实现实时日志处理系统:Kafka与ELK集成
发布时间: 2024-05-03 06:23:51 阅读量: 361 订阅数: 98 

ELK+Filebeat+Kafka+ZooKeeper构建日志分析平台

# 1. 实时日志处理系统的概述
实时日志处理系统是用于收集、处理和分析大量实时日志数据的软件系统。它使组织能够从日志数据中提取有价值的见解,以进行故障排除、性能监控和安全分析。
实时日志处理系统通常由三个主要组件组成:
- **日志收集器:**负责收集日志数据并将其发送到中央存储库。
- **日志处理器:**分析日志数据,提取有价值的信息并将其存储在可搜索的格式中。
- **日志分析器:**提供交互式界面,允许用户查询和可视化日志数据。
# 2. Kafka简介与实践
### 2.1 Kafka的基本概念与架构
#### 2.1.1 Kafka的组件和工作原理
Kafka是一个分布式流处理平台,它可以处理大规模的实时数据流。Kafka的核心组件包括:
- **生产者 (Producer)**:负责将数据写入Kafka集群。
- **代理 (Broker)**:存储和管理数据,并处理生产者和消费者之间的通信。
- **消费者 (Consumer)**:从Kafka集群中读取数据。
Kafka采用发布-订阅模型,生产者将数据发布到主题(Topic),消费者订阅主题并消费数据。每个主题可以有多个分区(Partition),每个分区是一个有序的不变日志,数据以追加的方式写入分区。
#### 2.1.2 Kafka的特性和优势
Kafka具有以下特性和优势:
- **高吞吐量和低延迟**:Kafka可以处理每秒数百万条消息,并提供低延迟的访问。
- **可扩展性**:Kafka可以轻松地扩展到数百个代理,以处理不断增长的数据量。
- **容错性**:Kafka通过复制数据和故障转移机制,确保数据的高可用性。
- **分布式**:Kafka是一个分布式系统,可以在多个服务器上运行。
- **持久性**:Kafka将数据持久化到磁盘,以确保数据不会丢失。
### 2.2 Kafka的实践应用
#### 2.2.1 Kafka的安装和配置
**安装 Kafka**
```bash
wget https://archive.apache.org/dist/kafka/3.3.1/kafka_2.13-3.3.1.tgz
tar -xzf kafka_2.13-3.3.1.tgz
```
**配置 Kafka**
编辑 `config/server.properties` 文件,设置以下参数:
```
broker.id=0
listeners=PLAINTEXT://localhost:9092
```
**启动 Kafka**
```bash
bin/kafka-server-start.sh config/server.properties
```
#### 2.2.2 Kafka的生产者和消费者使用
**创建主题**
```bash
bin/kafka-topics.sh --create --topic my-topic --partitions 3 --replication-factor 1
```
**发送消息**
```java
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");
producer.send(record);
producer.close();
}
}
```
**接收消息**
```java
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerExample {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singletonList("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.key() + ": " + record.value());
}
}
consumer.close();
}
}
```
# 3. ELK简介与实践
### 3.1 ELK的基本概念与架构
#### 3.1.1 Elasticsearch、Logstash和Kibana的介绍
**Elasticsearch**是一个分布式、可扩展的搜索和分析引擎,用于存储、搜索和分析海量数据。它基于Apache Lucene构建,提供强大的全文搜索、聚合和分析功能。
**Logstash**是一个日志解析和处理引擎,用于收集、解析和转换日志数据。它支持多种输入源,如文件、Syslog和HTTP,并提供丰富的过滤器和插件,用于自定义日志处理。
**Kibana**是一个数据可视化平台,用于探索、分析和展示Elasticsearch中的数据。它提供交互式仪表板、图表和地图,使用户能够轻松地从数据中提取洞察力。
#### 3.1.2 ELK的集成和工作原理
ELK组件通过管道集成在一起,形成一个端到端的日志处理系统。工作原理如下:
1. **日志收集:**Logstash从各种来源收集日志数据。
2. **日志解析:**Logstash使用过滤器和插件解析日志数据,提取结构化字段。
3. **数据索引:**Logstash将解析后的数据索引到Elasticsearch中,使数据可搜索和分析。
4. **数据可视化:**Kibana从Elasticsearch中检索数据,并将其可视化为仪表板、图表和地图,供用户分析和探索。
### 3.2 ELK的实践应用
#### 3.2.1 ELK的安装和配置
**安装:**
1. 下载并安装Elasticsearch、Logstash和Kibana。
2. 配置Elasticsearch集群。
3. 安装Logstash并配置输入和输出插件。
4. 安装Kibana并配置Elasticsearch连接。
**配置:**
1. 配置Logstash过滤器和插件,以满足特定的日志解析需求。
2. 配置Kibana仪表板和可视化,以满足特定的分析和报告需求。
#### 3.2.2 ELK的日志采集和分析
**日志采集:**
1. 使用Logstash配置输入插件,从各种来源(如文件、Syslog、HTTP)收集日志数据。
2. 使用过滤器和插件解析日志数据,提取结构化字段。
**日志分析:**
1. 使用Elasticsearch的搜索和分析功能,查询和分析日志数据。
2. 使用Kibana的可视化功能,创建交互式仪表板、图表和地图,以探索和分析日志数据。
3. 使用Kibana的机器学习功能,检测异常和趋势,并生成预测。
**代码块:**
```
# Logstash配置文件示例
input {
file {
path => "/var/log/nginx/access.log"
type => "nginx-access"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "nginx-access-%{+YYYY.MM.dd}"
}
}
```
**逻辑分析:**
此Logstash配置文件配置了一个输入插件,用于从Nginx访问日志文件中收集日志数据。它使用Grok过滤器解析日志消息,提取结构化字段,并使用日期过滤器解析时间戳。然后,它将解析后的数据输出到Elasticsearch中的索引中,索引名称以日期格式命名。
# 4. Kafka与ELK的集成实践
### 4.1 Kafka与ELK的集成原理
#### 4.1.1 数据流转流程
Kafka与ELK的集成实现了一个完整的数据流转流程,从日志生成到可视化分析。其流程如下:
1. **日志生成:**应用程序或系统生成日志事件,并将其发送到Kafka。
2. **Kafka接收:**Kafka接收日志事件,并将其存储在主题中。
3. **Logstash消费:**Logstash从Kafka的主题中消费日志事件。
4. **日志解析:**Logstash解析日志事件,提取相关字段和信息。
5. **数据预处理:**Logstash对日志事件进行预处理,如过滤、转换和丰富。
6. **Elasticsearch索引:**Logstash将预处理后的日志事件发送到Elasticsearch,Elasticsearch对日志事件进行索引和存储。
7. **Kibana可视化:**Kibana连接到Elasticsearch,并提供交互式界面,用于探索、分析和可视化日志数据。
#### 4.1.2 集成配置和注意事项
集成Kafka和ELK需要进行一些配置和注意事项:
**Kafka配置:**
* 创建一个主题用于存储日志事件。
* 配置Logstash连接到Kafka的主题。
**Logstash配置:**
* 安装Logstash的Kafka输入插件。
* 配置Logstash从Kafka主题中消费日志事件。
* 配置Logstash解析和预处理日志事件。
* 配置Logstash将日志事件发送到Elasticsearch。
**Elasticsearch配置:**
* 创建一个索引用于存储日志事件。
* 配置Kibana连接到Elasticsearch索引。
**注意事项:**
* 确保Kafka、Logstash和Elasticsearch之间的时间同步。
* 监控Kafka、Logstash和Elasticsearch的性能,并根据需要进行调整。
* 考虑使用负载均衡器来处理高流量。
### 4.2 Kafka与ELK的实践应用
#### 4.2.1 日志采集和预处理
Logstash在Kafka与ELK集成中扮演着日志采集和预处理的关键角色。其主要功能包括:
* **日志采集:**从Kafka主题中消费日志事件。
* **日志解析:**使用正则表达式或模式匹配器解析日志事件,提取相关字段和信息。
* **数据预处理:**过滤、转换和丰富日志事件,使其适合存储和分析。
#### 4.2.2 日志存储和索引
Elasticsearch是Kafka与ELK集成中用于存储和索引日志事件的组件。其主要功能包括:
* **日志存储:**将预处理后的日志事件存储在索引中。
* **日志索引:**对日志事件进行索引,以便快速搜索和检索。
* **数据管理:**提供数据管理功能,如索引管理、文档删除和更新。
#### 4.2.3 日志分析和可视化
Kibana是Kafka与ELK集成中用于日志分析和可视化的组件。其主要功能包括:
* **日志分析:**提供交互式界面,用于探索、分析和可视化日志数据。
* **仪表板创建:**允许用户创建自定义仪表板,以显示关键指标和图表。
* **数据挖掘:**支持使用Lucene查询语言对日志数据进行高级搜索和挖掘。
# 5. 实时日志处理系统的优化与运维
### 5.1 性能优化
#### 5.1.1 Kafka的性能优化
**参数调整:**
- `message.max.bytes`:调整消息的最大字节数,避免大消息导致性能下降。
- `batch.size`:调整批处理大小,平衡吞吐量和延迟。
- `linger.ms`:调整消息滞留时间,减少小消息的发送次数。
**分区优化:**
- 增加分区数量,提高并行处理能力。
- 根据数据特征合理分配分区,避免数据倾斜。
**压缩与编码:**
- 启用消息压缩,减少网络传输开销。
- 使用高效的编码方式,如Snappy或LZ4。
#### 5.1.2 ELK的性能优化
**硬件优化:**
- 增加CPU核心数和内存容量,提高处理能力。
- 使用SSD或NVMe存储,提升IO性能。
**索引优化:**
- 选择合适的索引类型,如倒排索引或全文索引。
- 定期优化索引,删除不需要的文档和合并段。
**查询优化:**
- 使用过滤器和范围查询,减少扫描数据量。
- 启用缓存,加速查询响应。
### 5.2 运维管理
#### 5.2.1 监控和告警
**Kafka监控:**
- 使用Kafka自带的监控工具,如JMX或Prometheus。
- 监控指标包括:分区滞后、消息积压、磁盘使用率。
**ELK监控:**
- 使用Elasticsearch的监控API或第三方工具。
- 监控指标包括:集群健康、索引大小、查询性能。
**告警配置:**
- 设置阈值和告警规则,及时发现异常情况。
- 集成告警系统,如PagerDuty或Slack。
#### 5.2.2 备份和恢复
**Kafka备份:**
- 使用Kafka自带的备份工具,如Kafka MirrorMaker。
- 定期备份元数据和数据,确保数据安全。
**ELK备份:**
- 使用Elasticsearch的快照功能,备份索引数据。
- 定期创建快照,并存储在安全的存储位置。
**恢复操作:**
- 从备份中恢复Kafka集群,恢复数据和元数据。
- 从快照中恢复Elasticsearch索引,恢复数据。
# 6. 实时日志处理系统在实际场景中的应用**
**6.1 应用场景举例**
实时日志处理系统在实际场景中有着广泛的应用,以下列举几个常见的应用场景:
- **网站访问日志分析:**通过收集和分析网站访问日志,可以了解网站流量、用户行为、页面性能等信息,从而优化网站体验和提高用户粘性。
- **应用性能监控:**实时收集和分析应用日志,可以快速发现和定位应用中的性能问题,从而保障应用的稳定性和可用性。
**6.2 实践案例分享**
**案例一:网站访问日志分析**
某电商网站使用 Kafka 和 ELK 搭建了实时日志处理系统,用于分析网站访问日志。通过对日志数据的处理和分析,网站运营团队可以获得以下信息:
- 网站流量趋势和用户分布
- 热门页面和访问路径
- 页面加载时间和响应速度
- 用户行为分析,如跳出率、转化率
这些信息帮助网站运营团队优化网站结构、提升页面性能,从而提高用户体验和网站转化率。
**案例二:应用性能监控**
某金融机构使用 Kafka 和 ELK 搭建了实时日志处理系统,用于监控其核心交易系统的性能。通过对日志数据的处理和分析,运维团队可以获得以下信息:
- 系统响应时间和吞吐量
- 异常和错误日志
- 慢查询和性能瓶颈
这些信息帮助运维团队快速发现和定位系统性能问题,及时采取措施解决问题,保障系统的稳定性和可用性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《Kafka从入门到精通》涵盖了Kafka技术的各个方面,从基础入门到高级应用。它提供了循序渐进的指南,帮助读者从头开始构建和部署Kafka消息队列系统。专栏深入探讨了Kafka中的关键概念,如生产者、消费者、分区、副本、消息过期和清理策略,以及安全性和可靠性考虑因素。此外,它还展示了Kafka与其他技术(如ELK、Hadoop、Hive和TensorFlow)的集成,以实现实时日志处理、数据流处理、数据仓库、机器学习等复杂应用场景。通过本专栏,读者将全面掌握Kafka技术,并能够构建和维护高性能、可扩展的消息队列系统,以满足各种实时数据处理需求。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【从零开始学Verilog】:如何在Cadence中成功搭建第一个项目

# 摘要
本文旨在提供一个全面的Verilog语言和Cadence工具使用指南,涵盖了从基础入门到项目综合与仿真的深入应用。第一章介绍了Verilog语言的基础知识,包括基本语法和结构。第二章则深入讲解了Cadence工具的使用技巧,包括界面操作、项目管理和设计库应用。第三章专注于在Cadence环境中构建和维护Verilog项目,着重讲述了代码编写、组织和集成。第四章探讨
微服务架构精要:实现高质量设计与最佳实践
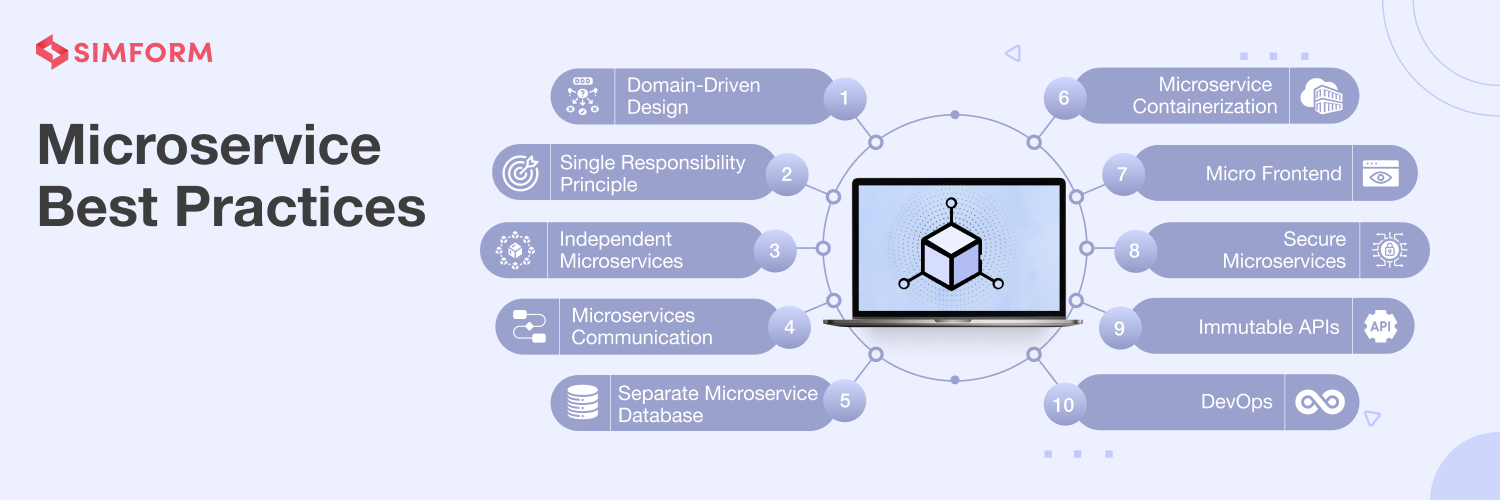
# 摘要
微服务架构作为一种现代化的软件开发范式,以其模块化、灵活性和可扩展性优势正逐渐成为企业级应用开发的首选。本文从基本概念入手,深入探讨了微服务的设计原则与模式、持续集成和部署策略、以及安全、测试与优化方法。通过对微服务架构模式的详细介绍,如API网关、断路器、CQRS等,文章强调了微服务通信机制的重要性。同时,本文还分析了微服务在持续集成和自动化部署中的实践,包括容器化技术的应用和监控、日志管理。此
【快速定位HMI通信故障】:自由口协议故障排查手册

# 摘要
自由口协议作为工业通信中的关键组件,其基础、故障定位及优化对于保证系统的稳定运行至关重要。本文首先介绍了自由口协议的基本原理、标准与参数配置以及数据包结构,为理解其工作机制奠定基础。接着,详细阐述了自由口协议故障排查技术,包括常见故障类型、诊断工具与方法及解
C语言内存管理速成课:避开动态内存分配的坑
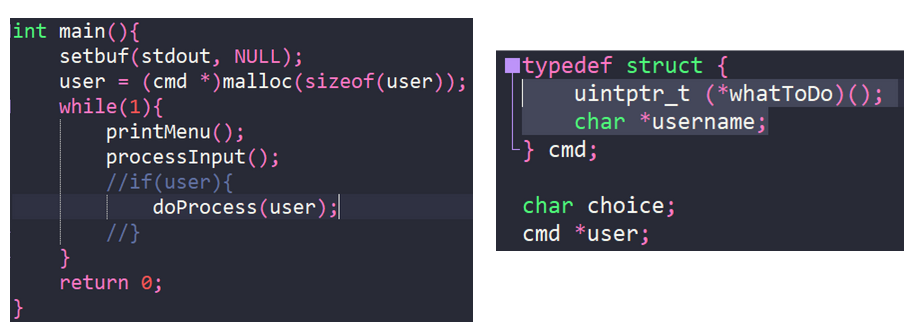
# 摘要
C语言作为经典的编程语言,其内存管理机制对程序的性能和稳定性具有决定性影响。本文首先概述了C语言内存管理的基础知识,随后深入探讨了动态内存分配的原理、使用技巧及常见错误。通过案例分析,本文进一步实践了内存管理在实际项目中的应用,并讨论了内存分配的安全性和优化策略。本文还涵盖了高级内存管理技术,并展望了内存管理技术的发展趋势和新兴技术的应用前景。通
【招投标方案书的语言艺术】:让技术文档更具说服力的技巧

# 摘要
本文探讨了招投标方案书撰写过程中的语言艺术及结构设计。重点分析了技术细节的语言表达技巧,包括技术规格的准确描述、方案的逻辑性和条理性构建、以及提升语言说服力的方法。接着,文章详细介绍了招投标方案书的结构设计,强调了标准结构和突出技术展示的重要性,以及结尾部分总结与承诺的撰写技巧。此外,本文还提供了写作实践的案例分析和写作技巧的演练,强调了与甲方沟通与互动的重要性,包括沟通技巧、语言策略和后续跟进调整。最后
【效能对比】:TAN时间明晰网络与传统网络的差异,新一代网络技术的效能评估
.jpg)
# 摘要
时间明晰网络作为新型网络架构,提供了比传统网络更精准的时间同步和更高的服务质量(QoS)。本文首先概述了时间明晰网络的基本概念、运作机制及其与传统网络的对比优势。接着,文章深入探讨了实现时间明晰网络的关键技术,包括精确时间协议(PTP)、网络时间协议(NTP)和时间敏感网络(TSN)技术等。通过对工业自动化
【UDS错误代码秘密解读】:专家级分析与故障排查技巧

# 摘要
统一诊断服务(UDS)协议是汽车行业中用于诊断和通信的国际标准,其错误代码机制对于检测和解决车载系统问题至关重要。本文首先概述了UDS协议的基础知识,包括其架构和消
【RTX 2080 Ti性能调优技巧】:硬件潜力全挖掘
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/8/v/dscSt1S7GuYFTJNrIH0g/2017-03-01-limpa-2.png)
# 摘要
本文全面概述了RTX 2080 Ti显卡的架构特点及其性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )