数据可视化:Anaconda数据库连接打造直观报告
发布时间: 2024-12-10 00:22:13 阅读量: 9 订阅数: 15 

School_District_Analysis:Anaconda Jupyter
# 1. 数据可视化的基础与重要性
数据可视化作为信息传达和分析的重要手段,已经成为了当今数据科学领域不可或缺的一部分。它通过图形化的方式将数据转化为直观的图像,帮助人们理解复杂数据集,并做出更为明智的决策。数据可视化不单单是将数据以图表的形式展示出来,更是一种讲述数据故事、发现数据洞察的艺术。
在本章中,我们将探讨数据可视化的基础知识和它的重要性。我们会了解到数据可视化背后的基本原理,例如数据表示、视觉编码、用户感知等,并讨论为何可视化的数据能比纯文本信息更快、更有效地传达信息。此外,我们将强调有效的数据可视化在商业智能、科研分析和教育传播等领域的关键作用。
通过本章的学习,读者将能够理解数据可视化的价值,并为进一步学习特定的可视化工具和技术打下坚实的基础。我们还会讨论一些常见的数据可视化工具,如Matplotlib和Seaborn,为后续章节中更深入的学习和应用奠定基础。
# 2. Anaconda环境的搭建与配置
## 2.1 Anaconda简介及其安装流程
### 2.1.1 Anaconda的定义和作用
Anaconda是一个强大的包管理和环境管理工具,它包含了Python和许多常用的科学计算包,比如NumPy、SciPy、Pandas、Matplotlib等。Anaconda为数据分析、机器学习、深度学习等提供了一套便捷的解决方案,特别适合数据科学家和开发人员处理大规模数据集。Anaconda主要具有以下作用:
- 环境管理:Anaconda允许多个Python版本以及各种库和依赖共存,通过创建虚拟环境可以轻松地为不同的项目设置独立的工作空间,避免包之间的冲突。
- 包管理:Anaconda提供了一个便捷的包管理界面,可以方便地安装、更新和卸载包。
- 整合工具:它还整合了包括Jupyter Notebook在内的多种工具,为数据科学工作流程提供了完整的支持。
### 2.1.2 Anaconda的安装步骤详解
安装Anaconda需要遵循以下步骤:
1. 下载安装包:访问Anaconda官网下载对应操作系统的安装包。选择合适的Python版本和安装器。
```bash
# 示例代码:下载Anaconda安装包的命令(此处仅为示例,实际命令应根据下载链接进行调整)
wget https://repo.anaconda.com/archive/Anaconda3-2022.10-Linux-x86_64.sh
```
2. 安装Anaconda:运行下载的安装脚本并按照提示完成安装过程。
```bash
# 示例代码:在Linux环境下安装Anaconda的命令
sh Anaconda3-2022.10-Linux-x86_64.sh
```
3. 初始化设置:安装过程中可能需要设置环境变量等,通常选择默认选项即可。
4. 验证安装:安装完成后,打开终端或命令提示符,输入`conda --version`确认安装成功。
```bash
# 示例代码:验证Anaconda是否安装成功的命令
conda --version
```
5. (可选)升级conda:安装完成后,建议立即升级conda以获取最新版本。
```bash
# 示例代码:升级conda的命令
conda update conda
```
按照上述步骤,用户可以顺利地安装并配置好Anaconda环境,为后续的数据科学工作奠定基础。
## 2.2 Anaconda环境管理
### 2.2.1 创建和管理虚拟环境
创建虚拟环境的目的是在隔离的环境中安装和运行不同版本的库,避免不同项目间的依赖冲突。Anaconda通过`conda`命令行工具管理虚拟环境。
- 创建虚拟环境:
```bash
# 示例代码:创建一个名为 env_name 的新虚拟环境
conda create -n env_name python=3.8
```
- 激活虚拟环境:
```bash
# 示例代码:激活名为 env_name 的虚拟环境
conda activate env_name
```
- 离开虚拟环境:
```bash
# 示例代码:离开当前虚拟环境
conda deactivate
```
### 2.2.2 包管理和更新策略
在Anaconda虚拟环境中安装包,可以使用`conda install`命令或`pip install`命令。Anaconda为包管理提供了一套非常方便的机制。
- 使用conda安装包:
```bash
# 示例代码:使用conda安装numpy包
conda install numpy
```
- 使用pip安装包:
```bash
# 示例代码:使用pip安装scikit-learn包
pip install scikit-learn
```
- 更新包:
```bash
# 示例代码:更新numpy包到最新版本
conda update numpy
```
- 更新conda本身:
```bash
# 示例代码:更新conda工具到最新版本
conda update conda
```
## 2.3 Anaconda的扩展工具
### 2.3.1 Jupyter Notebook快速上手
Jupyter Notebook是一个开源的Web应用程序,允许用户创建和共享包含代码、可视化和文本的文档。它在数据分析、机器学习等领域非常流行。
- 启动Jupyter Notebook:
```bash
# 示例代码:启动Jupyter Notebook
jupyter notebook
```
- 创建新的Notebook文件:
在Jupyter Notebook的主界面,点击右上角的“New”按钮,然后选择“Python 3”来创建一个新的Notebook。
- 使用Notebook:
- 编写代码:在单元格中输入Python代码,然后按下`Shift + Enter`来执行。
- 添加解释性文本:使用Markdown语法在单元格中添加格式化的解释性文本。
### 2.3.2 Conda命令行工具的高级用法
Conda命令行工具不仅用于安装和管理包,它还可以用来管理环境和解决包依赖关系。
- 导出环境到文件:
```bash
# 示例代码:将当前环境导出到环境文件
conda env export > environment.yml
```
- 从文件创建环境:
```bash
# 示例代码:根据环境文件创建新环境
conda env create -f environment.yml
```
- 删除环境:
```bash
# 示例代码:删除名为 env_name 的环境
conda env remove -n env_name
```
在本章节中,我们介绍了Anaconda的基本概念、安装流程以及环境管理和扩展工具的使用方法。这些内容构成了数据分析与科学计算的基石,为后续章节中涉及的数据处理和可视化技术打下了基础。通过本章节的介绍,读者可以了解到如何利用Anaconda快速搭建数据科学工作环境,并进行包和环境管理。随着学习的深入,我们将逐步探索更加复杂和高效的数据处理技术,以及数据可视化与报告制作的方法。
# 3. 数据库连接与数据处理
## 3.1 数据库基础理论
### 3.1.1 关系型数据库与非关系型数据库的区别
在现代信息系统中,数据库是一个不可或缺的组件。它的主要功能是存储、检索和管理数据。数据库系统可以分为两大类:关系型数据库和非关系型数据库,它们各自有着不同的特点和应用场景。
关系型数据库(Relational Database Management System, RDBMS)如MySQL、PostgreSQL等,是基于严格的表格模型,通过行和列来组织数据。它们将数据存储在不同的表中,表与表之间通过主键和外键相关联,从而构建复杂的数据关系。关系型数据库使用结构化查询语言(SQL)来访问和操作数据,这使得它们在执行复杂的查询时非常强大和灵活。
另一方面,非关系型数据库(NoSQL)是一种不使用传统表格形式的数据存储模型,它们支持更灵活的数据模型,如键值存储、文档存储、列存储和图形数据库。非关系型数据库的优势在于它们的可扩展性、高吞吐量和灵活的数据模型,使得它们在处理非结构化或半结构化数据、或者需要水平扩展的大型分布式系统中更加有效。
### 3.1.2 SQL语言基础
结构化查询语言(SQL)是操作关系型数据库的标准语言。SQL包含了一系列用于数据操作和管理的命令,如查询(SELECT)、插入(INSERT)、更新(UPDATE)和删除(DELETE)。
一个基本的SQL查询通常包括以下几个部分:
- SELECT:指定要返回的列。
- FROM:指定从哪个表或哪些表中检索数据。
- WHERE:指定筛选条件,用于返回满足特定条件的行。
- GROUP BY:用于将结果集中的记录分组。
- HAVING:对GROUP BY分组后的结果进行条件筛选。
- ORDER BY:对返回结果的记录进行排序。
理解SQL语言的基础对于任何数据处理流程都是至关重要的,尤其是在数据分析和数据科学领域。掌握SQL可以让我们从关系型数据库中高效地提取所需数据,并进行进一步的处理和分析。
## 3.2 使用Python连接数据库
### 3.2.1 常用数据库驱动安装与配置
要在Python中连接数据库,首先需要安装对应数据库的驱动。例如,要连接MySQL数据库,我们需要安装名为`mysql-connector-python`的驱动。通过pip安装命令如下:
```bash
pip install mysql-connector-python
```
同理,对于PostgreSQL数据库,安装`psycopg2`驱动:
```bash
pip install psycopg2
```
安装完成后,需要配置连接字符串,它包含了数据库的类型、主机地址、用户名、密码和数据库名等信息。以下是一个连接MySQL数据库的示例:
```python
import mysql.connector
config = {
'user': 'username',
'password': 'password',
'host': '127.0.0.1',
'database': 'database_name',
'raise_on_warnings': True
}
cnx = mysql.connector.connect(**config)
```
### 3.2.2 Python数据库连接库的使用(如sqlite3, MySQLdb, psycopg2等)
Python提供了多个数据库连接库,我们可以根据所使用的数据库类型选择合适的库进行操作。在这一节,我们将使用Python标准库中的`sqlite3`模块和第三方库`MySQLdb`与`psycopg2`来展示如何连接不同类型的数据库。
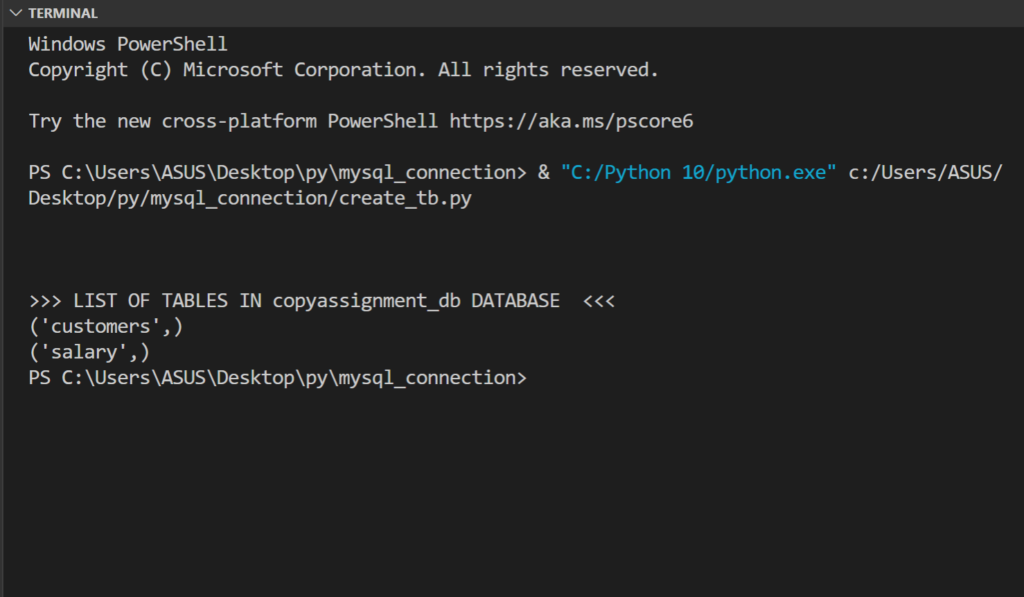
使用`sqlite3`模块连接SQLite数据库的示

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Anaconda 环境下数据库连接和使用的各个方面。从初学者指南到高级教程,它涵盖了各种数据库,包括 PostgreSQL、SQL Server、MongoDB、Cassandra 和 Redis。文章提供了详细的说明、代码示例和最佳实践,帮助读者建立高效的数据连接、优化查询、处理数据并集成 NoSQL 数据库。此外,专栏还介绍了 Jupyter Notebook 中的交互式连接技巧,以及 Hadoop 和 Spark 在 Anaconda 环境中的大数据连接策略。通过本专栏,读者将掌握在 Anaconda 环境中有效连接、使用和优化数据库所需的知识和技能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SIMCA 14.1进阶秘籍:打造复杂3D火山图的5大技巧

参考资源链接:[SIMCA 14.1教程:3D火山图制作与解析](https://wenku.csdn.net/doc/6401ad16cce7214c31
Silvaco TCAD 与 Spice 对比分析

参考资源链接:[Silvaco TCAD器件仿真教程:材料与物理模型设定](https://wenku.csdn.net/doc/6moyf21a6v?spm=1055.2635.3001.10343)
# 1. TCAD与Spice简介
## 1.1 TCAD与Spice的基本概念
TCAD(Technology Computer-Aided Design)与Spice是半导
数据同步与恢复:光纤环网机制详解及最佳实践

参考资源链接:[光纤环网技术详解:组网方式与帧处理机制](https://wenku.csdn.net/doc/1q4ubo5bp2?spm=1055.2635.3001.10343)
# 1. 数据同步与恢复概述
在现代IT架构中,数据同步与恢复是确保业务连续性和数据安全的关键组成部分。本章将概述数据同步与恢复的基本概念,并探讨其在企业环境中的重要性。
【技术写作秘籍】:四级词汇在技术文档中的巧妙运用

参考资源链接:[四级核心词汇详解:高频词与相关术语](https://wenku.csdn.net/doc/5gxen3nh5w?spm=1055.2635.3001.10343)
# 1. 技术写作与四级词汇的重要性
在技术领域,准确而清晰的沟通是至关重要的。技术写作不仅需要传达具体信息,而且需要确保不同背景的读者都能理解。四级词汇,指的是大学英语四级考试中的核心词汇,它们在技术写作中扮演着不可或缺的角色。这些词汇因为其普遍性和准确
西门子FB284成本效益评估:如何进行ROI与TCO分析以优化项目预算
参考资源链接:[西门子FB284功能块在TIA Portal中的V90定位控制](https://wenku.csdn.net/doc/6401acffcce7214c316ede81?spm=1055.2635.3001.10343)
# 1. 理解西门子FB284在项目中的角色
在现代工业自动化项目中,西门子FB284作为一个功能块,扮演着至关重要的角色。FB284是西门子SI
【BELLHOP全面解读】:从基础操作到高级特性的全方位指南

参考资源链接:[BELLHOP中文使用指南及MATLAB操作详解](https://wenku.csdn.net/doc/6412b546be7fbd1778d42928?spm=1055.2635.3001.10343)
# 1. BELLHOP基础介绍与安装
## BELLHOP是什么
BELLHOP是一个先进的IT任务自动化和管理系统,旨在优化日常运维任务的效率。
快速识别库卡机器人故障:维修手册与预防策略大揭秘

参考资源链接:[库卡机器人kuka故障信息与故障处理.pdf](https://wenku.csdn.net/doc/64619a8c543f844488937510?spm=1055.2635.3001.10343)
# 1. 库卡机器人故障快速识别概述
## 1.1 故障识别的重要性
在自动化领域中,库卡机器人故障的快速识别对于确保生产线的稳定运行至关重要。通过及时的故障识别,可以最小化生产停滞时间,减少经济损失,并增强整个
【RTD2556深度剖析】:解锁顶尖技术手册的12个秘诀

参考资源链接:[RTD2556-CG多功能显示器控制器数据手册:集成接口与应用解析](https://wenku.csdn.net/doc/6412b6eebe7fbd1778d487eb?spm=1055.2635.3001.10343)
# 1. RTD2556技术概述
## 1.1 RTD2556简介
RTD2556是一颗高度集成的系统级芯片(SoC),专为视频处理
【Dalsa相机固件升级全攻略】:避免失败的5个关键步骤

参考资源链接:[Dalsa相机全面使用指南:硬件配置与软件开发](https://wenku.csdn.net/doc/57bgbkrhzu?spm=1055.2635.3001.10343)
# 1. Dalsa相机固件升级概览
在本章中,我们将对Dalsa相机固件升级做一个全面的了解,为后续章节深入探讨升级前的准备、过程、验证以及高级应用打下基础。固件升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )