.2635.3001.10343)
# 1. 5G网络与物联网的融合
## 简介
随着技术的进步,5G网络与物联网的融合正在逐渐改变我们的世界。5G的高
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )