高阶数据清洗技巧:Power Query中的异常值处理
发布时间: 2023-12-24 13:39:30 阅读量: 165 订阅数: 35 
# 第一章:异常值的概念和影响
## 1.1 什么是异常值?
在数据分析中,异常值指的是与大多数样本明显不同的观测数值,也可以被称为离群点。这些数值可能是由于测量误差、数据录入错误或者真实世界中的罕见事件而出现。
## 1.2 异常值对数据分析的影响
异常值可能会导致数据分析结果产生偏差,影响统计指标的准确性,使得数据分析结果失真。例如,在平均数计算中,异常值可能导致平均数偏离了真实的中心位置。
## 1.3 异常值处理的重要性
准确处理异常值对于得到可靠的分析结果至关重要。在数据清洗阶段,识别和处理异常值能够保证数据质量,减少错误结果的发生。因此,在数据处理流程中,异常值处理是一个至关重要的步骤。
### 第二章: Power Query简介
在本章中,我们将深入了解Power Query的基本功能和应用领域,以及它在数据清洗中的作用。同时,我们还会回顾Power Query中的基本数据处理功能。 如果您对数据处理不熟悉,那么这部分内容将会让您受益匪浅。
### 第三章: 数据清洗准备
在进行异常值处理之前,我们首先需要对数据进行清洗准备。这包括数据导入和格式化,数据质量评估和异常值识别,以及数据清洗前的必要准备工作。
#### 3.1 数据导入和格式化
在Power Query中,数据导入可以通过各种数据源进行,例如Excel、CSV、数据库等。一旦数据导入,我们需要对数据进行格式化,包括数据类型转换、日期格式转换、列名重命名等操作,以确保数据质量和准确性。
```python
# Python示例代码
import pandas as pd
# 从Excel导入数据
data = pd.read_excel("data.xlsx")
# 数据格式化
data["Date"] = pd.to_datetime(data["Date"]) # 将日期列转换为日期格式
data["Amount"] = data["Amount"].astype(float) # 将金额列转换为浮点数类型
data.rename(columns={"old_name": "new_name"}, inplace=True) # 重命名列名
```
#### 3.2 数据质量评估和异常值识别
在数据清洗准备阶段,我们需要评估数据质量并识别异常值。常见的数据质量问题包括缺失值、重复值、不一致的格式等,而异常值可能通过统计指标(如均值、标准差)来识别。
```python
# Python示例代码
# 检查缺失值
missing_values = data.isnull().sum()
# 检查重复值
duplicate_rows = data[data.duplicated()]
# 识别异常值(以均值和标准差为例)
mean = data["Amount"].mean()
std_dev = data["Amount"].std()
threshold = 3 # 设置阈值
outliers = data[(data["Amount"] - mean).abs() > threshold * std_dev]
```
#### 3.3 数据清洗前的必要准备工作
在进行异常值处理之前,还需要做一些必要的准备工作,包括备份原始数据、设定异常值处理策略、以及确认异常值处理后的预期数据结果。这些工作将有助于确保异常值处理的准确性和可追溯性。
以上是数据清洗准备阶段的内容,下一步我们将进入异常值的识别和处理方法的讨论。
### 第四章: 异常值的识别和处理方法
在数据处理和清洗过程中,识别和处理异常值是至关重要的一步。本章将介绍在Power Query中识别和处理异常值的方法,包括基于统计指标的异常值识别、离群点的处理策略以及Power Query中常用的异常值处理函数的演示。
#### 4.1 基于统计指标的异常值识别
在Power Query中,我们可以使用各种统计指标来识别异常值,常见的包括均值、中位数、标准差、四分位数等。通过计算这些指标,我们可以找出超出一定阈值范围的数值,从而确定异常值的存在。
```python
# Python 代码示例
# 使用均值和标准差识别异常值
mean_value = df['col
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"power query"为主题,旨在深入探讨数据处理工具Power Query的各种应用技巧和实践案例。从入门到高级应用,涵盖了数据清洗、转换、导入、连接、模糊匹配、数据类型转换、格式化、分组、汇总、查询参数、自定义函数、逻辑表达式、日期时间处理、数据合并拆分、错误处理、数据突变标记、文本处理、正则表达式、数据过滤、金融分析、销售市场分析、数据可视化与Power BI协作应用、自定义数据源构建、数据采样抽样、异常值处理等多个方面。通过专栏内容,读者可系统学习Power Query的各项功能,提升数据处理的能力,并在实践中更加高效地利用Power Query处理各种数据情境。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据分片技术】:实现在线音乐系统数据库的负载均衡
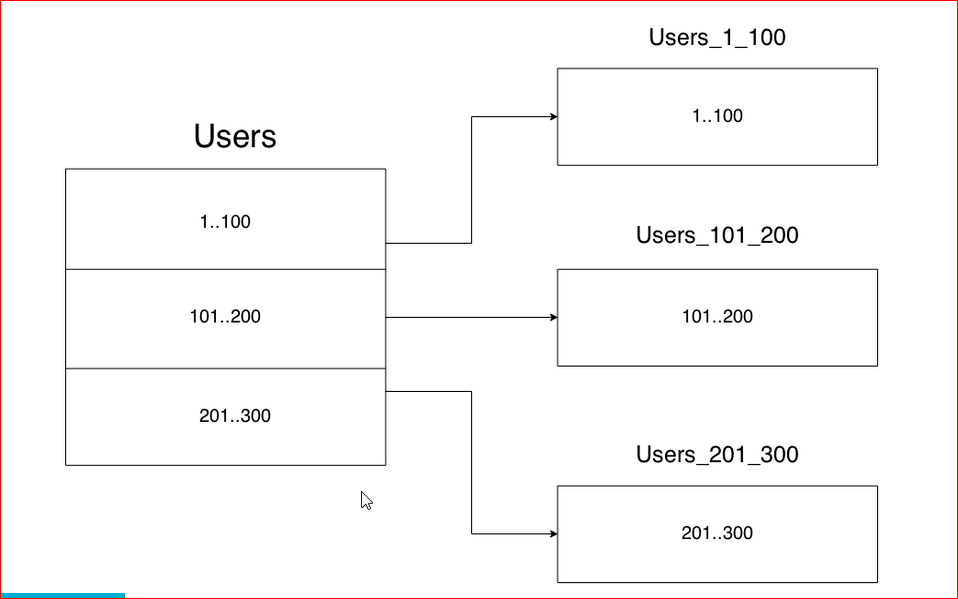
# 1. 数据分片技术概述
## 1.1 数据分片技术的作用
数据分片技术在现代IT架构中扮演着至关重要的角色。它将大型数据库或数据集切分为更小、更易于管理和访问的部分,这些部分被称为“分片”。分片可以优化性能,提高系统的可扩展性和稳定性,同时也是实现负载均衡和高可用性的关键手段。
## 1.2 数据分片的多样性与适用场景
数据分片的策略多种多样,常见的包括垂直分片和水平分片。垂直分片将数据
微信小程序登录后端日志分析与监控:Python管理指南
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
Java中JsonPath与Jackson的混合使用技巧:无缝数据转换与处理

# 1. JSON数据处理概述
JSON(JavaScript Object Notation)数据格式因其轻量级、易于阅读和编写、跨平台特性等优点,成为了现代网络通信中数据交换的首选格式。作为开发者,理解和掌握JSON数
【大数据处理利器】:MySQL分区表使用技巧与实践
# 1. MySQL分区表概述与优势
## 1.1 MySQL分区表简介
MySQL分区表是一种优化存储和管理大型数据集的技术,它允许将表的不同行存储在不同的物理分区中。这不仅可以提高查询性能,还能更有效地管理数据和提升数据库维护的便捷性。
## 1.2 分区表的主要优势
分区表的优势主要体现在以下几个方面:
- **查询性能提升**:通过分区,可以减少查询时需要扫描的数据量
【数据集不平衡处理法】:解决YOLO抽烟数据集类别不均衡问题的有效方法

# 1. 数据集不平衡现象及其影响
在机器学习中,数据集的平衡性是影响模型性能的关键因素之一。不平衡数据集指的是在分类问题中,不同类别的样本数量差异显著,这会导致分类器对多数类的偏好,从而忽视少数类。
## 数据集不平衡的影响
不平衡现象会使得模型在评估指标上产生偏差,如准确率可能很高,但实际上模型并未有效识别少数类样本。这种偏差对许多应
绿色计算与节能技术:计算机组成原理中的能耗管理
# 1. 绿色计算与节能技术概述
随着全球气候变化和能源危机的日益严峻,绿色计算作为一种旨在减少计算设备和系统对环境影响的技术,已经成为IT行业的研究热点。绿色计算关注的是优化计算系统的能源使用效率,降低碳足迹,同时也涉及减少资源消耗和有害物质的排放。它不仅仅关注硬件的能耗管理,也包括软件优化、系统设计等多个方面。本章将对绿色计算与节能技术的基本概念、目标及重要性进行概述
【数据库连接池管理】:高级指针技巧,优化数据库操作

# 1. 数据库连接池的概念与优势
数据库连接池是管理数据库连接复用的资源池,通过维护一定数量的数据库连接,以减少数据库连接的创建和销毁带来的性能开销。连接池的引入,不仅提高了数据库访问的效率,还降低了系统的资源消耗,尤其在高并发场景下,连接池的存在使得数据库能够更加稳定和高效地处理大量请求。对于IT行业专业人士来说,理解连接池的工作机制和优势,能够帮助他们设计出更加健壮的应用架构。
# 2. 数据库连
面向对象编程与函数式编程:探索编程范式的融合之道

# 1. 面向对象编程与函数式编程概念解析
## 1.1 面向对象编程(OOP)基础
面向对象编程是一种编程范式,它使用对象(对象是类的实例)来设计软件应用。
【用户体验设计】:创建易于理解的Java API文档指南
# 1. Java API文档的重要性与作用
## 1.1 API文档的定义及其在开发中的角色
Java API文档是软件开发生命周期中的核心部分,它详细记录了类库、接口、方法、属性等元素的用途、行为和使用方式。文档作为开发者之间的“沟通桥梁”,确保了代码的可维护性和可重用性。
## 1.2 文档对于提高代码质量的重要性
良好的文档
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )